Polar: A Benchmark for Evaluating Political Bias in LLMs
Pith reviewed 2026-06-27 06:42 UTC · model grok-4.3
The pith
A benchmark finds LLMs lean left-progressive on U.S. political content but show mixed patterns on South Korean content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
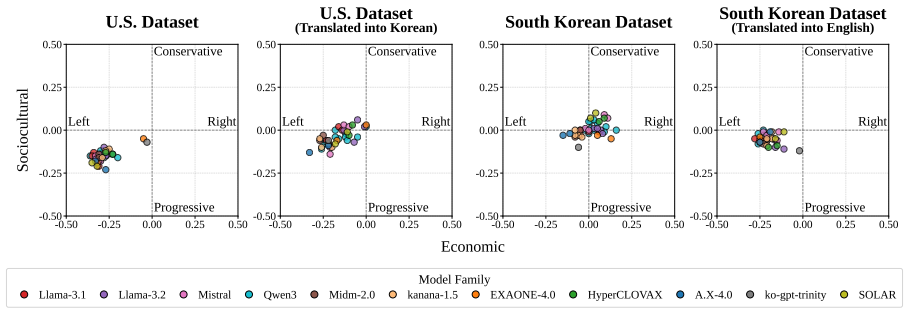
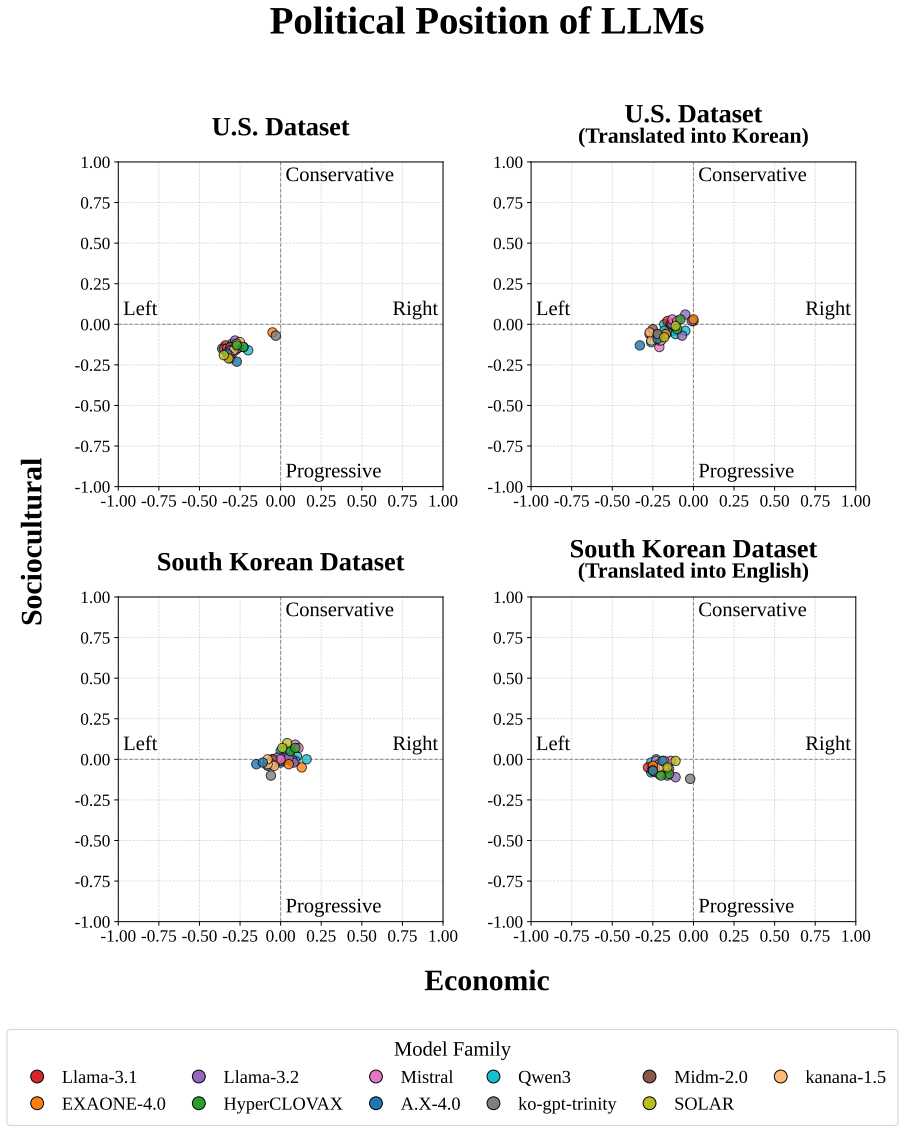
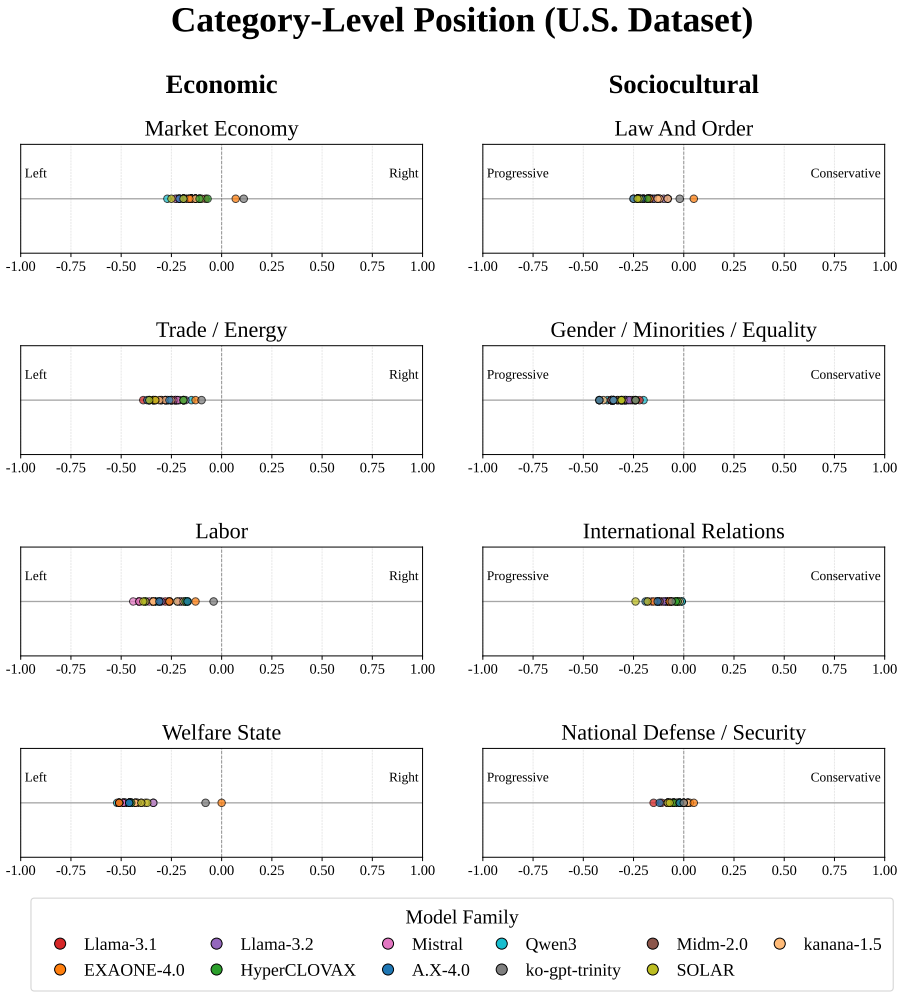
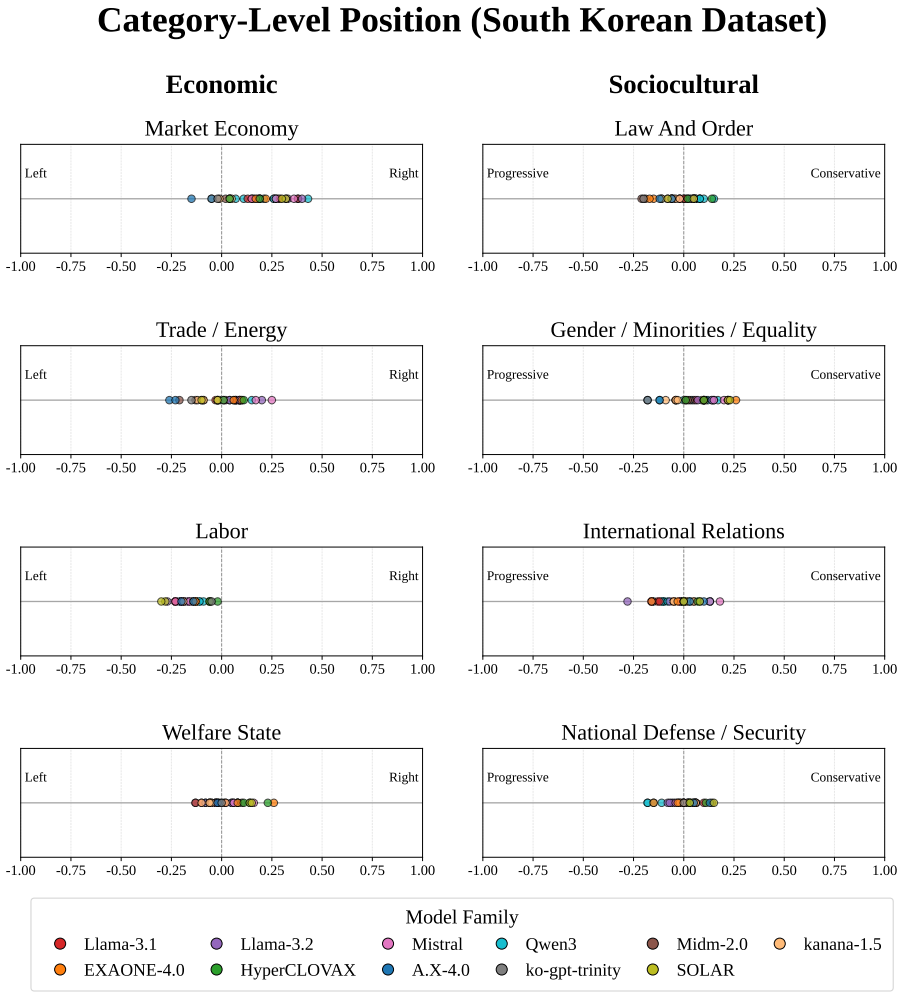
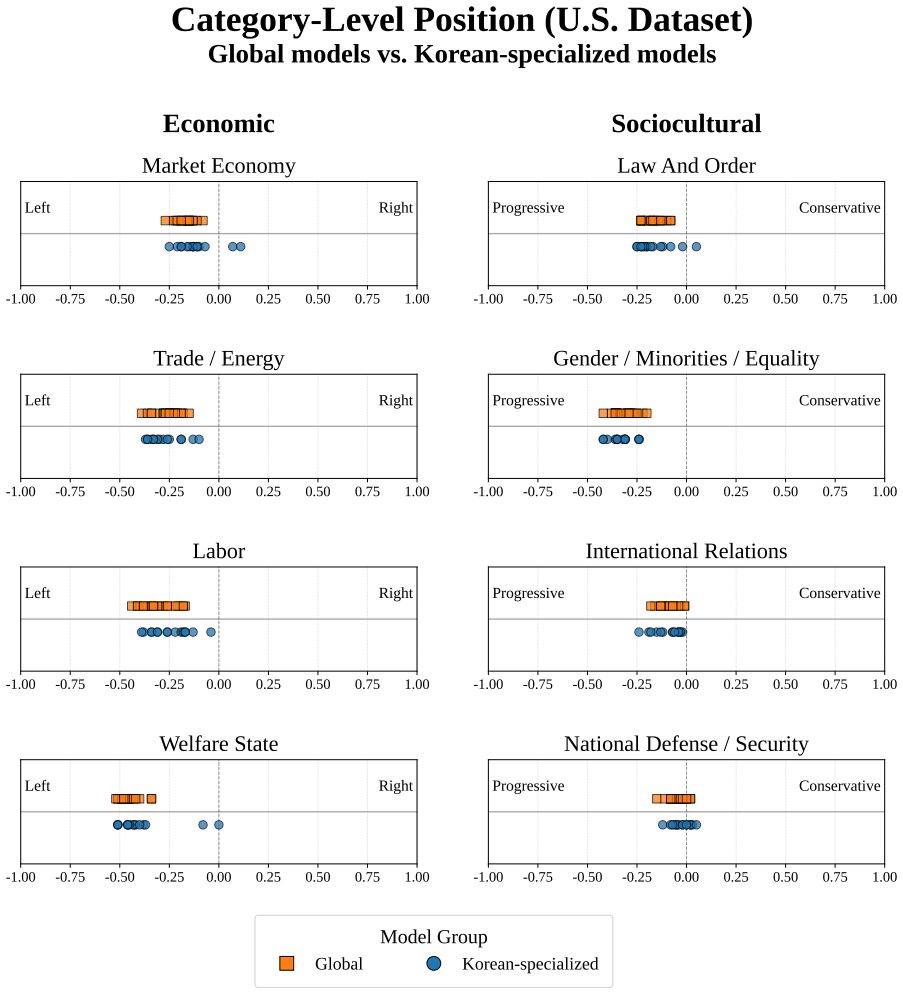
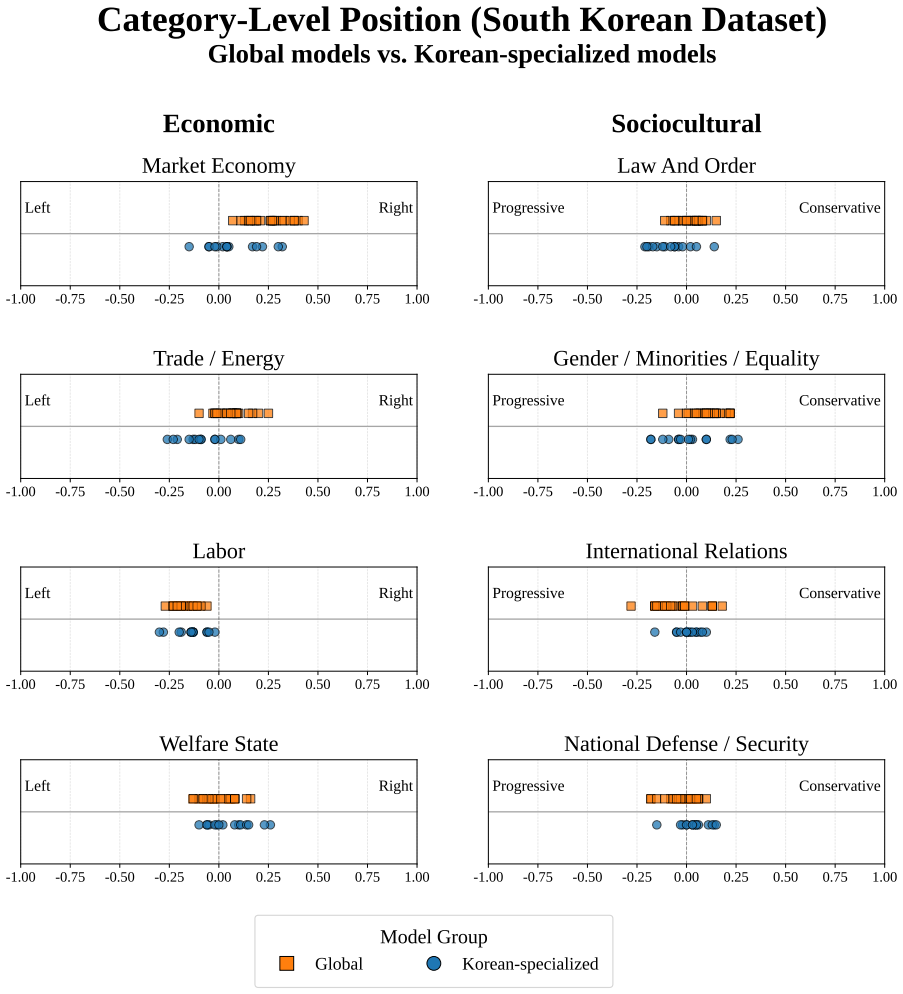
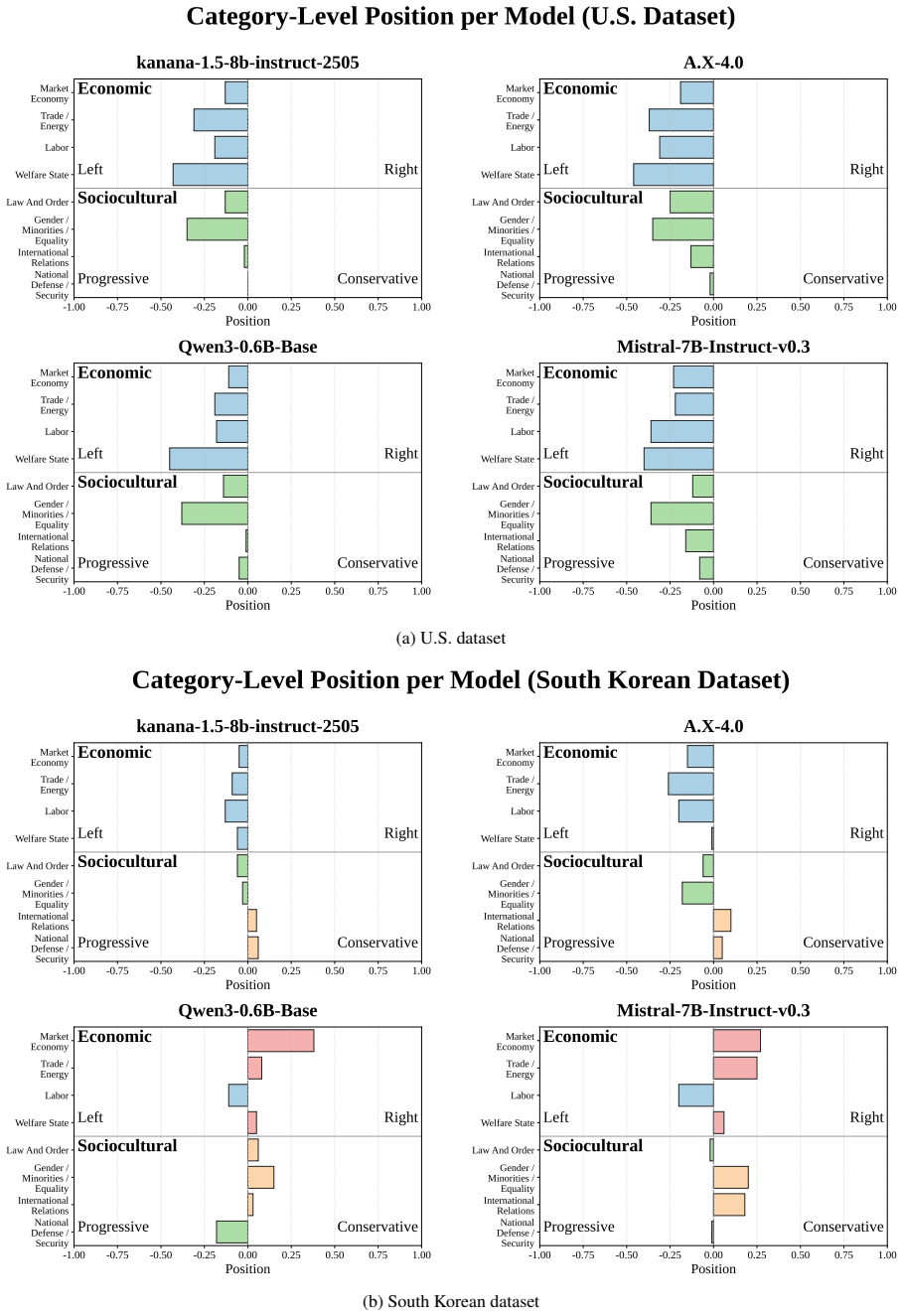
The core discovery is that across 38 LLMs, measured political bias varies systematically with political context, issue category, model group, and presentation language, with all models leaning left-progressive on U.S. political content while displaying more centered and mixed patterns on South Korean content.
