Boltzmann Attention: Learnable Ising Couplings for Cooperative Attention
Pith reviewed 2026-06-27 10:16 UTC · model grok-4.3
The pith
Boltzmann attention replaces softmax with an Ising model that includes learnable pairwise couplings between positions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
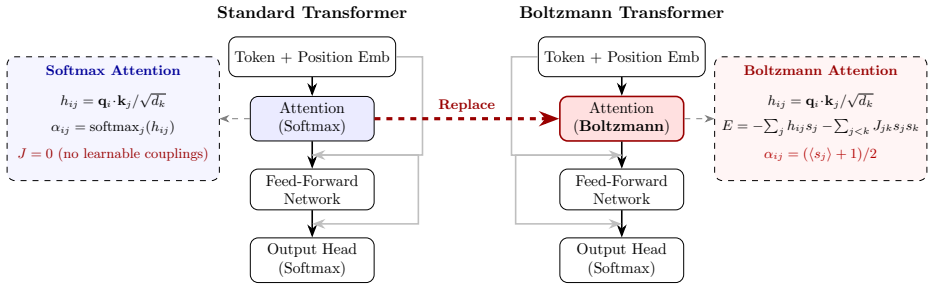
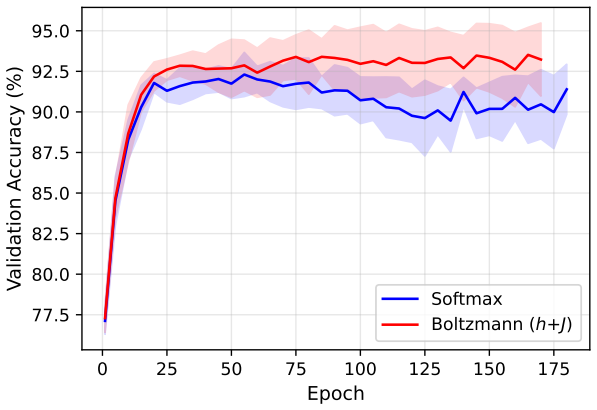
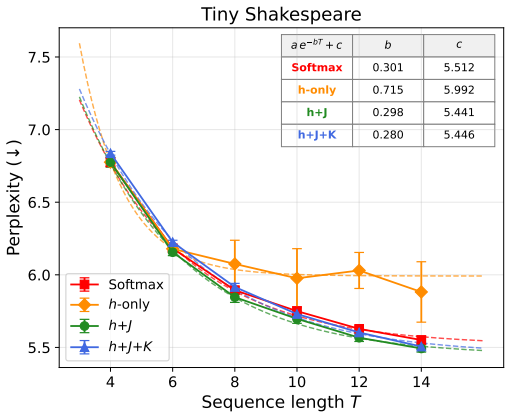
Boltzmann attention augments the data-dependent local fields with learnable pairwise couplings in an Ising model, allowing attention patterns to represent inter-position correlations. This leads to better performance in sequence modeling tasks compared to standard softmax attention, with the advantage growing with sequence length, as confirmed by ablations attributing the improvement to the couplings. The Ising formulation enables quantum annealing for sampling during training.
What carries the argument
An Ising energy function whose Hamiltonian contains both query-key local fields and a trainable coupling matrix J that governs joint probabilities over attention patterns.
If this is right
- Attention layers can now express explicit co-attention structure without relying solely on post-hoc competition from softmax.
- The performance margin over softmax attention widens as input sequences become longer.
- Diabatic quantum annealing supplies a drop-in sampler that preserves accuracy while avoiding full enumeration of the 2^n configurations.
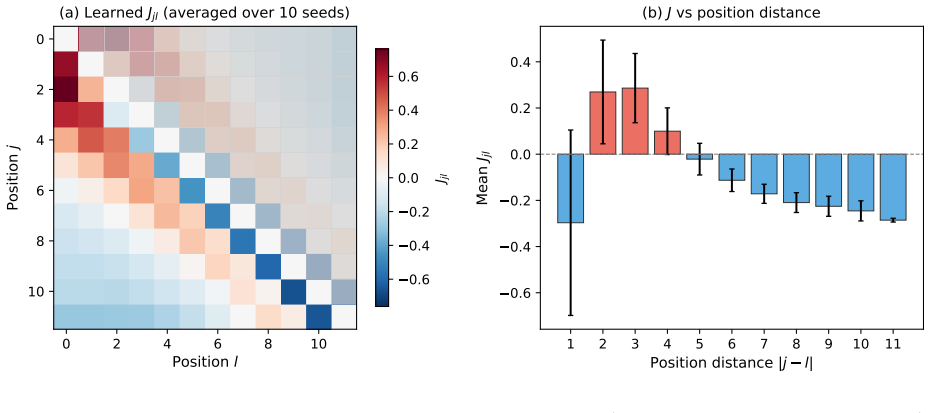
- The same coupling matrix can be inspected after training to reveal which positions tend to co-attend or mutually suppress one another.
