Fantastic Scientific Agents and How to Build Them: AgentBuild for Rietveld Refinement
Pith reviewed 2026-06-27 07:10 UTC · model grok-4.3
The pith
AgentBuild compiles scientific LLM agents from scientist-authored contracts of rubrics, curricula, and knowledge bases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
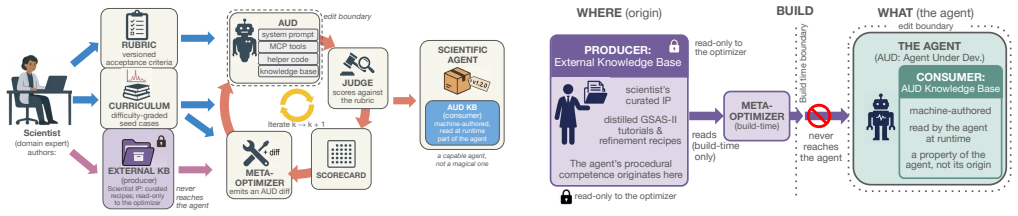
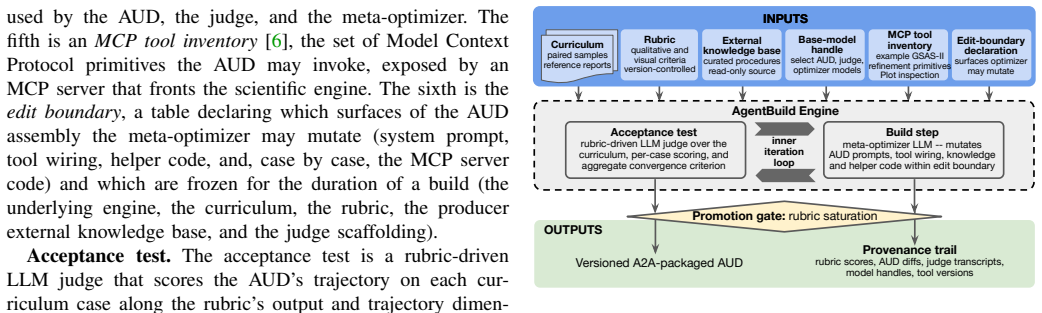
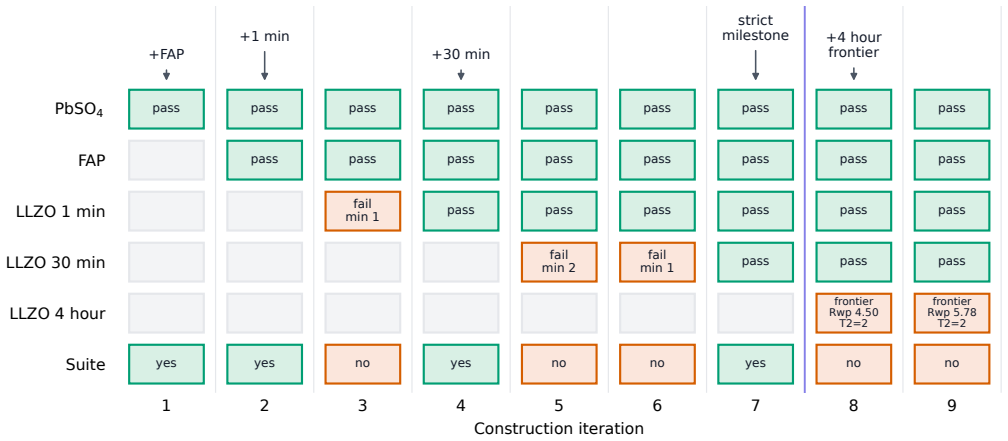
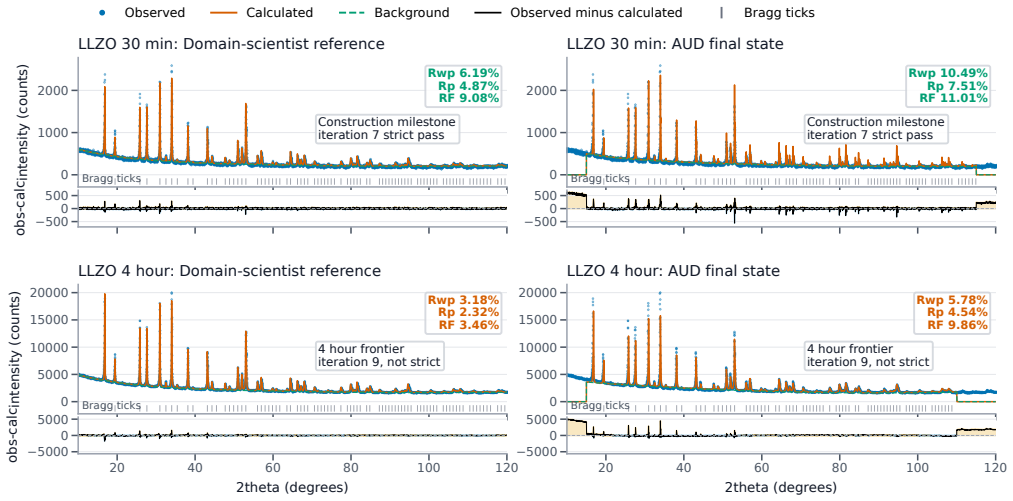
AgentBuild builds a scientific agent directly from a contract the scientist authors; the contract consists of a version-controlled rubric, a difficulty-graded curriculum, and a curated external knowledge base, and a rubric-driven judge gates a meta-optimizer coding agent that performs edits only inside declared boundaries, demonstrated by a blank-harness run on GSAS-II that advances through an LLZO signal-to-noise ladder to the four-hour scan case.
What carries the argument
The contract, a version-controlled rubric plus difficulty-graded curriculum plus curated knowledge base, which a rubric-driven judge uses to gate edits by a meta-optimizer coding agent.
If this is right
- The identical rubric can score both the credibility of the Rietveld fit and the scope of the agent's trajectory, so frontier cases become contract failures rather than pattern-fitting failures.
- Re-running AgentBuild with an updated base model becomes a re-tune step rather than a full rebuild.
- The scientist's authored contract remains the durable, version-controlled asset across changes in underlying models.
- Workflow-scope limits surface explicitly as rubric scores instead of remaining hidden inside model behavior.
Where Pith is reading between the lines
- The same contract format could be written for other data-analysis tasks that currently rely on ad-hoc LLM prompting.
- Version control of the contract would allow teams to track changes in scientific standards separately from changes in model weights.
- If the rubric is made public, different groups could compare agents built from identical contracts on different base models.
Load-bearing premise
A written rubric can capture enough of the scientist's judgment to let the judge reliably decide when an edited agent is acceptable.
What would settle it
