Reinforcement Learning Disrupts Gradient-Based Adversarial Optimization
Pith reviewed 2026-06-27 10:14 UTC · model grok-4.3
The pith
Reinforcement learning training produces classifiers with unstable gradient directions and smaller magnitudes that block gradient-based adversarial attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training classifiers with policy-gradient objectives and epsilon-greedy exploration, the resulting models exhibit highly unstable gradient directions and smaller gradient magnitudes, which together render each step in gradient-based attacks like PGD both unreliable in direction and limited in effect, causing the attacks to fail within practical iteration limits.
What carries the argument
RL acting as an implicit regularizer that produces unstable gradient directions and smaller magnitudes.
If this is right
- RL training alone supplies a gradient-level defense by degrading the directional and magnitude information available to attackers.
- RL combined with adversarial training supplies a dual defense operating at both gradient and decision-boundary levels.
- The combined RL-adv approach outperforms standard adversarial training on PGD, AutoAttack, transfer-based, and query-based attacks.
- The gradient disruption holds across CIFAR-10, CIFAR-100, ImageNet-100 and multiple model architectures.
Where Pith is reading between the lines
- Hybrid training schedules that begin with supervised learning and later incorporate RL could combine training speed with the observed gradient regularization.
- The same instability mechanism may affect other optimization-based attacks that rely on consistent gradient directions.
- If RL training becomes widespread, attackers would likely shift emphasis toward non-gradient query or transfer methods.
- Repeating the gradient analysis on non-image tasks would test whether the regularization effect depends on the image-classification setting.
Load-bearing premise
The gradient instability and attack failure arise specifically from the reinforcement learning training objective rather than from hyperparameter choices, architecture, or dataset properties.
What would settle it
If PGD and AutoAttack achieve success rates on RL-trained models comparable to those on standard supervised models, that observation would falsify the claim that RL training disrupts gradient-based optimization.
Figures


read the original abstract
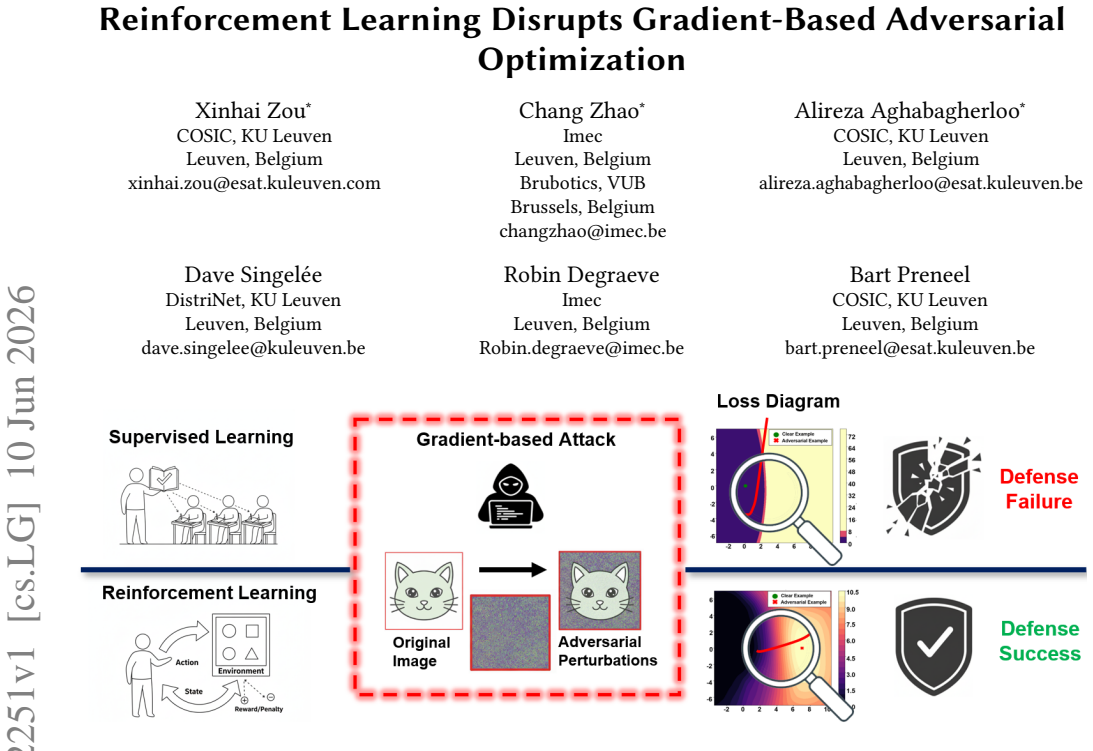
Gradient-based adversarial attacks remain a dominant threat to deep neural networks (DNNs), as they exploit gradient information to efficiently optimize adversarial perturbations. To address this, we investigate whether reinforcement learning (RL) training can disrupt the gradient structure used by attackers by training image classifiers with policy-gradient objectives and epsilon-greedy exploration. Through systematic experiments across CIFAR-10, CIFAR-100, and ImageNet-100 with multiple architectures, we find that RL-trained classifiers significantly disrupt gradient-based adversarial optimization. To explain