An Explainable AI Assistant for Introductory Programming Education: Improving Feedback Reliability with Instructor-AI Collaboration
Pith reviewed 2026-06-30 22:33 UTC · model grok-4.3
The pith
An explainable AI assistant maps student code errors to instructor-identified misconceptions and delivers verified feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an explainable AI model can reliably map logical errors in student code to instructor-identified misconceptions and deliver instructor-authored feedback, thereby producing accurate instructor-verified responses that students experience as usable and positive.
What carries the argument
The explainable AI model that maps logical errors in student code to instructor-identified misconceptions before delivering instructor-authored feedback.
If this is right
- The assistant can supply accurate feedback at scale in large introductory programming classes.
- Students receive feedback grounded in the same pedagogical knowledge used by their instructors.
- Classroom use produces measurable positive perceptions of usability among students.
- The approach reduces reliance on unverified AI outputs by anchoring explanations to instructor-defined content.
Where Pith is reading between the lines
- Instructors could use the system to surface previously unrecognized patterns in student misconceptions across multiple semesters.
- The same mapping technique might transfer to other technical subjects where experts have catalogued common errors in advance.
- Over time the logged mappings could serve as training data to refine the model without losing the instructor-verification layer.
Load-bearing premise
The explainable AI model can map logical errors in student code to the specific misconceptions identified by instructors without introducing systematic misalignment that makes the feedback incorrect.
What would settle it
A classroom deployment in which instructors rate a substantial fraction of the assistant's delivered feedback as incorrect or misaligned with the intended misconception would falsify the claim.
Figures

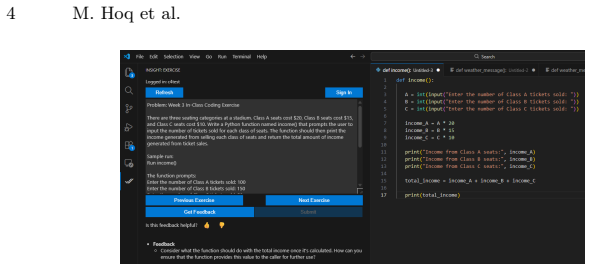
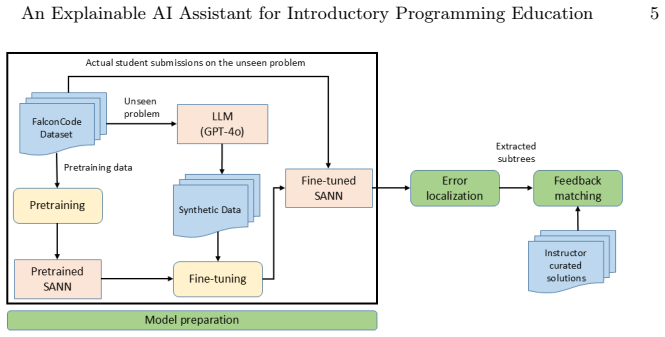



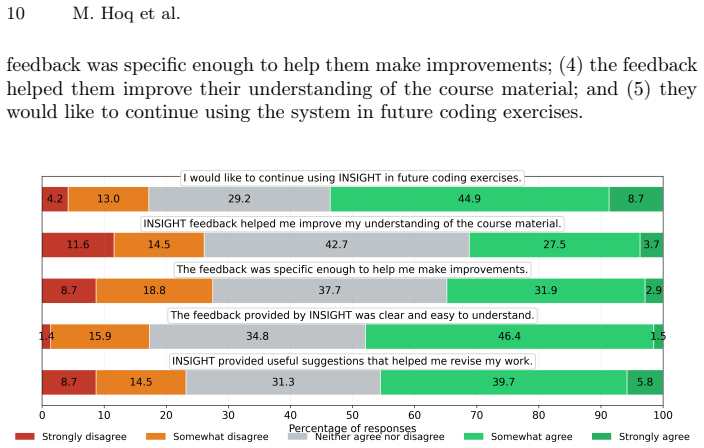
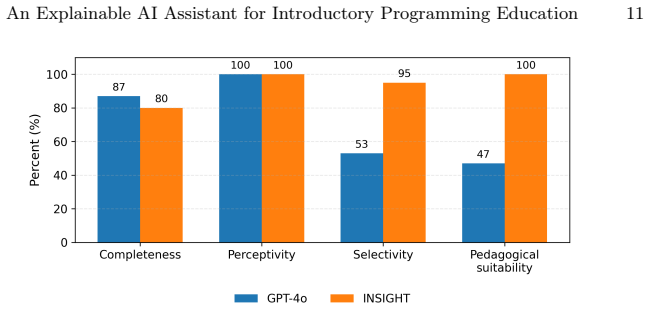
read the original abstract
Active learning is widely recognized as an effective approach for improving learning outcomes in introductory programming courses. However, insufficient instructional support often limits students' access to timely, personalized feedback, which is crucial for mastering foundational programming concepts. Although recent advances in AI, particularly large language models, offer scalable opportunities for feedback, concerns about explainability and reliability remain. In this paper, we present an AI-driven classroom assistant that leverages an explainable AI model to analyze student code, map logical errors to instructor-identified misconceptions, and deliver instructor-authored feedback, thereby grounding reliability in instructor-defined pedagogical knowledge. To evaluate the effectiveness of our framework, we conducted an expert evaluation to examine its alignment with instructor-verified feedback and deployed the system in a classroom setting to assess students' perceptions of its usability. Results indicate that the assistant can provide accurate, instructor-verified feedback to students while fostering a positive experience.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an explainable AI assistant for introductory programming courses. The system uses an XAI model to map logical errors in student code to instructor-identified misconceptions and delivers instructor-authored feedback. Evaluation consists of an expert evaluation examining alignment with instructor-verified feedback and a classroom deployment assessing student perceptions of usability, with the abstract concluding that the assistant provides accurate, instructor-verified feedback while fostering positive experiences.
