Speculative Rollback Correction for Quality-Diverse Web Agent Imitation
Pith reviewed 2026-06-27 10:51 UTC · model grok-4.3
The pith
Speculative rollback correction collects 977 verifier-passing trajectories and 9183 next-action examples for web agents by using fixed-horizon branch review.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
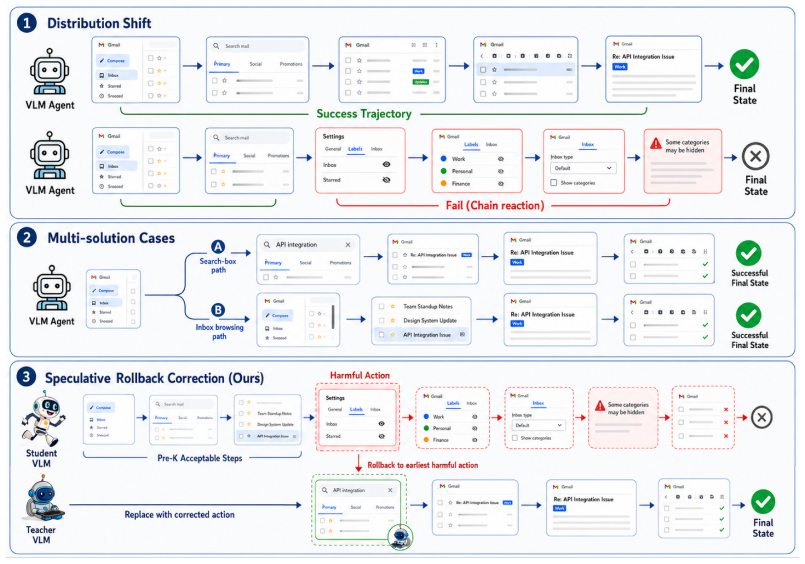
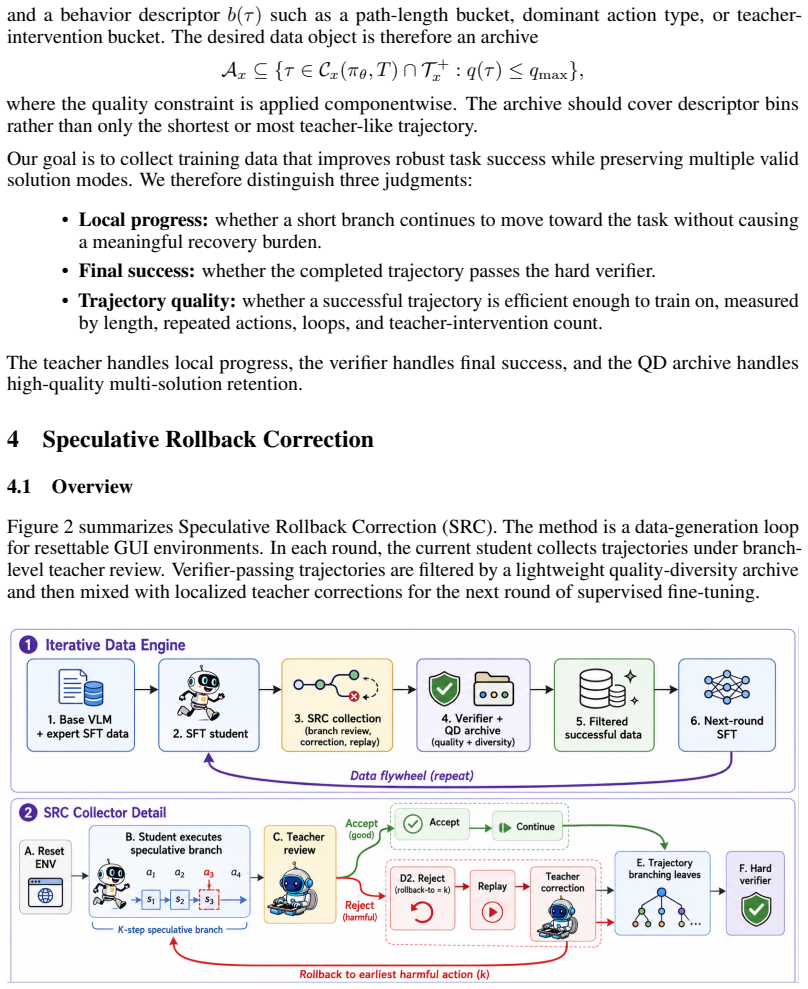
Speculative Rollback Correction (SRC) is a branch-level imitation framework for resettable agent environments: the student executes a short speculative segment before teacher review, the teacher localizes the first harmful deviation only when local progress breaks, rollback preserves useful prefixes, successful rollouts are filtered by a hard verifier and retained in a lightweight quality-diversity archive, and the resulting data supports next-action supervised fine-tuning on both localized corrections and verifier-passing trajectories.
