Which Models Are Our Models Built On? Auditing Invisible Dependencies in Modern LLMs
Pith reviewed 2026-06-27 09:56 UTC · model grok-4.3
The pith
An agentic system reconstructs hidden recursive dependency graphs of modern LLMs from scattered public artifacts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
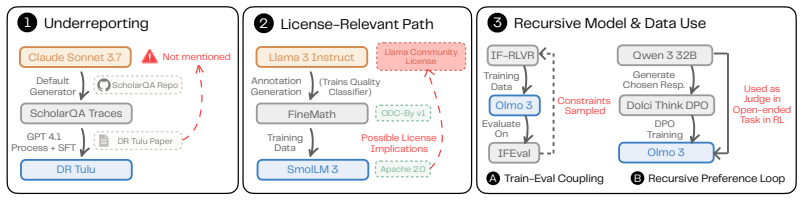
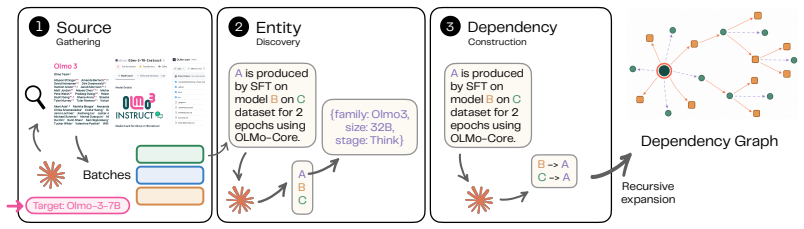
The paper claims that formalizing direct and indirect dependencies, representing pipeline roles through operation-centered relationships, and resolving artifact identities across names and versions allows an agentic system to recover 1,060 source-verified dependencies from four LLM releases and construct dependency graphs that reveal multi-hop license obligations, train-evaluation coupling, discrepancies between released and training-time artifacts, and documentation inconsistencies.
What carries the argument
ModSleuth, an agentic system that recursively reconstructs LLM dependency graphs from public artifacts with source-grounded evidence by distinguishing direct and indirect dependencies and reconciling references across inconsistent documentation.
Load-bearing premise
Public artifacts contain enough consistent, source-grounded information to allow accurate reconstruction of both direct and indirect dependencies without significant missing links or misidentified artifacts.
What would settle it
Manually compiling the complete dependency list for one of the four studied LLM releases from internal records and comparing it to the graph produced by ModSleuth to check whether more than 20 percent of links are missed or misidentified.
Figures
read the original abstract
Modern LLM training pipelines increasingly rely on other models to generate data, filter corpora, judge outputs, and guide development decisions. These dependencies are recursive: a model may depend on an upstream artifact whose own dependencies are documented only in separate releases and artifacts. As a result, the full dependency structure is fragmented across heterogeneous public artifacts, with complexity and recursive depth far outpacing humans' ability to trace. We introduce ModSleuth, an agentic system that recursively reconstructs LLM dependency graphs from public artifacts with source-grounded evidence. We find that the primary challenge is no longer information extraction, but defining what constitutes a dependency and reconciling artifact references across inconsistent documentation. We address these challenges through a formalization that distinguishes direct and indirect dependencies, represents heterogeneous pipeline roles through operation-centered relationships, and resolves artifact identities across names, versions, and repositories. Applying ModSleuth to four public-artifact-rich LLM releases, we recover 1,060 source-verified dependencies and construct large-scale dependency graphs of modern LLM development. These graphs reveal multi-hop license obligations, train-evaluation coupling, discrepancies between released and training-time artifacts, and documentation inconsistencies that would otherwise be difficult to uncover. We release ModSleuth and the resulting dependency graphs to support transparent analysis of the increasingly complex ecosystems underlying modern LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ModSleuth, an agentic system that recursively reconstructs LLM dependency graphs from public artifacts. It formalizes distinctions between direct and indirect dependencies, operation-centered roles, and cross-artifact identity resolution to address challenges of inconsistent documentation. Applied to four public-artifact-rich LLM releases, the system recovers 1,060 source-verified dependencies and constructs large-scale graphs that expose multi-hop license obligations, train-evaluation coupling, released vs. training-time discrepancies, and documentation inconsistencies. The work releases both the tool and the resulting graphs.