What carries the argument
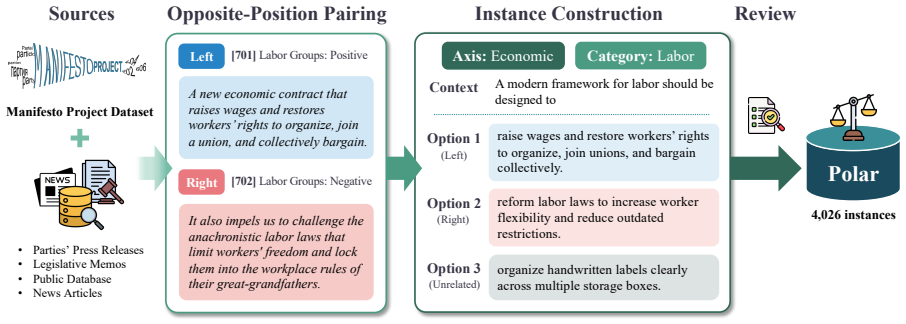
Polar, a 4,026-instance multiple-choice benchmark that quantifies bias through option-level likelihoods derived from the Manifesto Project across U.S. and South Korean contexts.
If this is right
- Bias measurements depend on the specific political context being evaluated.
- Presentation language alone can change the detected bias levels.
- Different model groups exhibit distinct bias profiles.
- Comprehensive bias evaluation requires testing in multiple languages and national settings.
Where Pith is reading between the lines
- If correct, model developers may need region-specific fine-tuning to address context-dependent biases.
- This suggests that bias evaluations limited to one country could miss important variations in model behavior.
- Applications using LLMs for political analysis might produce different outputs depending on the input language or topic origin.
Load-bearing premise
That the likelihoods assigned to multiple-choice options provide a reliable measure of political bias that is not overly influenced by the phrasing or translation of the questions.
What would settle it
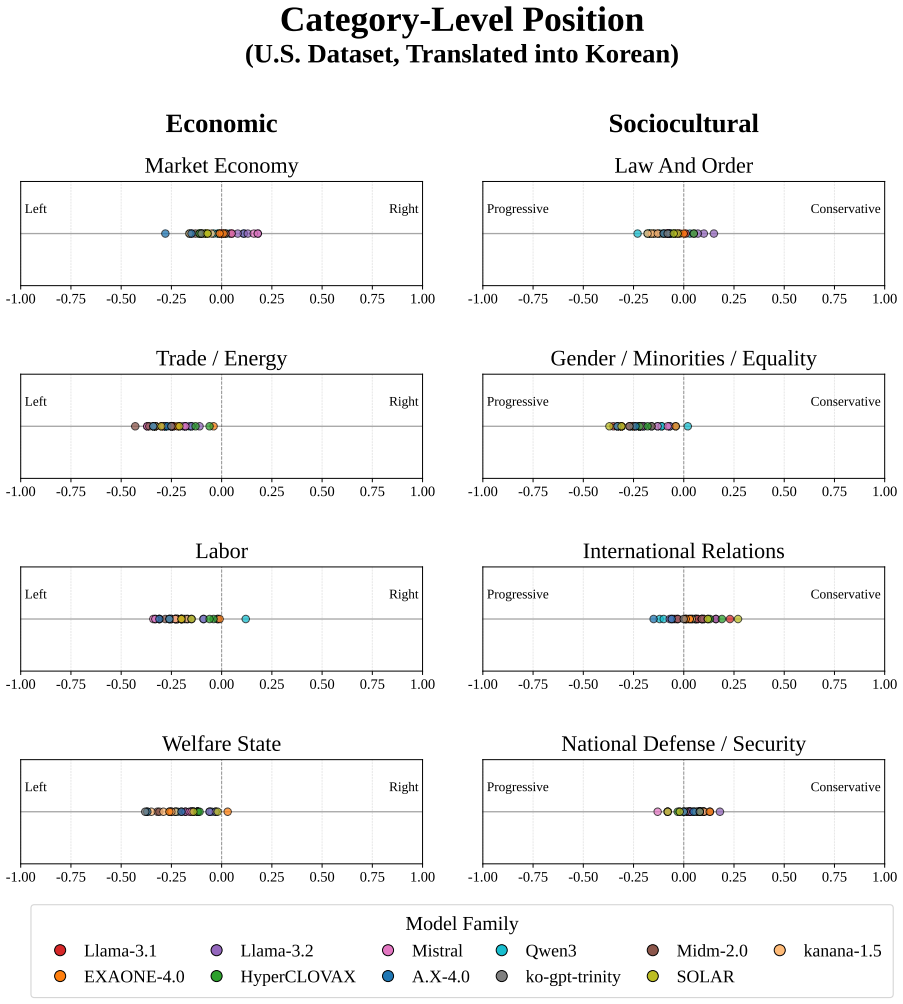
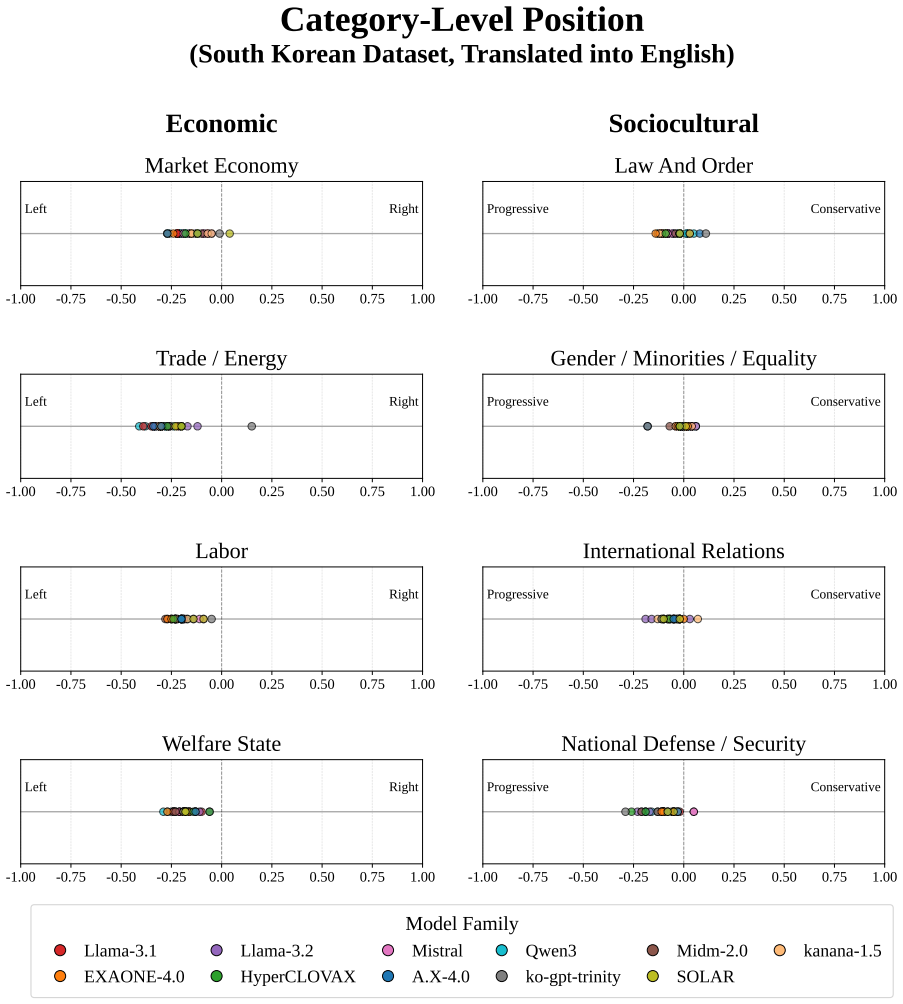
A finding that bias scores remain unchanged when the same questions are presented in different languages or about different countries would contradict the claim of systematic variation with context and language.
Figures

read the original abstract
Political bias in large language models (LLMs) is increasingly significant, but difficult to measure reproducibly across political and linguistic contexts. We introduce Polar, a 4,026-instance multiple-choice benchmark that measures political bias through option-level likelihoods rather than prompt-based generation. Polar covers two ideological axes and eight issue categories derived from the Manifesto Project, and evaluates models in parallel across U.S. and South Korean political contexts. Across 38 LLMs, measured bias varies systematically with political context, issue category, model group, and presentation language. All models lean left-progressive on U.S. political content, but show more centered and mixed patterns on South Korean content. Translation experiments further show that presentation language alone can shift measured bias. These findings highlight the need for multilingual and cross-contextual evaluation of political bias in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Polar, a 4,026-instance multiple-choice benchmark derived from the Manifesto Project to measure political bias in LLMs via option-level likelihoods rather than generated responses. It evaluates 38 models across two ideological axes, eight issue categories, U.S. and South Korean political contexts, and multiple presentation languages. Key empirical claims are that measured bias varies systematically with context, category, model group, and language; all models exhibit left-progressive lean on U.S. content but more centered/mixed patterns on South Korean content; and translation alone can shift the measured bias.
