Occupational Prompting Reveals Cultural Bias in Large Language Models
Pith reviewed 2026-06-30 18:00 UTC · model grok-4.3
The pith
Occupational prompts keep LLM value responses in a Western-leaning cultural region but produce distinct shifts by job.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
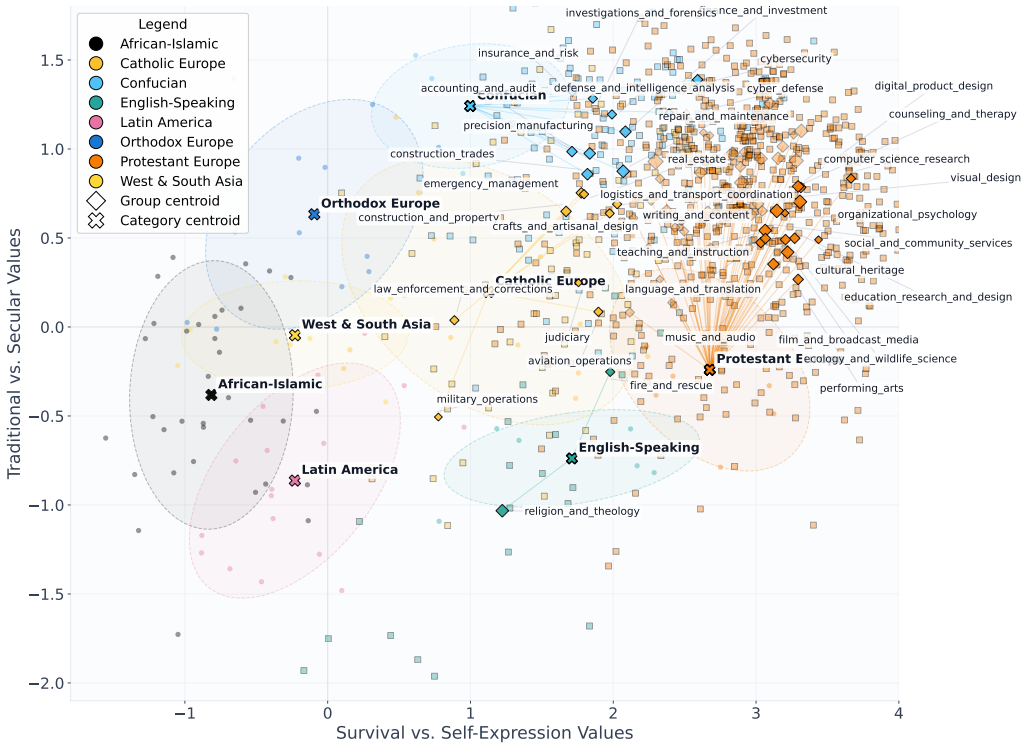
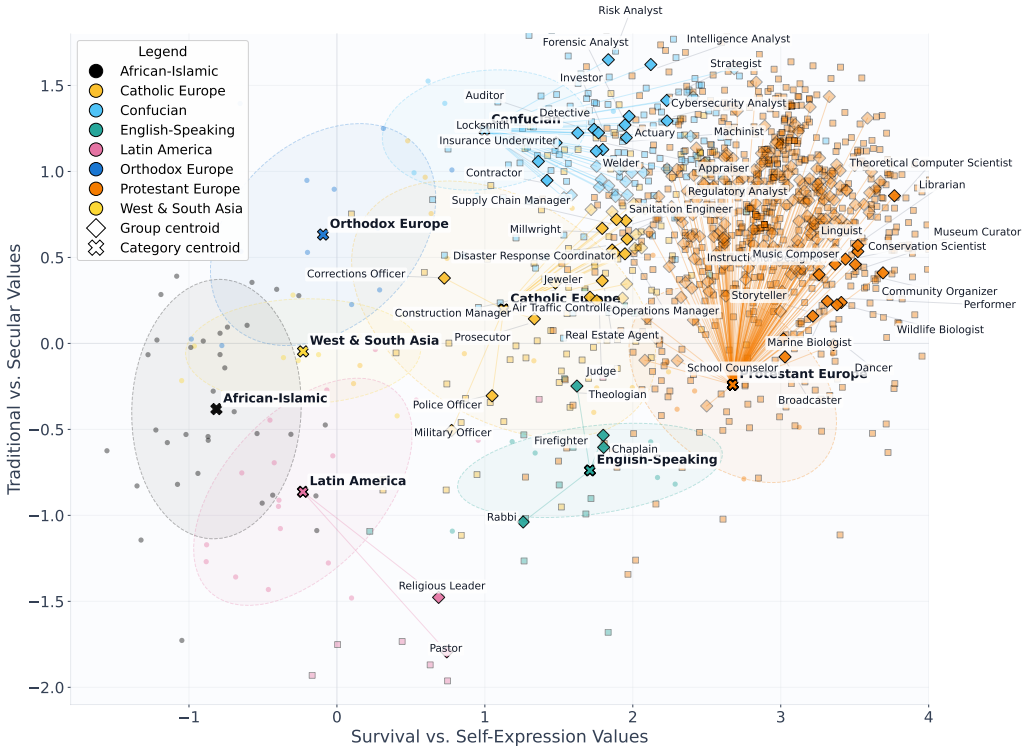
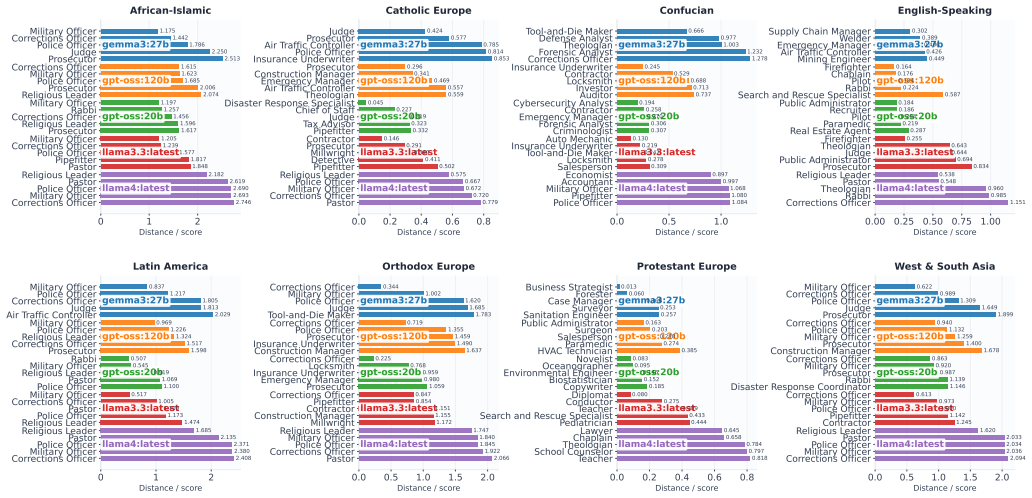
When open-weight LLMs are prompted with occupations rather than national identities, their responses remain within a broadly Western-leaning region of the cultural map. However, different occupations introduce shifts within this region, producing distinct occupational skews. This indicates that occupational prompts are not treated as neutral role labels, but instead elicit structured value patterns.
What carries the argument
Projection of occupation-conditioned answers to Integrated Values Survey questions onto the two-dimensional Inglehart-Welzel cultural map.
If this is right
- Occupational prompts elicit structured value patterns rather than neutral responses.
- Different occupations such as accountant, teacher, engineer, and nurse produce distinct shifts within the Western-leaning region.
- Survey-based evaluation of cultural bias can be extended beyond nationality-based prompting to occupational personas.
- LLMs associate professional roles with particular value orientations that mirror real-world role expectations.
Where Pith is reading between the lines
- The observed occupational skews may reflect patterns present in the training data that link jobs to cultural values.
- Testing whether these shifts persist after targeted fine-tuning on balanced occupational descriptions would clarify if the patterns are removable.
- Applications that assign occupational personas to models for advice or decision support could unintentionally amplify role-linked value differences.
Load-bearing premise
Responses to Integrated Values Survey questions under occupational prompts can be meaningfully projected onto the Inglehart-Welzel cultural map to reveal occupation-linked value patterns.
