Not Truly Multilingual: Script Consistency as a Missing Dimension in VLM Evaluation
Pith reviewed 2026-06-27 04:07 UTC · model grok-4.3
The pith
Current multilingual VLMs are not truly multi-script, showing systematic performance gaps up to 16% on identical visual tasks across different scripts of one language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
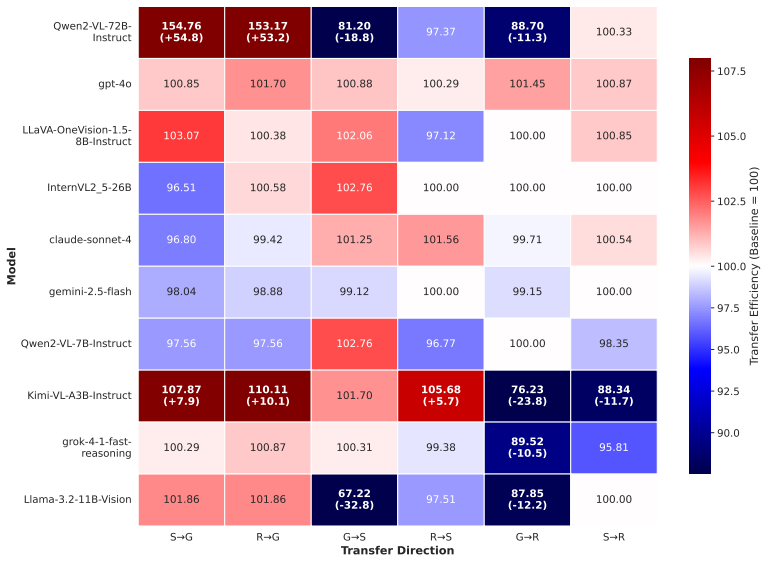
Evaluating ten state-of-the-art VLMs on the PuMVR benchmark reveals a substantial and systematic Script Gap, where models solve visual tasks in one script while failing identical tasks in another. Visual input boosts absolute performance uniformly yet does not close the orthographic gap. Cross-script in-context transfer is highly brittle, exposing script-locked knowledge representation. Supported by McNemar tests across all script pairs, the findings demonstrate that current multilingual VLMs are not truly multi-script, with the Script Consistency Rate falling as low as 24.8 percent.
What carries the argument
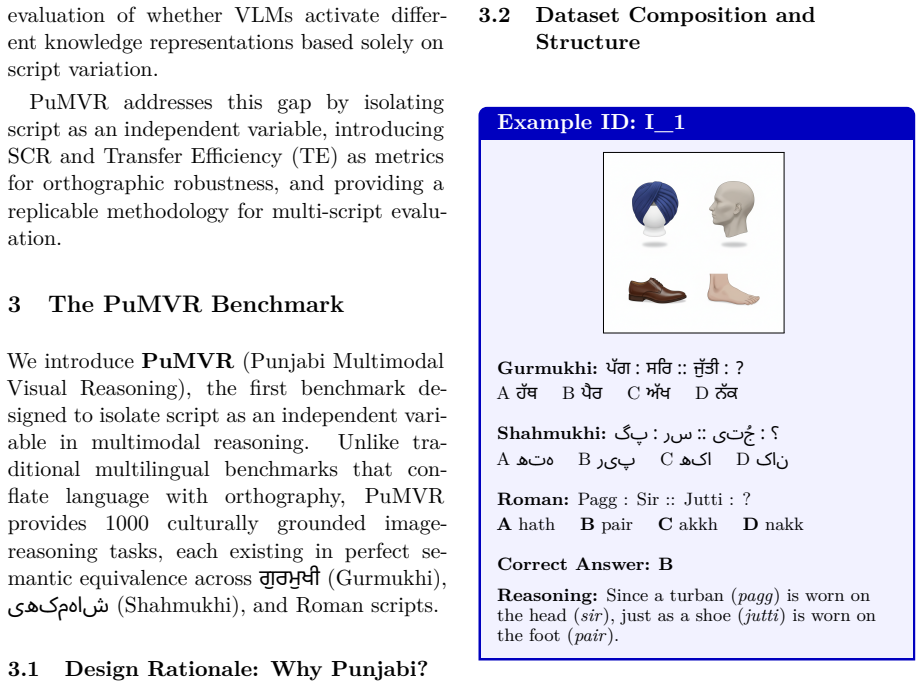
The PuMVR benchmark of 1,000 strictly parallel image-text instances across Punjabi's Gurmukhi, Shahmukhi, and Roman scripts, used to compute the Script Consistency Rate (SCR) as the measure of script-agnostic performance.
If this is right
- Accuracy deltas reach 16% between scripts on identical visual reasoning tasks.
- Visual input improves performance uniformly across scripts but does not reduce the orthographic gaps.
- In-context learning examples do not transfer reliably when the script changes.