Significance. If the error-to-misconception mapping proves reliable, the instructor-AI collaboration model could meaningfully advance scalable, trustworthy feedback in CS education by anchoring AI outputs in expert pedagogical knowledge. This grounding approach is a clear strength relative to purely generative LLM feedback systems.
major comments (2)
- [Abstract] Abstract: The central claim that the assistant 'can provide accurate, instructor-verified feedback' is unsupported by any quantitative metrics (accuracy rates, number of evaluated code instances, sample sizes, or inter-rater agreement on the mapping). The expert evaluation is described only at a high level with no error rates or failure-case analysis, leaving the reliability of the XAI mapping step unquantified.
- [Evaluation section] Evaluation description: No details are supplied on whether the expert alignment checks were blinded, how inter-rater reliability was measured for the misconception mapping, or what fraction of cases showed misalignment. These omissions are load-bearing because the paper's reliability argument rests entirely on the correctness of that mapping step.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence summarizing the scale of the expert evaluation and classroom deployment (e.g., number of instructors, students, or submissions).
Simulated Author's Rebuttal
We thank the referee for the constructive comments on strengthening the quantitative support and methodological transparency of our evaluation. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the assistant 'can provide accurate, instructor-verified feedback' is unsupported by any quantitative metrics (accuracy rates, number of evaluated code instances, sample sizes, or inter-rater agreement on the mapping). The expert evaluation is described only at a high level with no error rates or failure-case analysis, leaving the reliability of the XAI mapping step unquantified.
Authors: We agree that the abstract claim requires supporting quantitative evidence from the expert evaluation. In the revised manuscript we will report the number of code instances evaluated, the accuracy rate of the error-to-misconception mapping, sample sizes, inter-rater agreement statistics, error rates, and a brief failure-case analysis. These additions will be referenced in an updated abstract. revision: yes
-
Referee: [Evaluation section] Evaluation description: No details are supplied on whether the expert alignment checks were blinded, how inter-rater reliability was measured for the misconception mapping, or what fraction of cases showed misalignment. These omissions are load-bearing because the paper's reliability argument rests entirely on the correctness of that mapping step.