this, we conduct a comprehensive mechanism analysis using loss landscape visualization, static and dynamic gradient indicators, and predictive entropy. Our analysis reveals that RL acts as an implicit regularizer, producing models with highly unstable gradient directions and smaller gradient magnitudes. This combination makes each PGD step both unreliable in direction and limited in magnitude, causing gradient-based attacks to fail within practical iteration budgets. We further show that combining RL with adversarial training (RL-adv) provides a dual-layer defense operating at two complementary levels: RL degrades gradient information available to attackers (gradient-level defense), while adversarial training strengthens decision boundaries (boundary-level defense). RL-adv achieves the highest robustness across all major attack types evaluated, including gradient-based (PGD, AutoAttack), transfer-based, and query-based attacks, outperforming SL-adv by a significant margin. These findings identify RL-induced gradient disruption as a complementary robustness mechanism and motivate future research on hybrid SL-RL training schedules that combine SL's efficiency with RL's gradient-regularization properties.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that training DNN image classifiers with reinforcement learning (policy-gradient objectives and epsilon-greedy exploration) disrupts gradient-based adversarial attacks by producing models with highly unstable gradient directions and smaller gradient magnitudes, which it attributes to RL acting as an implicit regularizer. Systematic experiments on CIFAR-10, CIFAR-100, and ImageNet-100 across multiple architectures show that RL-trained models cause PGD and AutoAttack to fail within practical budgets; combining RL with adversarial training (RL-adv) yields a dual defense (gradient-level plus boundary-level) that outperforms SL-adv on gradient-based, transfer-based, and query-based attacks. Mechanism analysis via loss landscapes, gradient indicators, and predictive entropy supports the explanation.
Significance. If the central attribution to the RL objective holds after proper isolation, the work identifies a complementary robustness mechanism (gradient disruption) that is distinct from standard adversarial training and motivates hybrid SL-RL schedules. The multi-dataset, multi-architecture experimental scope is a strength, as is the explicit framing of RL-adv as operating at two levels.
major comments (3)
- [mechanism analysis / experimental setup] Mechanism analysis and experimental setup: The claim that policy-gradient + epsilon-greedy training (rather than architecture, dataset, or hyperparameter choices) produces the reported unstable gradient directions and reduced magnitudes requires matched SL controls that hold all other factors fixed while swapping only the objective. The abstract and described experiments do not confirm such isolation was performed; without it, the attribution that RL disrupts gradient-based optimization cannot be separated from potential confounders.
