Reward Modeling for Multi-Agent Orchestration
Pith reviewed 2026-06-27 06:50 UTC · model grok-4.3
The pith
OrchRM trains multi-agent orchestrators without human labels by turning execution artifacts into win-lose pairs for reward modeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
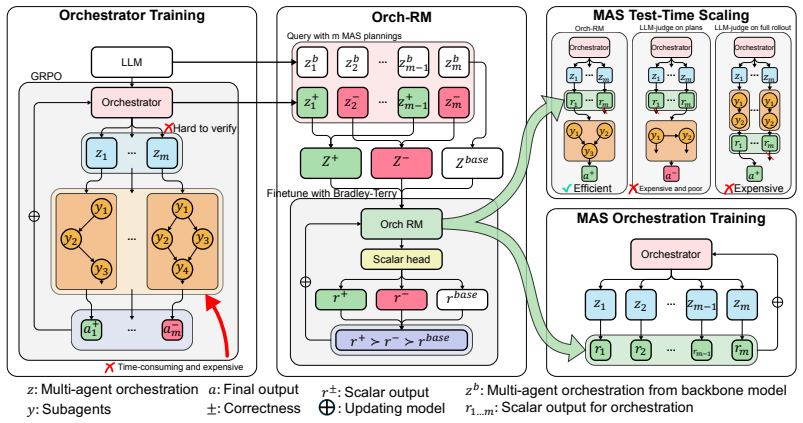
OrchRM constructs win-lose pairs from intermediate artifacts generated during multi-agent executions and trains a Bradley-Terry reward model on those pairs to score orchestration quality; the resulting model then guides both orchestrator training and test-time scaling decisions without any human annotations or extra sub-agent rollouts.
What carries the argument
Bradley-Terry reward model trained on automatically extracted win-lose pairs from multi-agent execution artifacts, which scores coordination choices at the orchestration level.
If this is right
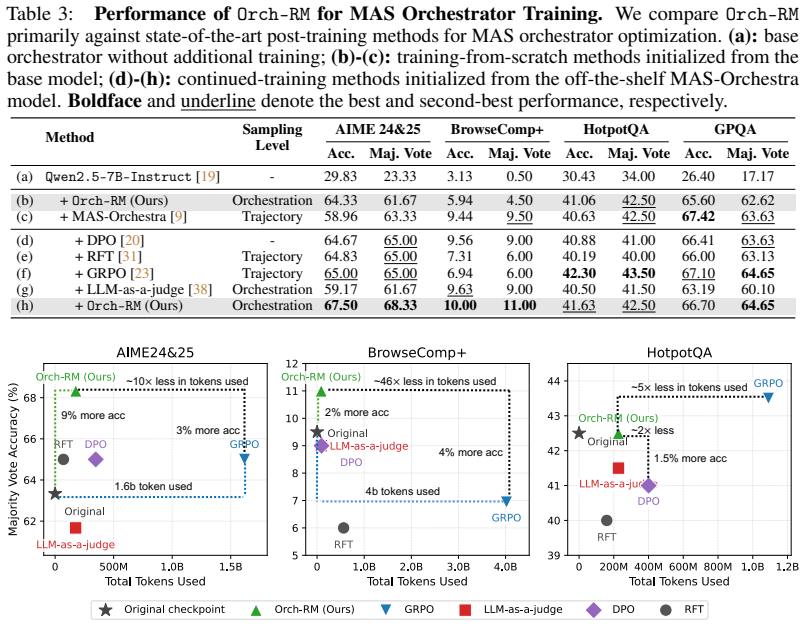
- Orchestrator training uses up to 10 times fewer tokens than prior MAS frameworks.
- Test-time scaling accuracy rises by up to 8 percent across domains.
- Performance gains hold for mathematical reasoning, web-based question answering, and multi-hop reasoning.
- Orchestration-level reward modeling becomes a scalable alternative to rollout-heavy methods.
Where Pith is reading between the lines
- The same artifact-based pairing technique could be tried on other coordination tasks where full rollouts are expensive.
- If the proxy holds, reward models might eventually replace some forms of human preference data in agent training pipelines.
