Mental-R1: Aligning LLM Reasoning for Mental Health Assessment
Pith reviewed 2026-06-27 07:13 UTC · model grok-4.3
The pith
Cognitive Relative Policy Optimization trains LLMs to assess mental health by shifting from broad exploration to confident conclusions in staged reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
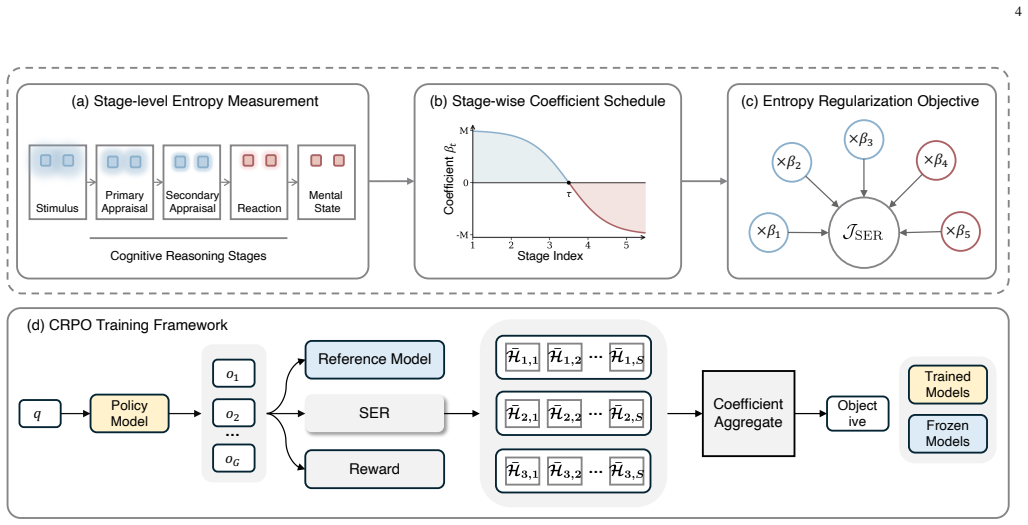
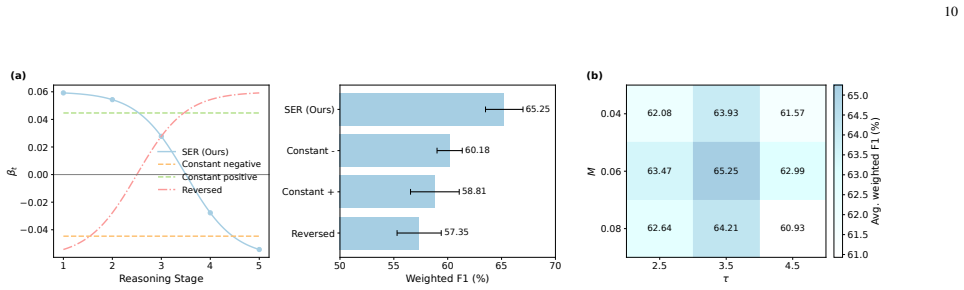
CRPO extends group relative policy optimization by integrating stage-dependent uncertainty modeling into the policy optimization process, using stage-wise entropy regularization that encourages broad exploration in early reasoning phases and progressively enforces confident decision-making in later stages, while formalizing cognitive reasoning stages inspired by cognitive appraisal theory to guide theory-grounded interpretable inference.
What carries the argument
Stage-wise entropy regularization inside the policy optimization loop, which modulates exploration confidence according to the current phase of reasoning.
If this is right
- Models trained with CRPO produce more reliable reasoning on complex mental health cases.
- The stage definitions allow more interpretable inference steps than standard RL training.
- Performance gains hold across multiple distinct mental health assessment datasets.
Where Pith is reading between the lines
- The same staged regularization pattern could be tested in other sequential decision domains such as medical diagnosis.
- Explicit stage labels may make it easier to audit where an LLM's reasoning diverges from clinical guidelines.
- Deployment studies on real patient data would reveal whether the reported F1 gains translate to practical clinical utility.
Load-bearing premise
That adjusting entropy by reasoning stage produces outputs that are both more reliable and closer to human assessment processes than ordinary reinforcement learning.
What would settle it
A controlled ablation that removes only the stage-wise entropy term and measures whether the 10.4-point F1 gain on the eight datasets disappears.