Re-run AgentBuild on the same contract but with a newer base model and check whether the new agent reaches the four-hour LLZO scan case with the same or higher rubric score without any change to the contract text.
Figures

read the original abstract
As scientific workflows shift from deterministic executables to LLM-based agents, the development practices on offer, such as fine-tuning, reinforcement learning, and prompt-and-go, bury the scientist's judgment. We propose treating agent construction as a workflow stage and introduce AgentBuild, which builds a scientific agent from a contract the scientist authors. The contract is a version-controlled rubric, a difficulty-graded curriculum, and a curated external knowledge base. A rubric-driven judge gates a meta-optimizer coding agent that edits the agent within a declared boundary, so the build compiles the agent, not the scientist's judgment. We instantiate this for Rietveld refinement of X-ray diffraction data through GSAS-II behind MCP and A2A, where a blank-harness construction run progresses through a lithium lanthanum zirconium oxide (LLZO) signal-to-noise ladder, reaches the 4 hour scan as a frontier case, and exposes the workflow-scope limits that remain. The same rubric that rewards credible fits also scores trajectory scope, making the frontier a contract failure rather than a pattern-fitting failure. As base models evolve, re-running AgentBuild is a re-tune, not a rebuild, and the scientist's authored contract remains the durable asset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes treating scientific agent construction as an explicit workflow stage via AgentBuild, which generates an agent from a scientist-authored contract (version-controlled rubric + difficulty-graded curriculum + curated external knowledge base). A rubric-driven external judge gates a meta-optimizer coding agent that edits the target agent only inside declared boundaries, so that the build process itself does not embed ongoing human judgment. The method is instantiated for Rietveld refinement of LLZO X-ray data inside GSAS-II (via MCP and A2A), with the claim that a blank-harness run traverses a signal-to-noise ladder, reaches the 4-hour scan as a contract frontier rather than a fitting failure, and remains re-runnable when base models change.
