A Risk Decomposition Framework for Pre-Hoc Fine-Tuning Prediction
Pith reviewed 2026-06-27 01:46 UTC · model grok-4.3
The pith
Pre-hoc LLM fine-tuning performance prediction faces a lower bound on how fast its uncertainty can decrease.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
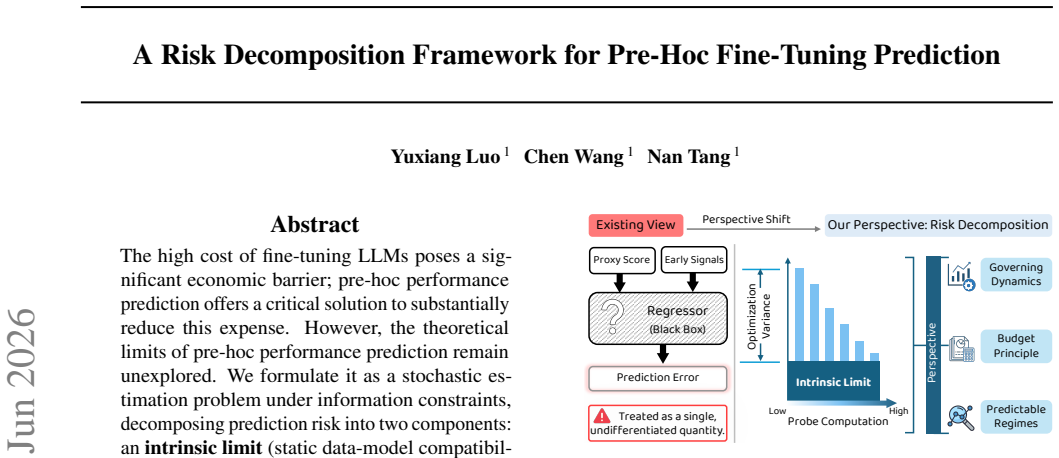
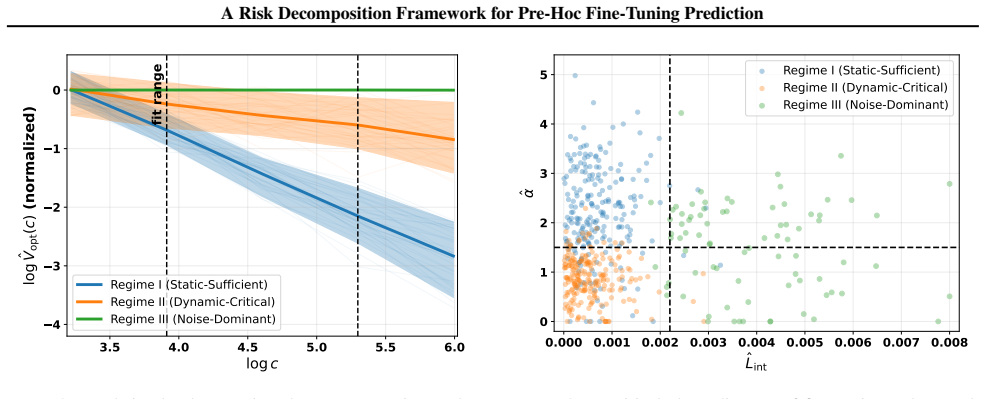
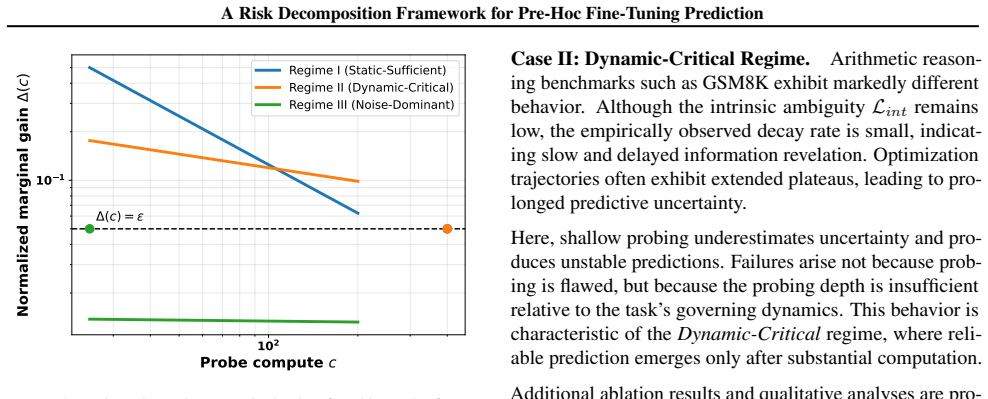
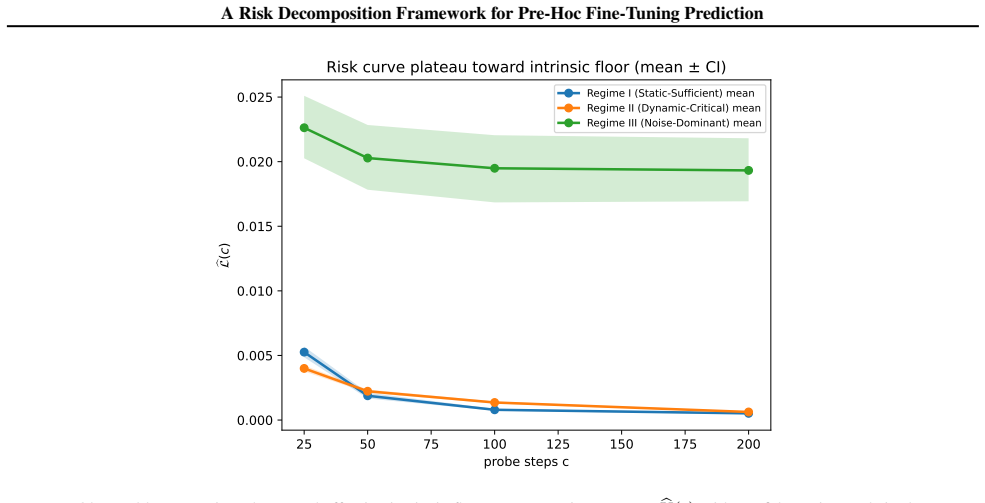
We formulate pre-hoc performance prediction as a stochastic estimation problem under information constraints, decomposing prediction risk into an intrinsic limit set by static data-model compatibility and a reducible optimization variance. We prove that optimization variance admits a necessary lower bound on its decay rate, implying fundamental constraints on how quickly uncertainty dissipates regardless of the predictor used. From these dynamics we derive a budget-optimal probing principle and a predictability phase diagram that organizes tasks into Static-Sufficient, Dynamic-Critical, and Noise-Dominant regimes.
What carries the argument
Risk decomposition into intrinsic limit and optimization variance, with the proven lower bound on the variance decay rate.
If this is right
- Uncertainty dissipates at a bounded rate independent of the choice of predictor.
- Tasks fall into one of three predictability regimes according to the phase diagram.
- A budget-optimal probing strategy follows directly from the derived dynamics.
Where Pith is reading between the lines
- The same decomposition could be applied to decide whether pre-hoc checks are economical for other expensive training procedures.
- The phase diagram offers a way to pre-screen tasks before committing compute to any predictor.
- Real-world validation on the reported benchmarks indicates the three regimes are observable rather than purely theoretical.
Load-bearing premise
The pre-hoc performance prediction problem can be accurately formulated as a stochastic estimation problem under information constraints.
What would settle it
An experiment in which optimization variance for a concrete fine-tuning predictor decays faster than the derived lower bound on any benchmark would falsify the central claim.
