Layer-Resolved Optimal Transport for Hallucination Detection in NMT and Abstractive Summarization
Pith reviewed 2026-06-27 06:41 UTC · model grok-4.3
The pith
Optimal transport distances on decoder cross-attention detect source-disengagement hallucinations in NMT but cannot catch content misrepresentation in summarization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
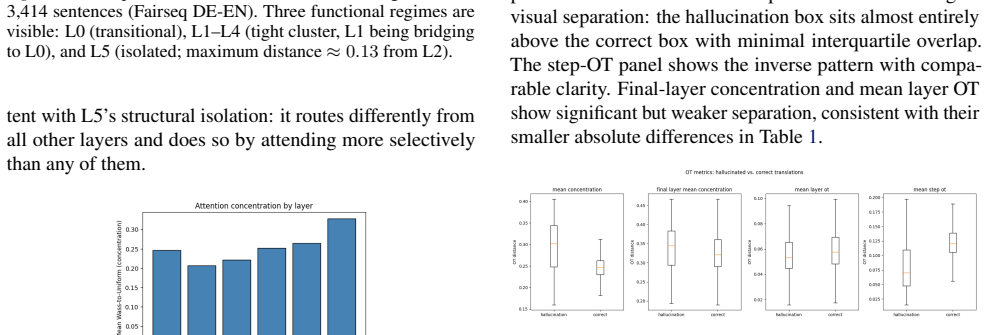
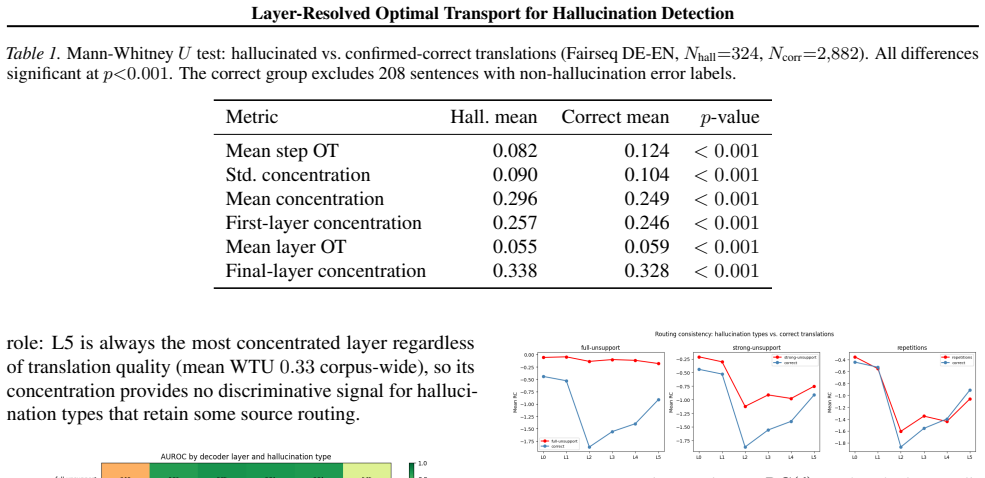
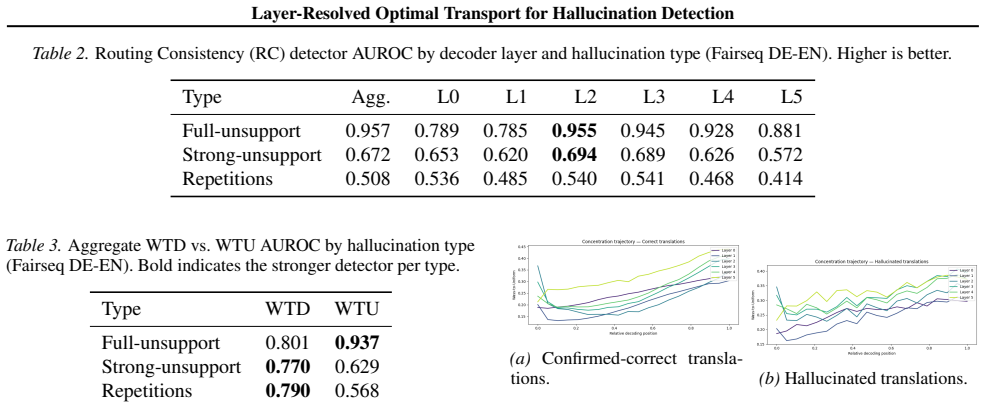
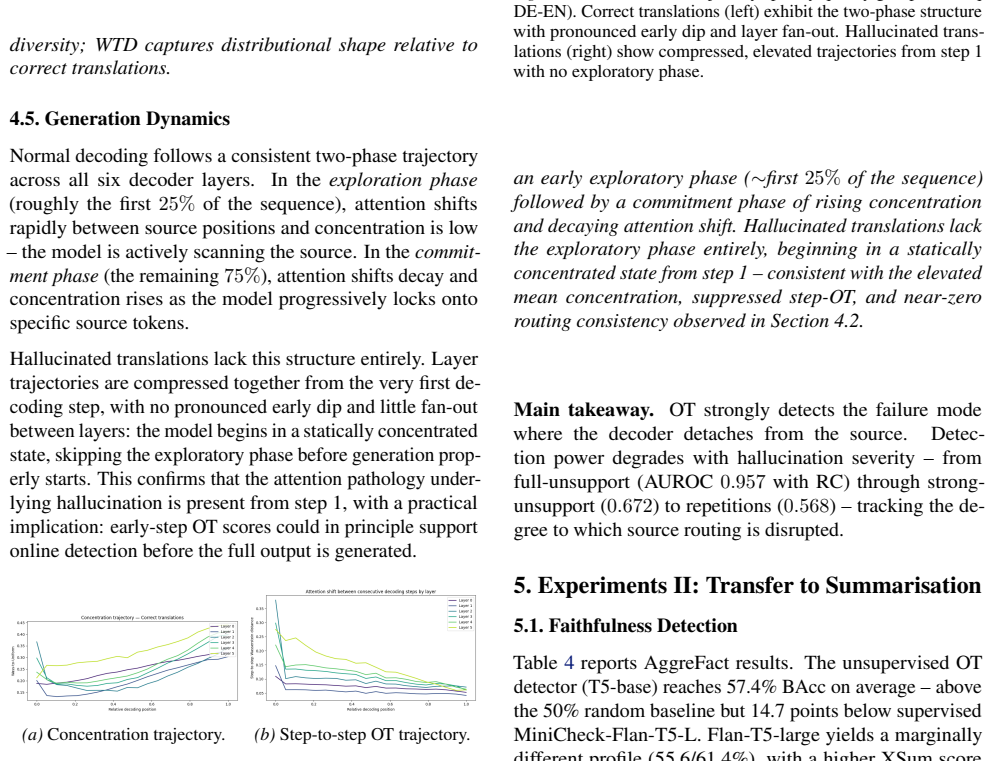
Optimal transport distances from each of the six decoder layers' cross-attention distributions to uniform and data-derived references flag hallucinations on a 3414-example NMT set, with Wass-to-Unif and Wass-to-Data proving complementary across hallucination types; detection peaks in layers 1-4 while layer 5 is anti-predictive for subtler cases, and hallucinated outputs lack the initial exploratory attention phase seen in correct translations. On 1116 AggreFact examples the unsupervised OT detector reaches 57.2-57.6 percent balanced accuracy on CNN/XSum, above chance but below supervised baselines, because unfaithful summaries can attend correctly to source tokens while misrepresenting their
What carries the argument
Layer-resolved Wasserstein-to-Uniform and Wasserstein-to-Data distances on cross-attention distributions; they quantify how far each layer's attention deviates from expected concentration to identify source disengagement.
If this is right
- Detection is reliable specifically when the hallucination arises from source disengagement.
- The method works as a task-agnostic interpretability tool for attention behavior regardless of generation task.