- Combining OrchRM scores with existing test-time search methods could produce further accuracy lifts without proportional cost increases.
Load-bearing premise
Automatically built win-lose pairs from intermediate execution artifacts serve as a reliable stand-in for actual orchestration quality.
What would settle it
A side-by-side experiment in which human raters or an independent ground-truth metric consistently rank OrchRM-selected orchestrations lower than those chosen by a model trained on direct human labels would falsify the proxy's reliability.
Figures

read the original abstract
Multi-Agent Systems (MAS) built on Large Language Models (LLMs) require effective orchestration to coordinate specialized agents, yet training such orchestrators is hindered by limited supervision and high computational cost. We propose Orchestration Reward Modeling (OrchRM), a self-supervised framework for evaluating orchestration quality without human annotations. OrchRM leverages intermediate artifacts from multi-agent executions to construct win-lose pairs for Bradley-Terry reward model training. Unlike existing MAS test-time scaling and orchestrator training frameworks that rely on costly sub-agent rollouts, OrchRM operates directly at the orchestration level, enabling efficient and high-performing reward-guided orchestrator training and MAS test-time scaling. OrchRM improves training efficiency by up to 10x in token usage while improving MAS test-time scaling performance by up to 8% in accuracy. These gains consistently transfer across multiple domains, including mathematical reasoning, web-based question answering, and multi-hop reasoning, demonstrating orchestration-level reward modeling as a scalable direction for robust multi-agent orchestration. Code will be available at https://github.com/Wang-ML-Lab/OrchRM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Orchestration Reward Modeling (OrchRM), a self-supervised framework that constructs win-lose pairs from intermediate artifacts of multi-agent LLM executions to train a Bradley-Terry reward model for orchestration quality. It claims this enables reward-guided training of orchestrators and MAS test-time scaling with up to 10x lower token usage and up to 8% higher accuracy than baselines, with gains transferring across mathematical reasoning, web-based QA, and multi-hop reasoning domains. The method avoids human annotations and costly sub-agent rollouts by operating directly at the orchestration level.
Significance. If the synthetic pairs prove to be a faithful proxy for true orchestration quality that generalizes beyond the data-generation heuristic, the work could meaningfully reduce supervision costs for MAS orchestrators. The efficiency and cross-domain transfer claims, if substantiated with ablations and external validation, would strengthen the case for reward modeling as a scalable alternative to rollout-heavy approaches in multi-agent systems.
major comments (2)
- [Abstract] Abstract: the headline claims of 10x token efficiency and +8% accuracy rest on win-lose pairs derived solely from internal execution artifacts, yet no quantitative evidence is supplied that these pairs correlate with human judgments of orchestration quality or with downstream task success on held-out orchestrations. Without such validation, the risk that the RM merely reinforces the same heuristics used to generate the pairs cannot be assessed.
- [Abstract] Abstract: the description of the self-supervised pair construction is limited to a single sentence; the manuscript provides no equations, algorithm, or pseudocode showing how 'intermediate artifacts' are turned into independent win-lose labels, making it impossible to evaluate whether the Bradley-Terry training objective is circular with the final evaluation metric.
minor comments (1)
- [Abstract] The abstract states 'Code will be available' but gives no repository link or commit hash; a permanent link should be provided for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address each major comment below, proposing revisions where they strengthen the manuscript without misrepresenting our contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 10x token efficiency and +8% accuracy rest on win-lose pairs derived solely from internal execution artifacts, yet no quantitative evidence is supplied that these pairs correlate with human judgments of orchestration quality or with downstream task success on held-out orchestrations. Without such validation, the risk that the RM merely reinforces the same heuristics used to generate the pairs cannot be assessed.