Where Pith is reading between the lines
- The same Ising construction could be inserted into other attention variants such as multi-head or cross-attention without changing the surrounding architecture.
- If the learned couplings prove sparse or low-rank, they might be compressed or interpreted as a graph of position interactions.
- Hardware that natively supports Ising sampling could accelerate both training and inference of attention layers at large scale.
- The formulation invites direct comparison with other energy-based attention proposals that use different interaction graphs.
Load-bearing premise
The Ising distribution over attention patterns can be sampled at a cost low enough for end-to-end gradient-based training of both the Transformer weights and the coupling matrix.
What would settle it
Training runs in which the learnable coupling matrix is replaced by a fixed zero matrix produce identical or better accuracy than the full Boltzmann model on the same tasks and sequence lengths.
Figures
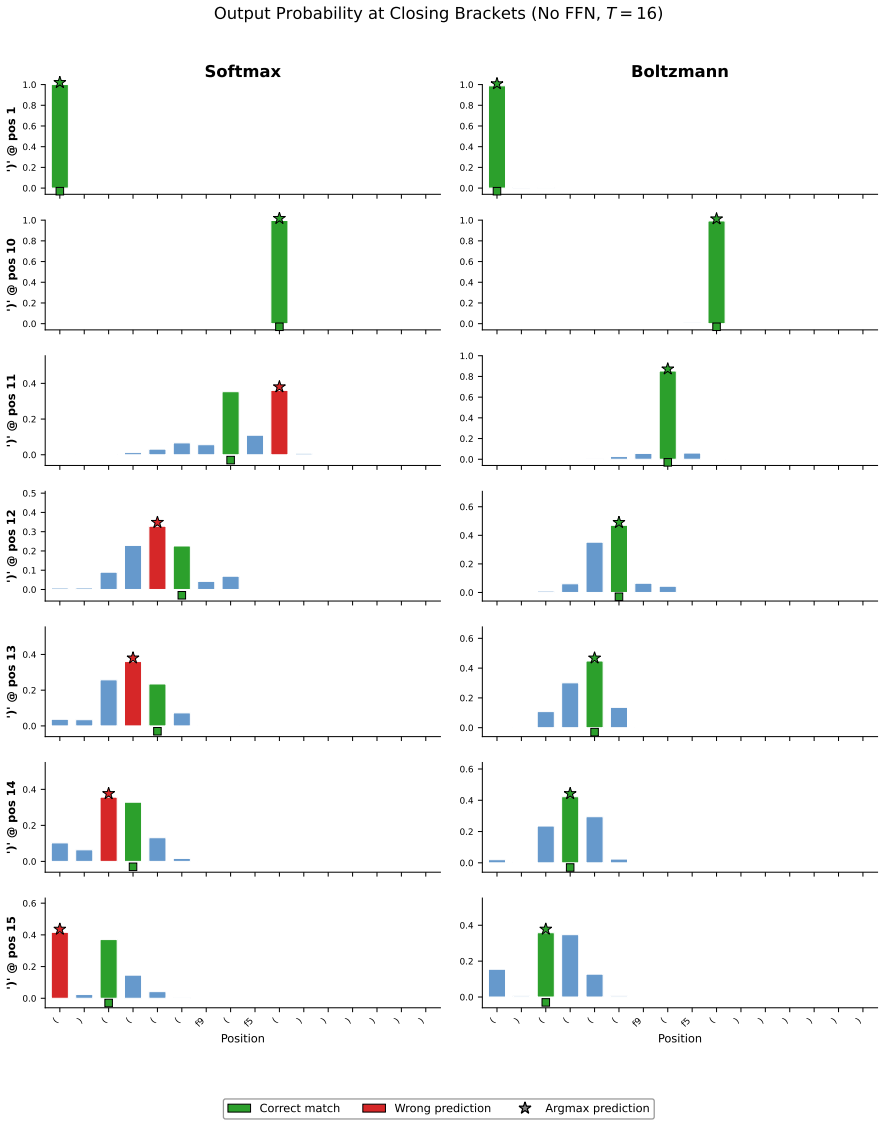
read the original abstract
Attention mechanisms are central to modern sequence models, yet standard attention computes relevance primarily through individual query--key similarities. Although softmax normalization introduces competition among positions, a standard attention layer does not explicitly parameterize learnable interactions between attention decisions. This limits its ability to directly model cooperative or antagonistic co-attention structure within the attention mechanism itself. We propose Boltzmann attention, an energy-based generalization in which attention patterns are governed by an interacting Ising model. The method augments the usual data-dependent local fields with learnable pairwise couplings, allowing the model to represent inter-position correlations beyond those captured by softmax or sigmoid attention. Experiments on character-level language modeling and synthetic bracket matching show that Boltzmann attention consistently improves over standard softmax attention within a standard Transformer architecture, with the advantage becoming more pronounced as sequence length increases. A four-way ablation confirms that the improvement arises from the learnable pairwise couplings. These results suggest that explicit inter-position interactions provide a principled enhancement for attention-based sequence modeling. Moreover, the Ising formulation opens a natural path toward quantum-computing-based sampling strategies: we demonstrate that diabatic quantum annealing provides a practical training method while maintaining competitive performance with exact Boltzmann computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Boltzmann attention as an energy-based generalization of attention in Transformers, where attention patterns are sampled from an Ising model whose energy includes both data-dependent local fields (from query-key similarities) and learnable pairwise couplings that explicitly