Figures
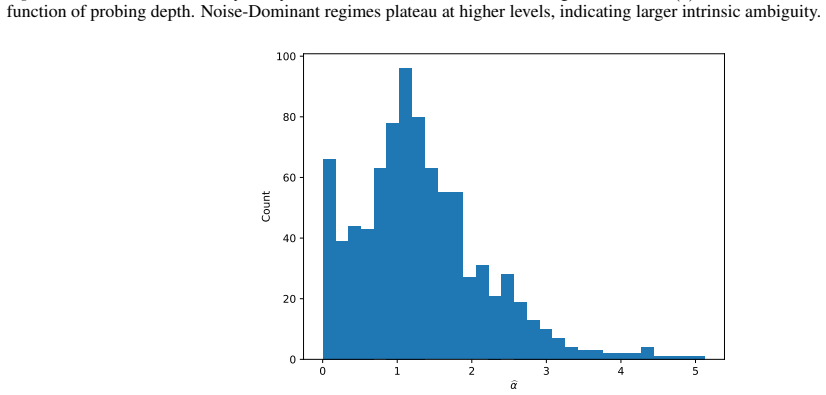
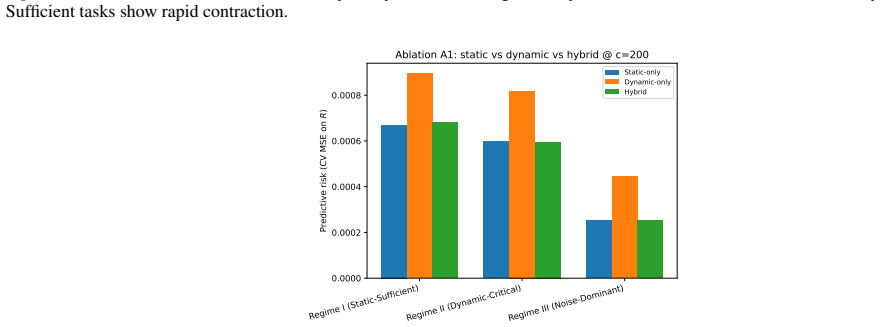
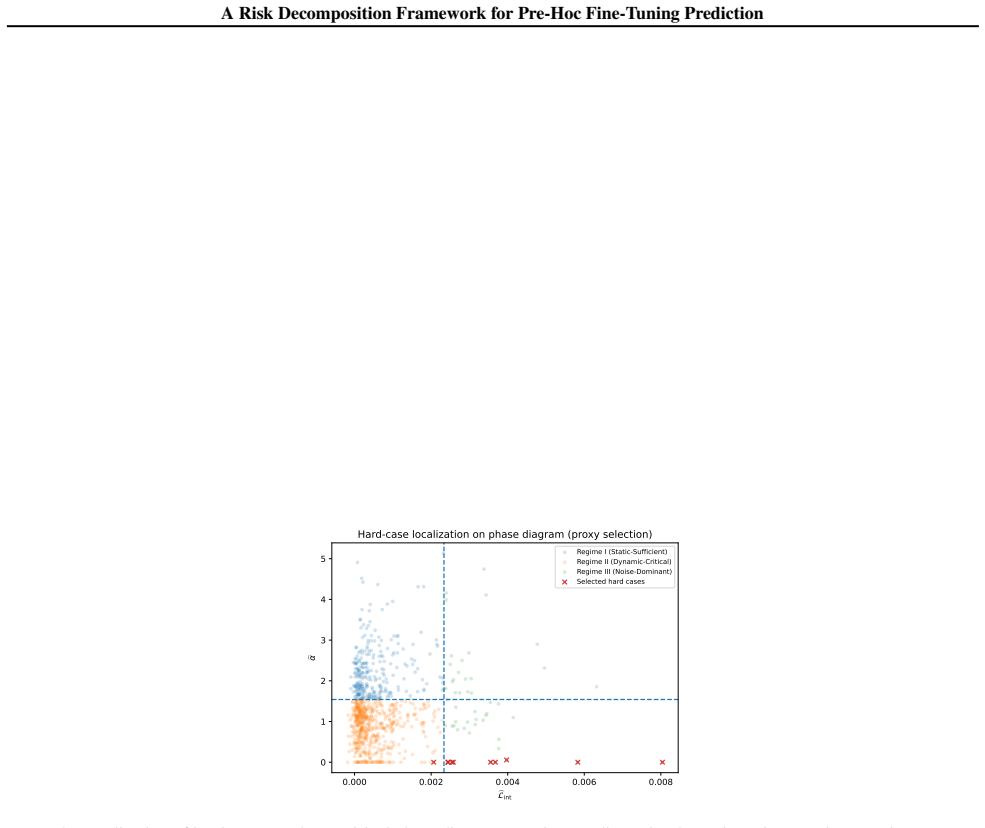
read the original abstract
The high cost of fine-tuning LLMs poses a significant economic barrier; pre-hoc performance prediction offers a critical solution to substantially reduce this expense. However, the theoretical limits of pre-hoc performance prediction remain unexplored. We formulate it as a stochastic estimation problem under information constraints, decomposing prediction risk into two components: an intrinsic limit (static data-model compatibility) and a reducible optimization variance. We prove that optimization variance admits a necessary lower bound on its decay rate, implying fundamental constraints on how quickly uncertainty dissipates, regardless of the predictor used. Based on these dynamics, we derive a budget-optimal probing principle and introduce a predictability phase diagram that organizes tasks into three distinct regimes: Static-Sufficient, Dynamic-Critical, and Noise-Dominant. Extensive experiments on synthetic and real-world benchmarks validate these theoretical regimes and demonstrate the efficiency of our probing strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a risk decomposition framework for pre-hoc fine-tuning prediction of large language models. It formulates the problem as a stochastic estimation task under information constraints, decomposes the risk into an intrinsic limit and reducible optimization variance, proves a lower bound on the decay rate of the optimization variance, derives a budget-optimal probing principle, and introduces a predictability phase diagram with three regimes: Static-Sufficient, Dynamic-Critical, and Noise-Dominant. The theoretical findings are supported by experiments on synthetic and real-world benchmarks.
Significance. If the central claims hold, this work would be significant for providing theoretical foundations for pre-hoc performance prediction in LLM fine-tuning, potentially leading to more efficient use of computational resources. The proof of a necessary lower bound on variance decay and the phase diagram could influence how practitioners approach probing strategies. The experimental validation adds practical value, though its strength depends on the fidelity of the model to real fine-tuning dynamics.
major comments (3)
