PolicyGuard: Towards Test-time and Step-level Adversary (Backdoor) Defense for Reinforcement Learning Agent
Pith reviewed 2026-06-27 07:22 UTC · model grok-4.3
The pith
PolicyGuard detects backdoor triggers in reinforcement learning agents at individual time steps during testing without internal model access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
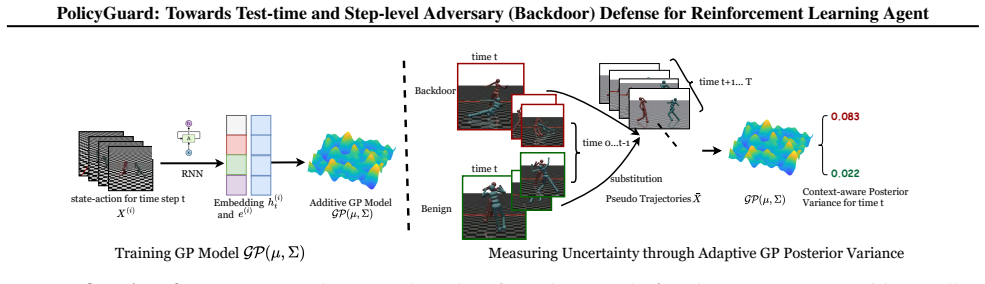
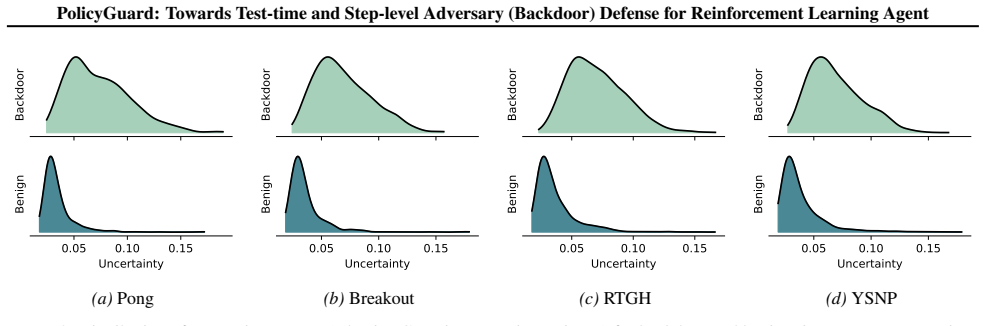
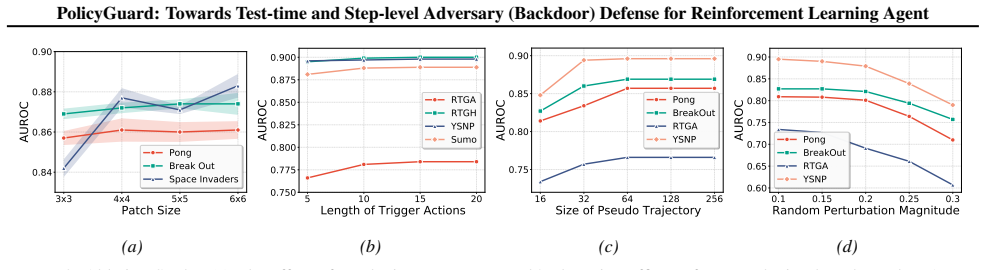
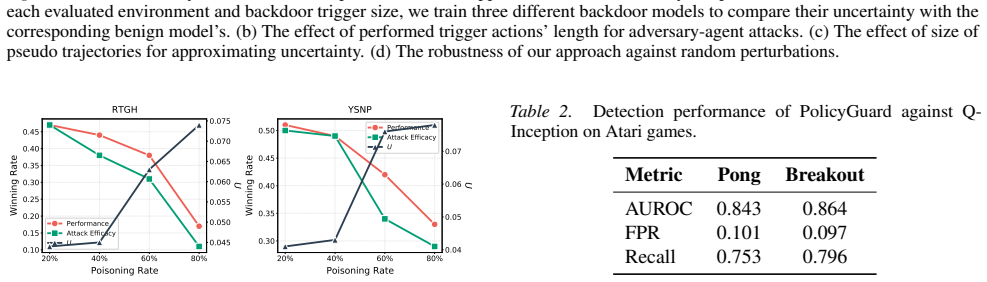
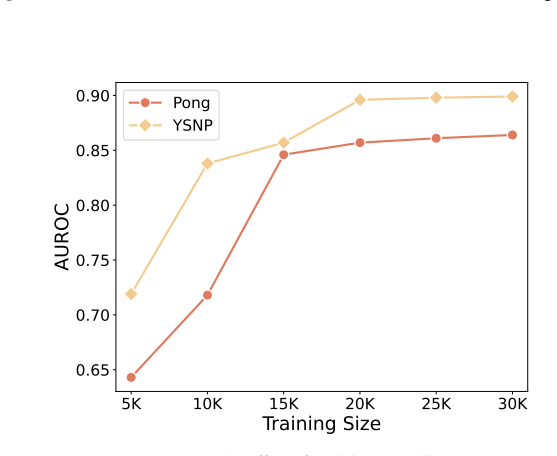
PolicyGuard is a test-time step-level backdoor defense for RL agents that leverages Gaussian Process posterior variance on adapted pseudo trajectories to enable uncertainty computation for individual time steps, with theoretical foundations to explain the efficacy of this measure, and achieves state-of-the-art detection performance in most cases with average AUROC of 0.856 for perturbation-based attacks and 0.859 for adversary-agent attacks across seven RL games.