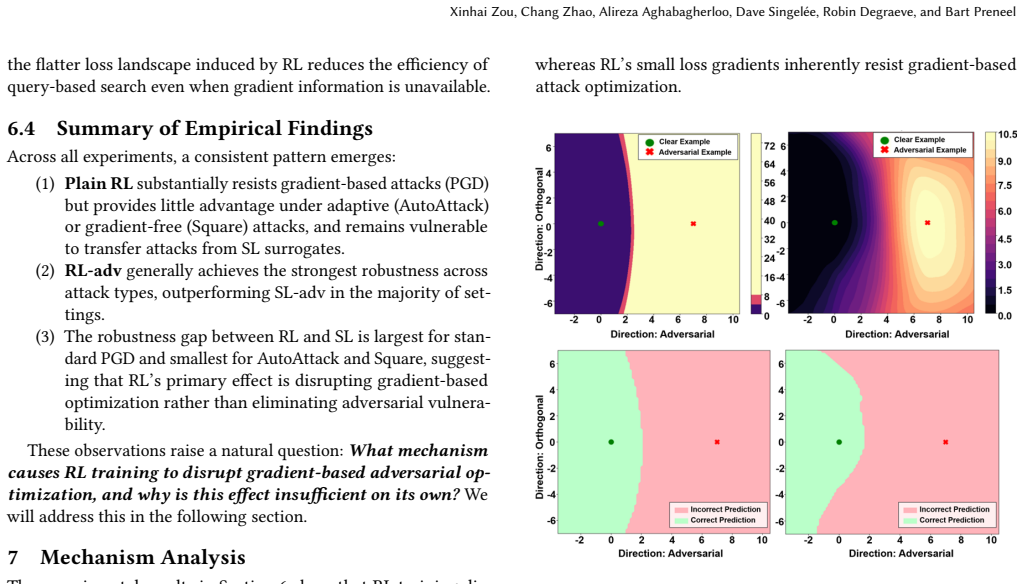
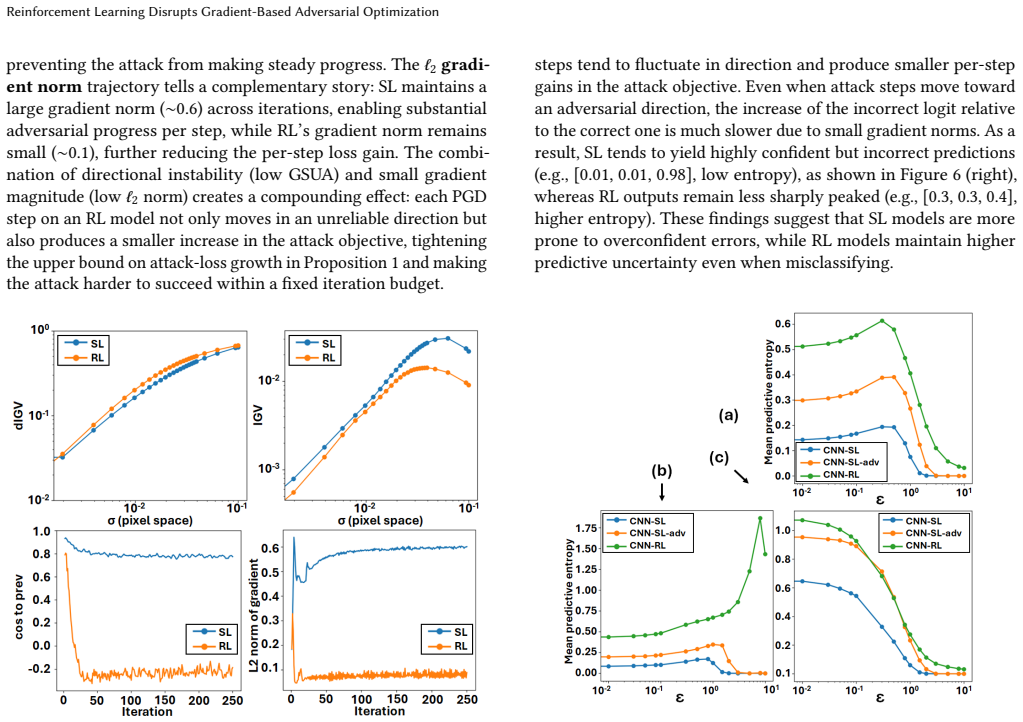
- [mechanism analysis / abstract] Results and mechanism analysis: The statements that RL produces 'highly unstable gradient directions' and 'smaller gradient magnitudes' rest on visualizations and indicators whose quantitative support (exact metrics, number of runs, statistical controls) is not specified; the abstract notes systematic experiments but provides no details on baseline comparisons or post-hoc analysis choices, which is load-bearing for the central claim that these properties cause attack failure.
