TerraTransfer: Learning End-to-End Driving Policies Without Expert Demonstrations
Pith reviewed 2026-06-27 02:23 UTC · model grok-4.3
The pith
Self-play in vectorized simulators enables end-to-end image driving policies without expert demonstrations via latent space alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
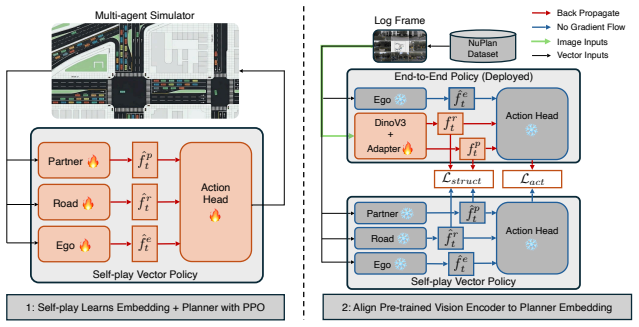
By pretraining a policy exclusively through self-play in a vectorized simulator and then aligning its latent space to a vision backbone with action KL divergence and batch-relational low-rank structural loss on paired image and scene-state data, the approach produces an end-to-end image-based driving policy that requires no expert trajectory supervision and achieves performance matching or exceeding prior methods on photorealistic closed-loop scenarios.
What carries the argument
The latent space alignment process that transfers self-play behavior to an image-based model using action KL divergence and batch-relational low-rank structural loss.
If this is right
- End-to-end policies can be trained without the cost of collecting and labeling expert driving demonstrations.
- Self-play supplies state distributions rich in collisions and recoveries absent from logged data.
- Pretrained vision backbones can be used directly for image inputs after alignment.
- Only paired image and scene-state frames are required for the transfer step.
- Closed-loop performance on photorealistic renderings reaches or surpasses imitation-based baselines.
Where Pith is reading between the lines
- The decoupling of policy learning from vision learning could apply to other simulation-heavy robotics tasks.
- Similar alignment techniques might reduce expert data needs in other vision-based control domains.
- Extending self-play to more complex vectorized environments could improve transfer quality.
- The batch-relational loss may help preserve structural consistency across diverse driving situations.
Load-bearing premise
That aligning the self-play policy's latent space to a vision backbone via action KL divergence and batch-relational low-rank structural loss will produce a functional image-based driving policy without expert trajectory supervision.
What would settle it
If the aligned image-based policy shows markedly worse closed-loop success rates than prior expert-supervised methods on the same photorealistic 3D Gaussian splatting scenarios, the central claim would be refuted.
Figures









read the original abstract
End-to-end autonomous driving has achieved state-of-the-art performance on benchmarks and real-world deployments. Its standard training recipe, however, is expensive across all stages: collecting and labeling millions of driving frames is costly, and closed-loop RL on images is bottlenecked by the per-step cost of photorealistic rendering plus a forward pass through a large vision backbone. Self-play in vectorized simulators changes the economics: millions of rollout steps per second, and a state distribution naturally rich in collisions, near-misses, and recoveries that no driving log contains. Our approach exploits this asymmetry by decoupling learning to drive from learning to see. We pretrain a single policy by self-play, then align its latent space with a pretrained vision backbone, through the action KL divergence and a batch-relational low-rank structural loss. The action target comes from the self-play policy, so alignment never supervises against a logged trajectory: a paired dataset of (image, scene-state) frames suffices, with no need for the curated expert demonstrations that imitation pretraining is built on. On photorealistic 3D Gaussian splatting closed-loop scenarios, the resulting end-to-end policy matches or exceeds prior end-to-end methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TerraTransfer, a method to learn end-to-end driving policies without expert demonstrations. A policy is first pretrained via self-play in a vectorized simulator; its latent space is then aligned to a pretrained vision backbone using action KL divergence together with a batch-relational low-rank structural loss on paired (image, scene-state) frames. The resulting image-based policy is evaluated in closed-loop on photorealistic 3D Gaussian splatting scenarios, where it is claimed to match or exceed prior end-to-end methods.