- [Abstract] Abstract: The proof that optimization variance admits a necessary lower bound on its decay rate is load-bearing for the central claim of fundamental constraints independent of the predictor. However, this bound is derived from the stochastic estimation formulation under information constraints; it is unclear if this bound is a genuine necessary limit or if it is induced by the specific modeling assumptions about information constraints.
- [Abstract] Abstract: The predictability phase diagram with regimes Static-Sufficient, Dynamic-Critical, and Noise-Dominant is derived from the decay-rate dynamics. The manuscript should explicitly show how these regimes are defined and distinguished, including any thresholds or conditions based on the lower bound, to allow assessment of whether they organize tasks in a non-trivial way.
- [Abstract] Abstract: The experiments are claimed to validate the theoretical regimes and the efficiency of the probing strategy. Without details on the specific benchmarks, how the regimes were identified, or error analysis, it is difficult to evaluate if the results support the claims or if confounding factors in the data affect the validation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below with clarifications on the theoretical claims and indicate where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The proof that optimization variance admits a necessary lower bound on its decay rate is load-bearing for the central claim of fundamental constraints independent of the predictor. However, this bound is derived from the stochastic estimation formulation under information constraints; it is unclear if this bound is a genuine necessary limit or if it is induced by the specific modeling assumptions about information constraints.
Authors: The stochastic estimation formulation under information constraints directly models the pre-hoc setting, where predictors have restricted access to fine-tuning dynamics. The lower bound is a necessary consequence of these constraints and is independent of the predictor; it is not an artifact but follows from the information-theoretic limits in the problem formulation. We will revise the abstract to explicitly note that the bound holds under this modeling framework. revision: partial
-
Referee: [Abstract] Abstract: The predictability phase diagram with regimes Static-Sufficient, Dynamic-Critical, and Noise-Dominant is derived from the decay-rate dynamics. The manuscript should explicitly show how these regimes are defined and distinguished, including any thresholds or conditions based on the lower bound, to allow assessment of whether they organize tasks in a non-trivial way.