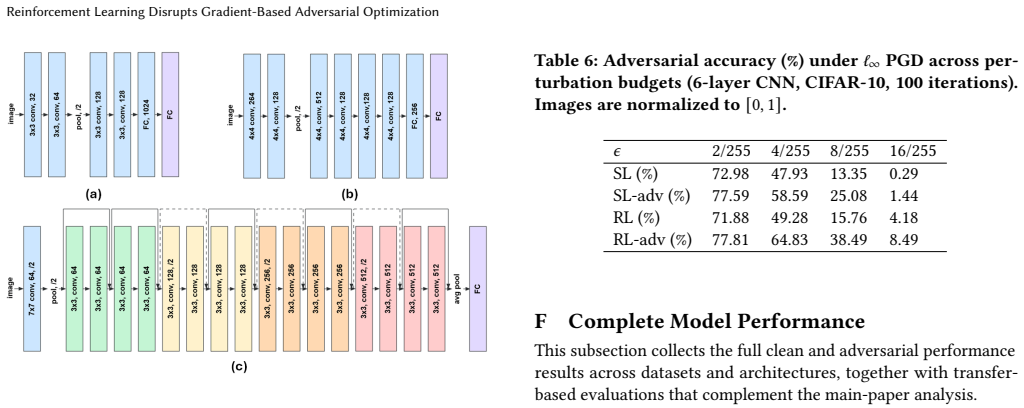
- [results on RL-adv] RL-adv results: The claim that RL-adv 'outperforms SL-adv by a significant margin' across attack types needs explicit reporting of the number of independent runs, variance, and statistical tests; absent these, the dual-layer defense conclusion rests on potentially under-controlled comparisons.
minor comments (1)
- [abstract] The abstract would benefit from a brief statement of the number of architectures, runs per experiment, and the precise set of gradient indicators used in the mechanism analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the experimental isolation, quantitative details, and statistical reporting.
read point-by-point responses
-
Referee: [mechanism analysis / experimental setup] Mechanism analysis and experimental setup: The claim that policy-gradient + epsilon-greedy training (rather than architecture, dataset, or hyperparameter choices) produces the reported unstable gradient directions and reduced magnitudes requires matched SL controls that hold all other factors fixed while swapping only the objective. The abstract and described experiments do not confirm such isolation was performed; without it, the attribution that RL disrupts gradient-based optimization cannot be separated from potential confounders.
Authors: We agree that explicit isolation of the RL objective is essential to support the attribution. Our experiments held architecture, dataset, and training regime as comparable as possible, with the objective as the primary variable, but we acknowledge that more tightly matched SL controls are needed. We will add dedicated ablation experiments with only the objective swapped in the revised manuscript. revision: yes
-
Referee: [mechanism analysis / abstract] Results and mechanism analysis: The statements that RL produces 'highly unstable gradient directions' and 'smaller gradient magnitudes' rest on visualizations and indicators whose quantitative support (exact metrics, number of runs, statistical controls) is not specified; the abstract notes systematic experiments but provides no details on baseline comparisons or post-hoc analysis choices, which is load-bearing for the central claim that these properties cause attack failure.
Authors: We will expand the mechanism analysis with explicit quantitative metrics (e.g., gradient cosine similarity variance and L2 magnitudes averaged over samples), report the number of runs performed, and include statistical controls. These details will be added to the relevant sections and referenced in the abstract. revision: yes
-
Referee: [results on RL-adv] RL-adv results: The claim that RL-adv 'outperforms SL-adv by a significant margin' across attack types needs explicit reporting of the number of independent runs, variance, and statistical tests; absent these, the dual-layer defense conclusion rests on potentially under-controlled comparisons.