Significance. If the recovered dependencies prove accurate, the contribution supplies a concrete, reusable auditing tool and dataset for an increasingly opaque aspect of LLM development. Releasing ModSleuth and the dependency graphs is a clear strength that enables community verification and extension. The work directly targets a practical transparency gap rather than proposing new model architectures.
major comments (2)
- [Abstract] Abstract: the claim that ModSleuth recovers 1,060 source-verified dependencies is presented without any validation metrics, error rates, inter-annotator agreement, or manual audit of a sample of the recovered edges. Because the central empirical result rests on the accuracy of these recoveries, the absence of such evidence makes it impossible to assess whether the graphs are reliable or contain systematic misidentifications.
- [Abstract] Abstract and methods description: the paper states that the primary challenge is defining dependencies and reconciling inconsistent documentation rather than extraction, yet provides no quantitative breakdown of how many candidate references were discarded, how ambiguous cases were resolved, or what fraction of the 1,060 edges required human adjudication. This information is load-bearing for the claim that the formalization successfully handles the stated difficulties.
minor comments (1)
- [Abstract] The abstract uses the phrase 'source-grounded evidence' without defining the precise criteria that qualify an artifact reference as source-grounded.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit validation and process metrics around the recovered dependencies. Both comments correctly identify gaps in the current presentation; we will revise the manuscript to include the requested evidence and breakdowns.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that ModSleuth recovers 1,060 source-verified dependencies is presented without any validation metrics, error rates, inter-annotator agreement, or manual audit of a sample of the recovered edges. Because the central empirical result rests on the accuracy of these recoveries, the absence of such evidence makes it impossible to assess whether the graphs are reliable or contain systematic misidentifications.
Authors: We agree that the abstract and main text must report validation evidence for the 1,060 edges. 'Source-verified' in the current draft means each edge is backed by an explicit citation or mention in a released artifact, but this does not substitute for quantitative accuracy assessment. We will add a dedicated validation subsection (and update the abstract) that reports: (1) a random sample of 150 edges manually audited by two authors with inter-annotator agreement, (2) precision/recall against a gold set of 50 known dependencies, and (3) any observed error patterns. This addresses the reliability concern directly. revision: yes
-
Referee: [Abstract] Abstract and methods description: the paper states that the primary challenge is defining dependencies and reconciling inconsistent documentation rather than extraction, yet provides no quantitative breakdown of how many candidate references were discarded, how ambiguous cases were resolved, or what fraction of the 1,060 edges required human adjudication. This information is load-bearing for the claim that the formalization successfully handles the stated difficulties.
Authors: The referee is correct that the current draft lacks these process statistics. We will insert a new 'Annotation and Resolution Statistics' paragraph (and corresponding table) that reports: total candidate references extracted before filtering, number and categories of discarded references with reasons, number of ambiguous cases escalated to human review, and the exact fraction of the final 1,060 edges that required adjudication. This will make the claim about the formalization's effectiveness quantitatively testable. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents ModSleuth as an empirical agentic system for reconstructing LLM dependency graphs from heterogeneous public artifacts. Its core output is the recovery of 1,060 source-verified dependencies across four releases and the resulting graphs; the contribution consists of formalizing direct/indirect distinctions, operation-centered roles, and cross-artifact identity resolution to address documentation inconsistencies. No equations, fitted parameters presented as predictions, self-definitional reductions, or load-bearing self-citations appear in the described derivation chain. The work is a tool-construction and auditing effort whose claims rest on the application to external artifacts rather than any internal loop that reduces outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydlícek, Agustín Piqueres Lajarín, Vaibhav Srivastav, Joshua Lochner, Caleb Fahlgren, Xuan-Son Nguyen, Clémentine Fourrier, Ben Burtenshaw, Hugo Larcher, Haojun Zhao, Cyril Zakka, Mathieu Morlon, Colin Raffel, Leandro von Werr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Claude 3.7 Sonnet and Claude Code, February 2025
Anthropic. Claude 3.7 Sonnet and Claude Code, February 2025
2025
-
[3]
Claude code documentation
Anthropic. Claude code documentation. https://code.claude.com/docs/en/overview, 2026
2026
-
[4]
Introducing Claude Opus 4.7, April 2026
Anthropic. Introducing Claude Opus 4.7, April 2026
2026
-
[5]
Introducing Claude Sonnet 4.6, February 2026
Anthropic. Introducing Claude Sonnet 4.6, February 2026
2026
-
[6]
SmolLM3: smol, multilingual, long-context reasoner.https://huggingface.co/blog/smollm3, 2025
Elie Bakouch, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Lewis Tunstall, Car- los Miguel Patiño, Edward Beeching, Aymeric Roucher, Aksel Joonas Reedi, Quentin Gal- louédec, Kashif Rasul, Nathan Habib, Clémentine Fourrier, Hynek Kydlicek, Guilherme Penedo, Hugo Larcher, Mathieu Morlon, Vaibhav Srivastav, Joshua Lochner, Xuan-Son Nguyen, Colin Raffel, ...