What carries the argument
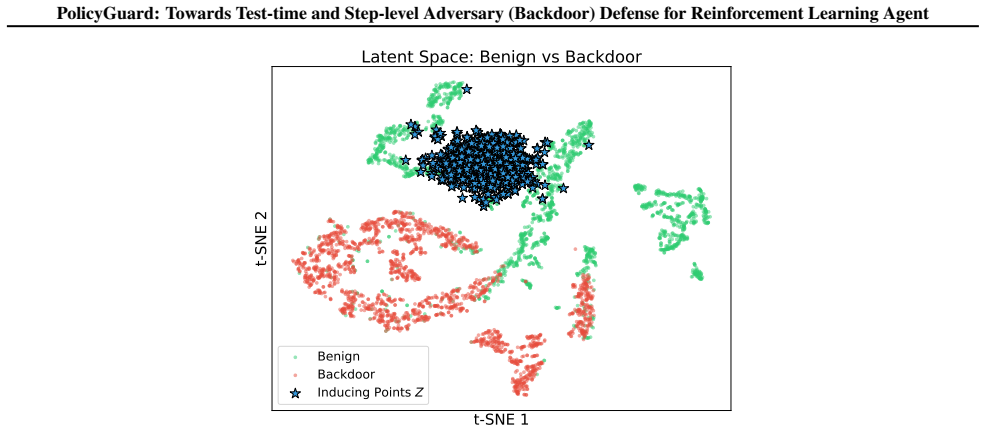
Gaussian Process posterior variance on adapted pseudo trajectories, used to flag backdoor triggers at specific time steps.
If this is right
- RL agents can be defended at deployment time without requiring access to internal parameters or retraining.
- Detection occurs at the granularity of single time steps rather than entire trajectories or models.
- The same approach applies to both perturbation-based attacks and adversary-agent attacks.
- Theoretical analysis supports why posterior variance serves as an effective indicator for this task.
Where Pith is reading between the lines
- The method could be combined with existing training-time defenses to create layered protection for RL systems.
- It might apply to detecting other forms of adversarial behavior in sequential decision-making beyond backdoors.
- Deployment in safety-critical RL domains such as robotics would benefit from the step-level granularity for immediate intervention.
Load-bearing premise
Gaussian Process posterior variance on adapted pseudo trajectories reliably indicates the presence of backdoor triggers at individual time steps.
What would settle it
A set of test trajectories containing known backdoor triggers where the computed Gaussian Process posterior variance shows no consistent elevation or correlation with trigger presence.