Authors: We acknowledge these methodological details are necessary. The revised evaluation section will specify whether alignment checks were blinded, describe the inter-rater reliability measure used (e.g., Cohen’s kappa), and report the fraction of misaligned cases. If blinding was not performed in the original study we will note this limitation explicitly. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript presents an empirical framework evaluated via expert alignment checks and classroom usability deployment. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the abstract or described structure. The central claim (accurate instructor-verified feedback) is positioned as an outcome of external evaluations rather than a quantity defined in terms of its own inputs or prior author work. This is the expected non-finding for an applied systems paper whose reliability rests on reported human judgments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Instructor-identified misconceptions and instructor-authored feedback constitute reliable pedagogical ground truth.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 50th ACM technical symposium on Computer science education
Akram, B., Min, W., Wiebe, E., Mott, B., Boyer, K.E., Lester, J.: Assessing middle school students’ computational thinking through programming trajectory analy- sis. In: Proceedings of the 50th ACM technical symposium on Computer science education. pp. 1269–1269 (2019)
2019
-
[2]
Cognitive Science13(4), 467–505 (1989)
Anderson, J.R., Conrad, F.G., Corbett, A.T.: Skill acquisition and the lisp tutor. Cognitive Science13(4), 467–505 (1989)
1989
-
[3]
In: Proceedings of the 40th International Conference on Software Engineering
Bhatia, S., Kohli, P., Singh, R.: Neuro-symbolic program corrector for introductory programming assignments. In: Proceedings of the 40th International Conference on Software Engineering. pp. 60–70 (2018)
2018
-
[4]
Journal of Research in Science Teaching57(6), 879–910 (2020)
Chen, C., Sonnert, G., Sadler, P.M., Sasselov, D., Fredericks, C.: The impact of student misconceptions on student persistence in a mooc. Journal of Research in Science Teaching57(6), 879–910 (2020)
2020
-
[5]
Educational Psychologist49(4), 219–243 (2014)
Chi, M.T., Wylie, R.: The icap framework: Linking cognitive engagement to active learning outcomes. Educational Psychologist49(4), 219–243 (2014)
2014
-
[6]
In: Proceedings of the Innovation and Technology in Computer Science Education, pp
Denny, P., MacNeil, S., Savelka, J., Porter, L., et al.: Desirable characteristics for ai teaching assistants in programming education. In: Proceedings of the Innovation and Technology in Computer Science Education, pp. 408–414 (2024)
2024
-
[7]
In: Proceedings of the ACM Technical Symposium on Computer Science Education V
de Freitas, A., Coffman, J., et al.: Falconcode: A multiyear dataset of python code samples from an introductory computer science course. In: Proceedings of the ACM Technical Symposium on Computer Science Education V. 1. pp. 938–944 (2023)
2023
-
[8]
ACM SIGPLAN Notices53(4), 465–480 (2018)
Gulwani, S., Radiček, I., et al.: Automated clustering and program repair for intro- ductory programming assignments. ACM SIGPLAN Notices53(4), 465–480 (2018)
2018
-
[9]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Gupta, R., Kanade, A., Shevade, S.: Deep reinforcement learning for syntactic error repair in student programs. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 33, pp. 930–937 (2019)
2019
-
[10]
In: Proceedings of the 16th International Conference on Educational Data Mining
Hoq, M., Brusilovsky, P., Akram, B.: Analysis of an explainable student perfor- mance prediction model in an introductory programming course. In: Proceedings of the 16th International Conference on Educational Data Mining. pp. 79–90. In- ternational Educational Data Mining Society, Bengaluru, India (2023)
2023
-
[11]
Journal of Educational Data Mining16(2), 115–148 (2024)
Hoq, M., Brusilovsky, P., Akram, B.: Explaining explainability: Early performance prediction with student programming pattern profiling. Journal of Educational Data Mining16(2), 115–148 (2024)
2024
-
[12]
In: Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM)
Hoq, M., Chilla, S.R., Ahmadi Ranjbar, M., Brusilovsky, P., Akram, B.: Sann: programming code representation using attention neural network with optimized subtree extraction. In: Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM). pp. 783–792 (2023)
2023
-
[13]
In: Proceedings of the 56th ACM Technical Symposium on Computer Science Ed- ucation (SIGCSE) V
Hoq, M., Patil, A., Akhuseyinoglu, K., Brusilovsky, P., Akram, B.: An automated approach to recommending relevant worked examples for programming problems. In: Proceedings of the 56th ACM Technical Symposium on Computer Science Ed- ucation (SIGCSE) V. 1. pp. 527–533. Association for Computing Machinery, New York, NY, USA (2025)
2025
-
[14]
In: Proceedings of the International Conference on Educational Data Mining
Hoq, M., Rao, A., Jaishankar, R., Piryani, K., Janapati, N., Vandenberg, J., Mott, B., Norouzi, N., Lester, J., Akram, B.: Automated identification of logical errors in programs: advancing scalable analysis of student misconceptions. In: Proceedings of the International Conference on Educational Data Mining. pp. 90–103 (2025)