2025
-
[7]
Nougat: Neural optical understanding for academic documents
Lukas Blecher, Guillem Cucurull, Thomas Scialom, and Robert Stojnic. Nougat: Neural optical understanding for academic documents. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[8]
The 2024 foundation model transparency index.Trans
Rishi Bommasani, Kevin Klyman, Sayash Kapoor, Shayne Longpre, Betty Xiong, Nestor Maslej, and Percy Liang. The 2024 foundation model transparency index.Trans. Mach. Learn. Res., 2025, 2025
2024
-
[9]
Liao, Kathleen A
Rishi Bommasani, Dilara Soylu, Thomas I. Liao, Kathleen A. Creel, and Percy Liang. Ecosystem graphs: Documenting the foundation model supply chain. InProceedings of the 2024 AAAI/ACM Conference on AI, Ethics, and Society, AIES ’24, page 196–209. AAAI Press, 2025
2024
-
[10]
and its affiliates
Cisco Systems, Inc. and its affiliates. Model provenance kit, 2026. Deep-signal fingerprints (CC BY 4.0) may be distributed separately on the Hugging Face Hub
2026
-
[11]
Alex Cloud, Minh Le, James Chua, Jan Betley, Anna Sztyber-Betley, Jacob Hilton, Samuel Marks, and Owain Evans. Subliminal learning: Language models transmit behavioral traits via hidden signals in data.CoRR, abs/2507.14805, 2025
-
[12]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.CoRR, abs/2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
ULTRAFEEDBACK: boosting language models with scaled AI feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. ULTRAFEEDBACK: boosting language models with scaled AI feedback. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty- ...
2024
-
[14]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models.CoRR, abs/2512.02556, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee F. Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, Shane Arora,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Rewriting pre-training data boosts LLM performance in math and code.CoRR, abs/2505.02881, 2025
Kazuki Fujii, Yukito Tajima, Sakae Mizuki, Hinari Shimada, Taihei Shiotani, Koshiro Saito, Masanari Ohi, Masaki Kawamura, Taishi Nakamura, Takumi Okamoto, Shigeki Ishida, Kakeru Hattori, Youmi Ma, Hiroya Takamura, Rio Yokota, and Naoaki Okazaki. Rewriting pre-training data boosts LLM performance in math and code.CoRR, abs/2505.02881, 2025
-
[17]
Wallach, Hal Daumé III, and Kate Crawford
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna M. Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Commun. ACM, 64(12):86– 92, 2021
2021
-
[18]
Gemini 3.1 pro model card, February 2026
Google DeepMind. Gemini 3.1 pro model card, February 2026
2026
-
[19]
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tau- man Kalai, Yin Tat Lee, and Yuanzhi Li. Textbooks are all you need.CoRR, abs/2306.11644, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
2025
-
[21]
Introducing Marin: An open lab for building foundation models
David Hall, Ahmed Ahmed, Christopher Chou, Abhinav Garg, Rohith Kuditipudi, Will Held, Nikil Ravi, Herumb Shandilya, Jason Wang, Jason Bolton, Siddharth Karamcheti, Suhas 14 Kotha, Tony Lee, Nelson Liu, Joel Niklaus, Ashwin Ramaswami, Kamyar Salahi, Kaiyue Wen, Chi Heem Wong, Sherry Yang, Ivan Zhou, and Percy Liang. Introducing Marin: An open lab for buil...
2025
-
[22]
Skywork open reasoner 1 technical report, 2025
Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, Siyuan Li, Liang Zeng, Tianwen Wei, Cheng Cheng, Bo An, Yang Liu, and Yahui Zhou. Skywork open reasoner 1 technical report, 2025
2025
-
[23]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
2021
-
[24]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Joaquin Vanschoren and Sai-Kit Yeung, editors,Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021...