- The approach is fundamentally limited when faithfulness fails after attention has already been allocated correctly.
- Signal strength varies systematically by layer, with early layers carrying most information and layer 5 sometimes anti-correlated.
- T5-base exhibits the same decoder-layer organization, with peak concentration at layer 3 and generation quality most sensitive at layer 12.
Where Pith is reading between the lines
- Regularizing attention concentration in layers 1-4 during training could reduce disengagement hallucinations.
- Hybrid detectors that add content-overlap checks after attention geometry would address the gap left by pure OT metrics.
- The same layer-wise OT analysis could be applied to dialogue or code generation to test whether source grounding failures follow similar patterns.
Load-bearing premise
The main hallucination types in the NMT set and faithfulness failures in AggreFact arise from measurable changes in how attention concentrates on source tokens.
What would settle it
Finding a sizable set of hallucinations where cross-attention concentration remains normal, or correct translations that show atypical concentration patterns, would show that the OT signal does not capture the dominant failure modes.
Figures




read the original abstract
Optimal transport (OT) has been shown to detect hallucinations in neural machine translation (NMT) by measuring the geometric distance between cross-attention distributions and a reference distribution, without any supervision. We extend this analysis to all six decoder layers of the Fairseq DE-EN model ($N=3{,}414$), showing that Wass-to-Unif and Wass-to-Data are complementary detectors specialised across hallucination types, that detection is concentrated in layers L1--L4 with L5 anti-predictive for subtler types, and that hallucinated translations lack the exploratory attention phase present in correct translations from the first decoding step. We further evaluate whether the geometric signal transfers to abstractive summarization faithfulness detection: our unsupervised OT detector on AggreFact ($N=1{,}116$) achieves $57.2\%$/$57.6\%$ balanced accuracy on CNN/XSum -- above chance but substantially below supervised MiniCheck-Flan-T5-L($69.9\%$/$74.3\%$). This gap is principled: unlike NMT hallucinations, unfaithful summaries can attend correctly to source tokens while misrepresenting their content, a failure mode invisible to concentration-based OT metrics by construction. Structural experiments on T5-base confirm consistent decoder organisation across depth, with Layer~3 showing peak concentration and Layer~12 being most critical for generation quality. Together, the results establish OT on cross-attention as a reliable detector when the failure mode is source disengagement, a principled interpretability tool regardless of task, and fundamentally limited when faithfulness failures occur downstream of attention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that optimal transport (OT) distances on cross-attention distributions provide an unsupervised, layer-resolved detector for hallucinations in NMT, with Wass-to-Unif and Wass-to-Data complementary across types and detection concentrated in layers L1-L4 (N=3414 samples); it further shows that this signal transfers to abstractive summarization faithfulness detection on AggreFact (N=1116) at 57.2%/57.6% balanced accuracy on CNN/XSum but is limited relative to supervised methods (~70-74%), attributing the gap to the principled fact that faithfulness failures can occur downstream of attention while still producing concentrated cross-attention.
Significance. If the empirical patterns hold, the work supplies sizable-scale evidence that geometric OT metrics are reliable precisely for source-disengagement failure modes, offers structural insights into decoder-layer organization (e.g., peak concentration at Layer 3, critical role of Layer 12), and delineates the boundary conditions under which attention-based interpretability tools succeed or fail across tasks. The concrete numbers, layer-wise analysis, and T5-base structural experiments constitute a clear contribution to hallucination detection methodology.
major comments (1)
- [Abstract] Abstract (summarization paragraph): the assertion that the performance gap is 'principled' because 'unfaithful summaries can attend correctly to source tokens while misrepresenting their content' is not supported by direct evidence; the manuscript reports no stratification of OT distances or attention concentration on the faithful vs. unfaithful subsets of AggreFact to verify that unfaithful cases indeed exhibit low deviation.
minor comments (2)
- [Abstract] Abstract: results are stated without error bars, confidence intervals, or mention of statistical tests, which reduces verifiability of the layer-specialization and complementarity claims despite the reported sample sizes.