Authors: We agree that rigorous statistical reporting is required. The revision will include the number of independent runs, means with standard deviations, and statistical tests (such as paired t-tests) for the RL-adv versus SL-adv comparisons across attack types. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivations or self-referential reductions
full rationale
The paper reports experimental outcomes from training RL classifiers (policy-gradient + epsilon-greedy) versus supervised baselines across datasets and architectures, followed by post-hoc mechanism analysis via loss landscapes, gradient indicators, and entropy. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citations are invoked to derive the central robustness claims; results are presented as direct measurements. The skeptic concern about confounding factors is a question of experimental controls and attribution strength, not a reduction of any claimed derivation to its own inputs by construction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard deep learning assumptions hold, including that training and test distributions are similar and that gradient-based optimization behaves as expected on the loss surfaces examined.
Reference graph
Works this paper leans on
-
[1]
Chirag Agarwal, Daniel D’souza, and Sara Hooker. 2022. Estimating Example Difficulty Using Variance of Gradients. In 2022 IEEE. InCVF Conference on Computer Vision and Pattern Recognition (CVPR). 10358–10368
2022
-
[2]
Alireza Aghabagherloo, Aydin Abadi, Sumanta Sarkar, Vishnu Asutosh Dasu, and Bart Preneel. 2025. Impact of Data Duplication on Deep Neural Network-Based Image Classifiers: Robust vs. Standard Models. In2025 IEEE Security and Privacy Workshops (SPW). 177–183. doi:10.1109/SPW67851.2025.00023
-
[3]
Alireza Aghabagherloo, Rafa Gálvez, Davy Preuveneers, and Bart Preneel. 2023. On the Brittleness of Robust Features: An Exploratory Analysis of Model Robust- ness and Illusionary Robust Features. In2023 IEEE Security and Privacy Workshops (SPW). 38–44. doi:10.1109/SPW59333.2023.00009
-
[4]
Alireza Aghabagherloo, Rafa Gálvez, Davy Preuveneers, and Bart Preneel
-
[5]
doi:10.1109/ACCESS.2025.3604636
Unveiling Illusionary Robust Features: A Novel Approach for Adver- sarial Defenses in Deep Neural Networks.IEEE Access13 (2025), 154678–154694. doi:10.1109/ACCESS.2025.3604636
-
[6]
Naveed Akhtar and Ajmal Mian. 2018. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey.IEEE Access6 (2018), 14410–14430. doi:10.1109/ACCESS.2018.2807385
-
[7]
Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion, and Matthias Hein. 2020. Square attack: a query-efficient black-box adversarial attack via random search. InEuropean conference on computer vision. Springer, 484–501
2020
-
[8]
Anish Athalye, Nicholas Carlini, and David Wagner. 2018. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. InInternational Conference on Machine Learning. PMLR, 274–283
2018
-
[9]
Battista Biggio and Fabio Roli. 2018. Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning.Pattern Recognition84 (2018), 317–331. doi:10. 1016/j.patcog.2018.07.023
2018
-
[10]
Christopher M. Bishop. 1995. Training with Noise Is Equivalent to Tikhonov Regularization.Neural Computation7, 1 (1995), 108–116. doi:10.1162/neco.1995. 7.1.108
-
[11]
Nicholas Carlini and David Wagner. 2017. Towards Evaluating the Robustness of Neural Networks. In2017 Ieee Symposium on Security and Privacy (Sp). Ieee, 39–57
2017
-
[12]
Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. 2017. Zoo: Zeroth Order Optimization Based Black-Box Attacks to Deep Neural Networks without Training Substitute Models. InProceedings of the 10th ACM Workshop on Artificial Intelligence and Security. 15–26
2017
-
[13]
Zico Kolter
Jeremy Cohen, Elan Rosenfeld, and J. Zico Kolter. 2019. Certified Adversarial Ro- bustness via Randomized Smoothing. InProceedings of the 36th International Con- ference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97). PMLR, 1310–1320
2019
-
[14]