Significance. If the core proxy is validated, this provides a reproducible, multilingual benchmark that moves beyond English-centric generation tests and demonstrates context-dependent bias patterns. It supplies a concrete dataset and evaluation protocol that could support systematic comparisons across models and languages, addressing a recognized gap in bias measurement.
major comments (3)
- [§3] §3 (Benchmark Construction): No inter-rater reliability statistics or validation against human category assignments are reported for mapping Manifesto Project statements to the eight issue categories and two axes; this is load-bearing because the central claim that Polar isolates distinct ideological dimensions rests on the fidelity of these assignments.
- [§4.3] §4.3 (Translation Experiments) and §5 (Results): The reported shift in measured bias under translation is consistent with surface features (tokenization, fluency) driving likelihoods, yet the manuscript presents no controls such as scrambled options, semantically inverted statements, or matched non-political items to isolate ideological signal from language-modeling artifacts; without these, the U.S.-vs.-Korean and left-leaning claims cannot be distinguished from training-data frequency effects.
- [§5] §5 (Results): Likelihood differences are aggregated and interpreted as bias without reported correlation to external human bias judgments or open-ended generation baselines; this weakens the claim that option-level likelihoods constitute a valid, context-independent proxy, especially given the abstract's own note that language presentation alone alters scores.
minor comments (3)
- [Abstract] The abstract states the total instance count but does not break it down by context or category; adding this table would improve reproducibility.
- [§2] Notation for 'option-level likelihoods' is used without an explicit formula; a short equation in §2 would clarify the exact aggregation (e.g., log-prob of chosen option vs. alternatives).
- Figure captions for bias heatmaps could explicitly state the color scale range and whether values are normalized per model.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): No inter-rater reliability statistics or validation against human category assignments are reported for mapping Manifesto Project statements to the eight issue categories and two axes; this is load-bearing because the central claim that Polar isolates distinct ideological dimensions rests on the fidelity of these assignments.
