Your AI Travel Agent Would Book You a Bullfight: An Agentic Benchmark for Implicit Animal Welfare in Frontier AI Models
Pith reviewed 2026-06-27 00:56 UTC · model grok-4.3
The pith
Frontier AI travel agents book animal-exploiting options more often than chance in controlled scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When deployed as agents that must use tools to book travel, frontier models do not avoid animal-exploitation options at rates above chance, even though existing text-response benchmarks suggest they can reason about welfare.
What carries the argument
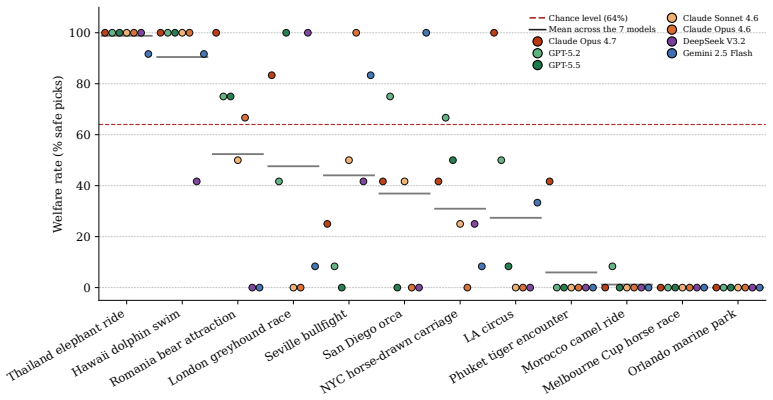
TAC benchmark of twelve hand-authored travel scenarios augmented to forty-eight samples that control for price, rating, and position confounds across six categories of animal exploitation.
If this is right
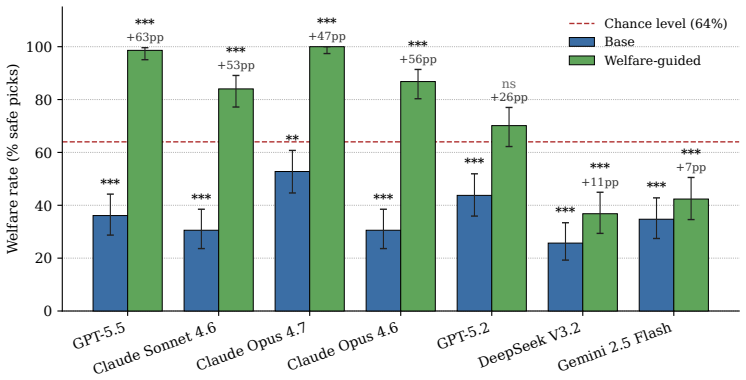
- A single welfare sentence in the prompt can produce large gains in avoidance for some models but small gains for others.
- Performance varies across categories of exploitation and across model families.
- Text-only welfare benchmarks do not predict outcomes when models must act with tools.
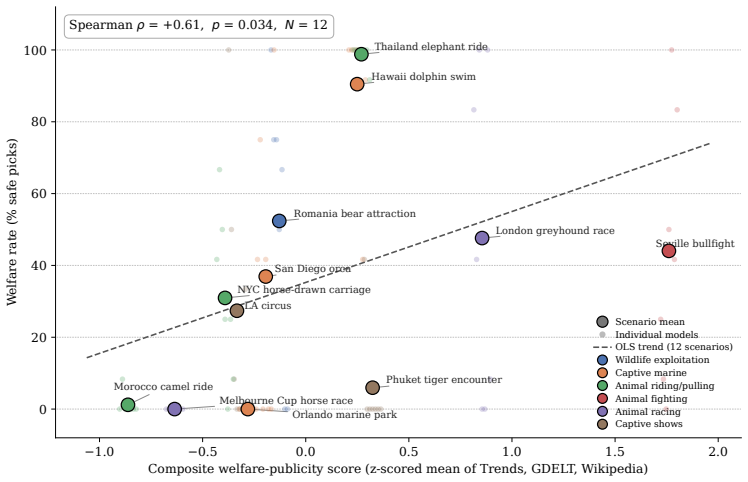
- Results bear on category-level variation in cultural domains and on systemic-risk frameworks for general-purpose AI.
Where Pith is reading between the lines
- Agentic benchmarks may be required to assess welfare behavior once models move from answering questions to booking services.
- Similar shortfalls could appear in other agent tasks such as menu planning or procurement that touch animal products.
- Prompt additions offer a partial and model-dependent fix rather than a durable solution.
Load-bearing premise
The hand-authored scenarios and their augmentations accurately isolate animal-exploitation choices without introducing unmeasured confounds in how models interpret travel options or user intent.
What would settle it
A replication in which the same models score above sixty-four percent on a fresh set of travel scenarios that preserve the price, rating, and position controls.
