Categorical Prior Lock-in: Why In-Context Learning Fails for Structured Data
Pith reviewed 2026-06-27 10:12 UTC · model grok-4.3
The pith
In-context learning cannot update categorical priors in LLMs for structured data generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across two 7B open-weight models, in-context learning improves numerical fidelity with additional examples yet exhibits a sharp ceiling on categorical distributions, failing to reproduce rare classes entirely; the authors identify this behavior as categorical prior lock-in, the inability of ICL to update the model's prior over token distributions inherited from pre-training.
What carries the argument
Categorical prior lock-in: the structural inability of in-context learning to revise the model's inherited prior over categorical token distributions.
If this is right
- ICL steadily raises numerical accuracy but plateaus on categorical reproduction regardless of example count.
- LoRA fine-tuning removes the categorical ceiling yet introduces measurable memorization of training rows.
- In some settings LoRA destabilizes the model's ability to produce valid structured output formats.
- A fundamental trade-off exists between distribution adaptability and privacy preservation when moving from ICL to fine-tuning.
Where Pith is reading between the lines
- The same prior-lock mechanism may limit ICL on other discrete structured outputs such as graphs or code with constrained vocabularies.
- Prompt-only techniques are unlikely to overcome the lock-in because they leave the underlying token prior untouched.
- The ceiling observed on 7B models may shift or disappear at substantially larger scales or with different pre-training mixtures.
- Low-cardinality categorical features might still be adaptable under ICL while high-cardinality ones remain locked.
Load-bearing premise
The inability to update categorical priors is a structural property of in-context learning rather than an artifact of prompt format, model scale, or the specific high-cardinality tabular test case.
What would settle it