2021
-
[25]
Teaching machines to read and comprehend
Karl Moritz Hermann, Tomáš Koˇciský, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. InProceedings of the 29th International Conference on Neural Information Processing Systems - Volume 1, NIPS’15, page 1693–1701, Cambridge, MA, USA, 2015. MIT Press
2015
-
[26]
We should chart an atlas of all the world’s models
Eliahu Horwitz, Nitzan Kurer, Jonathan Kahana, Liel Amar, and Yedid Hoshen. We should chart an atlas of all the world’s models. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems Position Paper Track, 2025
2025
-
[27]
Unsupervised model tree heritage recovery
Eliahu Horwitz, Asaf Shul, and Yedid Hoshen. Unsupervised model tree heritage recovery. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
2025
-
[28]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-coder technical report.CoRR, abs/2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [29]
-
[30]
Jaehun Jung, Seungju Han, Ximing Lu, Skyler Hallinan, David Acuna, Shrimai Prabhumoye, Mostafa Patwary, Mohammad Shoeybi, Bryan Catanzaro, and Yejin Choi. Prismatic syn- thesis: Gradient-based data diversification boosts generalization in LLM reasoning.CoRR, abs/2505.20161, 2025
-
[31]
Jaekyeom Kim, Sungryull Sohn, Gerrard Jeongwon Jo, Jihoon Choi, Kyunghoon Bae, Hway- oung Lee, Yongmin Park, and Honglak Lee. Do not trust licenses you see: Dataset compliance requires massive-scale ai-powered lifecycle tracing.CoRR, abs/2503.02784, 2025
-
[32]
Blackbox model provenance via palimpsestic membership inference
Rohith Kuditipudi, Jing Huang, Sally Zhu, Diyi Yang, Christopher Potts, and Percy Liang. Blackbox model provenance via palimpsestic membership inference. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[33]
Preference leakage: A contamination problem in llm-as-a-judge
Dawei Li, Renliang Sun, Yue Huang, Ming Zhong, Bohan Jiang, Jiawei Han, Xiangliang Zhang, Wei Wang, and Huan Liu. Preference leakage: A contamination problem in llm-as-a-judge. CoRR, abs/2502.01534, 2025
-
[34]
Tracing the Roots: A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs
Yu Li, Xiaoran Shang, Qizhi Pei, Yun Zhu, Xin Gao, Honglin Lin, Zhanping Zhong, Zhuoshi Pan, Zheng Liu, Xiaoyang Wang, et al. Tracing the roots: A multi-agent framework for uncovering data lineage in post-training llms.arXiv preprint arXiv:2604.10480, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Systematic analysis of 32,111 ai model cards characterizes documentation practice in ai.Nature Machine Intelligence, 6(7):744–753, 2024
Weixin Liang, Nazneen Rajani, Xinyu Yang, Ezinwanne Ozoani, Eric Wu, Yiqun Chen, Daniel Scott Smith, and James Zou. Systematic analysis of 32,111 ai model cards characterizes documentation practice in ai.Nature Machine Intelligence, 6(7):744–753, 2024. 15
2024
-
[36]
Tinygsm: achieving >80% on gsm8k with small language models
Bingbin Liu, Sébastien Bubeck, Ronen Eldan, Janardhan Kulkarni, Yuanzhi Li, Anh Nguyen, Rachel Ward, and Yi Zhang. Tinygsm: achieving >80% on gsm8k with small language models. CoRR, abs/2312.09241, 2023
-
[37]
G- eval: NLG evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G- eval: NLG evaluation using gpt-4 with better human alignment. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore, December 2023. Association for Computational...
2023
-
[38]
A large- scale audit of dataset licensing and attribution in ai.Nature Machine Intelligence, 6(8):975–987, 2024
Shayne Longpre, Robert Mahari, Anthony Chen, Naana Obeng-Marnu, Damien Sileo, William Brannon, Niklas Muennighoff, Nathan Khazam, Jad Kabbara, Kartik Perisetla, et al. A large- scale audit of dataset licensing and attribution in ai.Nature Machine Intelligence, 6(8):975–987, 2024
2024
-
[39]
Model cards for model reporting
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchin- son, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. In danah boyd and Jamie H. Morgenstern, editors,Proceedings of the Conference on Fairness, Accountability, and Transparency, FAT* 2019, Atlanta, GA, USA, January 29-31, 201...
2019
-
[40]
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of GPT-4. CoRR, abs/2306.02707, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
NVIDIA, :, Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, Aditya Vavre, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, Aleksandr Shaposhnikov, Alex Kondratenko, Alexander Bukharin, Alexandre Milesi, Ali Taghibakhshi, Alisa Liu, Amelia Barton, Ameya Sunil Mahabaleshwarkar, Amir Klein, Amit Zuker, A...
