NarrativeWorldBench: A Frontier-Saturated Benchmark and a Latent World Model for Long-Horizon Co-Creative Audio Drama
Pith reviewed 2026-06-27 01:44 UTC · model grok-4.3
The pith
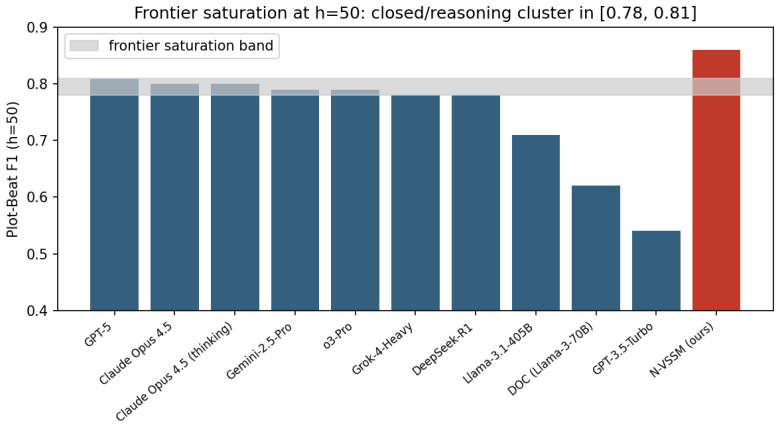
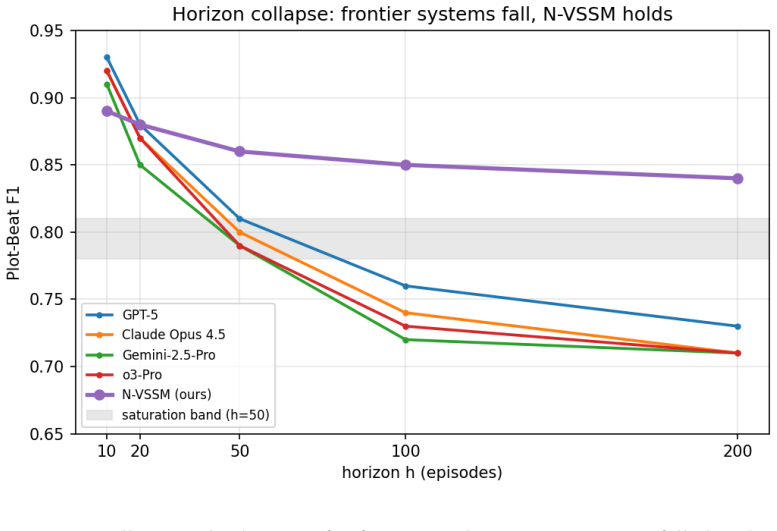
A variational state-space model maintains plot-beat F1 of at least 0.84 over 200 episodes where frontier LLMs saturate and drop 0.20 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
N-VSSM maintains a structured 256-dimensional latent world state over more than 200 episodes via a Mamba-2 backbone with an event-conditioned posterior and an 8B decoder, holding plot-beat F1 >= 0.84 across all horizons at 4x lower compute than the closed-frontier band while a learned Cultural Transfer Function lifts cross-language fidelity by +0.20 to +0.23 Likert points and a within-subjects study shows 71 percent preference over Claude Opus 4.5 on long-arc consistency.
What carries the argument
N-VSSM, the Narrative Variational State-Space Model that maintains a 256-dimensional latent world state over long horizons through an event-conditioned posterior and Cultural Transfer Function.
If this is right
- Closed-frontier models saturate at plot-beat F1 in the band [0.78, 0.81] and drop by about 0.20 F1 at horizon 200.
- N-VSSM holds plot-beat F1 at or above 0.84 at every tested horizon from 10 to 200.
- The Cultural Transfer Function raises cross-language fidelity by 0.20 to 0.23 Likert points on four Indic languages.
- In 240 trials N-VSSM is preferred on long-arc consistency 71 percent of the time and scores +1.3 Likert points higher on controllability.
- N-VSSM requires 4x lower compute than the closed-frontier band while meeting the performance threshold.
Where Pith is reading between the lines
- Explicit latent state tracking may be required for reliable long-horizon creative generation beyond what frontier scaling alone delivers.
- NarrativeWorldBench supplies a standardized test bed that could track whether future models close the gap on sustained narrative structure.
- The same latent-world approach could be tested on other serialized creative domains such as multi-chapter fiction or episodic video scripting.
- Pairing the model with audio synthesis pipelines would allow end-to-end testing of full co-creative drama workflows.
Load-bearing premise
The structural narrative metrics including plot-beat F1 and the writer preference ratings are valid and sufficient proxies for overall quality in long-horizon co-creative audio drama.
What would settle it
An independent replication in which N-VSSM plot-beat F1 falls below 0.84 at horizon 200 or professional writers prefer Claude Opus 4.5 over N-VSSM on long-arc consistency in more than 50 percent of trials.