Figures

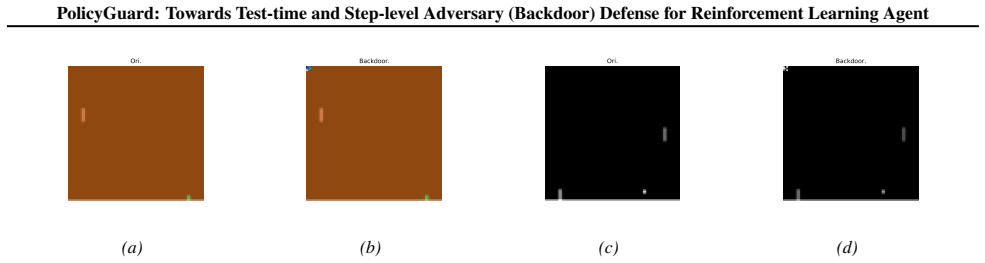
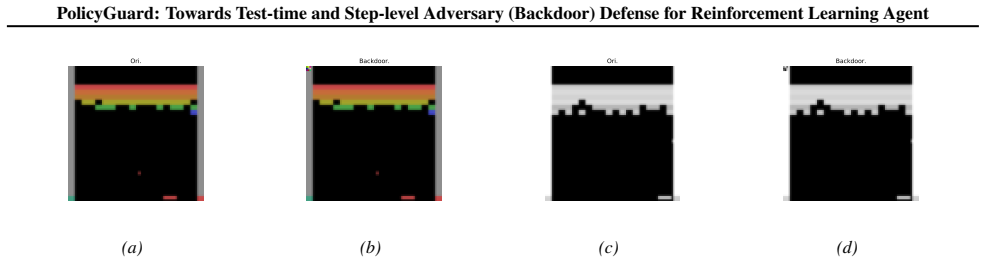
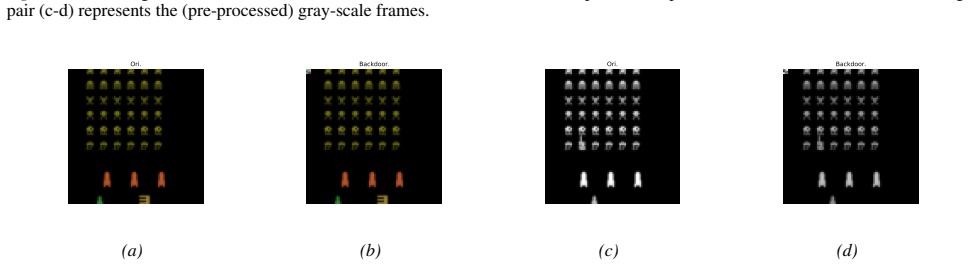

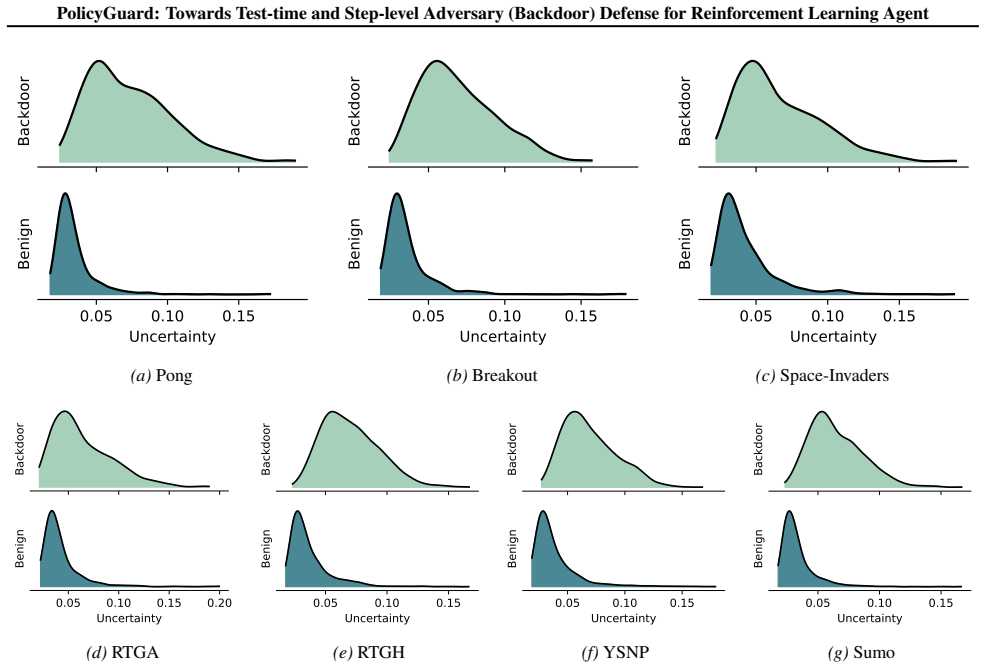
read the original abstract
While real-world applications of reinforcement learning (RL) are becoming increasingly popular, the security of RL systems deserve more attention and exploration. In particular, recent work has revealed that RL agents are vulnerable to backdoor attacks, where a victim agent behaves normally under standard conditions but executes malicious actions when a specific trigger is activated. Existing backdoor defenses for RL either require access to the agent's internal parameters, operate only at the model or trajectory level, or are limited to specific attack types. To ensure the security of RL agents, we propose \texttt{PolicyGuard}, a \textit{test-time step-level} backdoor defense which leverages Gaussian Process (GP) posterior variance and adapts pseudo trajectories to enable uncertainty computation for individual time step. Besides, we also provide theoretical foundations to explain the efficacy of GP posterior variance. Extensive experiments across seven RL games demonstrate that PolicyGuard achieves state-of-the-art detection performance in most cases, with average AUROC of 0.856 for perturbation-based attacks and 0.859 for adversary-agent attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PolicyGuard, a test-time step-level backdoor defense for RL agents. It adapts pseudo trajectories and computes Gaussian Process (GP) posterior variance to detect backdoor triggers at individual time steps, provides theoretical foundations explaining the efficacy of this variance measure, and reports state-of-the-art detection across seven RL games (average AUROC 0.856 for perturbation-based attacks and 0.859 for adversary-agent attacks).