Significance. If the workflow can be shown to function as described, the separation of contract authoring from automated build, the re-use of the same rubric for both fit quality and trajectory scope, and the explicit versioning of the contract as the durable asset would constitute a concrete advance over prompt-and-go or fine-tuning practices. The re-runnability claim when base models evolve is particularly valuable for long-term scientific tooling.
major comments (1)
- [Abstract] Abstract: the central empirical claim that a construction run 'reaches the 4 hour scan as a frontier case' and 'exposes the workflow-scope limits' is stated without any quantitative metrics, success rates, error bars, baseline comparisons, or trajectory statistics. This absence makes it impossible to evaluate whether the rubric-driven judge actually gates the meta-optimizer as intended or whether the frontier identification is reproducible.
minor comments (2)
- [Abstract] The acronyms MCP and A2A are used without expansion or citation on first appearance.
- The manuscript would benefit from an explicit diagram or pseudocode showing the exact gating loop between judge, meta-optimizer, and agent under construction.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and the recommendation for major revision. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that a construction run 'reaches the 4 hour scan as a frontier case' and 'exposes the workflow-scope limits' is stated without any quantitative metrics, success rates, error bars, baseline comparisons, or trajectory statistics. This absence makes it impossible to evaluate whether the rubric-driven judge actually gates the meta-optimizer as intended or whether the frontier identification is reproducible.
Authors: We agree that the abstract presents the outcome of the blank-harness construction run in primarily qualitative language. The full manuscript describes the signal-to-noise ladder progression and the 4-hour scan as the point at which the rubric-driven judge halts further improvement, but the abstract does not include the supporting quantitative details (e.g., per-level success rates, judge score thresholds, number of meta-optimizer iterations, or trajectory length statistics). In the revised version we will expand the abstract to report these metrics explicitly, drawing from the experimental results already present in the body of the paper. This change will make the reproducibility of the frontier identification clearer without altering the underlying claims. revision: yes
Circularity Check
No significant circularity detected in the workflow proposal
full rationale
The paper introduces AgentBuild as a methodological workflow for constructing LLM-based scientific agents from an externally authored contract (rubric, curriculum, and knowledge base), with a rubric-driven judge gating a meta-optimizer coding agent. No mathematical derivations, first-principles predictions, or equations are presented that reduce to inputs by construction. The Rietveld/GSAS-II instantiation is described as an empirical demonstration of the workflow progressing through a signal-to-noise ladder and identifying frontier cases as contract failures, without any fitted parameters renamed as predictions or self-definitional steps. The central claim of separating scientist judgment via the contract and judge is independent and does not rely on self-citation chains or ansatzes smuggled from prior work. The approach is self-contained against external benchmarks as a proposed construction process rather than a closed derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A ter- minology for scientific workflow systems,
F. Suter, T. Coleman, ˙I. Altinta¸ s, R. M. Badia, B. Balis, K. Chard, I. Colonnelli, E. Deelman, P. Di Tommaso, T. Fahringeret al., “A ter- minology for scientific workflow systems,”Future Generation Computer Systems, vol. 174, p. 107974, 2026
2026
-
[2]
Do large language models speak scientific workflows?
O. Yildiz and T. Peterka, “Do large language models speak scientific workflows?” 2024. [Online]. Available: https://arxiv.org/abs/2412.10606
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,” 2024, introduces Group Relative Policy Optimization (GRPO). [Online]. Available: https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, X. Zhang, X. Yu, Y . Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, and A. Liu, “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,”Nature, vol. 645, pp. 633–638, 2025, author list truncated; see arXiv for full DeepSeek-AI roste...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
GSAS-II: the genesis of a modern open-source all purpose crystallography software package,
B. H. Toby and R. B. V on Dreele, “GSAS-II: the genesis of a modern open-source all purpose crystallography software package,”Journal of Applied Crystallography, vol. 46, no. 2, pp. 544–549, 2013
2013
-
[6]
Model context protocol specification,
Anthropic, “Model context protocol specification,” https: //modelcontextprotocol.io/specification, 2024, open protocol for LLM-tool integration; specification version 2025-11-25 (revision dated 2025-11-25 in the canonical schema repository at https://github.com/modelcontextprotocol/specification). Originally announced by Anthropic November 2024
2024
-
[7]
Agent2agent (A2A) pro- tocol specification,
A2A Project, Google, and Linux Foundation, “Agent2agent (A2A) pro- tocol specification,” https://a2a-protocol.org/latest/specification/, 2025, open protocol for inter-agent communication; specification version 1.0.0 (announced by Google at Cloud Next on 2025-04-09; contributed to the Linux Foundation in June 2025; v0.3 released 2025-07-31). Canonical sche...