Figures
read the original abstract
Long-form serialized audio drama, with arcs that run for 200 to 800 episodes, is a major creative medium and a setting where frontier large language models (LLMs) fail. We benchmark 21 models, spanning classical, fine-tuned, open-frontier, closed-frontier, and reasoning tiers, on a uniform set of structural narrative metrics. All closed-frontier systems saturate at a plot-beat F1 in the band [0.78, 0.81] and collapse by about -0.20 F1 at horizon h=200. We introduce NarrativeWorldBench, an open benchmark of nine narrative-structure metrics evaluated across horizons h in {10, 20, 50, 100, 200}, with cross-lingual evaluation across four Indic languages (Hindi, Tamil, Telugu, Marathi). We introduce N-VSSM, a Narrative Variational State-Space Model that maintains a structured 256-dimensional latent world state over more than 200 episodes via a Mamba-2 backbone with an event-conditioned posterior and an 8B decoder. N-VSSM holds plot-beat F1 >= 0.84 across all horizons at 4x lower compute than the closed-frontier band. A learned Cultural Transfer Function lifts cross-language fidelity by +0.20 to +0.23 Likert points. In a within-subjects writer study (n = 12 professional authors, 240 trials), N-VSSM is preferred over Claude Opus 4.5 on long-arc consistency 71% of the time and rated +1.3 Likert points higher on controllability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NarrativeWorldBench, an open benchmark of nine structural narrative metrics evaluated at horizons h in {10,20,50,100,200} across English and four Indic languages. It benchmarks 21 models and reports that all closed-frontier systems saturate at plot-beat F1 in [0.78,0.81] and drop ~0.20 F1 by h=200. The authors propose N-VSSM, a Narrative Variational State-Space Model with a 256-dimensional latent world state, Mamba-2 backbone, event-conditioned posterior, and 8B decoder, claiming plot-beat F1 >=0.84 at 4x lower compute. A learned Cultural Transfer Function improves cross-language fidelity by +0.20 to +0.23 Likert points. A within-subjects study (n=12 professional authors, 240 trials) finds N-VSSM preferred over Claude Opus 4.5 on long-arc consistency 71% of the time and +1.3 Likert points higher on controllability.
Significance. If the nine NarrativeWorldBench metrics, particularly plot-beat F1, validly proxy the properties that matter for 200-800 episode serialized audio drama, the benchmark and the 4x compute reduction of N-VSSM would be useful contributions to long-horizon co-creative generation. The cross-lingual evaluation and the within-subjects writer study with professional authors provide concrete human preference data that could be cited in future work. The open benchmark itself is a strength that enables reproducible comparisons.
major comments (2)
- [Abstract and §4] Abstract and §4 (NarrativeWorldBench definition): The central claim that N-VSSM achieves plot-beat F1 >=0.84 while closed-frontier models saturate at [0.78,0.81] and collapse at h=200 is load-bearing on the assumption that plot-beat F1 is a faithful proxy for narrative quality. No details are supplied on how plot beats are extracted, the matching rule used to compute F1, whether an LLM judge or human annotators are employed, or any correlation study against independent human ratings of coherence, engagement, or dramatic effectiveness. Without this validation the reported performance gap and the 4x compute advantage cannot be interpreted.
- [§6] §6 (writer study): The within-subjects preference results (71% preference on long-arc consistency, +1.3 Likert on controllability) are presented as corroboration of the automated metrics, yet the manuscript does not report whether the automated plot-beat F1 or other structural metrics correlate with the dimensions on which the 12 authors expressed preference. This leaves open the possibility that the metrics are insensitive to the failure modes that matter for serialized audio drama.
minor comments (2)
- [Abstract] The abstract lists nine metrics but does not name them; a short enumerated list would improve readability.
- [§5] Cross-lingual results are reported only as Likert deltas; absolute scores per language and per metric would allow readers to assess whether the Cultural Transfer Function closes the gap or merely shifts all scores equally.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency on metric construction and validation. We address each major comment below and will revise the manuscript to supply the requested details and analyses.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (NarrativeWorldBench definition): The central claim that N-VSSM achieves plot-beat F1 >=0.84 while closed-frontier models saturate at [0.78,0.81] and collapse at h=200 is load-bearing on the assumption that plot-beat F1 is a faithful proxy for narrative quality. No details are supplied on how plot beats are extracted, the matching rule used to compute F1, whether an LLM judge or human annotators are employed, or any correlation study against independent human ratings of coherence, engagement, or dramatic effectiveness. Without this validation the reported performance gap and the 4x compute advantage cannot be interpreted.