Authors: We agree this is a substantive concern. The manuscript presents downstream accuracy and efficiency gains as primary evidence, with cross-domain transfer as indirect support that the pairs capture orchestration quality beyond the generation heuristic. However, we did not include direct correlation studies with human judgments or held-out orchestration success metrics. In revision we will add an explicit limitations paragraph acknowledging this gap and noting it as an important direction for future validation work. No new experiments are feasible at this stage, so the change is partial. revision: partial
-
Referee: [Abstract] Abstract: the description of the self-supervised pair construction is limited to a single sentence; the manuscript provides no equations, algorithm, or pseudocode showing how 'intermediate artifacts' are turned into independent win-lose labels, making it impossible to evaluate whether the Bradley-Terry training objective is circular with the final evaluation metric.
Authors: We accept this criticism. The pair-construction procedure is described too briefly. In the revised manuscript we will insert a new subsection (with equations for label derivation from execution traces and pseudocode for the full pair-generation process) that makes explicit how win/lose labels are obtained from intermediate artifacts independently of the final task metrics. This will allow readers to assess potential circularity directly. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description present OrchRM as a self-supervised method that constructs win-lose pairs from intermediate MAS execution artifacts to train a Bradley-Terry reward model. No equations, sections, or explicit derivations are available that reduce any claimed prediction, performance gain, or evaluation metric to the pair-construction heuristic by definition. No self-citations are referenced as load-bearing premises, and no uniqueness theorems or ansatzes are invoked. The claimed efficiency and accuracy improvements are positioned as empirical outcomes that transfer across domains, leaving the central derivation self-contained without reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bradley-Terry model can rank orchestration quality from automatically generated win-lose pairs
invented entities (1)
-
OrchRM framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker, H. Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
American Invitational Mathematics Examination
AIME. American Invitational Mathematics Examination. Mathematical Association of America, 2025.https://maa.org/maa-invitational-competitions/
2025
-
[3]
T. AIME. Aime problems and solutions, 2024
2024
-
[4]
Equipping agents for the real world with agent skills
Anthropic. Equipping agents for the real world with agent skills. https://www.anthropic. com/engineering/equipping-agents-for-the-real-world-with-agent-skills , 2024
2024
-
[5]
Y . Feng, A. Kwiatkowski, K. Zheng, J. Kempe, and Y . Duan. PILAF: Optimal human preference sampling for reward modeling. InForty-second International Conference on Machine Learning, 2025
2025
-
[6]
Y . Feng, H. Luo, Z. Lin, Y . Sun, P. Wei, L. B. Hsieh, and A. T. Luu. Orchmas: Orchestrated reasoning with multi collaborative heterogeneous scientific expert structured agents, 2026
2026
-
[7]
Openai gpt-5 system card, 2026
GPT-5Team. Openai gpt-5 system card, 2026
2026
-
[8]
Z. Ke, F. Jiao, Y . Ming, X.-P. Nguyen, A. Xu, D. X. Long, M. Li, C. Qin, P. Wang, S. Savarese, C. Xiong, and S. Joty. A survey of frontiers in llm reasoning: Inference scaling, learning to reason, and agentic systems.TMLR, 2025
2025
-
[9]
Z. Ke, Y . Ming, A. Xu, R. Chin, X.-P. Nguyen, P. Jwalapuram, J. Wang, S. Yavuz, C. Xiong, and S. Joty. Mas-orchestra: Understanding and improving multi-agent reasoning through holistic orchestration and controlled benchmarks.Forty-third International Conference on Machine Learning, 2026
2026
-
[10]
Z. Ke, A. Xu, Y . Ming, X.-P. Nguyen, C. Xiong, and S. Joty. MAS-ZERO: Designing multi-agent systems with zero supervision.SEA@NeurIPS, 2025
2025
-
[11]
Kumar, R
A. Kumar, R. Morabito, S. Umbet, J. Kabbara, and A. Emami. Confidence under the hood: An investigation into the confidence-probability alignment in large language models. In L.-W. Ku, A. Martins, and V . Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 315–334, Bangkok...