2025
-
[42]
NVIDIA, :, Aakshita Chandiramani, Aaron Blakeman, Abdullahi Olaoye, Abhibha Gupta, Abhilash Somasamudramath, Abhinav Khattar, Adeola Adesoba, Adi Renduchintala, Adil Asif, Aditya Agrawal, Aditya Vavre, Ahmad Kiswani, Aishwarya Padmakumar, Ajay Hotchandani, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, Aleksandr Shaposhnikov, Alex Gron- skiy, Alex K...
2026
-
[43]
Nemotron 3 nano omni: Efficient and open multimodal intelligence, 2026
NVIDIA, :, Amala Sanjay Deshmukh, Kateryna Chumachenko, Tuomas Rintamaki, Matthieu Le, Tyler Poon, Danial Mohseni Taheri, Ilia Karmanov, Guilin Liu, Jarno Seppanen, Arushi Goel, Mike Ranzinger, Greg Heinrich, Guo Chen, Lukas V oegtle, Philipp Fischer, Timo Roman, Karan Sapra, Collin McCarthy, Shaokun Zhang, Fuxiao Liu, Hanrong Ye, Yi Dong, Mingjie Liu, Yi...
2026
-
[44]
NVIDIA Nemotron 3: Efficient and Open Intelligence
NVIDIA. NVIDIA nemotron 3: Efficient and open intelligence.CoRR, abs/2512.20856, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Anatomy of a machine learning ecosystem: 2 million models on hugging face
Hamidah Oderinwale, Benjamin Laufer, and Jon Kleinberg. Anatomy of a machine learning ecosystem: 2 million models on hugging face. InNeurIPS 2025 Workshop on Regulatable ML, 2025
2025
-
[46]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Michal Guerquin, Hamish Ivison, Pang Wei Koh, Jiacheng Liu, Saumya Ma- lik, Willia...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Introducing ChatGPT, November 2022
OpenAI. Introducing ChatGPT, November 2022
2022
-
[48]
GPT-4, March 2023
OpenAI. GPT-4, March 2023
2023
-
[49]
Hello GPT-4o, May 2024
OpenAI. Hello GPT-4o, May 2024
2024
-
[50]
Introducing SWE-bench Verified, August 2024
OpenAI. Introducing SWE-bench Verified, August 2024. 19
2024
-
[51]
Introducing deep research, February 2025
OpenAI. Introducing deep research, February 2025
2025
-
[52]
Introducing GPT-5.4, March 2026
OpenAI. Introducing GPT-5.4, March 2026
2026
-
[53]
Introducing GPT-5.5, April 2026
OpenAI. Introducing GPT-5.5, April 2026
2026
-
[54]
Bowman, and Shi Feng
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurI...
2024
-
[55]
Raffel, Leandro von Werra, and Thomas Wolf
Guilherme Penedo, Hynek Kydlícek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin A. Raffel, Leandro von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural ...
2024
-
[56]
Data cards: Purposeful and transparent dataset documentation for responsible AI
Mahima Pushkarna, Andrew Zaldivar, and Oddur Kjartansson. Data cards: Purposeful and transparent dataset documentation for responsible AI. InFAccT ’22: 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, June 21 - 24, 2022, pages 1776–1826. ACM, 2022
2022
-
[57]
Generalizing Verifiable Instruction Following
Valentina Pyatkin, Saumya Malik, Victoria Graf, Hamish Ivison, Shengyi Huang, Pradeep Dasigi, Nathan Lambert, and Hannaneh Hajishirzi. Generalizing verifiable instruction following. CoRR, abs/2507.02833, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Hugginggraph: Understanding the supply chain of LLM ecosystem
Mohammad Shahedur Rahman, Peng Gao, and Yuede Ji. Hugginggraph: Understanding the supply chain of LLM ecosystem. In Meeyoung Cha, Chanyoung Park, Noseong Park, Carl Yang, Senjuti Basu Roy, Jessie Li, Jaap Kamps, Kijung Shin, Bryan Hooi, and Lifang He, editors,Proceedings of the 34th ACM International Conference on Information and Knowledge Management, CIK...
2025
-
[59]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark.CoRR, abs/2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark
Oscar Sainz, Jon Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, Singapore, Decembe...