2025
-
[8]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging LLM-as-a-judge with MT-bench and chatbot arena,” inAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), Datasets and Benchmarks Track, 2023. [Online]. Available: https://arxiv.org/abs/2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Applying the FAIR principles to computational workflows,
S. R. Wilkinson, M. Aloqalaa, K. Belhajjame, M. R. Crusoe, B. de Paula Kinoshita, L. Gadelha, D. Garijo, O. J. R. Gustafsson, N. Juty, S. Kanwal, F. Z. Khan, J. Köster, K. Peters-von Gehlen, L. Pouchard, R. K. Rannow, S. Soiland-Reyes, N. Soranzo, S. Sufi, Z. Sun, B. Vilne, M. A. Wouters, D. Yuen, and C. Goble, “Applying the FAIR principles to computation...
2025
-
[10]
PROV-AGENT: Unified provenance for tracking AI agent interactions in agentic workflows,
R. Souza, A. Gueroudji, S. DeWitt, D. Rosendo, T. Ghosal, R. Ross, P. Balaprakash, and R. Ferreira da Silva, “PROV-AGENT: Unified provenance for tracking AI agent interactions in agentic workflows,” inProceedings of the 21st IEEE International Conference on e-Science (eScience 2025), Chicago, IL, USA, 2025
2025
-
[11]
The FAIR guiding principles for scientific data management and stewardship,
M. D. Wilkinson, M. Dumontier, I. J. Aalbersberg, G. Appleton, M. Axton, A. Baak, N. Blomberg, J.-W. Boiten, L. B. da Silva Santos, P. E. Bourneet al., “The FAIR guiding principles for scientific data management and stewardship,”Scientific Data, vol. 3, p. 160018, 2016
2016
-
[12]
Introducing the FAIR principles for research software,
M. Barker, N. P. Chue Hong, D. S. Katz, A.-L. Lamprecht, C. Martinez- Ortiz, F. Psomopoulos, J. Harrow, L. J. Castro, M. Gruenpeter, P. A. Martinez, and T. Honeyman, “Introducing the FAIR principles for research software,”Scientific Data, vol. 9, no. 1, p. 622, 2022
2022
-
[13]
FAIR computational workflows,
C. Goble, S. Cohen-Boulakia, S. Soiland-Reyes, D. Garijo, Y . Gil, M. R. Crusoe, K. Peters, and D. Schober, “FAIR computational workflows,” Data Intelligence, vol. 2, no. 1-2, pp. 108–121, 2020
2020
-
[14]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR 2023),
2023
-
[15]
ReAct: Synergizing Reasoning and Acting in Language Models
[Online]. Available: https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” inAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), 2023. [Online]. Available: https://arxiv.org/abs/2303. 11366
2023
-
[17]
Pegasus, a workflow management system for science automation,
E. Deelman, K. Vahi, G. Juve, M. Rynge, S. Callaghan, P. J. Maechling, R. Mayani, W. Chen, R. Ferreira da Silva, M. Livny, and K. Wenger, “Pegasus, a workflow management system for science automation,” Future Generation Computer Systems, vol. 46, pp. 17–35, 2015
2015
-
[18]
Snakemake—a scalable bioinformatics workflow engine,
J. Köster and S. Rahmann, “Snakemake—a scalable bioinformatics workflow engine,”Bioinformatics, vol. 28, no. 19, pp. 2520–2522, 2012
2012
-
[19]
Nextflow enables reproducible computational work- flows,
P. Di Tommaso, M. Chatzou, E. W. Floden, P. P. Barja, E. Palumbo, and C. Notredame, “Nextflow enables reproducible computational work- flows,”Nature Biotechnology, vol. 35, no. 4, pp. 316–319, 2017
2017
-
[20]
Methods included: Standardizing computational reuse and portability with the Common Workflow Language,
M. R. Crusoe, S. Abeln, A. Iosup, P. Amstutz, J. Chilton, N. Tijani ´c, H. Ménager, S. Soiland-Reyes, B. Gavrilovi ´c, and C. Goble, “Methods included: Standardizing computational reuse and portability with the Common Workflow Language,”Communications of the ACM, vol. 65, no. 6, pp. 54–63, 2022
2022
-
[21]
Parsl: Pervasive parallel programming in Python,
Y . Babuji, A. Woodard, Z. Li, D. S. Katz, B. Clifford, R. Kumar, L. Lacinski, R. Chard, J. M. Wozniak, I. Foster, M. Wilde, and K. Chard, “Parsl: Pervasive parallel programming in Python,” inProceedings of the 28th International Symposium on High-Performance Parallel and Distributed Computing (HPDC ’19). Phoenix, AZ, USA: Association for Computing Machin...