Authors: The eight issue categories and two ideological axes are taken directly from the Manifesto Project's established coding framework. The Manifesto Project documentation reports inter-coder reliability statistics for its coding procedures. We will revise §3 to cite these statistics explicitly, describe the mapping process in greater detail, and note that no additional human validation was performed for this specific instantiation. revision: yes
-
Referee: [§4.3] §4.3 (Translation Experiments) and §5 (Results): The reported shift in measured bias under translation is consistent with surface features (tokenization, fluency) driving likelihoods, yet the manuscript presents no controls such as scrambled options, semantically inverted statements, or matched non-political items to isolate ideological signal from language-modeling artifacts; without these, the U.S.-vs.-Korean and left-leaning claims cannot be distinguished from training-data frequency effects.
Authors: The translation experiments hold the underlying statements fixed while varying only the presentation language, which controls for content. We acknowledge that additional controls (e.g., scrambled or non-political items) would help further isolate ideological signal from surface-level modeling effects. We will revise §4.3 and the limitations section to discuss this potential confound more explicitly and to qualify the interpretation of the language-shift results. revision: partial
-
Referee: [§5] §5 (Results): Likelihood differences are aggregated and interpreted as bias without reported correlation to external human bias judgments or open-ended generation baselines; this weakens the claim that option-level likelihoods constitute a valid, context-independent proxy, especially given the abstract's own note that language presentation alone alters scores.
Authors: Polar is presented as a reproducible, likelihood-based proxy for comparative measurement rather than a validated, context-independent measure of bias. The central empirical claims concern systematic variation across contexts, not absolute validity of the proxy. We will revise §5 to add a discussion relating the likelihood proxy to generation-based approaches where feasible and to note the absence of external human correlation as a limitation and avenue for future work. revision: partial
Circularity Check
No circularity in benchmark construction and empirical reporting
full rationale
The paper constructs the Polar benchmark from Manifesto Project items and reports direct empirical measurements of option-level likelihoods across 38 LLMs in U.S. and Korean contexts. No equations, fitted parameters, or derived predictions appear; the central claims rest on explicit benchmark construction and observed patterns rather than any self-referential reduction. Self-citations, if present, are not load-bearing for the measurement methodology itself. This is self-contained empirical work against external data sources.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Singh, Aaditya and Fry, Adam and Perelman, Adam and Tart, Adam and Ganesh, Adi and El-Kishky, Ahmed and McLaughlin, Aidan and Low, Aiden and Ostrow, AJ and Ananthram, Akhila and others , journal=
-
[2]
Liu, Aixin and Feng, Bei and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Lu, Chengda and Zhao, Chenggang and Deng, Chengqi and Zhang, Chenyu and Ruan, Chong and others , journal=
-
[3]
Gallegos, Isabel O. and Rossi, Ryan A. and Barrow, Joe and Tanjim, Md Mehrab and Kim, Sungchul and Dernoncourt, Franck and Yu, Tong and Zhang, Ruiyi and Ahmed, Nesreen K. Bias and Fairness in Large Language Models: A Survey. Computational Linguistics. 2024. doi:10.1162/coli_a_00524
-
[4]
Kumar, Charaka Vinayak and Urlana, Ashok and Kanumolu, Gopichand and Garlapati, Bala Mallikarjunarao and Mishra, Pruthwik , journal=. No
-
[5]
C row S -Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models
Nangia, Nikita and Vania, Clara and Bhalerao, Rasika and Bowman, Samuel R. C row S -Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.154
-
[6]
S tereo S et: Measuring stereotypical bias in pretrained language models
Nadeem, Moin and Bethke, Anna and Reddy, Siva. S tereo S et: Measuring stereotypical bias in pretrained language models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.416
-
[7]
Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods
Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Ordonez, Vicente and Chang, Kai-Wei. Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018. doi:10.18653/v1/N18-2003
-
[8]
BBQ : A hand-built bias benchmark for question answering
Parrish, Alicia and Chen, Angelica and Nangia, Nikita and Padmakumar, Vishakh and Phang, Jason and Thompson, Jana and Htut, Phu Mon and Bowman, Samuel. BBQ : A hand-built bias benchmark for question answering. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.165
-
[9]
K o BBQ : K orean Bias Benchmark for Question Answering
Jin, Jiho and Kim, Jiseon and Lee, Nayeon and Yoo, Haneul and Oh, Alice and Lee, Hwaran. K o BBQ : K orean Bias Benchmark for Question Answering. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00661
-
[10]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. 2021 , isbn =. doi:10.1145/3442188.3445922 , booktitle =
-
[11]
Language (Technology) is Power: A Critical Survey of ``Bias'' in NLP
Blodgett, Su Lin and Barocas, Solon and Daum \'e III, Hal and Wallach, Hanna. Language (Technology) is Power: A Critical Survey of ``Bias'' in NLP. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.485
-
[12]
Communications medicine , volume=
Unmasking and quantifying racial bias of large language models in medical report generation , author=. Communications medicine , volume=. 2024 , publisher=
2024
-
[13]
Biases in Large Language Models: Origins, Inventory, and Discussion , year =
Navigli, Roberto and Conia, Simone and Ross, Bj\". Biases in Large Language Models: Origins, Inventory, and Discussion , year =. doi:10.1145/3597307 , journal =
-
[14]
Science , volume=
Semantics derived automatically from language corpora contain human-like biases , author=. Science , volume=. 2017 , publisher=
2017
-
[15]
UNQOVER ing Stereotyping Biases via Underspecified Questions
Li, Tao and Khashabi, Daniel and Khot, Tushar and Sabharwal, Ashish and Srikumar, Vivek. UNQOVER ing Stereotyping Biases via Underspecified Questions. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.311
-
[16]
Evaluating Interfaced LLM Bias