2024
-
[12]
C. Y . Liu, L. Zeng, J. Liu, R. Yan, J. He, C. Wang, S. Yan, Y . Liu, and Y . Zhou. Skywork-reward: Bag of tricks for reward modeling in llms.arXiv preprint arXiv:2410.18451, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
C. Y . Liu, L. Zeng, Y . Xiao, J. He, J. Liu, C. Wang, R. Yan, W. Shen, F. Zhang, J. Xu, et al. Skywork-reward-v2: Scaling preference data curation via human-ai synergy.arXiv preprint arXiv:2507.01352, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Z. Liu, Y . Zhang, P. Li, Y . Liu, and D. Yang. A dynamic LLM-powered agent network for task-oriented agent collaboration. InFirst Conference on Language Modeling, 2024
2024
-
[15]
Madaan, N
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark. Self-refine: Iterative refinement with self-feedback. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[16]
B. Niu, Y . Song, K. Lian, Y . Shen, Y . Yao, K. Zhang, and T. Liu. Flow: Modularized agentic workflow automation, 2025. 10
2025
-
[17]
Openai gpt-4.1 nano model, 2025
OpenAI. Openai gpt-4.1 nano model, 2025. Released April 14, 2025 via API; 1 million token context window; fastest & cheapest version in GPT-4.1 family
2025
-
[18]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Gray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welin- der, P. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors,A...
2022
-
[19]
T. Qwen. Qwen2.5: A party of foundation models, September 2024
2024
-
[20]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, Neu...
2023
-
[21]
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y . Pang, J. Dirani, J. Michael, and S. R. Bowman. Gpqa: A graduate-level google-proof qa benchmark, 2023
2023
-
[22]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
H. Su, S. Diao, X. Lu, M. Liu, J. Xu, X. Dong, Y . Fu, P. Belcak, H. Ye, H. Yin, Y . Dong, E. Bakhturina, T. Yu, Y . Choi, J. Kautz, and P. Molchanov. Toolorchestra: Elevating intelligence via efficient model and tool orchestration, 2025
2025
-
[25]
Venkataramani, H
V . Venkataramani, H. Shi, Z. Ke, A. Xu, X. He, Y . Zhou, S. Yavuz, H. Wang, and S. Joty. Mas- prove: Understanding the process verification of multi-agent systems.Forty-third International Conference on Machine Learning, 2026
2026
-
[26]
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[27]
J. Wei, Z. Sun, S. Papay, S. McKinney, J. Han, I. Fulford, H. W. Chung, A. T. Passos, W. Fedus, and A. Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents, 2025
2025
-
[28]
Z. Xi, W. Chen, X. Guo, W. He, Y . Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhou, R. Zheng, X. Fan, X. Wang, L. Xiong, Y . Zhou, W. Wang, C. Jiang, Y . Zou, X. Liu, Z. Yin, S. Dou, R. Weng, W. Cheng, Q. Zhang, W. Qin, Y . Zheng, X. Qiu, X. Huang, and T. Gui. The rise and potential of large language model based agents: A survey.arXiv preprint arXiv:230...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium, Oct.-Nov
2018
-
[30]
Association for Computational Linguistics
-
[31]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[32]
Z. Yuan, H. Yuan, C. Li, G. Dong, C. Tan, and C. Zhou. Scaling relationship on learning mathematical reasoning with large language models.CoRR, abs/2308.01825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
L. Yue, K. R. Bhandari, C.-Y . Ko, D. Patel, S. Lin, N. Zhou, J. Gao, P.-Y . Chen, and S. Pan. From static templates to dynamic runtime graphs: A survey of workflow optimization for llm agents, 2026. 11
2026
-
[34]
Zhang, T
H. Zhang, T. Feng, and J. You. Router-r1: Teaching LLMs multi-round routing and aggregation via reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[35]
Zhang, J
J. Zhang, J. Xiang, Z. Yu, F. Teng, X.-H. Chen, J. Chen, M. Zhuge, X. Cheng, S. Hong, J. Wang, B. Zheng, B. Liu, Y . Luo, and C. Wu. AFlow: Automating agentic workflow generation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[36]
Zhang, K
K. Zhang, K. Tian, R. Liu, S. Zeng, X. Zhu, G. Jia, Y . Fan, X. Lv, Y . Zuo, C. Jiang, Y . wang, J. Wang, E. Hua, X. Long, J. Gao, Y . Sun, Z. Ma, G. Cui, N. Ding, B. Qi, and B. Zhou. MARTI: A framework for multi-agent LLM systems reinforced training and inference. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[37]
Zhang, H
Z. Zhang, H. Liu, X. Li, Z. Dai, J. Zeng, F. Wang, M. Lin, R. Chandradevan, L. Wu, Z. Li, C. Luo, Z. Wu, X. Tang, Q. He, and S. Wang. Bradley-terry and multi-objective reward modeling are complementary. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[38]
Y . Zhao, L. Hu, Y . Wang, M. Hou, H. Zhang, K. Ding, and J. Zhao. Stronger-MAS: Multi-agent reinforcement learning for collaborative LLMs. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[39]