What carries the argument
fixed-horizon branch review with rollback to the first harmful deviation and retention of verifier-passing trajectories in a quality-diversity archive
If this is right
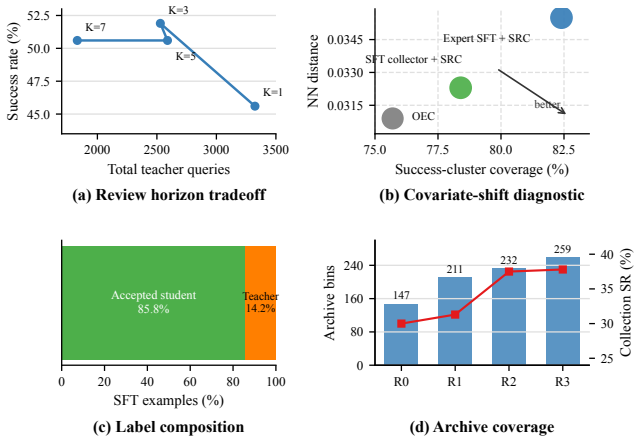
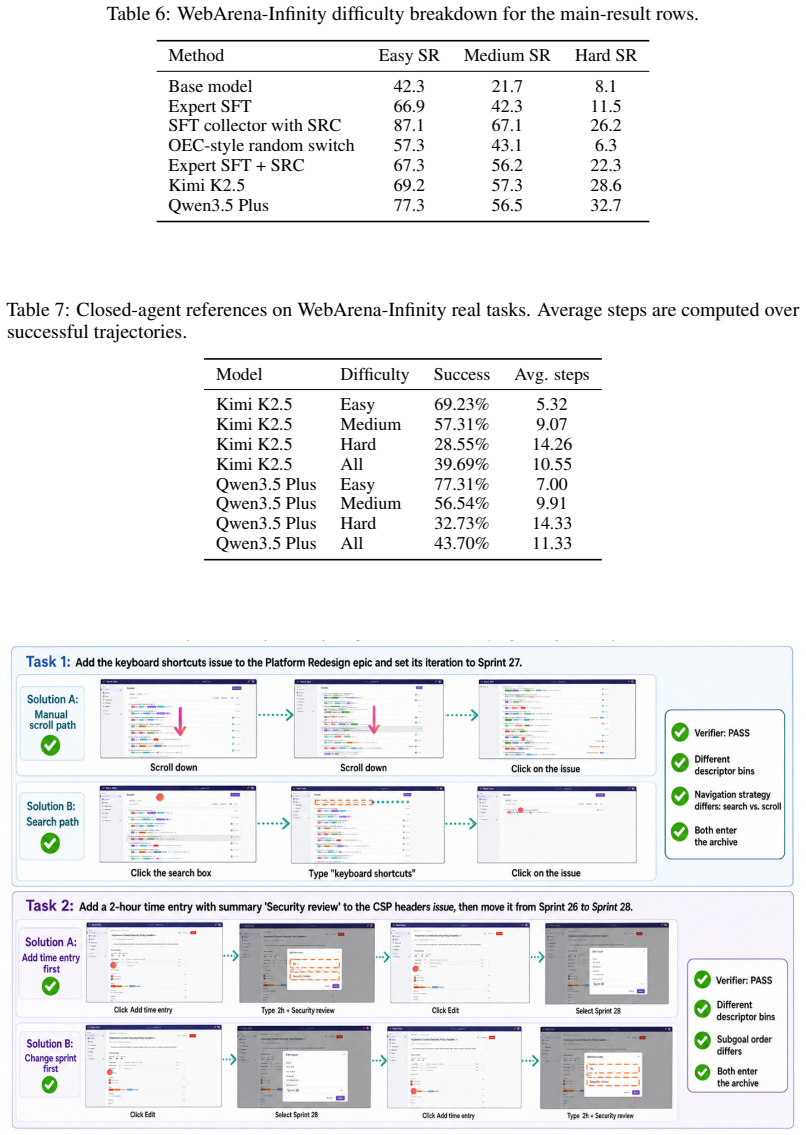
- SRC collects 977 verifier-passing trajectories and 9183 next-action examples on WebArena-Infinity.
- Fixed-horizon review improves the recovery-versus-query tradeoff over step-level review.
- The quality-diversity archive retains multiple verifier-passing solution variants.
- The collected data supports next-action supervised fine-tuning on both localized corrections and successful trajectories.
Where Pith is reading between the lines
- The rollback mechanism could be tested in other resettable domains such as simulated robotics or game environments.
- Retaining diverse verified trajectories may help agent policies avoid collapse to a single rigid path.
- The archive could be combined with online reinforcement learning to refine the collected examples further.
Load-bearing premise
The web environment must be resettable so that rollback preserves useful prefixes without side effects, and a hard verifier must exist that can reliably identify successful rollouts.
What would settle it
A controlled run on WebArena-Infinity in which fixed-horizon review produces fewer verifier-passing trajectories per expert query than step-level review, or fails to retain solution variants, would refute the claimed tradeoff improvement.
Figures


read the original abstract
Training interactive web agents through imitation learning from expert trajectories has emerged as a highly effective approach. However, determining the optimal timing for expert intervention presents a critical challenge in this context. Delayed intervention often leads to the accumulation of early-stage errors, pushing the page state into an irrecoverable regime. Conversely, premature