Figures

read the original abstract
Mental health problems such as anxiety, depression, and suicide remain urgent global challenges, where timely and accurate assessment is critical for effective intervention. Recently, large language models have been explored for mental health assessment. However, existing general-purpose post-training methods do not align with the cognitive processes of human assessment, which may lead to unreliable reasoning outcomes. To bridge this gap, we propose Cognitive Relative Policy Optimization (CRPO), a reinforcement learning framework tailored for the mental health domain. CRPO extends group relative policy optimization by integrating stage-dependent uncertainty modeling into the policy optimization process. Specifically, we introduce a stage-wise entropy regularization mechanism that encourages broad exploration in early reasoning phases and progressively enforces confident decision-making in later stages, mimicking the human cognitive shift from uncertainty to certainty. In addition, inspired by cognitive appraisal theory, we formalize cognitive reasoning stages, thereby guiding theory-grounded interpretable inference. Experiments on 8 mental health datasets show that CRPO achieves an average improvement of 10.4 percentage points in weighted F1-score over the best reinforcement learning baseline. Furthermore, the CRPO-trained model Mental-R1 demonstrates clear advantages compared with existing large language models on reasoning-intensive cases, suggesting that CRPO enhances reasoning capabilities for mental health assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
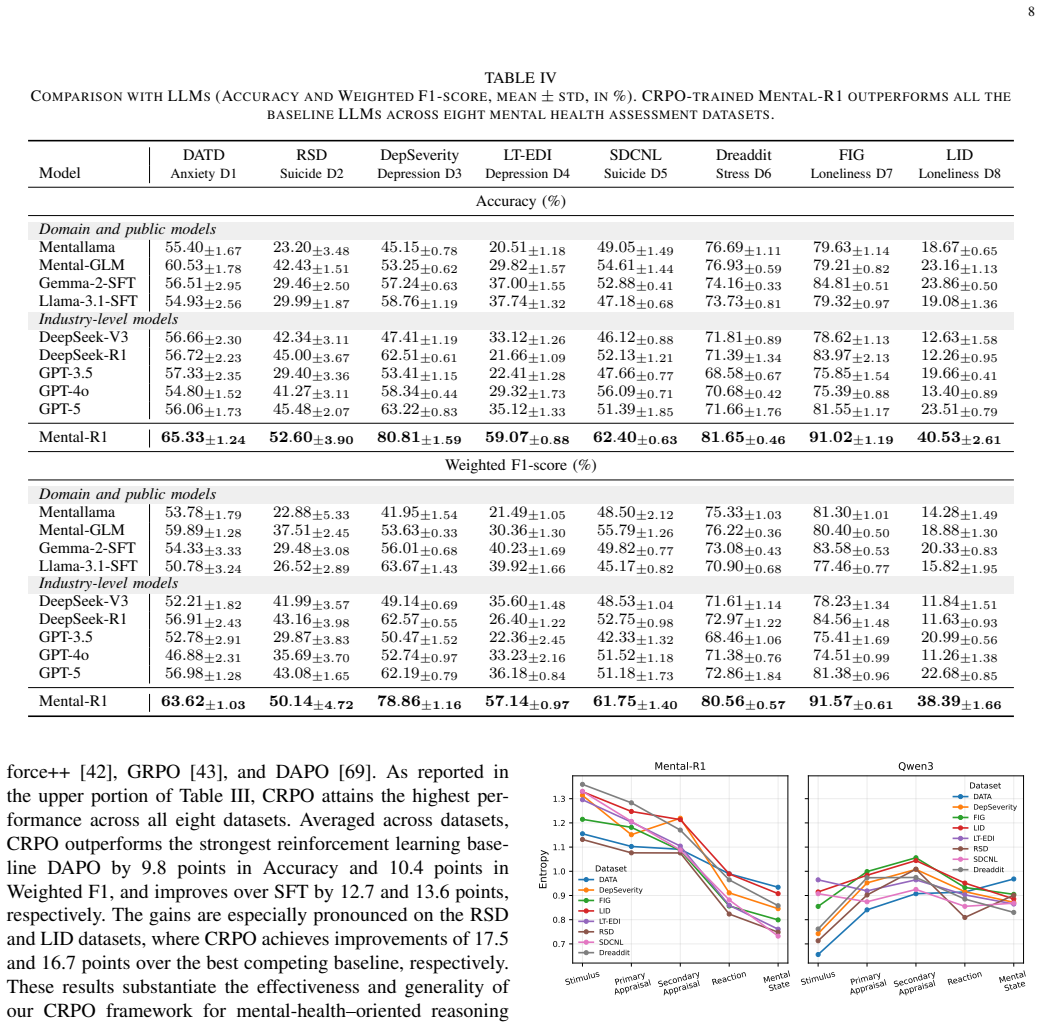
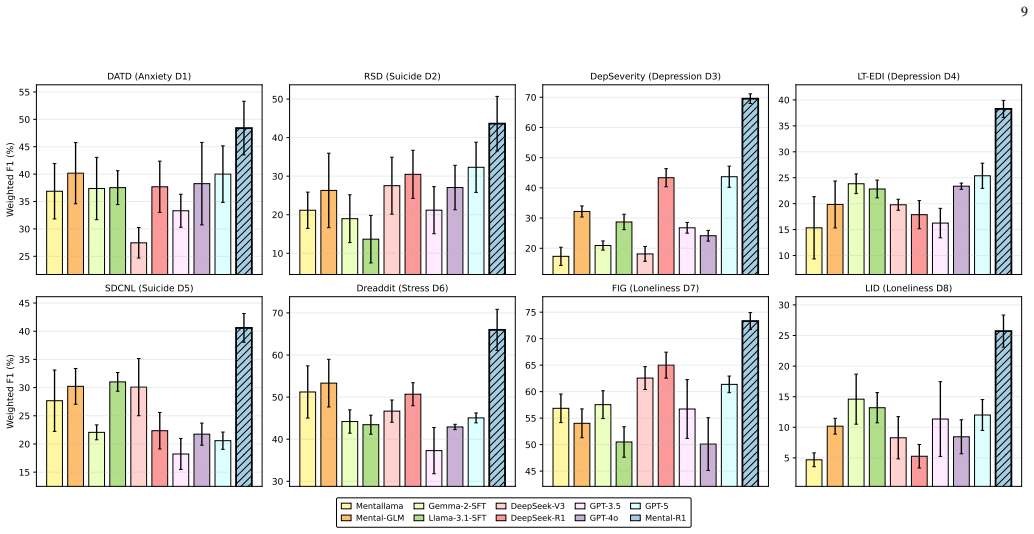
Summary. The paper proposes Cognitive Relative Policy Optimization (CRPO), an extension of group relative policy optimization that adds stage-dependent uncertainty modeling and stage-wise entropy regularization. Drawing on cognitive appraisal theory, it formalizes discrete cognitive reasoning stages to structure LLM inference for mental health assessment. The resulting Mental-R1 model is reported to deliver an average 10.4 percentage-point gain in weighted F1-score over the strongest RL baseline across eight mental-health datasets, with particular gains on reasoning-intensive instances.