correct-over-incorrect
L. Zheng, W. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural In...
2023
-
[40]
Has a specific purpose and expertise area
-
[41]
Uses its own context window separate from the main conversation
-
[42]
(Optional) Can be configured with specific tools it’s allowed to use 14
-
[43]
Each agent must contain <agent_name>, <agent_description>,<required_arguments>, and<agent_output_id>
Includes a custom system prompt that guides its behavior An agent should be defined in channel <agent>. Each agent must contain <agent_name>, <agent_description>,<required_arguments>, and<agent_output_id>. DO NOT MISS ANY REQUEST FIELDS and ensure that your response is a well- formed XML object!<|im_end|> <|im_start|>user Please solve the question step by...
2024
-
[44]
agent_input must be an Info object
Chain-of-Thought Agent (CoTAgent) Description: Encourages the LLM to think step by step rather than directly outputting an answer, enabling complex problem-solving. Required Arguments:agent_input(If left empty, defaults to original question). async def CoTAgent(self, agent_input, model: str): from mas_r1_reasoner.agents.agent_system import LLMAgentBase, I...
-
[45]
Please think step by step and then solve the task
Self-Consistency with Chain-of-Thought (SCAgent) Description: Repeatedly asks the same question with high temperature to generate different reasoning paths, combining them through majority voting ensembling. 16 Required Arguments:agent_input. async def SCAgent(self, agent_input, model: str): from mas_r1_reasoner.agents.agent_system import LLMAgentBase, In...
-
[46]
Math Profes- sor
LLM Debate (DebateAgent) Description: Lets different LLMs debate with each other, leveraging diverse perspectives to find better solutions. Required Arguments:agent_input , debate_roles (List of roles, e.g., ["Math Profes- sor", "Statistician"]). async def DebateAgent(self, agent_input, model: str, debate_roles: List[str]): temperature = 0.5; max_debate_r...
-
[47]
Graph Theory Expert
Self-Refine (ReflexionAgent) Description:Iteratively improves answers based on feedback from a Critic agent. Required Arguments:agent_input. async def ReflexionAgent(self, agent_input, model: str): temperature = 0.5; max_reflection_round = 5 cot_agent = LLMAgentBase([’thinking’, ’answer’], ’Chain-of-Thought LLM’, ...) critic_agent = LLMAgentBase([’feedbac...
2025
-
[48]
- The inequalities \(x - yz\textless y - zx\textless z - xy\) need to be analyzed to determine the regions where they hold true
Initial Analysis: - The plane equation \(x + y + z = 75\) represents a plane in 3D space. - The inequalities \(x - yz\textless y - zx\textless z - xy\) need to be analyzed to determine the regions where they hold true. 19
-
[49]
Agent into the De De of the inequalities: - \(x - yz\textless y - zx\) - \(y - zx\textless z - xy\)
-
[50]
Mathematics Professor
Delegation to DebateAgent: - We need to debate the regions where these inequalities hold true. - The DebateAgent will involve perspectives from a "Mathematics Professor" and a "Geometry Specialist" to ensure a comprehensive and accurate solution. ### Agent Delegation to DebateAgent The DebateAgent will handle the detailed analysis and provide a final answ...