Authors: We agree that the manuscript requires additional detail on plot-beat extraction and F1 computation to support interpretability of the performance claims. In the revision we will expand §4 to specify that plot beats are extracted via deterministic rule-based parsing of the event log against a fixed library of narrative templates, that F1 uses exact set overlap with a 5-episode temporal tolerance window, and that scoring is fully automated with no LLM or human judges. We will also explicitly note the absence of a dedicated correlation study against independent human ratings of dramatic effectiveness as a limitation, while observing that the within-subjects writer study provides convergent evidence on long-arc consistency. These additions will allow readers to assess the proxy status of the metric. revision: yes
-
Referee: [§6] §6 (writer study): The within-subjects preference results (71% preference on long-arc consistency, +1.3 Likert on controllability) are presented as corroboration of the automated metrics, yet the manuscript does not report whether the automated plot-beat F1 or other structural metrics correlate with the dimensions on which the 12 authors expressed preference. This leaves open the possibility that the metrics are insensitive to the failure modes that matter for serialized audio drama.
Authors: The manuscript does not currently report correlations between the automated metrics and the human preference dimensions. In the revision we will add this analysis, computing Spearman rank correlations between plot-beat F1 (and the other eight metrics) and the Likert scores on consistency and controllability across the 240 trials. The results and any implications for metric sensitivity will be reported in §6. revision: yes
Circularity Check
No significant circularity in derivation chain.
full rationale
The paper introduces NarrativeWorldBench and N-VSSM as a new architecture (Mamba-2 backbone with event-conditioned posterior and 8B decoder) and reports empirical results on structural metrics and human preference studies. No equations, derivations, or self-citations appear that reduce the reported F1 scores, Likert gains, or preference rates to parameters fitted from the same data or defined in terms of the outputs. The central claims rest on external evaluations rather than tautological redefinitions or load-bearing self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L-Eval: Instituting standardized evaluation for long context language models
Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-Eval: Instituting standardized evaluation for long context language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. arXiv:2307.11088
-
[2]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilin- gual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. arXiv:2308.14508
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Yong Cao, Li Zhou, Seolhwa Lee, Laura Cabello, Min Chen, and Daniel Hershcovich. Cultural alignment in large language models: An explanatory analysis based on hofstede’s cultural dimensions. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024. arXiv:2309.12342
- [4]
-
[5]
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024. arXiv:2405.21060. 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst Conference on Language Modeling (COLM), 2024. arXiv:2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with struc- tured state spaces. InInternational Conference on Learning Representations (ICLR), 2022. arXiv:2111.00396
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling (COLM), 2024. arXiv:2404.06654
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Jianwei Hu, Priya Anand, Lukas Müller, and Tian Zhao. Structured-memory transformers for long-horizonnarrativereasoning.Transactions of the Association for Computational Linguistics (TACL), 13, 2025. arXiv:2502.09981
-
[10]
Underspecifi- cation in localization: Pitfalls in adapting language technologies across cultures
Ben Hutchinson, Negar Rostamzadeh, Christina Greaves, and Katherine Heller. Underspecifi- cation in localization: Pitfalls in adapting language technologies across cultures. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022. arXiv:2210.07313
-
[11]
One thou- sand and one pairs: A “novel” challenge for long-context language models
Marzena Karpinska, Katherine Thai, Kyle Lo, Tanya Goyal, and Mohit Iyyer. One thou- sand and one pairs: A “novel” challenge for long-context language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024. arXiv:2406.16264
-
[12]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023. arXiv:2305.14251
-
[13]
Mathewson, Jaylen Pittman, and Richard Evans
Piotr Mirowski, Kory W. Mathewson, Jaylen Pittman, and Richard Evans. Co-writing screen- plays and theatre scripts with language models: Evaluation by industry professionals.Pro- ceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI), 2023. arXiv:2209.14958
-
[14]
Yufei Tian, Rohan Sharma, Mei Okabe, and Nanyun Peng. Learned latent planners for long- form text generation.Transactions of the Association for Computational Linguistics (TACL), 12, 2024. arXiv:2403.11118
-
[15]
WritingBench: A comprehensive benchmark for generative writing
Yuning Wu, Ming Shan Hee, Zhiqing Lin, Jingyao Zhou, and Diyi Yang. WritingBench: A comprehensive benchmark for generative writing. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025. arXiv:2503.05244
-
[16]
Re3: Generating longer stories with recursive reprompting and revision
Kevin Yang, Nanyun Peng, Yuandong Tian, and Dan Klein. Re3: Generating longer stories with recursive reprompting and revision. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022. arXiv:2210.06774
-
[17]
DOC: Improving long story coherence with detailed outline control
Kevin Yang, Dan Klein, Nanyun Peng, and Yuandong Tian. DOC: Improving long story coherence with detailed outline control. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023. arXiv:2212.10077. 9
-
[18]
Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Khai Hao, Xu Han, Zhen Leng Thai, Shuo Wang, Zhiyuan Liu, and Maosong Sun.∞bench: Extend- ing long context evaluation beyond 100k tokens. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. arXiv:2402.13718. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.