Significance. If the empirical gains can be shown to arise specifically from the stage-wise entropy schedule and the cognitive-stage formalization rather than from generic RL tuning, the work would offer a concrete route to theory-aligned, more interpretable reasoning in a high-stakes domain. The explicit linkage to cognitive appraisal theory is a distinctive feature that could be leveraged for future interpretability studies.
major comments (2)
- [Experiments] The central empirical claim attributes the 10.4 pp weighted-F1 improvement to the stage-wise entropy regularization and cognitive-stage formalization, yet no ablation isolates these components from other GRPO extensions or hyper-parameter choices. Without such controls (e.g., a direct GRPO baseline with matched entropy schedule), the causal link between the proposed mechanisms and the measured gain remains unverified.
- [Method] The formalization of cognitive reasoning stages (inspired by appraisal theory) is presented as guiding interpretable inference, but the manuscript supplies neither the explicit mapping from theory constructs to the RL reward or policy terms nor any verification that this mapping is non-circular. This mapping is load-bearing for the claim of “theory-grounded” alignment.
minor comments (2)
- [Experiments] Dataset names, sizes, class distributions, and preprocessing steps for the eight mental-health benchmarks are not summarized in the experimental section; these details are required for reproducibility and to assess whether the reported gains generalize across data regimes.
- The abstract and results tables omit error bars, confidence intervals, or statistical significance tests for the 10.4 pp average improvement; inclusion of these would allow readers to judge whether the gains exceed run-to-run variability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important areas for strengthening the empirical and theoretical claims. We address each point below and will incorporate the suggested revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Experiments] The central empirical claim attributes the 10.4 pp weighted-F1 improvement to the stage-wise entropy regularization and cognitive-stage formalization, yet no ablation isolates these components from other GRPO extensions or hyper-parameter choices. Without such controls (e.g., a direct GRPO baseline with matched entropy schedule), the causal link between the proposed mechanisms and the measured gain remains unverified.
