AnchorKV: Safety-Aware KV Cache Compression via Soft Penalty with a Refusal Anchor
Pith reviewed 2026-06-27 01:20 UTC · model grok-4.3
The pith
AnchorKV adds a refusal anchor in key space to keep KV cache compression from weakening safety alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AnchorKV constructs an offline safety anchor by adapting a difference-of-means representation engineering approach to the layer-specific key projection space used in KV caching. Based on this anchor, a soft penalty token selection rule trades a small amount of utility for substantially improved safety alignment, while reducing to the original compressor when the penalty is zero.
What carries the argument
The refusal anchor, a vector in layer-specific key space obtained via difference-of-means between harmful and harmless prompts, that supplies the direction for the soft penalty applied to token retention scores.
If this is right
- Existing KV compressors such as SnapKV or DynamicKV can incorporate the anchor without retraining or architectural changes.
- Safety alignment is preserved under aggressive eviction ratios that would otherwise degrade it.
- The method imposes only a small utility cost on benign tasks while delivering the safety gain.
- Setting the penalty coefficient to zero recovers the original compressor exactly.
Where Pith is reading between the lines
- The same anchor construction could be tested on other representation directions beyond refusal, such as truthfulness or style.
- Layer-specific anchors suggest that per-layer tuning may be needed for optimal performance rather than a single global vector.
- The offline nature of the anchor allows pre-computation once per model, but leaves open whether an online version could adapt during a conversation.
Load-bearing premise
The layer-specific key-space difference-of-means vector reliably identifies directions associated with harmful prompts and works across models, layers, and attack types without further tuning.
What would settle it
Run the anchor construction on a held-out model and attack set; if the resulting penalty does not measurably increase retention of refusal-supporting tokens relative to the baseline compressor, the safety claim fails.
Figures
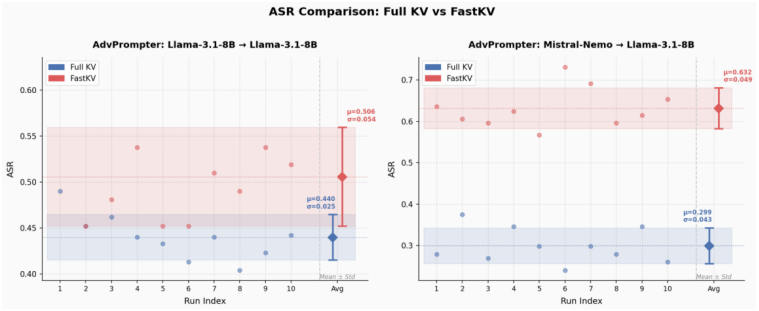
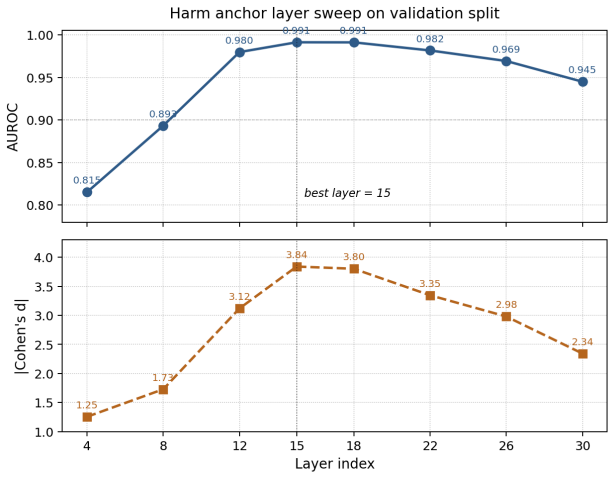
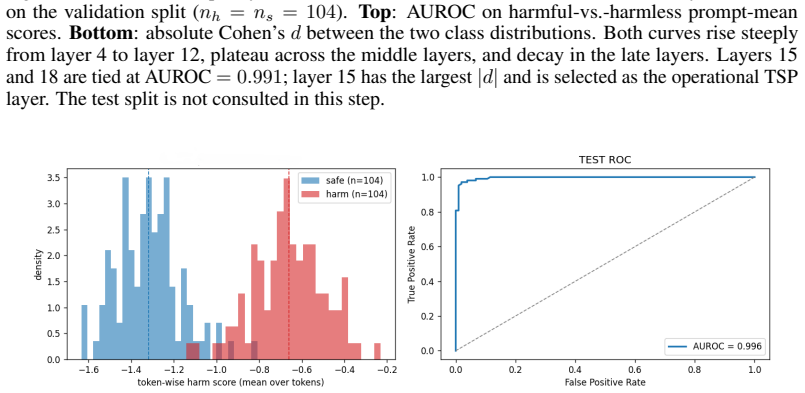
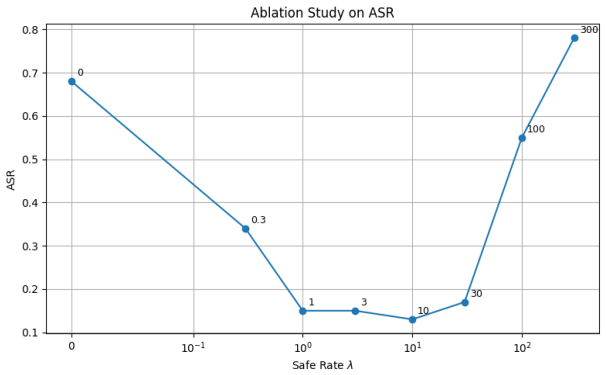
read the original abstract
Large language models (LLMs) outperform earlier architectures on generative inference and long-context tasks, but their large size introduces significant challenges in memory usage, energy cost, and on-device deployment. Since scaling pre-trained language models improves downstream capability \cite{zhao2023survey}, the key-value (KV) cache becomes a dominant inference bottleneck. Recent KV cache compression methods \cite{jo2025fastkv,li2024snapkv,zhou2024dynamickv} reduce this cost by retaining only a subset of attention-relevant tokens. However, while these approaches preserve accuracy on benign workloads, their compression policies either fail to defend against jailbreak attacks \cite{jiang2024robustkv} or degrade safety alignment under aggressive eviction. We propose AnchorKV, a drop-in modification to KV cache compression