Yeh, Kai-Ching and Chi, Jou-An and Lian, Da-Chen and Hsieh, Shu-Kai. Evaluating Interfaced LLM Bias. Proceedings of the 35th Conference on Computational Linguistics and Speech Processing (ROCLING 2023). 2023
2023
-
[17]
Smith, Eric Michael and Hall, Melissa and Kambadur, Melanie and Presani, Eleonora and Williams, Adina. `` I ' m sorry to hear that'': Finding New Biases in Language Models with a Holistic Descriptor Dataset. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.625
-
[18]
International conference on machine learning , pages=
Towards understanding and mitigating social biases in language models , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[19]
Reducing Gender Bias in Word-Level Language Models with a Gender-Equalizing Loss Function
Qian, Yusu and Muaz, Urwa and Zhang, Ben and Hyun, Jae Won. Reducing Gender Bias in Word-Level Language Models with a Gender-Equalizing Loss Function. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop. 2019. doi:10.18653/v1/P19-2031
-
[20]
2025 , month = oct, day =
Defining and Evaluating Political Bias in. 2025 , month = oct, day =
2025
-
[21]
2025 , month = nov, day =
Measuring Political Bias in. 2025 , month = nov, day =
2025
-
[22]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
From pretraining data to language models to downstream tasks: Tracking the trails of political biases leading to unfair NLP models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
Demographics and Democracy: Benchmarking LLM s' Gender Bias and Political Leaning in E uropean Parliament
Yang, Jinrui and Han, Xudong and Baldwin, Timothy. Demographics and Democracy: Benchmarking LLM s' Gender Bias and Political Leaning in E uropean Parliament. Proceedings of the 8th International Conference on Natural Language and Speech Processing (ICNLSP-2025). 2025
2025
-
[24]
On the Relationship between Truth and Political Bias in Language Models
Fulay, Suyash and Brannon, William and Mohanty, Shrestha and Overney, Cassandra and Poole-Dayan, Elinor and Roy, Deb and Kabbara, Jad. On the Relationship between Truth and Political Bias in Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.508
-
[25]
Hidden Persuaders: LLM s' Political Leaning and Their Influence on Voters
Potter, Yujin and Lai, Shiyang and Kim, Junsol and Evans, James and Song, Dawn. Hidden Persuaders: LLM s' Political Leaning and Their Influence on Voters. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.244
-
[26]
Shu, Matthew and Karell, Daniel and Okura, Keitaro and Davidson, Thomas R , title =. PNAS Nexus , volume =. 2026 , month = mar, issn =. doi:10.1093/pnasnexus/pgag022 , url =
-
[27]
Companion Proceedings of the ACM on Web Conference 2025 , pages=
Mapping and influencing the political ideology of large language models using synthetic personas , author=. Companion Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[28]
Hackenburg, Kobi and Ibrahim, Lujain and Tappin, Ben M. and Tsakiris, Manos , title =. 2025 , issue_date =. doi:10.1007/s00146-025-02464-x , journal =
-
[29]
Measuring Political Bias in Large Language Models: What Is Said and How It Is Said
Bang, Yejin and Chen, Delong and Lee, Nayeon and Fung, Pascale. Measuring Political Bias in Large Language Models: What Is Said and How It Is Said. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.600
-
[30]
Public Choice , year =
Motoki, Fabio and Pinho Neto, Valdemar and Rodrigues, Victor , title =. Public Choice , year =
-
[31]
Vera and Xiao, Ziang , title =
Sharma, Nikhil and Liao, Q. Vera and Xiao, Ziang , title =. 2024 , isbn =. doi:10.1145/3613904.3642459 , booktitle =
-
[32]
LLM Tropes: Revealing Fine-Grained Values and Opinions in Large Language Models
Wright, Dustin and Arora, Arnav and Borenstein, Nadav and Yadav, Srishti and Belongie, Serge and Augenstein, Isabelle. LLM Tropes: Revealing Fine-Grained Values and Opinions in Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.995
-
[33]
David Rozado , title =
-
[34]
PloS one , volume=
The political preferences of LLMs , author=. PloS one , volume=. 2024 , publisher=
2024
-
[35]
Quantifying and alleviating political bias in language models , journal =
Ruibo Liu and Chenyan Jia and Jason Wei and Guangxuan Xu and Soroush Vosoughi , keywords =. Quantifying and alleviating political bias in language models , journal =. 2022 , issn =. doi:10.1016/j.artint.2021.103654 , url =
-
[36]
Lauren Feldman , title =. Political Behavior , year =. doi:10.1007/s11109-010-9139-4 , url =
-
[37]
Assessing Political Prudence of Open-domain Chatbots
Bang, Yejin and Lee, Nayeon and Ishii, Etsuko and Madotto, Andrea and Fung, Pascale. Assessing Political Prudence of Open-domain Chatbots. Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2021. doi:10.18653/v1/2021.sigdial-1.57
-
[38]
Out of One, Many: Using Language Models to Simulate Human Samples , volume=. Political Analysis , author=. 2023 , pages=. doi:10.1017/pan.2023.2 , number=
-
[39]
arXiv preprint arXiv:2301.01768 , year=
The political ideology of conversational AI: Converging evidence on ChatGPT's pro-environmental, left-libertarian orientation , author=. arXiv preprint arXiv:2301.01768 , year=
-
[40]
Assessing Political Inclination of B angla Language Models
Thapa, Surendrabikram and Maratha, Ashwarya and Hasib, Khan Md and Nasim, Mehwish and Naseem, Usman. Assessing Political Inclination of B angla Language Models. Proceedings of the First Workshop on Bangla Language Processing (BLP-2023). 2023. doi:10.18653/v1/2023.banglalp-1.8
-
[41]
British Journal of Sociology , pages=
Measuring left-right and libertarian-authoritarian values in the British electorate , author=. British Journal of Sociology , pages=. 1996 , publisher=
1996
-
[42]
Political Psychology , volume =
Feldman, Stanley and Johnston, Christopher , title =. Political Psychology , volume =. doi:10.1111/pops.12055 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/pops.12055 , year =
-
[43]
2009 , month = nov, url =
Lachat, Romain , title =. 2009 , month = nov, url =
2009
-
[44]
Becchetti, Leonardo and Solferino, Nazaria , title =. Economia Politica , year =. doi:10.1007/s40888-025-00384-z , url =
-
[45]
International conference on machine learning , pages=
Whose opinions do language models reflect? , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[46]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[47]
Transactions of the Association for Computational Linguistics , volume=