or excessive intervention causes the agent to become overly reliant on expert policies, trapping the model in local optima characterized by a single, rigid trajectory. We propose Speculative Rollback Correction (SRC), a branch-level imitation framework for resettable agent environments. Instead of requesting teacher labels at every visited state or correcting only after a completed trajectory, SRC uses fixed-horizon branch review: the student executes a short speculative segment before teacher review, and the teacher localizes the first harmful deviation only when local progress breaks. Rollback preserves useful prefixes, while successful rollouts are filtered by a hard verifier and retained in a lightweight quality-diversity archive. The resulting data supports next-action supervised fine-tuning on both localized corrections and verifier-passing trajectories. On WebArena-Infinity, SRC collects 977 verifier-passing trajectories and 9,183 next-action examples; fixed-horizon review improves the recovery-versus-query tradeoff over step-level review while retaining verifier-passing solution variants. Code is available at https://github.com/LongkunHao/SRC_gui_agent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Speculative Rollback Correction (SRC), a branch-level imitation framework for web agents. SRC has the student execute short fixed-horizon speculative segments, after which the teacher localizes the first harmful deviation only when local progress breaks; rollback preserves useful prefixes and a hard verifier filters successful rollouts into a lightweight quality-diversity archive. The resulting data is used for next-action supervised fine-tuning. On WebArena-Infinity the method collects 977 verifier-passing trajectories and 9,183 next-action examples and reports an improved recovery-versus-query tradeoff relative to step-level review while retaining solution variants. Code is released.