Francesco Croce and Matthias Hein. 2020. Minimally distorted adversarial examples with a fast adaptive boundary attack. InInternational conference on machine learning. PMLR, 2196–2205
2020
-
[15]
Francesco Croce and Matthias Hein. 2020. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. InInternational conference on machine learning. PMLR, 2206–2216
2020
-
[16]
Zhengjie Deng, Wen Xiao, Xiyan Li, Shuqian He, and Yizhen Wang. 2023. En- hancing the Transferability of Targeted Attacks with Adversarial Perturbation Transform.Electronics12, 18 (2023), 3895
2023
-
[17]
Esther Derman and Shie Mannor. 2020. Distributional Robustness and Regu- larization in Reinforcement Learning.arXiv preprint arXiv:2003.02894(2020). arXiv:2003.02894 Reinforcement Learning Disrupts Gradient-Based Adversarial Optimization
arXiv 2020
-
[18]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2020. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale.arXiv preprint arXiv:2010.11929(2020). arXiv:2010.11929
Pith/arXiv arXiv 2020
-
[19]
Cornelius Emde, Francesco Pinto, Thomas Lukasiewicz, Philip HS Torr, and Adel Bibi. 2024. Towards Certification of Uncertainty Calibration under Adversarial Attacks.arXiv preprint arXiv:2405.13922(2024). arXiv:2405.13922
arXiv 2024
-
[20]
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. 2018. Robust Physical- World Attacks on Deep Learning Visual Classification. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2018
-
[21]
Alhussein Fawzi, Seyed-Mohsen Moosavi-Dezfooli, Pascal Frossard, and Stefano Soatto. 2018. Empirical Study of the Topology and Geometry of Deep Networks. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, 3762–3770
2018
-
[22]
Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. 2015. Model Inversion Attacks That Exploit Confidence Information and Basic Countermeasures. InPro- ceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. 1322–1333
2015
-
[23]
Adam Gleave, Michael Dennis, Cody Wild, Neel Kant, Sergey Levine, and Stuart Russell. 2020. Adversarial Policies: Attacking Deep Reinforcement Learning. In International Conference on Learning Representations (ICLR)
2020
-
[24]
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014. Explaining and Harnessing Adversarial Examples.arXiv preprint arXiv:1412.6572(2014). arXiv:1412.6572
Pith/arXiv arXiv 2014
-
[25]
Shixiang Gu, Timothy Lillicrap, Zoubin Ghahramani, Richard E Turner, and Sergey Levine. 2016. Q-prop: Sample-efficient policy gradient with an off-policy critic.arXiv preprint arXiv:1611.02247(2016)
Pith/arXiv arXiv 2016
-
[26]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. InProceedings of the IEEE International Conference on Computer Vision. 1026– 1034
2015
-
[27]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Resid- ual Learning for Image Recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 770–778
2016
-
[28]
Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan
Dan Hendrycks, Norman Mu, Ekin D. Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan. 2020. AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty. InInternational Conference on Learning Representations (ICLR)
2020
-
[29]
Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. 2019. Adversarial Examples Are Not Bugs, They Are Features.Advances in neural information processing systems32 (2019)
2019
-
[30]
Jaromír Janisch, Tomáš Pevný, and Viliam Lisý. 2020. Classification with Costly Features as a Sequential Decision-Making Problem.Machine Learning(2020). doi:10.1007/s10994-020-05874-8
-
[31]
Anna-Kathrin Kopetzki, Bertrand Charpentier, Daniel Zügner, Sandhya Giri, and Stephan Günnemann. 2021. Evaluating Robustness of Predictive Uncertainty Estimation: Are Dirichlet-based Models Reliable?. InInternational Conference on Machine Learning. PMLR, 5707–5718
2021
-
[32]
Alex Krizhevsky and Geoffrey Hinton. 2009. Learning Multiple Layers of Features from Tiny Images
2009
-
[33]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. Imagenet Classifica- tion with Deep Convolutional Neural Networks.Advances in neural information processing systems25 (2012)