2019
-
[22]
funcX: A federated function serving fabric for science,
R. Chard, Y . Babuji, Z. Li, T. Skluzacek, A. Woodard, B. Blaiszik, I. Foster, and K. Chard, “funcX: A federated function serving fabric for science,” inProceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing (HPDC ’20). Stockholm, Sweden: Association for Computing Machinery, 2020, pp. 65–76
2020
-
[23]
The Galaxy platform for accessible, reproducible and collaborative biomedical anal- yses: 2018 update,
E. Afgan, D. Baker, B. Batut, M. van den Beek, D. Bouvier, M. ˇCech, J. Chilton, D. Clements, N. Coraor, B. A. Grüning, A. Guerler, J. Hillman-Jackson, S. Hiltemann, V . Jalili, H. Rasche, N. Soranzo, J. Goecks, J. Taylor, A. Nekrutenko, and D. Blankenberg, “The Galaxy platform for accessible, reproducible and collaborative biomedical anal- yses: 2018 upd...
2018
-
[24]
Galaxy: a comprehensive approach for supporting accessible, reproducible, and transparent com- putational research in the life sciences,
J. Goecks, A. Nekrutenko, and J. Taylor, “Galaxy: a comprehensive approach for supporting accessible, reproducible, and transparent com- putational research in the life sciences,”Genome Biology, vol. 11, no. 8, p. R86, 2010
2010
-
[25]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
O. Khattab, A. Singhvi, P. Maheshwari, Z. Zhang, K. Santhanam, S. Vardhamanan, S. Haq, A. Sharma, T. T. Joshi, H. Moazam, H. Miller, M. Zaharia, and C. Potts, “DSPy: Compiling declarative language model calls into self-improving pipelines,” inInternational Conference on Learning Representations (ICLR 2024), 2024. [Online]. Available: https://arxiv.org/abs...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
L. A. Agrawal, S. Tan, D. Soylu, N. Ziems, R. Khare, K. Opsahl-Ong, A. Singhvi, H. Shandilya, M. J. Ryan, M. Jiang, C. Potts, K. Sen, A. G. Dimakis, I. Stoica, D. Klein, M. Zaharia, and O. Khattab, “GEPA: Reflective prompt evolution can outperform reinforcement learning,” inInternational Conference on Learning Representations (ICLR 2026, Oral), 2025. [Onl...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Mathematical discoveries from program search with large language models,
B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. R. Ruiz, J. S. Ellenberg, P. Wang, O. Fawzi, P. Kohli, and A. Fawzi, “Mathematical discoveries from program search with large language models,”Nature, vol. 625, pp. 468–475, 2024
2024
-
[28]
Eureka: Human-Level Reward Design via Coding Large Language Models
Y . J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Jayaraman, Y . Zhu, L. Fan, and A. Anandkumar, “Eureka: Human-level reward design via coding large language models,” inInternational Conference on Learning Representations (ICLR), 2024. [Online]. Available: https://arxiv.org/abs/2310.12931
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
A profile refinement method for nuclear and magnetic structures,
H. M. Rietveld, “A profile refinement method for nuclear and magnetic structures,”Journal of Applied Crystallography, vol. 2, no. 2, pp. 65–71, 1969
1969
-
[30]
Anthropic, “Claude,” https://www.anthropic.com, 2026, accessed: 2026
2026
-
[31]
Autonomous electrochemistry platform with real-time normality testing of voltammetry measurements using ML,