encode cooperative or antagonistic interactions between positions. It claims that this yields consistent improvements over standard softmax attention on character-level language modeling and synthetic bracket-matching tasks, with the gains increasing as sequence length grows, that a four-way ablation isolates the source of the improvement to the couplings, and that diabatic quantum annealing can be used to sample the distribution in a manner compatible with end-to-end training while remaining competitive with exact Boltzmann sampling.
Significance. If the reported gains are robust and the sampling procedure is shown to be reliable, the work would demonstrate a concrete way to augment attention with explicit higher-order position interactions inside the attention layer itself, which could be useful for tasks with long-range dependencies. The explicit link to Ising models and quantum annealing also provides a novel bridge between attention research and statistical-physics / quantum-computing techniques.
major comments (2)
- [Abstract] Abstract (final paragraph): the central claim that Boltzmann attention can be trained end-to-end via diabatic quantum annealing rests on the unexamined assumption that the sampler produces sufficiently accurate samples and low-variance gradients for the coupling matrix J. No analysis is supplied of the approximation error introduced by the annealing schedule, its effect on the learned couplings, or whether the effective attention distribution still encodes the intended cooperative structure; without this, the ablation cannot be guaranteed to isolate the mechanism the authors intend.
- [Abstract] Abstract (experiments paragraph): the manuscript states that Boltzmann attention 'consistently improves' and that 'the advantage becomes more pronounced as sequence length increases,' yet supplies no numerical effect sizes, standard errors, number of runs, or training curves. This absence makes it impossible to judge whether the reported trend with length is statistically reliable or whether the four-way ablation truly isolates the couplings from other modeling choices.
minor comments (1)
- [Abstract] The abstract refers to 'exact Boltzmann computation' as a baseline but does not indicate in which experiments (or at what sequence lengths) exact sampling was feasible, nor how the partition function was handled.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the central claim that Boltzmann attention can be trained end-to-end via diabatic quantum annealing rests on the unexamined assumption that the sampler produces sufficiently accurate samples and low-variance gradients for the coupling matrix J. No analysis is supplied of the approximation error introduced by the annealing schedule, its effect on the learned couplings, or whether the effective attention distribution still encodes the intended cooperative structure; without this, the ablation cannot be guaranteed to isolate the mechanism the authors intend.