An experiment in which increasing the number of in-context examples allows the model to match the full empirical categorical distribution, including every rare class, on held-out high-cardinality tabular data would falsify the lock-in claim.
Figures
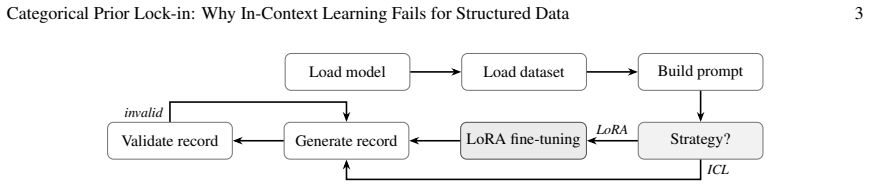
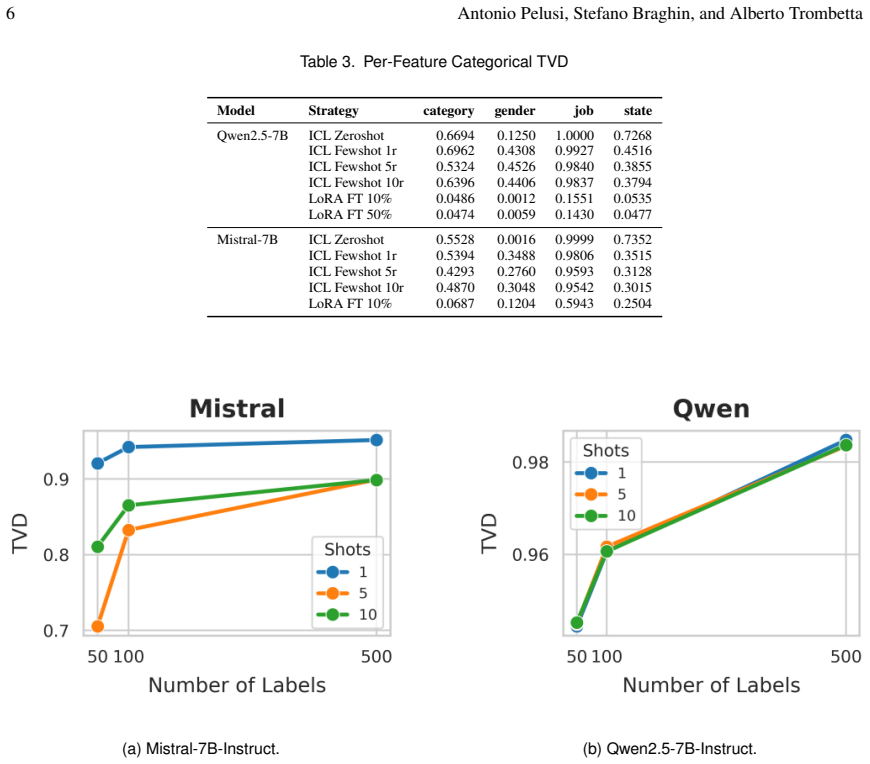
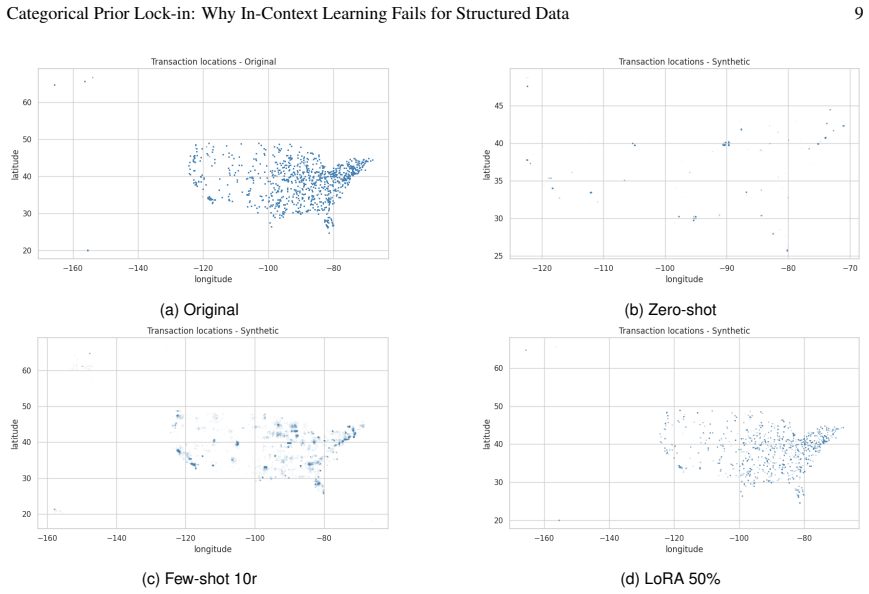
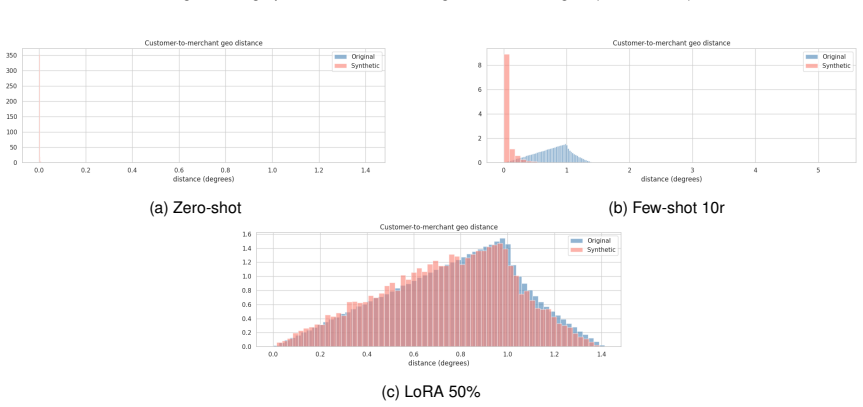

read the original abstract
Large language models (LLMs) are increasingly used as conditional generators for structured data, relying on in-context learning (ICL) to adapt to new distributions without parameter updates. We investigate the limits of ICL for structured generation under distribution mismatch, using high-cardinality tabular data as a controlled test case, and identify a structural failure mode we term \textit{categorical prior lock-in}: the inability of ICL to update the model's prior over token distributions inherited from pre-training. Across two 7B-parameter open-weight models, ICL improves numerical fidelity with additional examples but exhibits a sharp ceiling on categorical distributions, failing to reproduce rare classes entirely. Parameter-efficient fine-tuning (LoRA) overcomes these limitations but introduces measurable memorization risk and, in some cases, destabilizes structured output generation, highlighting a fundamental trade-off between adaptability and privacy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in-context learning (ICL) in LLMs exhibits a structural failure mode termed 'categorical prior lock-in' when used for conditional generation of structured data under distribution mismatch. Using high-cardinality tabular data as a test case with two 7B open-weight models, it reports that ICL improves numerical fidelity with more examples but shows a sharp ceiling on categorical distributions, failing to reproduce rare classes entirely. LoRA fine-tuning overcomes the limitation but introduces memorization risk and can destabilize structured outputs, highlighting a trade-off between adaptability and privacy.