2012
-
[34]
Alexey Kurakin, Ian Goodfellow, and Samy Bengio. 2017. Adversarial Machine Learning at Scale. InInternational Conference on Learning Representations (ICLR)
2017
-
[35]
Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. 2016. End-to-End Training of Deep Visuomotor Policies.Journal of Machine Learning Research17, 39 (2016), 1–40
2016
-
[36]
Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. 2018. Visualizing the Loss Landscape of Neural Nets.Advances in neural information processing systems31 (2018)
2018
-
[37]
Chen Liu, Mathieu Salzmann, Tao Lin, Ryota Tomioka, and Sabine Süsstrunk
-
[38]
On the Loss Landscape of Adversarial Training: Identifying Challenges and How to Overcome Them.Advances in Neural Information Processing Systems 33 (2020), 21476–21487
2020
-
[39]
Xuannan Liu, Yaoyao Zhong, Yuhang Zhang, Lixiong Qin, and Weihong Deng
-
[40]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Enhancing Generalization of Universal Adversarial Perturbation through Gradient Aggregation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 4435–4444
-
[41]
Dario Lütjens, Michael Everett, and Jonathan P. How. 2020. Certified Adversarial Robustness for Deep Reinforcement Learning. InProceedings of the 2nd Conference on Learning for Dynamics and Control (L4DC) (Proceedings of Machine Learning Research, Vol. 100). PMLR
2020
-
[42]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2017. Towards deep learning models resistant to adversarial attacks.arXiv preprint arXiv:1706.06083(2017)
Pith/arXiv arXiv 2017
-
[43]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards Deep Learning Models Resistant to Adversarial Attacks. InInternational Conference on Learning Representations (ICLR)
2018
-
[44]
and Veness, Joel and Bellemare, Marc G
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. 2015. Human-Level Control through Deep Reinforce...
-
[45]
Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, and Pascal Frossard. 2016. Deepfool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2574–2582
2016
-
[46]
Arnab Nilim and Laurent El Ghaoui. 2005. Robust Control of Markov Decision Processes with Uncertain Transition Matrices.Operations Research53, 5 (2005), 780–798. doi:10.1287/opre.1050.0216
-
[47]
Mesut Ozdag. 2018. Adversarial Attacks and Defenses against Deep Neural Networks: A Survey.Procedia Computer Science140 (2018), 152–161
2018
-
[48]
Nicolas Papernot, Fartash Faghri, Nicholas Carlini, Ian Goodfellow, Reuben Feinman, Alexey Kurakin, Cihang Xie, Yash Sharma, Tom Brown, Aurko Roy, Alexander Matyasko, Vahid Behzadan, Karen Hambardzumyan, Zhishuai Zhang, Yi-Lin Juang, Zhi Li, Ryan Sheatsley, Abhibhav Garg, Jonathan Uesato, Willi Gierke, Yinpeng Dong, David Berthelot, Paul Hendricks, Jonas ...
Pith/arXiv arXiv 2018
-
[49]
Lerrel Pinto, James Davidson, Rahul Sukthankar, and Abhinav Gupta. 2017. Ro- bust Adversarial Reinforcement Learning. InProceedings of the 34th International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Re- search, Vol. 70). PMLR, 2817–2826
2017
-
[50]
Yao Qin, Xuezhi Wang, Alex Beutel, and Ed Chi. 2021. Improving Calibration through the Relationship with Adversarial Robustness.Advances in Neural Information Processing Systems34 (2021), 14358–14369
2021
-
[51]
Aravind Rajeswaran, Sarvjeet Ghotra, Balaraman Ravindran, and Sergey Levine
-
[52]
InInternational Conference on Learning Representations (ICLR)
EPOpt: Learning Robust Neural Network Policies Using Model Ensembles. InInternational Conference on Learning Representations (ICLR)
-
[53]
Ram Ramrakhya, Dhruv Batra, Erik Wijmans, and Abhishek Das. 2023. Pirlnav: Pretraining with imitation and rl finetuning for objectnav. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 17896–17906
2023
-
[54]
Marc’Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba
-
[55]
Sequence level training with recurrent neural networks.arXiv preprint arXiv:1511.06732(2015)