A. Al-Najjar, N. S. V . Rao, C. A. Bridges, S. Dai, and A. Walters, “Autonomous electrochemistry platform with real-time normality testing of voltammetry measurements using ML,” inProceedings of the 2024 IEEE 20th International Conference on e-Science (e-Science). IEEE, 2024, pp. 1–10, oRNL ACL system paper; Pyro RPC framework and ML normality testing
2024
-
[32]
An autonomous chemistry lab for accelerated materials discov- ery and innovation,
Oak Ridge National Laboratory, “An autonomous chemistry lab for accelerated materials discov- ery and innovation,” https://www.ornl.gov/project/ autonomous-chemistry-lab-accelerated-materials-discovery-and-innovation, 2022, accessed: 2026-06-08
2022
-
[33]
Cross-facility orchestration of electrochemistry experiments and computations,
A. Al-Najjar, N. S. V . Rao, C. A. Bridges, and S. Dai, “Cross-facility orchestration of electrochemistry experiments and computations,” in Workshops of the International Conference on High Performance Com- puting, Network, Storage, and Analysis (SC-W 2023). New York, NY , USA: ACM, Nov. 2023, pp. 2118–2125
2023
-
[34]
The INTERSECT open federated architecture for the laboratory of the future,
C. Engelmann, O. Kuchar, S. Boehm, M. J. Brim, T. Naughton, S. Somnath, S. Atchley, J. Lange, B. Mintz, and E. Arenholz, “The INTERSECT open federated architecture for the laboratory of the future,” inCommunications in Computer and Information Science (CCIS): Accelerating Science and Engineering Discoveries Through Integrated Research Infrastructure for E...
2022
-
[35]
LLM agents for interactive workflow provenance: Reference architecture and evaluation methodology,
R. Souza, T. Poteet, B. Etz, D. Rosendo, A. Gueroudji, W. Shin, P. Bal- aprakash, and R. Ferreira da Silva, “LLM agents for interactive workflow provenance: Reference architecture and evaluation methodology,” in Proceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis (WORKS25), S...
2025
-
[36]
ChemOS 2.0: An orchestration architecture for chemical self-driving laboratories,
M. Sim, M. G. Vakili, F. Strieth-Kalthoff, H. Hao, R. J. Hickman, S. Miret, S. Pablo-García, and A. Aspuru-Guzik, “ChemOS 2.0: An orchestration architecture for chemical self-driving laboratories,”Matter, vol. 7, no. 9, pp. 2959–2977, 2024
2024
-
[37]
MADSci: A modular python-based framework to enable autonomous science,
R. D. Lewis, T. S. Ginsburg, D. Ozgulbas, C. Stone, A. Stroka, A. Cleary, I. T. Foster, and N. Paulson, “MADSci: A modular python-based framework to enable autonomous science,”Journal of Open Source Software, vol. 11, no. 119, p. 9416, 2026, argonne MADSci framework: https://github.com/AD-SDL/MADSci
2026
-
[38]
Employing artificial intelligence to steer exascale workflows with Colmena,
L. Ward, J. G. Pauloski, V . Hayot-Sasson, Y . Babuji, A. Brace, R. Chard, K. Chard, R. Thakur, and I. Foster, “Employing artificial intelligence to steer exascale workflows with Colmena,”The International Journal of High Performance Computing Applications, vol. 39, no. 1, pp. 52–64, 2025
2025
-
[39]
Towards a modular architecture for science factories,
R. Vescovi, T. Ginsburg, K. Hippe, D. Ozgulbas, C. Stone, A. Stroka, R. Butler, B. Blaiszik, T. Brettin, K. Chard, M. Hereld, A. Ramanathan, R. Stevens, A. Vriza, J. Xu, Q. Zhang, and I. Foster, “Towards a modular architecture for science factories,”Digital Discovery, vol. 2, no. 6, pp. 1980–1998, 2023
1980
-
[40]
Augmenting large language models with chemistry tools,