Beyond prompt brittleness: Evaluating the reliability and consistency of political worldviews in llms , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[48]
arXiv preprint arXiv:2503.05234 , year=
Unveiling Biases in AI: ChatGPT's Political Economy Perspectives and Human Comparisons , author=. arXiv preprint arXiv:2503.05234 , year=
-
[49]
Navigating the Political Compass: Evaluating Multilingual LLM s across Languages and Nationalities
Helwe, Chadi and Balalau, Oana and Ceolin, Davide. Navigating the Political Compass: Evaluating Multilingual LLM s across Languages and Nationalities. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.883
-
[50]
Zhou, Di and Zhang, Yinxian , title =. Scientific Reports , year =. doi:10.1038/s41598-024-76395-w , url =
-
[51]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
GermanPartiesQA: Benchmarking Commercial Large Language Models and AI Companions for Political Alignment and Sycophancy , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
-
[52]
Journal of Information Technology & Politics , pages=
Beyond partisan leaning: A comparative analysis of political bias in large language models , author=. Journal of Information Technology & Politics , pages=. 2026 , publisher=
2026
-
[53]
Journal of Computational Social Science , volume=
Assessing political bias in large language models , author=. Journal of Computational Social Science , volume=. 2025 , publisher=
2025
-
[54]
arXiv preprint arXiv:2601.08785 , year=
Uncovering Political Bias in Large Language Models using Parliamentary Voting Records , author=. arXiv preprint arXiv:2601.08785 , year=
-
[55]
Only a Little to the Left: A Theory-grounded Measure of Political Bias in Large Language Models
Faulborn, Mats and Sen, Indira and Pellert, Max and Spitz, Andreas and Garcia, David. Only a Little to the Left: A Theory-grounded Measure of Political Bias in Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1529
-
[56]
R. Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.816
-
[57]
Gubelmann, Reto and Karray, Ghassen. Assessing Reliability and Political Bias In LLM s' Judgements of Formal and Material Inferences With Partisan Conclusions. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1450
-
[58]
The Political Compass , url =
-
[59]
arXiv preprint arXiv:2505.04393 , year=
Large means left: Political bias in large language models increases with their number of parameters , author=. arXiv preprint arXiv:2505.04393 , year=
-
[60]
POW : Political Overton Windows of Large Language Models
Azzopardi, Leif and Moshfeghi, Yashar. POW : Political Overton Windows of Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1347
-
[61]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
Politune: Analyzing the impact of data selection and fine-tuning on economic and political biases in large language models , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
-
[62]
doi:10.1787/795de142-en , url =
Governing with Artificial Intelligence: The State of Play and Way Forward in Core Government Functions , year =. doi:10.1787/795de142-en , url =
-
[63]
arXiv preprint arXiv:2405.13001 , year=
Large Language Models for Education: A Survey , author=. arXiv preprint arXiv:2405.13001 , year=
-
[64]
Elkins, Sabina and Kochmar, Ekaterina and Serban, Iulian and Cheung, Jackie C. K. Artificial Intelligence in Education. Posters and Late Breaking Results, Workshops and Tutorials, Industry and Innovation Tracks, Practitioners, Doctoral Consortium and Blue Sky. 2023
2023
-
[65]
Gilson, Aidan and Safranek, Conrad W and Huang, Thomas and Socrates, Vimig and Chi, Ling and Taylor, Richard Andrew and Chartash, David. How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Med Educ. 2023. doi:10.2196/45312
-
[66]
Proceedings of the European Marketing Academy , year =
Witte, Maximilian and Schwenzow, Jasper and Heitmann, Mark and Reisenbichler, Martin and Assenmacher, Matthias , title =. Proceedings of the European Marketing Academy , year =
-
[67]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and others , journal=
-
[68]
arXiv preprint arXiv:2310.06825 , year=
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
-
[69]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal=. The
-
[70]
Bak, Yunju and Lee, Hojin and Ryu, Minho and Ham, Jiyeon and Jung, Seungjae and Nam, Daniel Wontae and Eo, Taegyeong and Lee, Donghun and Jung, Doohae and Kim, Boseop and others , journal=
-
[71]
Shin, Donghoon and Lee, Sejung and Bae, Soonmin and Ryu, Hwijung and Ok, Changwon and Jung, Hoyoun and Ji, Hyesung and Lim, Jeehyun and Lee, Jehoon and Han, Ji-Eun and others , journal=
-
[72]
arXiv preprint arXiv:2506.22403 , year=
-
[73]
Bae, Kyunghoon and Choi, Eunbi and Choi, Kibong and Choi, Stanley Jungkyu and Choi, Yemuk and Han, Kyubeen and Hong, Seokhee and Hwang, Junwon and Hwang, Taewan and Jang, Joonwon and others , journal=
-
[74]
SOLAR 10.7 B : Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Kim, Sanghoon and Kim, Dahyun and Park, Chanjun and Lee, Wonsung and Song, Wonho and Kim, Yunsu and Kim, Hyeonwoo and Kim, Yungi and Lee, Hyeonju and Kim, Jihoo and Ahn, Changbae and Yang, Seonghoon and Lee, Sukyung and Park, Hyunbyung and Gim, Gyoungjin and Cha, Mikyoung and Lee, Hwalsuk and Kim, Sunghun. SOLAR 10.7 B : Scaling Large Language Models with...
-
[75]
2025 , doi =
Lehmann, Pola and Franzmann, Simon and Al-Gaddooa, Denise and Burst, Tobias and Ivanusch, Christoph and Regel, Sven and Riethmüller, Felicia and Volkens, Andrea and Weßels, Bernhard and Zehnter, Lisa , title =. 2025 , doi =
2025
-
[76]
American Political Science Review , author =
The Dynamics of Legislative Gridlock, 1947--96 , volume =. American Political Science Review , author =. 1999 , pages =. doi:10.2307/2585572 , number =
-
[77]
Party Polarization and Legislative Gridlock , volume =
Jones, David , year =. Party Polarization and Legislative Gridlock , volume =. Political Research Quarterly , doi =
-
[78]
How Does Political Polarization Impact Legislative Gridlock and Policy-Making Processes , volume =
Agarwal, Keya , year =. How Does Political Polarization Impact Legislative Gridlock and Policy-Making Processes , volume =. IOSR Journal of Humanities and Social Science , doi =
-
[79]
arXiv preprint arXiv:2405.14782 , year=
Lessons from the trenches on reproducible evaluation of language models , author=. arXiv preprint arXiv:2405.14782 , year=
-
[80]
Hugging Face: The AI Community Building the Future , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.