2023
-
[61]
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research
Rulin Shao, Akari Asai, Shannon Zejiang Shen, Hamish Ivison, Varsha Kishore, Jingming Zhuo, Xinran Zhao, Molly Park, Samuel G. Finlayson, David A. Sontag, Tyler Murray, Sewon Min, Pradeep Dasigi, Luca Soldaini, Faeze Brahman, Wen-tau Yih, Tongshuang Wu, Luke Zettlemoyer, Yoon Kim, Hannaneh Hajishirzi, and Pang Wei Koh. DR tulu: Reinforcement learning with...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Anderson, and Yarin Gal
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross J. Anderson, and Yarin Gal. AI models collapse when trained on recursively generated data.Nat., 631(8022):755–759, 2024
2024
-
[63]
Hwang, Rodney Kinney, Daniel S Weld, Doug Downey, and Sergey Feldman
Amanpreet Singh, Joseph Chee Chang, Dany Haddad, Aakanksha Naik, Jena D. Hwang, Rodney Kinney, Daniel S Weld, Doug Downey, and Sergey Feldman. Ai2 scholar QA: Organized literature synthesis with attribution. In Pushkar Mishra, Smaranda Muresan, and Tao Yu, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vo...
2025
-
[64]
Heymann, Massimiliano Di Penta, Daniel M
Trevor Stalnaker, Nathan Wintersgill, Oscar Chaparro, Laura A. Heymann, Massimiliano Di Penta, Daniel M. Germán, and Denys Poshyvanyk. The ML supply chain in the era of software 2.0: Lessons learned from hugging face.CoRR, abs/2502.04484, 2025
-
[65]
Llama Team. The llama 3 herd of models.CoRR, abs/2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Qwen Team. Qwen3 technical report.CoRR, abs/2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Boxin Wang, Chankyu Lee, Nayeon Lee, Sheng-Chieh Lin, Wenliang Dai, Yang Chen, Yangyi Chen, Zhuolin Yang, Zihan Liu, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Nemotron-cascade: Scaling cascaded reinforcement learning for general-purpose reasoning models.CoRR, abs/2512.13607, 2025
-
[68]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long ...
2023
-
[69]
HelpSteer3: Human-annotated feedback and edit data to empower inference-time scaling in open-ended general-domain tasks
Zhilin Wang, Jiaqi Zeng, Olivier Delalleau, Daniel Egert, Ellie Evans, Hoo-Chang Shin, Felipe Soares, Yi Dong, and Oleksii Kuchaiev. HelpSteer3: Human-annotated feedback and edit data to empower inference-time scaling in open-ended general-domain tasks. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of ...
2025
-
[70]
Synthetic artifact auditing: Tracing llm-generated synthetic data usage in downstream applications
Yixin Wu, Ziqing Yang, Yun Shen, Michael Backes, and Yang Zhang. Synthetic artifact auditing: Tracing llm-generated synthetic data usage in downstream applications. In Lujo Bauer and Giancarlo Pellegrino, editors,34th USENIX Security Symposium, USENIX Security 2025, Seattle, WA, USA, August 13-15, 2025, pages 1689–1708. USENIX Association, 2025
2025
-
[71]
LLM DNA: Tracing model evolution via functional representations
Zhaomin Wu, Haodong Zhao, Ziyang Wang, Jizhou Guo, Qian Wang, and Bingsheng He. LLM DNA: Tracing model evolution via functional representations. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[72]
Wizardlm: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qing- wei Lin, and Daxin Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[73]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement.CoRR, abs/2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
Shuo Yang, Wei-Lin Chiang, Lianmin Zheng, Joseph E. Gonzalez, and Ion Stoica. Re- thinking benchmark and contamination for language models with rephrased samples.CoRR, abs/2311.04850, 2023
-
[76]
Navigating dataset documentations in AI: A large-scale analysis of dataset cards on huggingface
Xinyu Yang, Weixin Liang, and James Zou. Navigating dataset documentations in AI: A large-scale analysis of dataset cards on huggingface. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 21
2024
-
[77]
Phylolm: Inferring the phylogeny of large language models and predicting their performances in benchmarks
Nicolas Yax, Pierre-Yves Oudeyer, and Stefano Palminteri. Phylolm: Inferring the phylogeny of large language models and predicting their performances in benchmarks. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[78]
OpenReview.net, 2025
2025
-
[79]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Weinan Dai, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural In...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.