Significance. If the rollback and verifier assumptions hold and the empirical gains are reproducible, SRC would provide a practical mechanism for balancing early error accumulation against over-reliance on expert trajectories in imitation learning for interactive agents, while the public code release directly supports reproducibility.
major comments (2)
- [Abstract] Abstract: the central empirical claims (977 verifier-passing trajectories, 9,183 next-action examples, and improved tradeoff) are stated without any description of experimental protocol, number of runs, baseline implementations, or statistical measures, leaving the quantitative results only partially supported.
- [Abstract] Abstract: the method description relies on the hard verifier correctly identifying successful rollouts and on rollback restoring exact pre-speculation state without side effects, yet no implementation details, state-equivalence checks, or ablation on verifier noise are supplied; both assumptions are load-bearing for the reported data collection and tradeoff improvement.
minor comments (1)
- The abstract could reference the specific section or algorithm number containing the SRC procedure or pseudocode to improve readability.
Simulated Author's Rebuttal
We thank the referee for highlighting issues with the abstract's presentation of results and assumptions. We will revise the abstract in the next version to better contextualize the quantitative claims and clarify key assumptions while preserving its brevity. Details below address each comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (977 verifier-passing trajectories, 9,183 next-action examples, and improved tradeoff) are stated without any description of experimental protocol, number of runs, baseline implementations, or statistical measures, leaving the quantitative results only partially supported.
Authors: The abstract summarizes the main outcomes for brevity. Full experimental protocol appears in Section 4: evaluation uses WebArena-Infinity with 5 independent runs (different seeds), the step-level review baseline is implemented following the protocol in prior work, and results report means with standard deviations. The 977 trajectories and 9,183 examples are aggregates across these runs. We will revise the abstract to include a short clause noting 'across 5 runs on WebArena-Infinity' to improve self-containment. revision: yes
-
Referee: [Abstract] Abstract: the method description relies on the hard verifier correctly identifying successful rollouts and on rollback restoring exact pre-speculation state without side effects, yet no implementation details, state-equivalence checks, or ablation on verifier noise are supplied; both assumptions are load-bearing for the reported data collection and tradeoff improvement.
Authors: Section 3.1 explicitly states that SRC targets resettable environments where rollback restores exact prior state by construction (no side effects). The hard verifier is the environment-provided task success checker standard in WebArena. State management and equivalence are handled via the released code at https://github.com/LongkunHao/SRC_gui_agent. No ablation on verifier noise is included because the framework assumes a reliable verifier; noisy-verifier behavior is an orthogonal extension. We will add one sentence to the abstract noting the resettable-environment assumption. revision: partial
Circularity Check
No circularity: empirical data collection on external benchmark with no equations or self-referential derivations
full rationale
The paper describes an empirical method (SRC) for collecting trajectories and next-action examples on WebArena-Infinity, reporting raw counts (977 verifier-passing trajectories, 9,183 examples) and a tradeoff comparison. No equations, fitted parameters, or derivations are present. Results are direct measurements on an external benchmark rather than reductions of outputs to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The work is self-contained against external benchmarks, satisfying the default expectation of no circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- speculative segment length
axioms (1)
- domain assumption Web environments permit state rollback that preserves useful prefixes.
Reference graph
Works this paper leans on
-
[1]
Kai-Wei Chang, Akshay Krishnamurthy, Alekh Agarwal, Hal Daumé III, and John Langford
URL https://papers.nips.cc/paper/5956-schedul ed-sampling-for-sequence-prediction-with-recurrent-neural-networks. Kai-Wei Chang, Akshay Krishnamurthy, Alekh Agarwal, Hal Daumé III, and John Langford. Learning to search better than your teacher. InProceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learn...