Authors: The regimes are distinguished by the relationship between the optimization variance decay rate and the intrinsic limit, using the proven lower bound: Static-Sufficient when decay exceeds the bound sufficiently to reach the limit, Dynamic-Critical when the bound governs the transition, and Noise-Dominant when decay is constrained below effective reduction. We will add explicit definitions, thresholds, and conditions based on the lower bound to the phase diagram section. revision: yes
-
Referee: [Abstract] Abstract: The experiments are claimed to validate the theoretical regimes and the efficiency of the probing strategy. Without details on the specific benchmarks, how the regimes were identified, or error analysis, it is difficult to evaluate if the results support the claims or if confounding factors in the data affect the validation.
Authors: The full manuscript details the synthetic benchmarks (controlled variance parameters) and real-world NLP tasks, regime identification via empirical decay plots against the theoretical bound, and error analysis with repeated runs and confidence intervals. The abstract is concise, but we will add a brief validation summary. The experiments isolate the modeled effects and support the claims. revision: partial
Circularity Check
No significant circularity; derivation is a standard mathematical consequence of the stochastic model
full rationale
The paper's central result is a mathematical proof of a lower bound on optimization variance decay, obtained after explicitly formulating the problem as stochastic estimation under information constraints and decomposing risk into intrinsic limit plus reducible variance. This is a first-principles derivation internal to the chosen model rather than a tautology, fitted parameter renamed as prediction, or load-bearing self-citation. No equations or steps in the provided text reduce the bound to its inputs by construction; the bound follows from the information constraints assumed in the formulation. The modeling choice itself is an assumption whose validity is separate from circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-hoc fine-tuning performance prediction can be formulated as a stochastic estimation problem under information constraints.
invented entities (1)
-
Predictability phase diagram with regimes Static-Sufficient, Dynamic-Critical, Noise-Dominant
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Xiaotian Lin and Yanlin Qi and Yizhang Zhu and Themis Palpanas and Chengliang Chai and Nan Tang and Yuyu Luo , title =. Proc. 2025 , url =
2025
-
[5]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[6]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[7]
Suppressed for Anonymity , author=
-
[8]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[9]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[10]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[11]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[12]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[13]
2025 , eprint=
COSMOS: Predictable and Cost-Effective Adaptation of LLMs , author=. 2025 , eprint=
2025
-
[14]
2024 , eprint=
Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models , author=. 2024 , eprint=
2024
-
[15]
2025 , eprint=
LENSLLM: Unveiling Fine-Tuning Dynamics for LLM Selection , author=. 2025 , eprint=
2025
-
[16]
2017 , eprint=
A Unified Approach to Interpreting Model Predictions , author=. 2017 , eprint=
2017
-
[17]
2020 , eprint=
Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples , author=. 2020 , eprint=
2020
-
[18]
2021 , eprint=
Dataset2Vec: Learning Dataset Meta-Features , author=. 2021 , eprint=
2021
-
[19]
2022 , eprint=
Model Zoos: A Dataset of Diverse Populations of Neural Network Models , author=. 2022 , eprint=
2022
-
[20]
Proceedings of the 24th International Conference on Artificial Intelligence , pages =
Domhan, Tobias and Springenberg, Jost Tobias and Hutter, Frank , title =. Proceedings of the 24th International Conference on Artificial Intelligence , pages =. 2015 , isbn =
2015