Significance. If the central claim holds, the work would materially lower the cost of training end-to-end driving policies by exploiting the speed and rich failure-state distribution of vectorized self-play while removing the need for curated expert trajectories. The explicit decoupling of policy learning from perception learning is a substantive conceptual contribution that could generalize beyond driving.
major comments (2)
- [Abstract / §3 (alignment)] The alignment procedure (described in the abstract and presumably §3) uses paired (image, scene-state) frames and action KL divergence, yet the manuscript does not state whether the scene-states are generated inside the vectorized simulator or inside the target Gaussian-splatting environment. If the former, the domain gap in dynamics, geometry, and physics is never directly penalized and remains load-bearing for the claim that the transferred policy functions in photorealistic closed-loop rollouts.
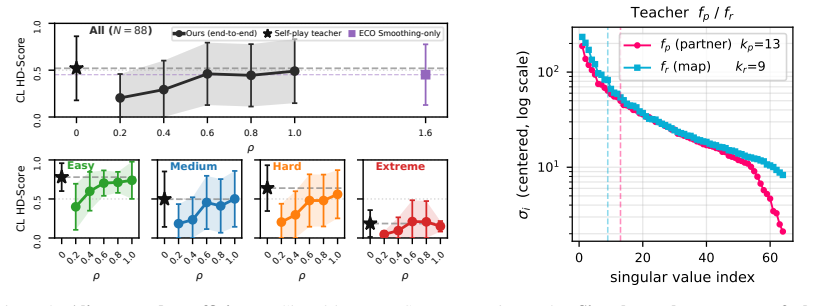
- [§4] §4 (closed-loop evaluation): the claim that the policy “matches or exceeds prior end-to-end methods” is presented without reported trial counts, variance, or statistical tests against the cited baselines; a single qualitative statement is insufficient to support the performance conclusion that justifies the entire pipeline.
minor comments (1)
- [Abstract / §3] The batch-relational low-rank structural loss is named but not defined or referenced; a short equation or citation would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / §3 (alignment)] The alignment procedure (described in the abstract and presumably §3) uses paired (image, scene-state) frames and action KL divergence, yet the manuscript does not state whether the scene-states are generated inside the vectorized simulator or inside the target Gaussian-splatting environment. If the former, the domain gap in dynamics, geometry, and physics is never directly penalized and remains load-bearing for the claim that the transferred policy functions in photorealistic closed-loop rollouts.
Authors: We agree that the source of the scene-states must be stated explicitly. The paired (image, scene-state) frames are constructed by rendering images from the 3D Gaussian splatting environment while obtaining the corresponding scene-states from the vectorized simulator for the same underlying scene configuration. We will revise §3 to state this construction clearly and add a short discussion of how the alignment losses are intended to mitigate the resulting domain gap. revision: yes
-
Referee: [§4] §4 (closed-loop evaluation): the claim that the policy “matches or exceeds prior end-to-end methods” is presented without reported trial counts, variance, or statistical tests against the cited baselines; a single qualitative statement is insufficient to support the performance conclusion that justifies the entire pipeline.
Authors: We acknowledge that the current presentation of the closed-loop results lacks the quantitative detail needed to substantiate the performance claims. We will expand §4 to report the number of independent trials, standard deviations or confidence intervals, and appropriate statistical comparisons against the baselines. revision: yes
Circularity Check
No circularity: method is a standard self-play pretrain + latent alignment pipeline with empirical claims
full rationale
The provided abstract and description outline a two-stage procedure: (1) self-play RL in a vectorized simulator to obtain a policy, (2) alignment of a vision backbone's latent space to that policy via action KL divergence plus a structural loss on paired (image, scene-state) frames. No equation in the text reduces a claimed result to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The performance statement is an empirical claim on closed-loop Gaussian-splatting rollouts rather than a mathematical identity. The derivation chain is therefore self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Paden, M
B. Paden, M. ˇC´ap, S. Z. Yong, D. Yershov, and E. Frazzoli. A survey of motion planning and control techniques for self-driving urban vehicles.IEEE Transactions on Intelligent V ehicles, 1(1):33–55, 2016
2016
-
[2]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, V . Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y . Zhang, J. Shlens, Z. Chen, and D. Anguelov. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF ...