Authors: We agree that the current experiments do not fully isolate the contributions of stage-wise entropy regularization and cognitive-stage formalization from other design choices. In the revised version, we will add targeted ablations: (i) GRPO with a matched (non-stage-dependent) entropy schedule, (ii) CRPO without the cognitive-stage formalization, and (iii) variants that vary only the stage-dependent uncertainty modeling. These controls will directly test the causal role of the proposed mechanisms in the reported 10.4 pp gain. revision: yes
-
Referee: [Method] The formalization of cognitive reasoning stages (inspired by appraisal theory) is presented as guiding interpretable inference, but the manuscript supplies neither the explicit mapping from theory constructs to the RL reward or policy terms nor any verification that this mapping is non-circular. This mapping is load-bearing for the claim of “theory-grounded” alignment.
Authors: We acknowledge that the current manuscript does not provide an explicit, non-circular mapping from cognitive appraisal theory constructs to the specific RL reward and policy terms. In the revision, we will add a dedicated subsection that (a) states the precise correspondence between appraisal-theory stages and the stage-dependent uncertainty parameters, (b) shows how these parameters enter the advantage and entropy terms, and (c) includes a short verification that the mapping introduces constraints beyond standard GRPO (e.g., by contrasting with a generic stage-agnostic entropy schedule). revision: yes
Circularity Check
No circularity in derivation; empirical claims rest on external dataset evaluations
full rationale
The paper introduces CRPO as an extension of GRPO with added stage-wise entropy regularization and cognitive-stage formalization drawn from appraisal theory. These are presented as modeling choices whose value is measured by downstream F1 improvements on 8 held-out mental health datasets. No equations, fitted parameters, or self-citations are shown that would make the reported 10.4 pp gain equivalent to the input mechanisms by construction. The central claim therefore remains an empirical assertion open to falsification by ablation or replication rather than a self-referential identity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Suicide,
World Health Organization, “Suicide,” https://www.who.int/news-room/ fact-sheets/detail/suicide, 2023, accessed: 2025-09-09
2023
-
[2]
Many ways to be lonely: fine-grained characterization of loneliness and its potential changes in covid-19,
Y . Jiang, Y . Jiang, L. Leqi, and P. Winkielman, “Many ways to be lonely: fine-grained characterization of loneliness and its potential changes in covid-19,” inProceedings of the International AAAI Conference on Web and Social Media, vol. 16, 2022, pp. 405–416
2022
-
[3]
Decoding loneliness: Can explainable ai help in understanding language differences in lonely older adults?
N. Wang, S. Goel, S. Ibrahim, V . D. Badal, C. Depp, E. Bilal, K. Subbalakshmi, and E. Lee, “Decoding loneliness: Can explainable ai help in understanding language differences in lonely older adults?” Psychiatry research, vol. 339, p. 116078, 2024
2024
-
[4]
Data set creation and empirical analysis for detecting signs of depression from social media postings,
K. Sampath and T. Durairaj, “Data set creation and empirical analysis for detecting signs of depression from social media postings,” inIn- ternational Conference on Computational Intelligence in Data Science. Springer, 2022, pp. 136–151
2022
-
[5]
Early identification of depression severity levels on reddit using ordinal classification,
U. Naseem, A. G. Dunn, J. Kim, and M. Khushi, “Early identification of depression severity levels on reddit using ordinal classification,” in Proceedings of the ACM web conference 2022, 2022, pp. 2563–2572
2022
-
[6]
Leverage social media for personalized stress detection,
X. Wang, H. Zhang, L. Cao, and L. Feng, “Leverage social media for personalized stress detection,” inProceedings of the 28th ACM international conference on multimedia, 2020, pp. 2710–2718
2020
-
[7]
A meta- learning based stress category detection framework on social media,
X. Wang, L. Cao, H. Zhang, L. Feng, Y . Ding, and N. Li, “A meta- learning based stress category detection framework on social media,” in Proceedings of the ACM Web Conference 2022, 2022, pp. 2925–2935
2022
-
[8]
Towards preemptive detection of depression and anxiety in twitter,
D. Owen, J. Camacho-Collados, and L. E. Anke, “Towards preemptive detection of depression and anxiety in twitter,” inProceedings of the Fifth Social Media Mining for Health Applications Workshop & Shared Task, 2020, pp. 82–89
2020
-
[9]
Automatic anxiety recognition method based on microblog text analysis,
Y . Yu, Q. Li, and X. Liu, “Automatic anxiety recognition method based on microblog text analysis,”Frontiers in Public Health, vol. 11, p. 1080013, 2023
2023
-
[10]
Latent suicide risk detection on microblog via suicide-oriented word embeddings and layered attention,
L. Cao, H. Zhang, L. Feng, Z. Wei, X. Wang, N. Li, and X. He, “Latent suicide risk detection on microblog via suicide-oriented word embeddings and layered attention,” inProceedings of the 2019 Con- ference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pp....