What would settle it
If repeated runs under the same occupational prompts produce positions on the cultural map that show no consistent occupation-to-shift mapping and instead scatter without pattern, the central claim would be falsified.
Figures
read the original abstract
Social roles shape expectations, priorities, and judgments, yet it remains unclear how large language models (LLMs) associate occupational identities with broader cultural value patterns. Prior work used nationality-based cultural prompting to study how LLM responses to value-survey questions align with human cultural benchmarks. In this paper, we extend that framework by replacing cultural prompting with occupational prompting to examine how professional-role cues influence value-survey responses in open-weight LLMs. Using a survey-grounded evaluation pipeline based on questions from the Integrated Values Surveys, we project model responses into the two-dimensional Inglehart--Welzel cultural space. We prompt open-weight LLMs to answer questions under occupational identities such as accountant, teacher, engineer, and nurse, and then analyze how these occupation-conditioned responses are positioned on the cultural map. Our results show that when open-weight LLMs are prompted with occupations rather than national identities, their responses remain within a broadly Western-leaning region of the cultural map. However, different occupations introduce shifts within this region, producing distinct occupational skews. This indicates that occupational prompts are not treated as neutral role labels, but instead elicit structured value patterns. These findings extend survey-based evaluation of cultural bias beyond nationality-based prompting and provide a framework for studying how occupational personas shape value expression in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends nationality-based cultural prompting of LLMs to occupational prompting. Open-weight models are prompted with roles such as accountant, teacher, engineer, and nurse to answer Integrated Values Survey items; the resulting answers are projected onto the two-dimensional Inglehart-Welzel cultural map. The central claim is that responses remain inside a broadly Western-leaning region yet exhibit occupation-specific shifts, demonstrating that occupational identities are not neutral labels but elicit structured value patterns.
Significance. If the projection is shown to be valid, the work supplies a concrete, survey-grounded method for isolating the effect of professional personas on model value expression, thereby broadening cultural-bias evaluation beyond national-identity cues and offering a reusable pipeline for future studies of role-conditioned behavior in LLMs.
major comments (1)
- [Abstract] Abstract and evaluation pipeline: the headline result that occupational prompts produce interpretable shifts on the Inglehart-Welzel map presupposes that the principal components derived from human cross-national data remain valid when applied to LLM-generated answers. No evidence is supplied that the correlation structure or variance directions of the model responses align with the original human factor loadings; absent such validation (e.g., a comparison of item inter-correlations or a check that the two axes capture comparable variance), the reported occupational coordinates cannot be treated as cultural positions.
minor comments (2)
- The abstract supplies neither the specific open-weight models evaluated, the exact number of IVS items retained, the number of responses per occupation, nor any statistical tests or error bars for the claimed shifts.
- Notation for the projection step is not defined; it is unclear whether the mapping uses the original Inglehart-Welzel loadings directly or a re-derived transformation.
Simulated Author's Rebuttal
We thank the referee for the detailed comment on the validity of projecting LLM responses onto the Inglehart-Welzel map. We address the concern directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation pipeline: the headline result that occupational prompts produce interpretable shifts on the Inglehart-Welzel map presupposes that the principal components derived from human cross-national data remain valid when applied to LLM-generated answers. No evidence is supplied that the correlation structure or variance directions of the model responses align with the original human factor loadings; absent such validation (e.g., a comparison of item inter-correlations or a check that the two axes capture comparable variance), the reported occupational coordinates cannot be treated as cultural positions.