A. M. Bran, S. Cox, O. Schilter, C. Baldassari, A. D. White, and P. Schwaller, “Augmenting large language models with chemistry tools,” Nature Machine Intelligence, vol. 6, no. 5, pp. 525–535, 2024, chem- Crow LLM-with-tools chemistry agent
2024
-
[41]
Autonomous chemical research with large language models,
D. A. Boiko, R. MacKnight, B. Kline, and G. Gomes, “Autonomous chemical research with large language models,”Nature, vol. 624, no. 7992, pp. 570–578, 2023, coscientist GPT-4 driven autonomous chem- istry agent
2023
-
[42]
An autonomous laboratory for the accelerated synthesis of inorganic materials,
N. J. Szymanski, B. Rendy, Y . Fei, R. E. Kumar, T. He, D. Milsted, M. J. McDermott, M. Gallant, E. D. Cubuk, A. Merchant, H. Kim, A. Jain, C. J. Bartel, K. Persson, Y . Zeng, and G. Ceder, “An autonomous laboratory for the accelerated synthesis of inorganic materials,”Nature, vol. 624, no. 7990, pp. 86–91, 2023, a-Lab autonomous materials synthesis platform
2023
-
[43]
J. Gottweis, W.-H. Weng, A. Daryin, T. Tu, A. Palepu, P. Sirkovic, A. Myaskovsky, F. Weissenberger, K. Rong, R. Tanno, K. Saab, D. Popovici, J. Blum, F. Zhang, K. Chou, A. Hassidim, B. Gokturk, A. Vahdat, P. Kohli, Y . Matias, A. Carroll, K. Kulkarni, N. Tomasev, Y . Guan, V . Dhillon, E. D. Vaishnav, B. Lee, T. R. D. Costa, J. R. Penadés, G. Peltz, Y . X...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
C. Lu, C. Lu, R. T. Lange, J. Foerster, J. Clune, and D. Ha, “The AI scientist: Towards fully automated open-ended scientific discovery,” 2024, sakana AI technical report. [Online]. Available: https://arxiv.org/abs/2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Automated crystal structure analysis based on blackbox opti- misation,
Y . Ozaki, Y . Suzuki, T. Hawai, K. Saito, M. Onishi, and K. Ono, “Automated crystal structure analysis based on blackbox opti- misation,”npj Computational Materials, vol. 6, no. 1, p. 75, 2020, bBO-Rietveld implementation and seed data: https://github.com/ quantumbeam/BBO-Rietveld
2020
-
[46]
Optuna: A next- generation hyperparameter optimization framework,
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next- generation hyperparameter optimization framework,” inProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019, pp. 2623–2631
2019
-
[47]
Adaptively driven X-ray diffraction guided by machine learning for autonomous phase identification,
N. J. Szymanski, C. J. Bartel, Y . Zeng, M. Diallo, H. Kim, and G. Ceder, “Adaptively driven X-ray diffraction guided by machine learning for autonomous phase identification,”npj Computational Materials, vol. 9, no. 1, p. 31, 2023, adaptive-XRD release with Aeris UAI driver: https: //github.com/njszym/Adaptive-XRD
2023
-
[48]
Crystallography companion agent for high-throughput materials discovery,
P. M. Maffettone, L. Banko, P. Cui, Y . Lysogorskiy, M. A. Little, D. Olds, A. Ludwig, and A. I. Cooper, “Crystallography companion agent for high-throughput materials discovery,”Nature Computational Science, vol. 1, no. 4, pp. 290–297, 2021
2021
-
[49]
Dara: Automated multiple-hypothesis phase identification and refinement from powder X-ray diffraction,
Y . Fei, M. J. McDermott, C. L. Rom, S. Wang, and G. Ceder, “Dara: Automated multiple-hypothesis phase identification and refinement from powder X-ray diffraction,”Chemistry of Materials, vol. 38, no. 3, pp. 1364–1376, 2026
2026
-
[50]
ChatGPT,
OpenAI, “ChatGPT,” https://www.openai.com, 2026, accessed: 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.