2019
-
[11]
Learning users inner thoughts and emotion changes for social media based suicide risk detection,
L. Cao, H. Zhang, X. Wang, and L. Feng, “Learning users inner thoughts and emotion changes for social media based suicide risk detection,” IEEE Transactions on Affective Computing, vol. 14, no. 2, pp. 1280– 1296, 2021
2021
-
[12]
Mentalqlm: A lightweight large language model for mental healthcare based on instruction tuning and dual lora modules,
J. Shi, Z. Wang, J. Zhou, C. Liu, P. Z. Sun, E. Zhao, and L. Lu, “Mentalqlm: A lightweight large language model for mental healthcare based on instruction tuning and dual lora modules,”IEEE Journal of Biomedical and Health Informatics, 2025
2025
-
[13]
Mental-llm: Leveraging large language models for mental health prediction via online text data,
X. Xu, B. Yao, Y . Dong, S. Gabriel, H. Yu, J. Hendler, M. Ghassemi, A. K. Dey, and D. Wang, “Mental-llm: Leveraging large language models for mental health prediction via online text data,”Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 8, no. 1, pp. 1–32, 2024
2024
-
[14]
Mentallama: interpretable mental health analysis on social media with large language models,
K. Yang, T. Zhang, Z. Kuang, Q. Xie, J. Huang, and S. Ananiadou, “Mentallama: interpretable mental health analysis on social media with large language models,” inProceedings of the ACM Web Conference 2024, 2024, pp. 4489–4500
2024
-
[15]
From pattern recognizers to personalized companions: A survey of large language models in mental health,
H. Hu, Y . Zhou, Q. Wang, Y . Zou, C. Ma, J. Si, J. Liu, Z. Yu, L. Cui, and F. Ma, “From pattern recognizers to personalized companions: A survey of large language models in mental health,” 2025
2025
-
[16]
Are llms effective psychological assessors? leveraging adaptive rag for interpretable mental health screening through psychometric practice,
F. Ravenda, S. A. Bahrainian, A. Raballo, A. Mira, and N. Kando, “Are llms effective psychological assessors? leveraging adaptive rag for interpretable mental health screening through psychometric practice,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 8975– 8991
2025
-
[17]
Re- view of predictive techniques for detecting mental disorders from user- generated content on social media,
M. S. Rohei, K. D. Varathan, S. Palaiahnakote, and N. B. Anuar, “Re- view of predictive techniques for detecting mental disorders from user- generated content on social media,”PeerJ Computer Science, vol. 12, p. e3559, 2026
2026
-
[18]
Mentalglm series: Explainable large language models for mental health analysis on chinese social media,
W. Zhai, N. Bai, Q. Zhao, J. Li, F. Wang, H. Qi, M. Jiang, X. Wang, B. X. Yang, and G. Fu, “Mentalglm series: Explainable large language models for mental health analysis on chinese social media,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 13 599–13 614
2025
-
[19]
A comprehensive overview of large language models,
H. Naveed, A. U. Khan, S. Qiu, M. Saqib, S. Anwar, M. Usman, N. Akhtar, N. Barnes, and A. Mian, “A comprehensive overview of large language models,”ACM Transactions on Intelligent Systems and Technology, vol. 16, no. 5, pp. 1–72, 2025
2025
-
[20]
Cyberconfucius: An interactive confucian philosophical counseling system for mental health,
L. Zhao, B. Chen, W. Zheng, L. Zhou, and X. Ding, “Cyberconfucius: An interactive confucian philosophical counseling system for mental health,” inCompanion of the 2025 ACM International Joint Conference on Pervasive and Ubiquitous Computing, 2025, pp. 343–347
2025
-
[21]
H. Hu, Y . Zhou, J. Si, Q. Wang, H. Zhang, F. Ren, F. Ma, L. Cui, and Q. Tian, “Beyond empathy: Integrating diagnostic and therapeutic reasoning with large language models for mental health counseling,” arXiv preprint arXiv:2505.15715, 2025
-
[22]
EmoBench-M: Benchmarking Emotional Intelligence for Multimodal Large Language Models
H. Hu, Y . Zhou, L. You, H. Xu, Q. Wang, Z. Lian, F. R. Yu, F. Ma, and L. Cui, “Emobench-m: Benchmarking emotional intelligence for multimodal large language models,”arXiv preprint arXiv:2502.04424, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Personax: A recommendation agent-oriented user modeling framework for long behavior sequence,
Y . Shi, W. Xu, Z. Zeqi, X. Zi, Q. Wu, and M. Xu, “Personax: A recommendation agent-oriented user modeling framework for long behavior sequence,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 5764–5787