2025
-
[51]
Thinking Phase: - We comprehend the given problem: Finding the area of a finite convex region in 3D space defined by the plane equation \(x + y + z = 75\) and the inequalities \(x - yz\textless y - zx\textless z - xy\)
-
[52]
Geometry Specialist
Delegation Decision: - This problem combines geometry (plane and convex regions), algebra (inequalities), and area computation. It benefits from diverse perspectives, making it ideal for the DebateAgent. The DebateAgent allows different specialized LLMs (e.g., a "Geometry Specialist" and an "Inequality Expert") to debate and converge on the correct soluti...
-
[54]
Geometry Specialist
Final Answer Tag: - The <answer> tag will contain the output identifier debate_agent_output, representing the complete and verified solution generated by the DebateAgent. This approach ensures both correctness and confidence through collaborative reasoning. ---------------------------------------------------------------------- > Executing DebateAgent [Geo...
-
[55]
The goal is to find the finite-area 21 convex region formed by these conditions and express its area in the form \(a\sqrt{b}\), then compute \(a + b\)
Thinking Phase: - We understand the given constraints: the plane equation \(x + y + z = 75\) and the inequalities \(x - yz\textless y - zx\textless z - xy\). The goal is to find the finite-area 21 convex region formed by these conditions and express its area in the form \(a\sqrt{b}\), then compute \(a + b\)
-
[56]
Geometry Specialist
Delegation Decision: - This problem combines geometry (plane equations and region definitions), algebra (inequalities), and area computation. It benefits from diverse perspectives, making it ideal for the DebateAgent. The DebateAgent allows different specialized LLMs (e.g., a "Geometry Specialist" and an "Inequality Expert") to debate and converge on the ...
-
[57]
" (empty) as instructed, ensuring the original question is inserted by the parser. - debate_roles: A list containing two distinct expert roles (
Agent Definition: - Agent Name: DebateAgent - Agent Description: Fits the problem’s need for diverse and justified reasoning. - Required Arguments: - agent_input: Set to "" (empty) as instructed, ensuring the original question is inserted by the parser. - debate_roles: A list containing two distinct expert roles ("Geometry Specialist" and "Inequality Expe...
-
[58]
Geometry Specialist
Final Answer Tag: - The <answer> tag will contain the output identifier debate_agent_output, representing the complete and justified solution generated by the DebateAgent. This approach ensures both correctness and confidence through collaborative reasoning. ---------------------------------------------------------------------- > Executing DebateAgent [Ge...
-
[59]
Thinking Phase: - We comprehend the given problem: Find the area of the finite region in the plane \(x + y + z = 75\) constrained by \(x - yz\textless y - zx\textless z - xy\)
-
[60]
Geometry Specialist
Delegation Decision: - This problem combines geometric constraints (plane equation and region bounds) and algebraic inequalities. It benefits from diverse perspectives, making it ideal for the DebateAgent. The DebateAgent allows different specialized LLMs (e.g., a "Geometry Specialist" and an "Inequality Expert") to debate and converge on the correct solu...
-
[61]
" (empty) as instructed, ensuring the original question is inserted by the parser. - debate_roles: A list with two distinct expert roles (
Agent Definition: - Agent Name: DebateAgent - Agent Description: Fits the problem’s need for diverse and justified reasoning. - Required Arguments: - agent_input: Set to "" (empty) as instructed, ensuring the original question is inserted by the parser. - debate_roles: A list with two distinct expert roles ("Geometry Specialist" and "Inequality Expert"), ...
-
[62]
This approach ensures both correctness and confidence through collaborative reasoning
Final Answer Tag: - The <answer> tag will contain the output identifier debate_agent_output, representing the complete and justified solution generated by the DebateAgent. This approach ensures both correctness and confidence through collaborative reasoning. ---------------------------------------------------------------------- > Executing DebateAgent [Ge...
2020
-
[63]
The birth year (1820-1830) and the named street in a European capital
-
[64]
The move to Germany with the brother and the encounter with the English writer
-
[65]
completion year
The role as a tutor in the United States and the friendship with the photographer. Each agent focuses on a distinct aspect, ensuring no detail is overlooked. The findings will be cross-verified, and the ReflexionAgent will consolidate the information, cross-checking dates, names, and events for accuracy. The ReflexionAgent is the final sink, producing a c...
2020
-
[66]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.