- [Abstract] Abstract: 'Wass-to-Unif' and 'Wass-to-Data' are used without inline definition or reference to their exact formulations, which may hinder immediate comprehension.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and agree that additional analysis would strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (summarization paragraph): the assertion that the performance gap is 'principled' because 'unfaithful summaries can attend correctly to source tokens while misrepresenting their content' is not supported by direct evidence; the manuscript reports no stratification of OT distances or attention concentration on the faithful vs. unfaithful subsets of AggreFact to verify that unfaithful cases indeed exhibit low deviation.
Authors: We acknowledge that the current manuscript does not report a direct stratification of OT distances or attention concentration on the faithful versus unfaithful subsets of AggreFact. The principled nature of the gap follows from the metric definition: OT distances quantify geometric deviation of cross-attention from uniform or empirical reference distributions, which by construction detects source disengagement but is insensitive to cases where attention remains correctly concentrated yet content is misrepresented downstream. We will add the requested stratification analysis (comparing OT values and concentration statistics on the two subsets) to the revised version to supply the direct empirical verification. revision: yes
Circularity Check
No significant circularity: purely empirical measurements
full rationale
The paper performs direct empirical measurements of OT distances on cross-attention maps from fixed pretrained models (Fairseq DE-EN, T5-base) evaluated on public datasets (NMT test set N=3414, AggreFact N=1116). No equations, fitted parameters, or derivations are introduced whose outputs reduce by construction to inputs defined inside the paper. The 'by construction' phrasing in the abstract simply restates the definitional scope of concentration-based metrics and does not create a self-referential loop. Self-citations, if present, are not load-bearing for any central claim. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wasserstein distance between cross-attention distributions and a reference distribution measures source disengagement
Reference graph
Works this paper leans on
-
[1]
Guerreiro, N
URL https://anonymous.4open.science/r/ Layer_Resolved_Optimal_Transport. Guerreiro, N. M., Martins, A. F. T., and Mariet, Z. Opti- mal transport for unsupervised hallucination detection in neural machine translation. InProceedings of the 61st Annual Meeting of the Association for Computa- tional Linguistics (ACL 2023),
2023
-
[2]
Kry´sci´nski, W., McCann, B., Xiong, C., and Socher, R
URL https: //arxiv.org/abs/2212.09631. Kry´sci´nski, W., McCann, B., Xiong, C., and Socher, R. Evaluating the factual consistency of abstractive text summarization. InProceedings of the 2020 Conference 8 Layer-Resolved Optimal Transport for Hallucination Detection on Empirical Methods in Natural Language Processing (EMNLP 2020),
-
[3]
Maynez, J., Narayan, S., Bohnet, B., and McDonald, R
URL https://arxiv.org/ abs/1910.12840. Maynez, J., Narayan, S., Bohnet, B., and McDonald, R. On faithfulness and factuality in abstractive summarization. InProceedings of the 58th Annual Meeting of the Asso- ciation for Computational Linguistics (ACL 2020),
- [4]
-
[5]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., and Liu, P
URL https://arxiv.org/abs/ 1803.00567. Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21 (140):1–67,
-
[6]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
URL https://arxiv.org/abs/ 1910.10683. Tang, L., Goyal, T., Fabbri, A., Laban, P., Xu, J., Koncel- Kedziorski, R., Choi, E., Nenkova, A., and McKeown, K. Understanding factual errors in summarization: Er- rors, summarizers, datasets, error detectors. InPro- ceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL 2023),
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[7]
Tang, L., Laban, P., and McKeown, K
URL https://arxiv.org/abs/2205.12854. Tang, L., Laban, P., and McKeown, K. MiniCheck: Efficient fact-checking of LLMs on grounding documents. InPro- ceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024),
-
[8]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A
URLhttps://arxiv.org/abs/2404.10774. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Atten- tion is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30,
-
[9]
URL https://arxiv.org/abs/1706.03762. 9
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.