- The Script Consistency Rate reaches lows of 24.8% on the benchmark, indicating inconsistent script handling.
Where Pith is reading between the lines
- Similar script gaps are likely to appear when testing other multi-script languages that share the same linguistic content across orthographies.
- Tokenization differences and uneven script representation in training data are probable root causes of the observed script locking.
- Requiring the Script Consistency Rate in standard VLM benchmarks would push development toward representations that treat scripts as interchangeable for the same language.
Load-bearing premise
The 1,000 instances are strictly parallel across scripts with identical task difficulty and content, so any performance differences can be attributed to script rather than rendering, tokenization, or data distribution factors.
What would settle it
Re-evaluating the ten VLMs on the PuMVR benchmark and obtaining no statistically significant accuracy differences between any script pairs according to McNemar tests would falsify the existence of a systematic script gap.
Figures

read the original abstract
Current multilingual evaluations for Vision-Language Models (VLMs) assume a one-to-one mapping between language and orthography, overlooking billions of users of multi-script languages. We introduce PuMVR (Punjabi Multimodal Visual Reasoning), a benchmark of 1,000 strictly parallel image-text instances across Punjabi's three active scripts: Gurmukhi, Shahmukhi, and Roman. Evaluating 10 state-of-the-art VLMs, we expose a substantial and systematic Script Gap. Models frequently solve visual tasks in one script while failing identical tasks in another, with accuracy deltas reaching 16%. Crucially, visual input boosts absolute performance uniformly yet does not close the orthographic gap. Furthermore, cross-script in-context transfer is highly brittle, exposing script-locked knowledge representation. Supported by McNemar tests across all script pairs, our findings demonstrate that current "multilingual" VLMs are not truly multi-script. We propose the Script Consistency Rate (SCR), which falls as low as 24.8% on our benchmark, as a mandatory metric for script-agnostic evaluation to ensure equitable AI access. Data and code are available at: https://github.com/prabhjotschugh/Not-Truly-Multilingual-PuMVR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PuMVR, a benchmark of 1,000 strictly parallel image-text instances across Punjabi's three scripts (Gurmukhi, Shahmukhi, Roman). Evaluating 10 VLMs, it reports accuracy deltas up to 16% between scripts on identical visual tasks, shows that visual input boosts performance uniformly but does not close the orthographic gap, finds cross-script in-context transfer brittle, and proposes the Script Consistency Rate (SCR) metric (as low as 24.8%) supported by McNemar tests to argue that current 'multilingual' VLMs are not truly multi-script.
Significance. If the parallelism of instances holds, the work identifies script consistency as an overlooked dimension in VLM evaluation for multi-script languages spoken by billions, with implications for equitable access. The public release of data and code is a clear strength for reproducibility and follow-up work.
major comments (3)
- [§3 (Dataset Construction)] §3 (Dataset Construction): The central claim that performance deltas are attributable to script alone rests on the 1,000 instances being strictly parallel with identical semantics, task difficulty, and no confounds from translation or tokenization; the manuscript provides no explicit verification protocol (e.g., back-translation, expert equivalence ratings, or controls for Romanization variability), which is load-bearing for the attribution of gaps to orthography rather than other factors.
- [§4 (Evaluation and Results)] §4 (Evaluation and Results): While McNemar tests are invoked to support systematic gaps across script pairs, the manuscript should report exact test statistics, p-values (with correction for multiple comparisons), and effect sizes per model and pair to substantiate the 'substantial' claim rather than relying on accuracy deltas alone.
- [§5 (Proposed Metric)] §5 (Proposed Metric): The Script Consistency Rate (SCR) is presented as a mandatory new metric, but its precise definition, aggregation across three scripts, and normalization must be formalized (ideally with an equation) to allow independent verification and ensure it is not reducible to simple accuracy variance.
minor comments (2)
- Figure captions should explicitly label the three scripts and clarify whether bars represent per-script accuracy or consistency rates.
- The related work section should more explicitly contrast PuMVR against prior multilingual VLM benchmarks that include non-Latin scripts to better position the novelty of the script-gap focus.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the rigor of our claims. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§3 (Dataset Construction)] The central claim that performance deltas are attributable to script alone rests on the 1,000 instances being strictly parallel with identical semantics, task difficulty, and no confounds from translation or tokenization; the manuscript provides no explicit verification protocol (e.g., back-translation, expert equivalence ratings, or controls for Romanization variability), which is load-bearing for the attribution of gaps to orthography rather than other factors.
Authors: We agree that an explicit verification protocol should have been included to fully support the parallelism claim. In the revised manuscript, we have added a new subsection in §3 that details the protocol used: independent back-translation of all instances, equivalence ratings by three native Punjabi linguists (with reported inter-rater agreement), and explicit controls for Romanization variants. These steps confirm identical semantics and task difficulty across scripts, allowing attribution of gaps to orthography. revision: yes
-
Referee: [§4 (Evaluation and Results)] While McNemar tests are invoked to support systematic gaps across script pairs, the manuscript should report exact test statistics, p-values (with correction for multiple comparisons), and effect sizes per model and pair to substantiate the 'substantial' claim rather than relying on accuracy deltas alone.