Authors: We agree that the current manuscript does not provide explicit checks confirming that the correlation structure and variance directions observed in LLM responses align with the human-derived factor loadings. To strengthen the interpretability of the occupational coordinates, the revised manuscript will include (1) a direct comparison of item inter-correlations between the human Integrated Values Survey data and the aggregated LLM responses, and (2) an assessment of the proportion of variance captured by the two axes when the human-derived loadings are applied to the model data. These additions will be placed in the methods and results sections. revision: yes
Circularity Check
No significant circularity: empirical projection onto external map
full rationale
The paper's derivation consists of prompting open-weight LLMs with occupational identities, collecting responses to Integrated Values Survey items, and projecting those responses onto the pre-existing Inglehart-Welzel cultural map derived from human cross-national data. This is a direct empirical comparison against an external benchmark with no equations, fitted parameters, or self-citations that reduce the reported occupational shifts to the inputs by construction. The central claim therefore retains independent content and does not match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The ghost in the ma- chine has an american accent: value conflict in gpt-3,
R. L. Johnson, G. Pistilli, N. Men ´edez-Gonz´alez, L. D. D. Duran, E. Panai, J. Kalpokiene, and D. J. Bertulfo, “The ghost in the ma- chine has an american accent: value conflict in gpt-3,”arXiv preprint arXiv:2203.07785, 2022
-
[2]
M. Atari, M. J. Xue, P. S. Park, D. E. Blasi, and J. Henrich, “Which humans?”PsyArXiv, 2023. [Online]. Available: https://doi.org/ 10.31234/osf.io/5b26t
-
[3]
Having beer after prayer? measuring cultural bias in large language models,
T. Naous, M. J. Ryan, and W. Xu, “Having beer after prayer? measuring cultural bias in large language models,” inAnnual Meeting of the Association for Computational Linguistics, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:258865272
2023
-
[4]
Investigating cultural alignment of large language models,
B. AlKhamissi, M. N. ElNokrashy, M. Alkhamissi, and M. T. Diab, “Investigating cultural alignment of large language models,”ArXiv, vol. abs/2402.13231, 2024. [Online]. Available: https://api.semanticscholar. org/CorpusID:267759574
-
[5]
Computational Linguistics , volume =
S. M. Pawar, J. Park, J. Jin, A. Arora, J. Myung, S. Yadav, F. G. Haznitrama, I. Song, A. Oh, and I. Augenstein, “Survey of cultural awareness in language models: Text and beyond,”ArXiv, vol. abs/2411.00860, 2024. [Online]. Available: https://api.semanticscholar. org/CorpusID:273811670
-
[6]
Should llms be weird? exploring weirdness and human rights in large language models,
K. Zhou, M. Constantinides, and D. Quercia, “Should llms be weird? exploring weirdness and human rights in large language models,”ArXiv, vol. abs/2508.19269, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:280919174
-
[7]
Journal of Data and Information Quality , author =
R. Navigli, S. Conia, and B. Ross, “Biases in large language models: Origins, inventory, and discussion,”J. Data and Information Quality, vol. 15, no. 2, Jun. 2023. [Online]. Available: https: //doi.org/10.1145/3597307
-
[8]
Culture is everywhere: A call for intentionally cultural evaluation,
J. Oh, I. Cha, M. Saxon, H. Lim, S. Bhatt, and A. Oh, “Culture is everywhere: A call for intentionally cultural evaluation,”ArXiv, vol. abs/2509.01301, 2025. [Online]. Available: https://api.semanticscholar. org/CorpusID:281079526
-
[9]
Effects of language- and culture- specific prompting on chatgpt,
M. Tuna, K. Schaaff, and T. Schlippe, “Effects of language- and culture- specific prompting on chatgpt,” in2024 2nd International Conference on Foundation and Large Language Models (FLLM), 2024, pp. 73–81
2024
-
[10]
Evaluating cultural adaptability of a large language model via simulation of synthetic personas,
L. Kwok, M. Bravansky, and L. Griffin, “Evaluating cultural adaptability of a large language model via simulation of synthetic personas,” in First Conference on Language Modeling, 2024. [Online]. Available: https://openreview.net/forum?id=S4ZOkV1AHl
2024
-
[11]
C. M. Greco, L. L. Cava, and A. Tagarelli, “Culturally grounded personas in large language models: Characterization and alignment with socio-psychological value frameworks,”ArXiv, vol. abs/2601.22396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Available: https://api.semanticscholar.org/CorpusID: 285241197