2025
-
[15]
In: Proceedings of the 55th ACM Technical Symposium on Computer Sci- ence Education
Hoq, M., Shi, Y., Leinonen, J., Babalola, D., Lynch, C., Price, T., Akram, B.: De- tecting chatgpt-generated code submissions in a cs1 course using machine learning models. In: Proceedings of the 55th ACM Technical Symposium on Computer Sci- ence Education. p. 526–532 (2024) An Explainable AI Assistant for Introductory Programming Education 15
2024
-
[16]
In: Proceedings of the CHI 2025 Workshop on Aug- mented Educators and AI: Shaping the Future of Human and AI Cooperation in Learning (2025)
Hoq, M., Vandenberg, J., Jiao, S., Lee, S., Mott, B., Norouzi, N., Lester, J., Akram, B.: Facilitating instructors-llm collaboration for problem design in introductory programming classrooms. In: Proceedings of the CHI 2025 Workshop on Aug- mented Educators and AI: Shaping the Future of Human and AI Cooperation in Learning (2025)
2025
-
[17]
In: Proceedings of the 57th ACM Technical Symposium on Computer Science Education V
Hoq, M., Vandenberg, J., Lee, S., Mott, B., Lester, J., Norouzi, N., Jiao, S., Akram, B.: Insight: An explainable, instructor-guided ai assistant for active learning in cs1. In: Proceedings of the 57th ACM Technical Symposium on Computer Science Education V. 2. pp. 1363–1364 (2026)
2026
-
[18]
arXiv preprint arXiv:2403.09744 (2024)
Jacobs, S., Jaschke, S.: Evaluating the application of large language models to gen- erate feedback in programming education. arXiv preprint arXiv:2403.09744 (2024)
-
[19]
In: Proceedings of the International Conference on Educational Data Mining
Jia, Q., Cui, J., Du, H., Rashid, P., Xi, R., et al.: Llm-generated feedback in real classes and beyond: perspectives from students and instructors. In: Proceedings of the International Conference on Educational Data Mining. pp. 862–867 (2024)
2024
-
[20]
In: Proceedings of the International Conference on Educational Data Mining
Jia, Q., Cui, J., Xi, R., Liu, C., Rashid, P., Li, R., Gehringer, E.: On assessing the faithfulness of llm-generated feedback on student assignments. In: Proceedings of the International Conference on Educational Data Mining. pp. 491–499 (2024)
2024
-
[21]
In: Proceedings of the 2024 on Innovation and Tech- nology in Computer Science Education V
Koutcheme, C., Dainese, N., Sarsa, S., Hellas, A., Leinonen, J., Denny, P.: Open source language models can provide feedback: evaluating llms’ ability to help stu- dents using gpt-4-as-a-judge. In: Proceedings of the 2024 on Innovation and Tech- nology in Computer Science Education V. 1, pp. 52–58 (2024)
2024
-
[22]
Biometrics33(1), 159–174 (1977)
Landis, J.R., Koch, G.G.: The measurement of observer agreement for categorical data. Biometrics33(1), 159–174 (1977)
1977
-
[23]
In: Proceedings of the Conference on Integrating Technology into Computer Science Education
McConnell, J.J.: Active learning and its use in computer science. In: Proceedings of the Conference on Integrating Technology into Computer Science Education. pp. 52–54 (1996)
1996
-
[24]
Messer, M., Brown, N.C., Kölling, M., Shi, M.: Automated grading and feedback toolsforprogrammingeducation:Asystematicreview.ACMTransactionsonCom- puting Education24(1), 1–43 (2024)
2024
-
[25]
In: Proceedings of the 16th International Conference on Educational Data Mining
Phung, T., Cambronero, J., Gulwani, S., Kohn, T., Majumdar, R., Singla, A., Soares, G.: Generating high-precision feedback for programming syntax errors us- ing large language models. In: Proceedings of the 16th International Conference on Educational Data Mining. pp. 370–377 (2023)
2023
-
[26]
In: Proceedings of the 2023 ACM Conference on International Computing Education Research-Volume 2
Phung, T., Pădurean, V.A., Cambronero, J., Gulwani, S., Kohn, T., Majumdar, R., Singla, A., Soares, G.: Generative ai for programming education: Benchmarking chatgpt, gpt-4, and human tutors. In: Proceedings of the 2023 ACM Conference on International Computing Education Research-Volume 2. pp. 41–42 (2023)
2023
-
[27]
In: Proceedings of the 14th Learning Analytics and Knowledge Conference
Phung, T., Pădurean, V.A., Singh, A., Brooks, C., Cambronero, J., Gulwani, S., Singla, A., Soares, G.: Automating human tutor-style programming feedback: Leveraging gpt-4 tutor model for hint generation and gpt-3.5 student model for hint validation. In: Proceedings of the 14th Learning Analytics and Knowledge Conference. pp. 12–23 (2024)
2024
-
[28]
Singh, R., Gulwani, S., Solar-Lezama, A.: Automated feedback generation for in- troductoryprogrammingassignments.In:ProceedingsoftheACMSIGPLANCon- ference on Programming Language Design and Implementation. pp. 15–26 (2013)
2013
-
[29]
arXiv preprint arXiv:2410.16513 (2024)
Tang, X., Wong, S., Huynh, M., He, Z., Yang, Y., Chen, Y.: Sphere: Scaling person- alized feedback in programming classrooms with structured review of llm outputs. arXiv preprint arXiv:2410.16513 (2024)
-
[30]
arXiv preprint arXiv:2209.14876 (2022)
Zhang, J., Cambronero, J., Gulwani, S., Le, V., Piskac, R., Soares, G., Verbruggen, G.: Repairing bugs in python assignments using large language models. arXiv preprint arXiv:2209.14876 (2022)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.