2025
-
[24]
Agentselect: Benchmark for narrative query-to- agent recommendation,
Y . Shi, W. Xu, T. Chen, H. Shang, L. Yang, Y . Wan, Z. Cao, X. Zi, D. N. Metaxas, and M. Xu, “Agentselect: Benchmark for narrative query-to- agent recommendation,”arXiv preprint arXiv:2603.03761, 2026
-
[25]
Llm-assisted systematic review of large language models in clinical medicine,
S. F. Chen, A. Alyakin, A. Seas, E. Yang, J. J. Choi, J. V . Lee, A. L. Chen, P. I. Warman, R. T. Bitolas, R. J. Steeleet al., “Llm-assisted systematic review of large language models in clinical medicine,”Nature medicine, pp. 1–8, 2026
2026
-
[26]
Optimization inspired few-shot adaptation for large language models,
B. Gao, X. Wang, Y . Yang, and D. A. Clifton, “Optimization inspired few-shot adaptation for large language models,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=rZ2nSt1X58
2025
-
[27]
Llm post-training: A deep dive into reasoning large language models,
K. Kumar, T. Ashraf, O. Thawakar, R. M. Anwer, H. Cholakkal, M. Shah, M.-H. Yang, P. H. Torr, F. S. Khan, and S. Khan, “Llm post-training: A deep dive into reasoning large language models,”arXiv preprint arXiv:2502.21321, 2025
-
[28]
J. S. Beck,Cognitive behavior therapy: Basics and beyond. Guilford Publications, 2020
2020
-
[29]
J. B. Persons,The case formulation approach to cognitive-behavior therapy. Guilford Press, 2012
2012
-
[30]
Kuyken, C
W. Kuyken, C. A. Padesky, and R. Dudley,Collaborative case con- ceptualization: Working effectively with clients in cognitive-behavioral therapy. Guilford Press, 2011
2011
-
[31]
T. D. Eells,Handbook of psychotherapy case formulation. Guilford Publications, 2022
2022
-
[32]
A. S. Elstein, L. S. Shulman, and S. A. Sprafka,Medical problem solving: An analysis of clinical reasoning. Harvard University Press, 1978
1978
-
[33]
Higgs, G
J. Higgs, G. M. Jensen, S. Loftus, F. V . Trede, and S. Grace,Clinical Reasoning in the Health Professions E-Book: Clinical Reasoning in the Health Professions E-Book. Elsevier Health Sciences, 2024
2024
-
[34]
H. N. Garb,Studying the clinician. American Psychological Association (APA), 1998
1998
-
[35]
The neural basis of decision making
J. Gold and M. Shadlen, “The neural basis of decision making.”Annual Review of Neuroscience, vol. 30, pp. 535–574, 2007
2007
-
[36]
Whatever next? predictive brains, situated agents, and the future of cognitive science,
A. Clark, “Whatever next? predictive brains, situated agents, and the future of cognitive science,”Behavioral and brain sciences, vol. 36, no. 3, pp. 181–204, 2013
2013
-
[37]
J. H. Wright, G. K. Brown, M. E. Thase, and M. R. Basco,Learning cognitive-behavior therapy: An illustrated guide. American Psychiatric Pub, 2017
2017
-
[38]
Reason and emotion in psychotherapy
A. Ellis, “Reason and emotion in psychotherapy.” 1962. 12
1962
-
[39]
A. T. Beck,Cognitive therapy and the emotional disorders. Penguin, 1979
1979
-
[40]
R. S. Lazarus and S. Folkman,Stress, appraisal, and coping. Springer publishing company, 1984
1984
-
[41]
Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models,
Z. Li, T. Xu, Y . Zhang, Z. Lin, Y . Yu, R. Sun, and Z. Luo, “Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models,” inForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024
2024
-
[42]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
J. Hu, J. K. Liu, H. Xu, and W. Shen, “Reinforce++: An efficient rlhf algorithm with robustness to both prompt and reward models,”arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Some implications of cognitive appraisal theories of emotion,
P. C. Ellsworth, “Some implications of cognitive appraisal theories of emotion,” 1991
1991
-
[45]
Causes and consequences of emotions on consumer behaviour: A review and integrative cognitive appraisal theory,
L. Watson and M. T. Spence, “Causes and consequences of emotions on consumer behaviour: A review and integrative cognitive appraisal theory,”European Journal of marketing, vol. 41, no. 5/6, pp. 487–511, 2007
2007
-
[46]
Language-based detection of depression with machine learning: systematic review and meta-analysis,
H. Fisher, N. M. Jaffe, K. Pidvirny, A. O. Tierney, M. S. Vaidean, P. Dongre, and C. A. Webb, “Language-based detection of depression with machine learning: systematic review and meta-analysis,”npj Digital Medicine, 2026
2026
-
[47]