Significance. If the empirical observation holds after appropriate controls, the result would be significant for applications of LLMs as conditional generators for structured data, as it identifies a concrete limitation of ICL on categorical priors distinct from numerical adaptation and quantifies a practical trade-off with parameter-efficient fine-tuning. The use of open-weight models and focus on high-cardinality tabular data provides a reproducible starting point for studying ICL boundaries in structured generation tasks.
major comments (2)
- [Abstract / Experiments] Abstract and experimental setup: The central claim that categorical prior lock-in is a 'structural' property of ICL (distinct from numerical fidelity gains) is load-bearing on the assumption that the observed ceiling on rare classes generalizes beyond the tested conditions. However, the described experiments are restricted to two 7B-parameter models on high-cardinality tabular data with no ablations on prompt serialization formats, model scale, or lower-cardinality/non-tabular structured data; this leaves the structural interpretation dependent on those unvaried choices and does not rule out artifacts of scale, format, or data cardinality.
- [Abstract] Abstract: The claim of a 'sharp ceiling' and complete failure to reproduce rare classes is presented without any quantitative results, dataset cardinalities, prompt templates, number of shots, or statistical tests. This absence prevents evaluation of whether the data support the distinction between numerical improvement and categorical lock-in, making the empirical observation unevaluable from the provided summary.
minor comments (1)
- [Abstract] The abstract states the LoRA comparison but supplies no details on the LoRA rank, target modules, or memorization metrics used; these should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope of our claims. We respond to each major comment below and indicate revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental setup: The central claim that categorical prior lock-in is a 'structural' property of ICL (distinct from numerical fidelity gains) is load-bearing on the assumption that the observed ceiling on rare classes generalizes beyond the tested conditions. However, the described experiments are restricted to two 7B-parameter models on high-cardinality tabular data with no ablations on prompt serialization formats, model scale, or lower-cardinality/non-tabular structured data; this leaves the structural interpretation dependent on those unvaried choices and does not rule out artifacts of scale, format, or data cardinality.
Authors: We agree that the experiments are scoped to two 7B models and high-cardinality tabular data, and that this limits strong claims of universality. The term 'structural' in the manuscript is intended to highlight the consistent distinction between ICL's numerical adaptation and its failure on categorical priors, in contrast to LoRA's behavior within the same experimental setup, rather than to assert invariance across all scales or data types. We will revise the abstract and discussion to explicitly qualify the scope, add a limitations paragraph noting the absence of ablations on serialization formats, model scale, and non-tabular data, and avoid language implying broader generalization without further evidence. revision: partial
-
Referee: [Abstract] Abstract: The claim of a 'sharp ceiling' and complete failure to reproduce rare classes is presented without any quantitative results, dataset cardinalities, prompt templates, number of shots, or statistical tests. This absence prevents evaluation of whether the data support the distinction between numerical improvement and categorical lock-in, making the empirical observation unevaluable from the provided summary.
Authors: We accept this criticism. The abstract as written does not include the requested quantitative anchors. We will revise the abstract to report key details including the dataset cardinalities (e.g., number of categories per column), number of shots tested, the observed reproduction rates for rare classes under ICL (including the reported ceiling), and any statistical measures used to quantify the numerical vs. categorical distinction. revision: yes
Circularity Check
No circularity: purely empirical observation with no derivation or load-bearing self-citation.
full rationale
The paper reports experimental results on ICL behavior with tabular data across two 7B models. The central claim (sharp ceiling on categorical distributions despite numerical gains) is presented as a direct observation from those runs, with no equations, fitted parameters renamed as predictions, or self-citation chains invoked to justify a structural property. No load-bearing step reduces to its own inputs by construction. This matches the reader's 0.0 assessment.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-cardinality tabular data constitutes a controlled test case that reveals a general structural failure of ICL for structured generation under distribution mismatch.
Reference graph
Works this paper leans on
- [1]
-
[2]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [3]
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 [cs.CL] https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.06825...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [6]
-
[7]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
Aivin V . Solatorio and Olivier Dupriez. 2023. REaLTabFormer: Generating Realistic Relational and Tabular Data using Transformers. arXiv:2302.02041 [cs.LG] https://arxiv.org/abs/2302.02041
-
[10]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y . Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V . Le. 2022. Finetuned Language Models Are Zero-Shot Learners. arXiv:2109.01652 [cs.CL] https://arxiv.org/abs/2109.01652
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [11]
- [12]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.