Significance. If the core assumptions hold, this would be a meaningful advance for RL security: it operates at test time without internal parameter access, provides per-step granularity, and addresses a broader range of attacks than prior defenses. Explicit provision of theoretical foundations is a positive feature that attempts to ground the detection mechanism.
major comments (2)
- [Method and theoretical foundations sections] The central claim depends on the adaptation procedure (described in the method) producing pseudo trajectories whose distribution matches the clean policy except precisely at trigger locations, and on the GP posterior variance (with the chosen kernel) reflecting epistemic uncertainty induced by the trigger rather than model mismatch or aleatoric effects. The theoretical foundations section does not derive the variance spike under explicitly stated MDP/reward assumptions, leaving the per-step detection claim vulnerable to the three failure modes noted in the stress test; this is load-bearing because the reported AUROCs rest on this mechanism working as described.
- [Experiments section] Experiments section: the average AUROCs are presented as evidence of SOTA performance, yet no ablation or sensitivity analysis is shown for the adaptation procedure or GP hyperparameters. Without these, it is unclear whether the results support the general claim or are tied to the specific seven games and attack implementations.
minor comments (2)
- [Method section] Notation for the adapted pseudo trajectories and the exact form of the GP posterior variance should be introduced with a single consistent symbol set to aid readability.
- [Abstract and title] The abstract and title use slightly varying phrasing for 'adversary (Backdoor)'; standardize terminology throughout.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method and theoretical foundations sections] The central claim depends on the adaptation procedure (described in the method) producing pseudo trajectories whose distribution matches the clean policy except precisely at trigger locations, and on the GP posterior variance (with the chosen kernel) reflecting epistemic uncertainty induced by the trigger rather than model mismatch or aleatoric effects. The theoretical foundations section does not derive the variance spike under explicitly stated MDP/reward assumptions, leaving the per-step detection claim vulnerable to the three failure modes noted in the stress test; this is load-bearing because the reported AUROCs rest on this mechanism working as described.
Authors: We agree that the theoretical foundations would benefit from greater explicitness. In the revised manuscript we will add a dedicated subsection that states the MDP and reward assumptions under which the GP posterior variance is guaranteed to spike at trigger locations (while remaining low elsewhere). We will also include a short discussion of the three failure modes referenced in the stress test, with arguments showing why the adaptation procedure and kernel choice mitigate them under the stated assumptions. A more detailed derivation of the variance expression will be provided in the appendix. revision: yes
-
Referee: [Experiments section] Experiments section: the average AUROCs are presented as evidence of SOTA performance, yet no ablation or sensitivity analysis is shown for the adaptation procedure or GP hyperparameters. Without these, it is unclear whether the results support the general claim or are tied to the specific seven games and attack implementations.
Authors: We acknowledge that the current experiments lack ablations. In the revision we will add (i) sensitivity plots for the main GP hyperparameters (length-scale, output-scale, and noise variance) and (ii) ablation results on the adaptation procedure parameters (number of pseudo-trajectories and adaptation steps). We will also report AUROC on two additional environments to support the claim of generality beyond the original seven games. revision: yes
Circularity Check
No significant circularity; derivation relies on standard GP techniques
full rationale
The provided abstract and context describe PolicyGuard as leveraging established Gaussian Process posterior variance on adapted pseudo trajectories, with theoretical foundations claimed for its efficacy. No equations or sections in the visible text reduce the central detection claim to a self-definition, a fitted parameter renamed as prediction, or a load-bearing self-citation chain. The approach builds on independent GP properties and external RL benchmarks rather than deriving its key performance metric by construction from its own inputs. This is the expected self-contained case for a method paper using a standard statistical tool.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Forty-first International Conference on Machine Learning , year=
SHINE: Shielding backdoors in deep reinforcement learning , author=. Forty-first International Conference on Machine Learning , year=
-
[2]
Jensen's inequality , author=
-
[3]
Uber die abgrenzung der eigenwerte einer matrix , author=
-
[4]
Posterior Variance Analysis of Gaussian Processes with Application to Average Learning Curves
Posterior variance analysis of Gaussian processes with application to average learning curves , author=. arXiv preprint arXiv:1906.01404 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[5]