-
[21]
2020 , eprint=
Scaling Laws for Neural Language Models , author=. 2020 , eprint=
2020
-
[22]
2024 , eprint=
ProxyLM: Predicting Language Model Performance on Multilingual Tasks via Proxy Models , author=. 2024 , eprint=
2024
-
[23]
2020 , eprint=
Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics , author=. 2020 , eprint=
2020
-
[24]
2019 , eprint=
Data Shapley: Equitable Valuation of Data for Machine Learning , author=. 2019 , eprint=
2019
-
[25]
2025 , eprint=
Refine-n-Judge: Curating High-Quality Preference Chains for LLM-Fine-Tuning , author=. 2025 , eprint=
2025
-
[26]
2018 , eprint=
The Dataset Nutrition Label: A Framework To Drive Higher Data Quality Standards , author=. 2018 , eprint=
2018
-
[27]
2021 , eprint=
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers , author=. 2021 , eprint=
2021
-
[28]
2023 , eprint=
GENTLE: A Genre-Diverse Multilayer Challenge Set for English NLP and Linguistic Evaluation , author=. 2023 , eprint=
2023
-
[29]
2021 , eprint=
On the Importance of Gradients for Detecting Distributional Shifts in the Wild , author=. 2021 , eprint=
2021
-
[30]
2018 , eprint=
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks , author=. 2018 , eprint=
2018
-
[31]
Louis , year=
Shuofeng Zhang and Isaac Reid and Guillermo Valle-Perez and Ard A. Louis , year=
-
[32]
2024 , url=
Gradient norm as a powerful proxy to out-of-distribution error estimation , author=. 2024 , url=
2024
-
[33]
2023 , eprint=
Gradient Norm Aware Minimization Seeks First-Order Flatness and Improves Generalization , author=. 2023 , eprint=
2023
-
[34]
2021 , eprint=
Self-Validation: Early Stopping for Single-Instance Deep Generative Priors , author=. 2021 , eprint=
2021
-
[35]
2025 , eprint=
Autoencoder-Based Framework to Capture Vocabulary Quality in NLP , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Massive Supervised Fine-tuning Experiments Reveal How Data, Layer, and Training Factors Shape LLM Alignment Quality , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
Assessing the Impact of the Quality of Textual Data on Feature Representation and Machine Learning Models , author=. 2025 , eprint=
2025
-
[38]
Model Explainability using SHAP Values for LightGBM Predictions , year=
Bugaj, Michal and Wrobel, Krzysztof and Iwaniec, Joanna , booktitle=. Model Explainability using SHAP Values for LightGBM Predictions , year=
-
[39]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
Ke, Guolin and Meng, Qi and Finley, Thomas and Wang, Taifeng and Chen, Wei and Ma, Weidong and Ye, Qiwei and Liu, Tie-Yan , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[40]
Wang, Ying and Wang, Pengxin and Tansey, Kevin and Liu, Junming and Delaney, Bethany and Quan, Wenting , title =. 2025 , issue_date =. doi:10.1016/j.compag.2024.109758 , journal =
-
[41]
Garcia and Carlos Soares and Joaquin Vanschoren and André C.P.L.F
Adriano Rivolli and Luís P.F. Garcia and Carlos Soares and Joaquin Vanschoren and André C.P.L.F. Meta-features for meta-learning , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.knosys.2021.108101 , url =
-
[42]
2022 , eprint=
Predicting Fine-Tuning Performance with Probing , author=. 2022 , eprint=
2022
-
[43]
2024 , eprint=
Predictable Emergent Abilities of LLMs: Proxy Tasks Are All You Need , author=. 2024 , eprint=
2024
-
[44]
2020 , eprint=
The Break-Even Point on Optimization Trajectories of Deep Neural Networks , author=. 2020 , eprint=
2020
-
[45]
2019 , eprint=
Visualizing and Understanding the Effectiveness of BERT , author=. 2019 , eprint=
2019
-
[46]
2023 , eprint=
Efficient Bayesian Learning Curve Extrapolation using Prior-Data Fitted Networks , author=. 2023 , eprint=
2023
-
[47]
International Conference on Learning Representations (ICLR) , year =
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations (ICLR) , year =
-
[48]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =. doi:10.48550/arXiv.2412.15115 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115
-
[49]
2025 , url =
Qwen2.5-7B-Instruct , author =. 2025 , url =
2025
-
[50]
2025 , eprint=