[Online]. Available: https://api.semanticscholar.org/CorpusID: 285241197
-
[13]
Prompt programming for cultural bias and alignment of large language models,
M. E. Eren, E. Michalak, B. Cook, and J. Seales, “Prompt programming for cultural bias and alignment of large language models,”
-
[14]
Available: https://api.semanticscholar.org/CorpusID: 286584101
[Online]. Available: https://api.semanticscholar.org/CorpusID: 286584101
-
[15]
Ai documentation: A path to accountability,
F. K ¨onigstorfer and S. Thalmann, “Ai documentation: A path to accountability,”Journal of Responsible Technology, vol. 11, p. 100043, 2022. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S2666659622000208
2022
-
[16]
Bias in news summarization: Measures, pitfalls and corpora,
J. Steen and K. Markert, “Bias in news summarization: Measures, pitfalls and corpora,” inAnnual Meeting of the Association for Computational Linguistics, 2023. [Online]. Available: https://api. semanticscholar.org/CorpusID:262013727
2023
-
[17]
Smart audit system empowered by llm,
X. Yao, X. Wu, X. Li, H. Xu, C. Li, P. Huang, S. Li, X. Ma, and J. Shan, “Smart audit system empowered by llm,”ArXiv, vol. abs/2410.07677,
-
[18]
Available: https://api.semanticscholar.org/CorpusID: 273233253
[Online]. Available: https://api.semanticscholar.org/CorpusID: 273233253
-
[19]
A. Godbole, J. G. George, and S. Shandilya, “Leveraging long- context large language models for multi-document understanding and summarization in enterprise applications,”ArXiv, vol. abs/2409.18454,
-
[20]
Available: https://api.semanticscholar.org/CorpusID: 272969413
[Online]. Available: https://api.semanticscholar.org/CorpusID: 272969413
-
[21]
Cultural bias and cultural alignment of large language models,
Y . Tao, O. Viberg, R. S. Baker, and R. F. Kizilcec, “Cultural bias and cultural alignment of large language models,”PNAS Nexus, vol. 3, no. 9, p. pgae346, 09 2024. [Online]. Available: https://doi.org/10.1093/pnasnexus/pgae346
-
[22]
Inglehart and C
R. Inglehart and C. Welzel,Modernization, Cultural Change, and Democracy: The Human Development Sequence. Cambridge University Press, 2005
2005
-
[23]
World values survey: Round seven — country-pooled datafile (2017–2022), version 5.0,
C. H ¨arpfer, R. Inglehartet al., “World values survey: Round seven — country-pooled datafile (2017–2022), version 5.0,” https: //www.worldvaluessurvey.org/WVSDocumentationWV7.jsp, 2022, ac- cessed: 2026-02-24
2017
-
[24]
European values study 2017–2022: Trend file,
European Values Study, “European values study 2017–2022: Trend file,” https://europeanvaluesstudy.eu/, 2022, accessed: 2026-02-24
2017
-
[25]
Inte- grated values surveys (ivs) — codebook and documentation,
World Values Survey Association and European Values Study, “Inte- grated values surveys (ivs) — codebook and documentation,” https: //www.worldvaluessurvey.org/WVSDocumentationWVL.jsp, 2023, ac- cessed: 2026-02-24
2023
-
[26]
Worldvaluesbench: A large-scale benchmark dataset for multi-cultural value awareness of language models,
W. Zhao, D. Mondal, N. Tandon, D. Dillion, K. Gray, and Y . Gu, “Worldvaluesbench: A large-scale benchmark dataset for multi-cultural value awareness of language models,” inInternational Conference on Language Resources and Evaluation, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:269362884
2024
-
[27]
Do llms have consistent values?
N. Rozen, L. Bezalel, G. Elidan, A. Globerson, and E. Daniel, “Do llms have consistent values?” inInternational Conference on Learning Representations, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., vol. 2025, 2025, pp. 42 441–42 467. [Online]. Available: https://proceedings.iclr.cc/paper files/paper/2025/ file/68fb4539dabb0e34ea42845776f42953-Paper-...
2025
-
[28]
Two tales of persona in LLMs: A survey of role-playing and personalization,
Y .-M. Tseng, Y .-C. Huang, T.-Y . Hsiao, W.-L. Chen, C.-W. Huang, Y . Meng, and Y .-N. Chen, “Two tales of persona in LLMs: A survey of role-playing and personalization,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics,...
2024
-
[29]
Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models,
Z. M. Wang, Z. Peng, H. Que, J. Liu, W. Zhou, Y . Wu, H. Guo, R. Gan, Z. Ni, M. Zhang, Z. Zhang, W. Ouyang, K. Xu, W. Chen, J. Fu, and J. Peng, “Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models,” inAnnual Meeting of the Association for Computational Linguistics, 2023. [Online]. Available: https://api.semantic...