Advances in Neural Information Processing Systems , volume=
Bird: generalizable backdoor detection and removal for deep reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Proceedings of the 35th annual computer security applications conference , pages=
Strip: A defence against trojan attacks on deep neural networks , author=. Proceedings of the 35th annual computer security applications conference , pages=
-
[7]
arXiv preprint arXiv:2302.03251 , year=
Scale-up: An efficient black-box input-level backdoor detection via analyzing scaled prediction consistency , author=. arXiv preprint arXiv:2302.03251 , year=
-
[8]
2019 IEEE symposium on security and privacy (SP) , pages=
Neural cleanse: Identifying and mitigating backdoor attacks in neural networks , author=. 2019 IEEE symposium on security and privacy (SP) , pages=. 2019 , organization=
2019
-
[9]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Policycleanse: Backdoor detection and mitigation for competitive reinforcement learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[10]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Black-box detection of backdoor attacks with limited information and data , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[11]
arXiv preprint arXiv:2105.00579 , year=
Backdoorl: Backdoor attack against competitive reinforcement learning , author=. arXiv preprint arXiv:2105.00579 , year=
-
[12]
2020 57th ACM/IEEE Design Automation Conference (DAC) , pages=
Trojdrl: evaluation of backdoor attacks on deep reinforcement learning , author=. 2020 57th ACM/IEEE Design Automation Conference (DAC) , pages=. 2020 , organization=
2020
-
[13]
Playing Atari with Deep Reinforcement Learning
Playing atari with deep reinforcement learning , author=. arXiv preprint arXiv:1312.5602 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems , volume=
Edge: Explaining deep reinforcement learning policies , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Emergent Complexity via Multi-Agent Competition
Emergent complexity via multi-agent competition , author=. arXiv preprint arXiv:1710.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Sutton , doi =
David Silver and Satinder Singh and Doina Precup and Richard S. Sutton , doi =. Reward is enough , url =. Artificial Intelligence , keywords =. 2021 , Bdsk-Url-1 =
2021
-
[17]
and Wu, Celimuge and Low, Yeh-Ching , journal=
Rasheed, Faizan and Yau, Kok-Lim Alvin and Noor, Rafidah Md. and Wu, Celimuge and Low, Yeh-Ching , journal=. Deep Reinforcement Learning for Traffic Signal Control: A Review , year=
-
[18]
Neural computation , volume=
Long short-term memory , author=. Neural computation , volume=
-
[19]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , pages =
Adversarial Inception Backdoor Attacks against Reinforcement Learning , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , pages =. 2025 , series =
2025
-
[20]
The handbook of brain theory and neural networks , year=
Convolutional networks for images, speech, and time series , author=. The handbook of brain theory and neural networks , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Provable defense against backdoor policies in reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
2017 IEEE 60th international midwest symposium on circuits and systems (MWSCAS) , pages=
Gate-variants of gated recurrent unit (GRU) neural networks , author=. 2017 IEEE 60th international midwest symposium on circuits and systems (MWSCAS) , pages=. 2017 , organization=
2017
-
[23]
Deep Reinforcement Learning framework for Autonomous Driving
Deep reinforcement learning framework for autonomous driving , author=. arXiv preprint arXiv:1704.02532 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Proceedings of the AAAI conference on artificial intelligence , volume=
End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[25]
Submitted to Transactions on Machine Learning Research , year=
Plan2Cleanse: Test-Time Backdoor Defense via Monte-Carlo Planning in Deep Reinforcement Learning , author=. Submitted to Transactions on Machine Learning Research , year=
-
[26]
Artificial Intelligence Review , volume=
Reinforcement learning in robotic applications: a comprehensive survey , author=. Artificial Intelligence Review , volume=. 2022 , publisher=
2022
-
[27]
arXiv preprint arXiv:2104.02361 , year=
Backdoor attack in the physical world , author=. arXiv preprint arXiv:2104.02361 , year=
-
[28]
Advances in Neural Information Processing Systems , volume=
Posterior and computational uncertainty in Gaussian processes , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Advances in Neural Information Processing Systems , year=
GPyTorch: Blackbox Matrix-Matrix Gaussian Process Inference with GPU Acceleration , author=. Advances in Neural Information Processing Systems , year=
-
[30]
BMC medical research methodology , volume=
Estimating the sample mean and standard deviation from the sample size, median, range and/or interquartile range , author=. BMC medical research methodology , volume=. 2014 , publisher=
2014
-
[31]
arXiv preprint arXiv:2110.02797 , year=
Adversarial robustness comparison of vision transformer and mlp-mixer to cnns , author=. arXiv preprint arXiv:2110.02797 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.