A Multi-Power Law for Loss Curve Prediction Across Learning Rate Schedules , author=. 2025 , eprint=
2025
-
[51]
2020 , eprint=
Don't Stop Pretraining: Adapt Language Models to Domains and Tasks , author=. 2020 , eprint=
2020
-
[52]
Mu, Yida and Jin, Mali and Song, Xingyi and Aletras, Nikolaos. Enhancing Data Quality through Simple De-duplication: Navigating Responsible Computational Social Science Research. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.694
-
[53]
2025 , eprint=
Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric , author=. 2025 , eprint=
2025
-
[54]
2023 , eprint=
The Vendi Score: A Diversity Evaluation Metric for Machine Learning , author=. 2023 , eprint=
2023
-
[55]
2018 , eprint=
Visualizing the Loss Landscape of Neural Nets , author=. 2018 , eprint=
2018
-
[56]
2020 , eprint=
Adversarial Weight Perturbation Helps Robust Generalization , author=. 2020 , eprint=
2020
-
[57]
Mathematics , VOLUME =
Liang, Hailun and Zheng, Haowen and Wang, Hao and He, Liu and Lin, Haoyi and Liang, Yanyan , TITLE =. Mathematics , VOLUME =. 2025 , NUMBER =
2025
-
[58]
Technometrics , volume =
Ridge Regression: Biased Estimation for Nonorthogonal Problems , author =. Technometrics , volume =. 1970 , publisher =
1970
-
[59]
Advances in Neural Information Processing Systems , volume =
Support Vector Regression Machines , author =. Advances in Neural Information Processing Systems , volume =. 1997 , publisher =
1997
-
[60]
Statistics and Computing , volume =
A Tutorial on Support Vector Regression , author =. Statistics and Computing , volume =. 2004 , doi =
2004
-
[61]
Machine Learning , volume =
Random Forests , author =. Machine Learning , volume =. 2001 , doi =
2001
-
[62]
Nature , volume =
Learning Representations by Back-Propagating Errors , author =. Nature , volume =. 1986 , doi =
1986
-
[63]
Neural Networks , volume =
Multilayer Feedforward Networks Are Universal Approximators , author =. Neural Networks , volume =. 1989 , doi =
1989
-
[64]
Journal of Machine Learning Research , volume =
Scikit-learn: Machine Learning in Python , author =. Journal of Machine Learning Research , volume =. 2011 , url =
2011
-
[65]
arXiv preprint arXiv:1706.10239 , year=
Towards Understanding Generalization of Deep Learning: Perspective of Loss Landscapes , author=. arXiv preprint arXiv:1706.10239 , year=
-
[66]
arXiv preprint arXiv:2412.13573 , year=
Seeking Consistent Flat Minima for Better Domain Generalization via Refining Loss Landscapes , author=. arXiv preprint arXiv:2412.13573 , year=
-
[67]
2019 , eprint=
Characterizing classification datasets: a study of meta-features for meta-learning , author=. 2019 , eprint=
2019
-
[68]
2024 , eprint=
Machine Translation Meta Evaluation through Translation Accuracy Challenge Sets , author=. 2024 , eprint=
2024
-
[69]
2023 , eprint=
Advances and Challenges in Meta-Learning: A Technical Review , author=. 2023 , eprint=
2023
-
[70]
2018 , eprint=
Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization , author=. 2018 , eprint=
2018
-
[71]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[72]
2018 , eprint=
A Survey of Machine Learning for Big Code and Naturalness , author=. 2018 , eprint=
2018
-
[73]
, title =
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2020 , issue_date =
2020
-
[74]
2022 , eprint=
Deduplicating Training Data Makes Language Models Better , author=. 2022 , eprint=
2022
-
[75]
2023 , eprint=
Extracting Training Data from Diffusion Models , author=. 2023 , eprint=
2023
-
[76]
2022 , eprint=
Training Compute-Optimal Large Language Models , author=. 2022 , eprint=
2022
-
[77]
2019 , eprint=
Deep Anomaly Detection with Outlier Exposure , author=. 2019 , eprint=
2019
-
[78]
2022 , eprint=
Confident Learning: Estimating Uncertainty in Dataset Labels , author=. 2022 , eprint=
2022
-
[79]
2021 , eprint=
Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus , author=. 2021 , eprint=
2021
-
[80]
2020 , eprint=
The Curious Case of Neural Text Degeneration , author=. 2020 , eprint=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.