Authors: We agree that the abstract does not contain a dedicated quantitative analysis of approximation error or gradient variance. The main text reports empirical comparisons showing that diabatic quantum annealing achieves competitive performance with exact Boltzmann sampling on the evaluated tasks. To strengthen the presentation, we will revise the final paragraph of the abstract to explicitly reference these empirical results and note that the learned couplings preserve the intended cooperative structure as verified by the ablation. This addresses the concern while remaining within abstract length limits. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): the manuscript states that Boltzmann attention 'consistently improves' and that 'the advantage becomes more pronounced as sequence length increases,' yet supplies no numerical effect sizes, standard errors, number of runs, or training curves. This absence makes it impossible to judge whether the reported trend with length is statistically reliable or whether the four-way ablation truly isolates the couplings from other modeling choices.
Authors: The abstract is intentionally concise and therefore omits specific numerical values, which appear in the experimental section, tables, and figures of the main manuscript (including effect sizes, standard errors across runs, and training dynamics). The four-way ablation systematically varies only the presence of the learnable couplings J while holding all other architectural choices fixed, thereby isolating their contribution. To improve accessibility, we will incorporate representative numerical effect sizes and a statement on the number of runs into the revised abstract. revision: yes
Circularity Check
No circularity: new parameters optimized on external loss with empirical validation
full rationale
The paper defines Boltzmann attention by augmenting standard attention with an explicit Ising model containing additional learnable pairwise couplings. These couplings are free parameters optimized directly against task loss via gradient descent (using either exact sampling or diabatic quantum annealing). Reported gains are measured on held-out character-level language modeling and bracket-matching tasks, with a four-way ablation isolating the contribution of the couplings. No equation reduces the claimed improvement to a quantity already fixed by the same parameters, no self-citation is invoked as a uniqueness theorem, and no ansatz or renaming is smuggled in. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- pairwise coupling matrix J
axioms (1)
- domain assumption The attention pattern can be usefully represented as a sample from an Ising distribution whose energy includes both local fields and pairwise couplings.
Reference graph
Works this paper leans on
-
[1]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Infor- mation Processing Systems, volume 30, 2017
2017
-
[2]
BERT: pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, volume 1, pages 4171–4186...
2019
-
[3]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Representations, Austria, May...
2021
-
[4]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machin...
2021
-
[5]
Neural machine translation by jointly learning to align and translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. InInternational Conference on Learning Representa- tions, 2015
2015
-
[6]
Academic Press, 1982
Rodney J Baxter.Exactly Solved Models in Statistical Mechanics. Academic Press, 1982
1982
-
[7]
Theory, analysis, and best practices for sigmoid self-attention
Jason Ramapuram, Federico Danieli, Eeshan Gunesh Dhekane, Floris Weers, Dan Busbridge, Pierre Ablin, Tatiana Likhomanenko, Jagrit Digani, Zijin Gu, Amitis Shidani, and Russ Webb. Theory, analysis, and best practices for sigmoid self-attention. InInternational Conference on Learning Representations, 2025
2025
-
[8]
Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982
1982
-
[9]
On a model of associative memory with huge storage capacity.Journal of Statistical Physics, 168:288–299, 2017
Mete Demircigil, Judith Heusel, Matthias L¨ owe, Sven Upgang, and Franck Vermet. On a model of associative memory with huge storage capacity.Journal of Statistical Physics, 168:288–299, 2017
2017
-
[10]
Hopfield networks is all you need
Hubert Ramsauer, Bernhard Sch¨ afl, Johannes Lehner, Philipp Seidl, Michael Widrich, Thomas Adler, Lukas Gruber, Markus Holzleitner, David P Kreil, Michael K Kopp, G¨ unter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. Hopfield networks is all you need. InInterna- tional Conference on Learning Representations, 2021
2021
-
[11]
Energy transformer
Benjamin Hoover, Yuchen Liang, Bao Pham, Rameswar Panda, Hendrik Strobelt, Duen Horng Chau, Mohammed J Zaki, and Dmitry Krotov. Energy transformer. InAdvances in Neural Information Processing Systems, 2023