2020
-
[3]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. Wolff, A. Lang, L. Fletcher, O. Beijbom, and S. Omari. nuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
End to End Learning for Self-Driving Cars
M. Bojarski, D. D. Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Mon- fort, U. Muller, J. Zhang, X. Zhang, J. Zhao, and K. Zieba. End to end learning for self-driving cars.arXiv preprint arXiv:1604.07316, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Codevilla, E
F. Codevilla, E. Santana, A. M. L ´opez, and A. Gaidon. Exploring the limitations of behavior cloning for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[6]
Caesar, V
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom. nuScenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[7]
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, L. Lu, X. Jia, Q. Liu, J. Dai, Y . Qiao, and H. Li. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[8]
Jiang, S
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang. V AD: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[9]
Chitta, A
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger. TransFuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 45(11):12878–12895, 2023
2023
-
[10]
Dauner, M
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, A. Geiger, and K. Chitta. NA VSIM: Data-driven non-reactive au- tonomous vehicle simulation and benchmarking. InAdvances in Neural Information Process- ing Systems (NeurIPS) Datasets and Benchmarks Track, 2024
2024
- [11]
-
[12]
Zhang, M
B. Zhang, M. Golchoubian, I. Gilitschenski, B. Ivanovic, and K. Chitta. Endpoint constrained trajectory optimization for driving foundation models. InICCV RealADSim Workshop, 2025
2025
-
[13]
Karkus, M
P. Karkus, M. Igl, Y . Chen, K. Chitta, J. Packer, B. Douillard, T. Tian, A. Naumann, G. Garcia- Cobo, S. Tan, A. Degirmenci, A. Popov, N. Smolyanskiy, U. Muller, B. Ivanovic, and M. Pavone. Beyond behavior cloning in autonomous driving: a survey of closed-loop training techniques.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[14]
Dosovitskiy, G
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun. CARLA: An open urban driving simulator. InProceedings of the Conference on Robot Learning (CoRL), 2017. 9
2017
-
[15]
D. Chen, B. Zhou, V . Koltun, and P. Kr¨ahenb¨uhl. Learning by cheating. InProceedings of the Conference on Robot Learning (CoRL), 2019
2019
-
[16]
Zhang, A
Z. Zhang, A. Liniger, D. Dai, F. Yu, and L. Van Gool. End-to-end urban driving by imitating a reinforcement learning coach. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[17]
P. Wu, X. Jia, L. Chen, J. Yan, H. Li, and Y . Qiao. Trajectory-guided control prediction for end- to-end autonomous driving: A simple yet strong baseline. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[18]
M. Cusumano-Towner, D. Hafner, A. Hertzberg, B. Huval, A. Petrenko, E. Vinitsky, E. Wij- mans, T. Killian, S. Bowers, O. Sener, P. Kr¨ahenb¨uhl, and V . Koltun. Robust autonomy emerges from self-play.arXiv preprint arXiv:2502.03349, 2025
-
[19]
Chang, A
W.-J. Chang, A. Rangesh, K. Joseph, M. Strong, M. Tomizuka, Y . Hu, and W. Zhan. SPACeR: Self-play anchoring with centralized reference models. InProceedings of the International Conference on Learning Representations (ICLR), 2026
2026
-
[20]
H. Seong, J.-K. Lee, H. Myeong, Y . Shin, H.-M. Cho, D. H. Kim, P. Desai, and M. Surana. Post-training and test-time scaling of generative agent behavior models for interactive au- tonomous driving.arXiv preprint arXiv:2512.13262, 2025
- [21]
-
[22]
Konstantinidis, M
F. Konstantinidis, M. Sackmann, U. Hofmann, and C. Stiller. Toward efficient and robust behavior models for multi-agent driving simulation. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[23]
Ahmadi, H
E. Ahmadi, H. Schofield, B. Khamidehi, F. Arasteh, J. Shan, L. Mou, K. Rezaee, and D. Bai. RLFTSim: Realistic and controllable multi-agent traffic simulation via reinforcement learning fine-tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[24]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J´egou, P. Labatut, and P. Bojanowski. DINOv3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
W. Wu, X. Feng, Z. Gao, and Y . Kan. SMART: Scalable multi-agent real-time motion gen- eration via next-token prediction. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[26]