2023
-
[30]
The prompt makes the person(a): A systematic evaluation of sociodemographic persona prompting for large language models,
M. Lutz, I. Sen, G. Ahnert, E. Rogers, and M. Strohmaier, “The prompt makes the person(a): A systematic evaluation of sociodemographic persona prompting for large language models,” inConference on Empirical Methods in Natural Language Processing, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:280166937
2025
-
[31]
Gender bias and stereotypes in large language models,
H. Kotek, R. Dockum, and D. Q. Sun, “Gender bias and stereotypes in large language models,”Proceedings of The ACM Collective Intelligence Conference, 2023. [Online]. Available: https: //api.semanticscholar.org/CorpusID:261276445
2023
-
[32]
Evaluating gender, racial, and age biases in large language models: A comparative analysis of occupational and crime scenarios,
V . Mirza, R. Kulkarni, and A. Jadhav, “Evaluating gender, racial, and age biases in large language models: A comparative analysis of occupational and crime scenarios,”2025 IEEE Conference on Artificial Intelligence (CAI), pp. 244–251, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:272826949
2025
-
[33]
Exploring the occupational biases and stereotypes of chinese large language models,
L. Jiang, G. Zhu, J. Sun, J. Cao, and J. Wu, “Exploring the occupational biases and stereotypes of chinese large language models,”Scientific Reports, vol. 15, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:278963044
2025
-
[34]
I. T. Jolliffe and J. Cadima,Principal Component Analysis, 2nd ed. Springer, 2016
2016
-
[35]
The varimax criterion for analytic rotation in factor analysis,
H. F. Kaiser, “The varimax criterion for analytic rotation in factor analysis,”Psychometrika, vol. 23, no. 3, pp. 187–200, 1958
1958
-
[36]
ChatGPT Pro,
OpenAI, “ChatGPT Pro,” https://chatgpt.com/, 2026, large language model accessed via ChatGPT Pro; model: GPT-5.5 Thinking; accessed April 28, 2026
2026
-
[37]
Self-instruct: Aligning language models with self-generated instructions,
Y . Wang, Y . Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi, “Self-instruct: Aligning language models with self-generated instructions,” inAnnual Meeting of the Association for Computational Linguistics, 2022. [Online]. Available: https: //api.semanticscholar.org/CorpusID:254877310
2022
-
[38]
Large language models as annotators: Enhancing generalization of nlp models at minimal cost,
P. Bansal and A. Sharma, “Large language models as annotators: Enhancing generalization of nlp models at minimal cost,”ArXiv, vol. abs/2306.15766, 2023. [Online]. Available: https://api.semanticscholar. org/CorpusID:259274939
-
[39]
On llms-driven synthetic data generation, curation, and evaluation: A survey,
L. Long, R. Wang, R. Xiao, J. Zhao, X. Ding, G. Chen, and H. Wang, “On llms-driven synthetic data generation, curation, and evaluation: A survey,”ArXiv, vol. abs/2406.15126, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:270688337
-
[40]
Synthetic replacements for human survey data? the perils of large language models,
J. Bisbee, J. D. Clinton, C. Dorff, B. Kenkel, and J. M. Larson, “Synthetic replacements for human survey data? the perils of large language models,”Political Analysis, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:269845858
2024
-
[41]
Llama 3 model card,
Meta, “Llama 3 model card,” https://github.com/meta-llama/llama3/ blob/main/MODEL CARD.md, 2024, accessed 2026-02-24
2024
-
[42]
Llama 4 model card,
——, “Llama 4 model card,” https://github.com/meta-llama/ llama-models/blob/main/models/llama4/MODEL CARD.md, 2025, accessed 2026-02-24
2025
-
[43]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, “Gemma: Open models based on gemini research and technology,” https://arxiv.org/abs/2403.08295, 2024, accessed 2026-02- 24
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, “gpt-oss-120b & gpt-oss-20b model card,” https://arxiv.org/abs/ 2508.10925, 2025, accessed 2026-02-24
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.