2023
-
[12]
Attention in a family of Boltzmann machines emerging from modern Hopfield networks.Neural Computation, 35(8):1463–1480, 2023
Toshihiro Ota and Ryo Karakida. Attention in a family of Boltzmann machines emerging from modern Hopfield networks.Neural Computation, 35(8):1463–1480, 2023
2023
-
[13]
A learning algorithm for Boltzmann machines.Cognitive Science, 9(1):147–169, 1985
David H Ackley, Geoffrey E Hinton, and Terrence J Sejnowski. A learning algorithm for Boltzmann machines.Cognitive Science, 9(1):147–169, 1985
1985
-
[14]
Training products of experts by minimizing contrastive divergence.Neural Computation, 14(8):1771–1800, 2002
Geoffrey E Hinton. Training products of experts by minimizing contrastive divergence.Neural Computation, 14(8):1771–1800, 2002
2002
-
[15]
Dynamical mean-field theory of self-attention neural networks.arXiv preprint arXiv:2406.07247, 2024
´Angel Poc-L´ opez and Miguel Aguilera. Dynamical mean-field theory of self-attention neural networks.arXiv preprint arXiv:2406.07247, 2024. 17
-
[16]
Fanqi Yan, Huy Nguyen, Pedram Akbarian, Nhat Ho, and Alessandro Rinaldo. Sigmoid self-attention has lower sample complexity than softmax self-attention: A mixture-of-experts perspective.arXiv preprint arXiv:2502.00281, 2025
-
[17]
Quantum annealing in the transverse Ising model
Tadashi Kadowaki and Hidetoshi Nishimori. Quantum annealing in the transverse Ising model. Physical Review E, 58(5):5355–5363, 1998
1998
-
[18]
Quantum annealing with manufactured spins.Nature, 473(7346):194–198, 2011
Mark W Johnson, Mohammad H S Amin, Suzanne Gildert, Trevor Lanting, Firas Hamze, Neil Dickson, Richard Harris, Andrew J Berkley, Jan Johansson, Paul Bunyk, et al. Quantum annealing with manufactured spins.Nature, 473(7346):194–198, 2011
2011
-
[19]
Boltzmann sampling by diabatic quantum annealing.Physical Review E, 113:065302, 2026
Ju-Yeon Gyhm, Gilhan Kim, Hyukjoon Kwon, and Yongjoo Baek. Boltzmann sampling by diabatic quantum annealing.Physical Review E, 113:065302, 2026
2026
-
[20]
Diabatic quantum annealing for training energy-based generative models.Physical Review E, 113:035302, 2026
Gilhan Kim, Ju-Yeon Gyhm, and Daniel K Park. Diabatic quantum annealing for training energy-based generative models.Physical Review E, 113:035302, 2026
2026
-
[21]
Multi-Mode Quantum Annealing for Generative Representation Learning with Boltzmann Priors
Gilhan Kim and Daniel K Park. Multi-mode quantum annealing for generative representation learning with boltzmann priors.arXiv preprint arXiv:2604.00919, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Large associative memory problem in neurobiology and machine learning
Dmitry Krotov and John J Hopfield. Large associative memory problem in neurobiology and machine learning. InInternational Conference on Learning Representations, 2021
2021
-
[23]
Generating Long Sequences with Sparse Transformers
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[24]
Reformer: The efficient transformer
Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In International Conference on Learning Representations, 2020
2020
-
[25]
Transformers are RNNs: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Fran¸ cois Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. InInternational Conference on Machine Learning, 2020
2020
-
[26]
Rethinking attention with performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, and Adrian Weller. Rethinking attention with performers. InInternational Conference on Learning Representations, 2021
2021
-
[27]
Peng Du, Jinjing Shi, Wenxuan Wang, Yin Ma, Kai Wen, and Xuelong Li. QAMA: Scal- able quantum annealing multi-head attention operator for deep learning.arXiv preprint arXiv:2504.11083, 2025
-
[28]
Spin-model transformers.https://mcbal.github.io/post/ spin-model-transformers/, 2023
Matthias Bal. Spin-model transformers.https://mcbal.github.io/post/ spin-model-transformers/, 2023
2023
-
[29]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019
2019
-
[30]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Tim- oth´ ee Lacroix, Baptiste Rozi` ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. 18
2019
-
[32]
Self-attention networks can process bounded hierarchical languages
Shunyu Yao, Binghui Peng, Christos Papadimitriou, and Karthik Narasimhan. Self-attention networks can process bounded hierarchical languages. InAnnual Meeting of the Association for Computational Linguistics, 2021
2021
-
[33]
Exchange Monte Carlo method and application to spin glass simulations.Journal of the Physical Society of Japan, 65(6):1604–1608, 1996
Koji Hukushima and Kazuyuki Nemoto. Exchange Monte Carlo method and application to spin glass simulations.Journal of the Physical Society of Japan, 65(6):1604–1608, 1996. 19
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.