G. Hess, C. Lindstr ¨om, M. Fatemi, C. Petersson, and L. Svensson. SplatAD: Real-time lidar and camera rendering with 3d gaussian splatting for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[27]
H. Gao, S. Chen, B. Jiang, B. Liao, Y . Shi, X. Guo, Y . Pu, H. Yin, X. Li, X. Zhang, Y . Zhang, W. Liu, Q. Zhang, and X. Wang. RAD: Training an end-to-end driving policy via large-scale 3DGS-based reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
- [28]
-
[29]
Kaufmann, L
E. Kaufmann, L. Bauersfeld, A. Loquercio, M. M ¨uller, V . Koltun, and D. Scaramuzza. Champion-level drone racing using deep reinforcement learning.Nature, 620(7976):982–987, 2023. 10
2023
- [30]
-
[31]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the International Conference on Machine Learning (ICML), 2021
2021
-
[32]
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. V . Le, Y .-H. Sung, Z. Li, and T. Duerig. Scaling up visual and vision-language representation learning with noisy text su- pervision. InProceedings of the International Conference on Machine Learning (ICML), 2021
2021
-
[33]
J. Li, D. Li, S. Savarese, and S. Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InProceedings of the International Conference on Machine Learning (ICML), 2023
2023
-
[34]
A. A. Rusu, S. G. Colmenarejo, C ¸ . G ¨ulc ¸ehre, G. Desjardins, J. Kirkpatrick, R. Pascanu, V . Mnih, K. Kavukcuoglu, and R. Hadsell. Policy distillation. InProceedings of the Inter- national Conference on Learning Representations (ICLR), 2016
2016
-
[35]
Parisotto, J
E. Parisotto, J. Ba, and R. Salakhutdinov. Actor-mimic: Deep multitask and transfer reinforce- ment learning. InProceedings of the International Conference on Learning Representations (ICLR), 2016
2016
-
[36]
Y . W. Teh, V . Bapst, W. M. Czarnecki, J. Quan, J. Kirkpatrick, R. Hadsell, N. Heess, and R. Pascanu. Distral: Robust multitask reinforcement learning. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2017
2017
-
[37]
Kickstarting Deep Reinforcement Learning
S. Schmitt, J. J. Hudson, A. ˇZ´ıdek, S. Osindero, C. Doersch, W. M. Czarnecki, J. Z. Leibo, H. K¨uttler, A. Zisserman, K. Simonyan, and S. M. A. Eslami. Kickstarting deep reinforcement learning.arXiv preprint arXiv:1803.03835, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning quadrupedal locomo- tion over challenging terrain.Science Robotics, 5(47):eabc5986, 2020
2020
-
[39]
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning robust per- ceptive locomotion for quadrupedal robots in the wild.Science Robotics, 7(62):eabk2822, 2022
2022
-
[40]
Kumar, Z
A. Kumar, Z. Fu, D. Pathak, and J. Malik. RMA: Rapid motor adaptation for legged robots. In Robotics: Science and Systems (RSS), 2021
2021
-
[41]
Loquercio, E
A. Loquercio, E. Kaufmann, R. Ranftl, M. M ¨uller, V . Koltun, and D. Scaramuzza. Learning high-speed flight in the wild.Science Robotics, 6(59):eabg5810, 2021
2021
-
[42]
T. Chen, J. Xu, and P. Agrawal. A system for general in-hand object re-orientation. InPro- ceedings of the Conference on Robot Learning (CoRL), 2021
2021
- [43]
-
[44]
Hinton, O
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. InNeurIPS Deep Learning and Representation Learning Workshop, 2015
2015
-
[45]
Philion, A
J. Philion, A. Kar, and S. Fidler. Learning to evaluate perception models using planner-centric metrics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2020. 11
2020
-
[46]
Li and X
W.-X. Li and X. Yang. Transcendental idealism of planner: Evaluating perception from plan- ning perspective for autonomous driving. InProceedings of the International Conference on Machine Learning (ICML), 2023
2023
-
[47]
Tung and G
F. Tung and G. Mori. Similarity-preserving knowledge distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 1365–1374, 2019
2019
-
[48]
Zaheer, S
M. Zaheer, S. Kottur, S. Ravanbakhsh, B. Poczos, R. R. Salakhutdinov, and A. J. Smola. Deep sets. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[49]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[51]
Gavish and D
M. Gavish and D. L. Donoho. The optimal hard threshold for singular values is4/ √ 3.IEEE Transactions on Information Theory, 60(8):5040–5053, 2014
2014
-
[52]
O. Roy and M. Vetterli. The effective rank: A measure of effective dimensionality. In2007 15th European Signal Processing Conference, pages 606–610. IEEE, 2007. 12 Supplementary Contents A Self-Play Policy Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 B Closed-Loop HD...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.