Pith/arXiv arXiv 2015
-
[56]
Johannes Schneider and Giovanni Apruzzese. 2023. Dual Adversarial Attacks: Fooling Humans and Classifiers.J. Inf. Secur. Appl.75 (2023), 103502
2023
-
[57]
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel
-
[58]
High-dimensional continuous control using generalized advantage estima- tion.arXiv preprint arXiv:1506.02438(2015)
Pith/arXiv arXiv 2015
-
[59]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[60]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
Pith/arXiv arXiv 2017
-
[61]
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Membership Inference Attacks Against Machine Learning Models. In2017 IEEE Symposium on Security and Privacy (SP). 3–18
2017
-
[62]
Aman Sinha, Hongseok Namkoong, Riccardo Volpi, and John Duchi. 2017. Certi- fying some distributional robustness with principled adversarial training.arXiv preprint arXiv:1710.10571(2017)
arXiv 2017
-
[63]
Lewis Smith and Yarin Gal. 2018. Understanding Measures of Uncertainty for Adversarial Example Detection.arXiv preprint arXiv:1803.08533(2018). arXiv:1803.08533
Pith/arXiv arXiv 2018
-
[64]
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. 2014. Intriguing Properties of Neural Networks. InInternational Conference on Learning Representations (ICLR)
2014
-
[65]
Yonglong Tian, Dilip Krishnan, and Phillip Isola. 2020. Contrastive Multiview Coding. InEuropean Conference on Computer Vision. Springer, 776–794
2020
-
[66]
Yusuke Tsuzuku, Issei Sato, and Masashi Sugiyama. 2018. Lipschitz-margin train- ing: Scalable certification of perturbation invariance for deep neural networks. Advances in neural information processing systems31 (2018)
2018
-
[67]
Xiaosen Wang and Kun He. 2021. Enhancing the Transferability of Adversarial Attacks through Variance Tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1924–1933
2021
-
[68]
Wolfram Wiesemann, Daniel Kuhn, and Berç Rustem. 2013. Robust Markov Decision Processes.Mathematics of Operations Research38, 1 (2013), 153–183. doi:10.1287/moor.1120.0566
-
[69]
Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine learning8, 3 (1992), 229–256
1992
-
[70]
Baoyuan Wu, Shaokui Wei, Mingli Zhu, Meixi Zheng, Zihao Zhu, Mingda Zhang, Hongrui Chen, Danni Yuan, Li Liu, and Qingshan Liu. 2023. Defenses in Ad- versarial Machine Learning: A Survey.arXiv preprint arXiv:2312.08890(2023). arXiv:2312.08890 Xinhai Zou, Chang Zhao, Alireza Aghabagherloo, Dave Singelée, Robin Degraeve, and Bart Preneel
arXiv 2023
-
[71]
Jingjing Xu, Liang Zhao, Hanqi Yan, Qi Zeng, Yun Liang, and Xu Sun. 2019. LexicalAT: Lexical-Based Adversarial Reinforcement Training for Robust Senti- ment Classification. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Assoc...
2019
-
[72]
Shojiro Yamabe, Kazuto Fukuchi, and Jun Sakuma. 2024. Robust Deep Reinforce- ment Learning against Adversarial Behavior Manipulation.OpenReview preprint (2024)
2024
-
[73]
Huan Zhang, Hongge Chen, Chaowei Xiao, Bo Li, Mingyan Liu, Duane Boning, and Cho-Jui Hsieh. 2020. Robust Deep Reinforcement Learning against Adver- sarial Perturbations on State Observations. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 33. 21024–21037
2020
-
[74]
Dauphin, and David Lopez-Paz
Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. 2018. Mixup: Beyond Empirical Risk Minimization. InInternational Conference on Learning Representations (ICLR)
2018
-
[75]
Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael Jordan. 2019. Theoretically Principled Trade-off between Robustness and Accuracy. InInternational Conference on Machine Learning. PMLR, 7472–7482
2019
-
[76]
Pinlong Zhao, Weiyao Zhu, Pengfei Jiao, Di Gao, and Ou Wu. 2025. Data Poi- soning in Deep Learning: A Survey.arXiv preprint arXiv:2503.22759(2025). arXiv:2503.22759 A Disambiguation of Epsilons To avoid ambiguity, we distinguish three different epsilon sym- bols used throughout the paper: the exploration rate in RL, the adversarial perturbation budget, an...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.