Contrastive learning of stress-specific word embedding for social media based stress detection,
X. Wang, H. Zhang, L. Cao, K. Zeng, Q. Li, N. Li, and L. Feng, “Contrastive learning of stress-specific word embedding for social media based stress detection,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 5137– 5149
2023
-
[48]
Mise: Meta-knowledge inheritance for social media-based stressor estimation,
X. Wang, L. Feng, H. Zhang, L. Cao, K. Zeng, Q. Li, Y . Ding, Y . Dai, and D. Clifton, “Mise: Meta-knowledge inheritance for social media-based stressor estimation,” inProceedings of the ACM on Web Conference 2025, 2025, pp. 1866–1876
2025
-
[49]
A scoping review of natural language processing for detecting work-related stress among health professionals,
C. Ikae, S. Ben Souissi, J. S. Bieri, T. J. M ¨uller, M. C. Feuz-Schlunegger, and C. Golz, “A scoping review of natural language processing for detecting work-related stress among health professionals,”Discover Computing, vol. 29, no. 1, p. 14, 2026
2026
-
[50]
Language anxiety detection in english texts using bert and svm,
R. Hidayat, K. M. Lhaksmana, and I. K. Nurhayati, “Language anxiety detection in english texts using bert and svm,” in2025 International Conference on Data Science and Its Applications (ICoDSA). IEEE, 2025, pp. 357–362
2025
-
[51]
Knowledge-aware assessment of severity of suicide risk for early intervention,
M. Gaur, A. Alambo, J. P. Sain, U. Kursuncu, K. Thirunarayan, R. Kavuluru, A. Sheth, R. Welton, and J. Pathak, “Knowledge-aware assessment of severity of suicide risk for early intervention,” inThe world wide web conference, 2019, pp. 514–525
2019
-
[52]
Suicide ideation detection using social media data and ensemble machine learning model,
E. KINA, J.-G. Choi, A. Ishaq, R. Shafique, M. G. Villar, E. S. Alvarado, I. d. l. T. Diez, and I. Ashraf, “Suicide ideation detection using social media data and ensemble machine learning model,”International Journal of Computational Intelligence Systems, 2026
2026
-
[53]
Category-aware chronic stress detection on microblogs,
L. Cao, H. Zhang, N. Li, X. Wang, W. Ri, and L. Feng, “Category-aware chronic stress detection on microblogs,”IEEE journal of biomedical and health informatics, vol. 26, no. 2, pp. 852–864, 2021
2021
-
[54]
Rsd-15k: A large-scale user-level annotated dataset for suicide risk detection on social media,
S. Zheng, Y . Tao, and T. Zhou, “Rsd-15k: A large-scale user-level annotated dataset for suicide risk detection on social media,” in2025 IEEE 41st International Conference on Data Engineering Workshops (ICDEW). IEEE, 2025, pp. 190–196
2025
-
[55]
Evaluation of chatgpt for nlp-based mental health applications,
B. Lamichhane, “Evaluation of chatgpt for nlp-based mental health applications,”arXiv preprint arXiv:2303.15727, 2023
-
[56]
Feelings behind words: A systematic review on how effective is nlp-based assessment for mental health diagnosis in human studies,
E. P. Yulianti, Y . S. E. Putri, B. A. Keliat, and A. N. Hidayanto, “Feelings behind words: A systematic review on how effective is nlp-based assessment for mental health diagnosis in human studies,”International Journal of Medical Informatics, p. 106129, 2025
2025
-
[57]
Detecting multiple mental health disorders with large language models,
M. Nanda, D. Inkpen, and A. Dargel, “Detecting multiple mental health disorders with large language models,” in2024 28th International Conference Information Visualisation (IV). IEEE, 2024, pp. 252–257
2024
-
[58]
The applications of large language models in mental health: scoping review,
Y . Jin, J. Liu, P. Li, B. Wang, Y . Yan, H. Zhang, C. Ni, J. Wang, Y . Li, Y . Buet al., “The applications of large language models in mental health: scoping review,”Journal of Medical Internet Research, vol. 27, no. 1, p. e69284, 2025
2025
-
[59]
Let’s verify step by step,
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, “Let’s verify step by step,” inThe twelfth international conference on learning represen- tations, 2023
2023
-
[60]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Consistent paths lead to truth: Self- rewarding reinforcement learning for llm reasoning,
W. Zhang, Y . Liuet al., “Consistent paths lead to truth: Self- rewarding reinforcement learning for llm reasoning,”arXiv preprint arXiv:2506.08745, 2025. [Online]. Available: https://arxiv.org/abs/2506. 08745
-
[62]
Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model?