2058
-
[2]
Robots that can adapt like animals.Nat., 521(7553):503–507, 2015
doi: 10.1038/nature14422. Hal Daumé III, John Langford, and Daniel Marcu. Search-based structured prediction.Machine Learning, 75(3):297–325,
-
[3]
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, and Jie Tang
URL https://papers.nips.cc/paper_files/paper/2023/ha sh/5950bf290a1570ea401bf98882128160-Abstract-Datasets_and_Benchmarks.html. Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, and Jie Tang. CogAgent: A visual language model for GUI agents. InProceedings of the IEEE/CVF Conference on C...
2023
-
[4]
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried
URL https://proceedi ngs.neurips.cc/paper_files/paper/2023/hash/7cc1005ec73cfbaac9fa21192b622 507-Abstract-Conference.html. Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. InProc...
2023
-
[5]
V isual W eb A rena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
doi: 10.18653/v1/2024.acl-long.50. URL https://aclanthology.org/2024.acl-long.50/. Alex M. Lamb, Anirudh Goyal, Ying Zhang, Saizheng Zhang, Aaron C. Courville, and Yoshua Bengio. Professor forcing: A new algorithm for training recurrent networks. InAdvances in Neural Information Processing Systems, volume 29,
-
[7]
URLhttps://arxiv.org/abs/2512.14895. 10 Joel Lehman and Kenneth O. Stanley. Abandoning objectives: Evolution through the search for novelty alone.Evolutionary Computation, 19(2):189–223,
-
[9]
URLhttps://arxiv.org/abs/1504.04909. Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. WebGPT: Browser-assisted question-answering wit...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
WebGPT: Browser-assisted question-answering with human feedback
URLhttps://arxiv.org/abs/2112.09332. Justin K. Pugh, Lisa B. Soros, and Kenneth O. Stanley. Quality diversity: A new frontier for evolutionary computation.Frontiers in Robotics and AI, 3:40,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
doi: 10.3389/frobt.2016.00040. URLhttps://www.frontiersin.org/articles/10.3389/frobt.2016.00040/full. Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. Agent Q: Advanced reasoning and learning for autonomous AI agents.arXiv preprint arXiv:2408.07199,
-
[12]
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
URLhttps://arxiv.org/abs/2408.07199. Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Xinyue Yang, Jiadai Sun, Yu Yang, Shuntian Yao, Tianjie Zhang, Wei Xu, Jie Tang, and Yuxiao Dong. WebRL: Training LLM web agents via self-evolving online curriculum reinforcement learning.arXiv preprint arXiv:2411.02337,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URLhttps://arxiv.org/abs/2411.02337. Stephane Ross and J. Andrew Bagnell. Reinforcement and imitation learning via interactive no-regret learning.arXiv preprint arXiv:1406.5979,
-
[14]
Reinforcement and Imitation Learning via Interactive No-Regret Learning
URLhttps://arxiv.org/abs/1406.5979. Stephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pages 627–635. PMLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URLhttps://arxiv.org/abs/2305.16291. Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking multimodal agents for open- ended tasks in real computer environmen...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan
URL https://papers.nips.cc/paper_files/paper/2024/hash/5d413 e48f84dc61244b6be550f1cd8f5-Abstract-Datasets_and_Benchmarks_Track.html. Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop: Towards scalable real-world web interaction with grounded language agents. InAdvances in Neural Information Processing Systems, volume 35,
2024
-
[18]
11 Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L
URL https://papers.nips.cc/paper_files/paper /2022/hash/82ad13ec01f9fe44c01cb91814fd7b8c-Abstract-Conference.html. 11 Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, volume ...
2022
-
[20]
URL https://arxiv.org/abs/2307.13854. A SRC Collection Details A.1 Teacher Review and Correction Interface For each branch, the teacher reviewer receives the task instruction, recent pre-branch context, the pre-action observation for each student action, the executed action dictionaries, the student rationale when available, and the post-branch observatio...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.