that biases token retention scores away from directions in key space associated with harmful prompts. AnchorKV constructs an offline safety anchor by adapting a difference-of-means representation engineering approach \cite{arditi2024refusal,zou2023representation} to the layer-specific key projection space used in KV caching. Based on this anchor, a soft penalty token selection rule trades a small amount of utility for substantially improved safety alignment, while reducing to the original compressor when the penalty is zero.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AnchorKV, a drop-in modification to KV cache compression methods. It constructs an offline safety anchor by adapting difference-of-means representation engineering to the layer-specific key projection space and applies a soft penalty during token selection to bias retention away from directions associated with harmful prompts. The method is claimed to trade a small amount of utility for substantially improved safety alignment while reducing to the baseline compressor when the penalty strength is zero.
Significance. If the layer-specific key-space anchor reliably identifies harmful directions and the soft penalty generalizes without model- or attack-specific tuning, the approach could address a practical gap in KV compression by preserving safety under jailbreak threats at modest utility cost. This would be a useful contribution for on-device and long-context LLM deployment, building on prior representation engineering and compression work.
major comments (2)
- [Abstract] Abstract: the central claim that the construction 'trades a small amount of utility for substantially improved safety alignment' is unsupported because the manuscript supplies no quantitative results, ablation studies, attack evaluations, or comparisons to baselines. Without these, it is impossible to assess whether the key-space difference-of-means vector produces a stable refusal direction or whether the penalty term achieves the intended trade-off.
- [Abstract] Abstract: the weakest assumption—that adapting difference-of-means to per-layer key projections yields a direction that generalizes across models, layers, and jailbreak distributions without post-hoc tuning—is stated but receives no derivation, stability check, or cross-model verification. This assumption is load-bearing for the safety claim; if the anchor fails to align with harmful content in key space, the penalty cannot deliver the claimed improvement.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract claims and assumptions. We agree that the current submission requires additional empirical support and analysis to substantiate the safety-utility trade-off and the generalization properties of the anchor. We outline revisions below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the construction 'trades a small amount of utility for substantially improved safety alignment' is unsupported because the manuscript supplies no quantitative results, ablation studies, attack evaluations, or comparisons to baselines. Without these, it is impossible to assess whether the key-space difference-of-means vector produces a stable refusal direction or whether the penalty term achieves the intended trade-off.