Authors: We concur that full statistical reporting is needed. The revised §4 now includes a supplementary table reporting exact McNemar χ² statistics, Bonferroni-corrected p-values across all model-script-pair comparisons, and effect sizes (Cohen's h) for each of the 10 models. These additional details substantiate that the gaps are systematic and statistically significant beyond the reported accuracy deltas. revision: yes
-
Referee: [§5 (Proposed Metric)] The Script Consistency Rate (SCR) is presented as a mandatory new metric, but its precise definition, aggregation across three scripts, and normalization must be formalized (ideally with an equation) to allow independent verification and ensure it is not reducible to simple accuracy variance.
Authors: We have addressed this by adding a formal definition and equation for SCR in the revised §5. SCR is defined as the proportion of instances where a model produces correct answers across all three scripts, aggregated as the mean over N instances and normalized to the unit interval. This per-instance consistency measure is mathematically distinct from aggregate accuracy variance, as shown in the added equation and accompanying explanation. revision: yes
Circularity Check
No circularity: empirical benchmark with independent data collection
full rationale
The paper constructs a new benchmark (PuMVR) of 1,000 parallel image-text instances across three scripts and evaluates existing VLMs on it, reporting accuracy deltas and proposing SCR as a metric. No equations, fitted parameters, or derivations are present that reduce results to inputs by construction. Claims rest on direct model evaluations and statistical tests (McNemar) rather than self-referential definitions or self-citation chains. The parallelism assumption is an empirical claim about data construction, not a definitional loop. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 1,000 instances are strictly parallel across the three scripts with identical task difficulty and content.
invented entities (1)
-
Script Consistency Rate (SCR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learning Transferable Visual Models From Natural Language Supervision
CORI: CJKV benchmark with Roman- ization integration - a step towards cross-lingual transfer beyond textual scripts . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages 4008–4020, Torino, Italia. ELRA and ICCL. OpenAI. 2024. GPT-4o System Card. https:// opena...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Blend-vis: Benchmarking multimodal cul- tural understanding in vision language models . Preprint, arXiv:2510.11178. Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Gar- rett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, Soroosh Mariooryad, Yifan Ding, Xinyang Geng, Fred Alcober, Roy Frostig, Mark Omernick, Lexi Walker,...
-
[3]
All languages matter: Evaluating lmms on culturally diverse 100 languages . Preprint, arXiv:2411.16508. Da Yin, Liunian Harold Li, Ziniu Hu, Nanyun Peng, and Kai-Wei Chang. 2021. Broaden the vision: Geo-diverse visual commonsense reason- ing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Process- ing, pages 2115–2129, Onli...
-
[4]
Forcing the model to re- produce the script-specific text ensures it can parse and generate the target orthog- raphy
Script Comprehension V erification: A model might correctly guess a letter (25% probability) without truly process- ing the script. Forcing the model to re- produce the script-specific text ensures it can parse and generate the target orthog- raphy
-
[5]
hallucinated
F ailure Mode Analysis: By requiring text output, we could identify cases where models produced "hallucinated" charac- ters or mixed scripts, data that would be lost if restricted to single-letter outputs. D.3 Experiment 1: Baseline Script Gap The primary benchmark used the following template with English instructions and script- specific constraints. Exp ...
-
[10]
Exp 2: Native Script Instructions Question {Script Instruction}: {question} Options: {formatted_options} CRITICAL RULES:
Output ONLY the option text, nothing else Your answer (copy exact text from options): Answer: D.4 Experiment 2: Native Instruction Prompting This experiment used similar prompts as ex- periment 1, without the image input to test model performance and establish a baseline. Exp 2: Native Script Instructions Question {Script Instruction}: {question} Options:...
-
[11]
Answer MUST be in the SAME script as the question
-
[12]
Copy EXACTLY one option from above - character by character
-
[13]
NO explanations, NO extra words, NO English translations
-
[14]
NO letters like A), B), C) or numbers
-
[15]
Exp 3: System Prompt You are a precise answering assistant
Output ONLY the option text, nothing else Your answer (copy exact text from options): D.5 Experiment 3: System Prompting (F ew-Shot) For experiments involving system-level instruc- tions, the following persona-based prompt was utilized. Exp 3: System Prompt You are a precise answering assistant. You will be given a visual question and options. You must ou...
-
[16]
NO option letters (like A, B)
-
[17]
Output strictly the option text. E Error Classification Details Table 7 reports the per-script breakdown of error types across all 11,250 model responses (10 models × 375 instances × 3 scripts), con- firming that the generative evaluation design measures comprehension rather than output formatting difficulty. Script Comp. F ailures Empty F ormatting Gurmukhi ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.