Y . Yue, Z. Chen, R. Lu, A. Zhao, Z. Wang, Y . Yue, S. Song, and G. Huang, “Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model?” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=4OsgYD7em5
2025
-
[63]
A Survey of Reinforcement Learning for Large Reasoning Models
K. Zhang, Y . Zuo, B. He, Y . Sun, R. Liu, C. Jiang, Y . Fan, K. Tian, G. Jia, P. Liet al., “A survey of reinforcement learning for large reasoning models,”arXiv preprint arXiv:2509.08827, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
2022
-
[65]
Rlaif: Scaling re- inforcement learning from human feedback with ai feedback
H. Lee, S. Phatale, H. Mansoor, K. R. Lu, T. Mesnard, J. Ferret, C. Bishop, E. Hall, V . Carbune, and A. Rastogi, “Rlaif: Scaling re- inforcement learning from human feedback with ai feedback.”
-
[66]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023
2023
-
[67]
Rest-rl: Achieving accurate code reasoning of llms with optimized self-training and decoding,
Y . Zhou, B. Lianget al., “Rest-rl: Achieving accurate code reasoning of llms with optimized self-training and decoding,” arXiv preprint arXiv:2508.19576, 2025. [Online]. Available: https: //arxiv.org/abs/2508.19576
-
[69]
Available: https://arxiv.org/abs/2505.15034
[Online]. Available: https://arxiv.org/abs/2505.15034
-
[70]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, W. Dai, T. Fan, G. Liu, L. Liuet al., “Dapo: An open-source llm reinforcement learning system at scale,”arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Dreaddit: A reddit dataset for stress analysis in social media,
E. Turcan and K. McKeown, “Dreaddit: A reddit dataset for stress analysis in social media,”EMNLP-IJCNLP 2019, p. 97, 2019
2019
-
[72]
Deep learning for suicide and depression identification with unsupervised label correction,
A. Haque, V . Reddi, and T. Giallanza, “Deep learning for suicide and depression identification with unsupervised label correction,” in International Conference on Artificial Neural Networks. Springer, 2021, pp. 436–447
2021
-
[73]
Loneliness-intensity,
Y . K. Yael Katsman, Hilly Segal, “Loneliness-intensity,” https:// huggingface.co/datasets/yael-katsman/Loneliness-Causes-and-Intensity, 2025
2025
-
[74]
Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms,
A. Ahmadian, C. Cremer, M. Gall ´e, M. Fadaee, J. Kreutzer, O. Pietquin, A. ¨Ust¨un, and S. Hooker, “Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16,...
2024
-
[75]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Gemma 2: Improving Open Language Models at a Practical Size
G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ram ´eet al., “Gemma 2: Improving open language models at a practical size,”arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
The llama 3 herd of models,
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
2024
-
[78]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
Gpt3.5 turbo fine-tuning and api updates,
OpenAI, “Gpt3.5 turbo fine-tuning and api updates,” https://openai.com/ index/gpt-3-5-turbo-fine-tuning-and-api-updates/, 2023
2023
-
[80]
Hello gpt-4o,
Openai, “Hello gpt-4o,” https://openai.com/index/hello-gpt-4o/, 2024
2024
-
[81]
Gpt-5 is here,
OpenAI, “Gpt-5 is here,” https://openai.com/gpt-5/, 2025. 13 APPENDIX A. System Prompt for Mental-R1 The prompt in last line will be replaced with the specific mental health question during usage. “A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The Assistant must explicitly think through the reasoning pro...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.