Authors: We agree the abstract claim is currently unsupported by data in the submission. The manuscript presents the method and its reduction to the baseline compressor but contains no experimental section with utility metrics, safety evaluations under jailbreaks, ablations, or baseline comparisons. In revision we will add these quantitative results (including attack success rates and benchmark scores) so the trade-off can be assessed directly; the abstract will be updated to reflect the measured outcomes rather than the qualitative statement. revision: yes
-
Referee: [Abstract] Abstract: the weakest assumption—that adapting difference-of-means to per-layer key projections yields a direction that generalizes across models, layers, and jailbreak distributions without post-hoc tuning—is stated but receives no derivation, stability check, or cross-model verification. This assumption is load-bearing for the safety claim; if the anchor fails to align with harmful content in key space, the penalty cannot deliver the claimed improvement.
Authors: The assumption is load-bearing and currently lacks supporting analysis. The manuscript adapts the difference-of-means construction to layer-specific key projections but provides neither a derivation of why this space yields a stable refusal direction nor stability or cross-model checks. We will add a dedicated subsection deriving the per-layer adaptation, reporting stability of the anchor vector across layers, and including verification on at least two models and multiple jailbreak families. If the anchor proves model- or attack-specific, we will revise the abstract and method description to state the observed scope of applicability. revision: yes
Circularity Check
No significant circularity in derivation chain.
full rationale
The paper constructs its safety anchor by adapting an external difference-of-means representation engineering method from cited prior work (arditi2024refusal, zou2023representation) to per-layer key projections, then defines a soft-penalty selection rule that reduces to the baseline compressor at zero penalty. No equation or step reduces by construction to the paper's own fitted values, self-citations, or inputs; the central premise relies on the external technique without internal redefinition or renaming of known results as new derivations. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- penalty strength
axioms (1)
- domain assumption Difference-of-means in layer-specific key space identifies directions associated with harmful prompts
invented entities (1)
-
refusal anchor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Junyuan Hong, Jinhao Duan, Chenhui Zhang, Zhangheng Li, Chulin Xie, Kelsey Lieberman, James Diffenderfer, Brian Bartoldson, Ajay Jaiswal, Kaidi Xu, et al. Decoding compressed trust: Scruti- nizing the trustworthiness of efficient llms under compression.arXiv preprint arXiv:2403.15447,
-
[3]
Tanqiu Jiang, Zian Wang, Jiacheng Liang, Changjiang Li, Yuhui Wang, and Ting Wang. Ro- bustkv: Defending large language models against jailbreak attacks via kv eviction.arXiv preprint arXiv:2410.19937,
-
[4]
FastKV: Decoupling of Context Reduction and KV Cache Compression for Prefill-Decoding Acceleration
Dongwon Jo, Jiwon Song, Yulhwa Kim, and Jae-Joon Kim. Fastkv: Kv cache compression for fast long-context processing with token-selective propagation.arXiv preprint arXiv:2502.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451, 2023a. 13 Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, and Yuandong Tian
Accessed: 2025-XX-XX. Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, and Yuandong Tian. Ad- vprompter: Fast adaptive adversarial prompting for llms.arXiv preprint arXiv:2404.16873,
-
[8]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Alexander Robey, Eric Wong, Hamed Hassani, and George J Pappas. Smoothllm: Defending large language models against jailbreaking attacks.arXiv preprint arXiv:2310.03684,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2):1–124,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Xiabin Zhou, Wenbin Wang, Minyan Zeng, Jiaxian Guo, Xuebo Liu, Li Shen, Min Zhang, and Liang Ding. Dynamickv: Task-aware adaptive kv cache compression for long context llms.arXiv preprint arXiv:2412.14838,
-
[12]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023a. Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.