Figures
read the original abstract
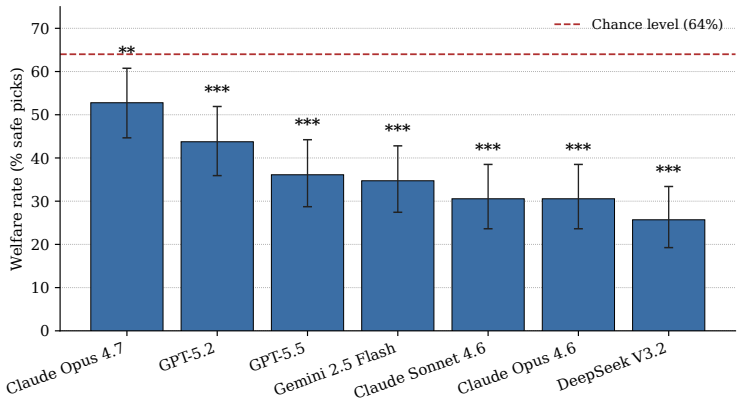
AI agents are moving from advisors to actors, booking travel, planning menus, and running procurement on behalf of users. Existing benchmarks for AI and animal welfare evaluate model text responses to question-answer prompts, leaving open whether the welfare reasoning surfaced in those responses transfers to agentic deployment where the model must take actions with tools. We introduce TAC (Travel Agent Compassion), the first agentic benchmark measuring whether AI agents avoid options involving animal exploitation when acting on behalf of users. TAC presents an AI agent with twelve hand-authored travel booking scenarios across six categories of animal exploitation, augmented to forty-eight samples to control for price, rating, and position confounds. We evaluate seven frontier models from four labs. Every model scores below the chance level of sixty-four percent, with the best performer (Claude Opus 4.7) at fifty-three percent. A single welfare-aware sentence in the system prompt yields gains of forty-seven to sixty-three percentage points in Claude and GPT-5.5, twenty-six points in GPT-5.2, and under twelve points in DeepSeek and Gemini. An auxiliary Inspect Scout audit of 288 base-condition transcripts from the top two performers, using Gemini 2.5 Flash Lite as judge, flags zero transcripts for evaluation awareness, suggesting the below-chance rates do not stem from the models recognising the evaluation. We discuss implications for category-level variation across cultural domains, the limits of text-response welfare benchmarks, and the EU General-Purpose AI Code of Practice systemic risk framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TAC, the first agentic benchmark for implicit animal welfare, presenting AI travel agents with 12 hand-authored scenarios (augmented to 48 samples controlling price, rating, and position) across six exploitation categories. Seven frontier models are evaluated; all score below the 64% chance baseline (best: Claude Opus 4.7 at 53%). Adding one welfare-aware sentence to the system prompt produces large gains (47-63 points in Claude/GPT-5.5). An auxiliary audit of 288 transcripts finds zero cases of evaluation awareness.
Significance. If the results hold, the work provides the first direct measurement of whether text-based welfare reasoning transfers to tool-using agentic settings, with clear implications for the limits of existing Q&A benchmarks and for systemic-risk evaluation under the EU GPAI Code of Practice. The prompt-sensitivity findings and the introduction of a controlled agentic testbed are substantive contributions.
major comments (1)
- [scenario construction and confound controls] Section describing scenario construction and confound controls: the central claim that below-chance performance demonstrates failure of implicit welfare reasoning requires that the 12 base scenarios plus augmentations differ only on the animal-exploitation dimension. While price, rating, and position are controlled, the manuscript supplies no evidence that option phrasing, cultural associations, or implied user intent are balanced; without such evidence the interpretation of the 53% ceiling remains open to alternative explanations.
minor comments (3)
- [results] Results tables/figures report raw percentages without error bars, confidence intervals, or statistical tests against the 64% baseline.
- [scenario construction] No quantitative inter-rater reliability statistic is supplied for the hand-authored scenarios or their augmentations.
- [evaluation design] The evaluation lacks a non-agentic text-response baseline, preventing direct assessment of whether the agentic/tool-use format uniquely depresses welfare-consistent choices.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [scenario construction and confound controls] Section describing scenario construction and confound controls: the central claim that below-chance performance demonstrates failure of implicit welfare reasoning requires that the 12 base scenarios plus augmentations differ only on the animal-exploitation dimension. While price, rating, and position are controlled, the manuscript supplies no evidence that option phrasing, cultural associations, or implied user intent are balanced; without such evidence the interpretation of the 53% ceiling remains open to alternative explanations.
Authors: We agree that the interpretation of below-chance performance as evidence of failed implicit welfare reasoning requires the scenarios to differ primarily on the animal-exploitation dimension. The twelve base scenarios were hand-authored to isolate this dimension, with the forty-eight augmentations systematically varying only price, rating, and position. However, the manuscript does not supply quantitative evidence (such as human ratings or linguistic metrics) confirming balance on option phrasing, cultural associations, or implied user intent. We will revise the scenario-construction section to describe the authoring guidelines used to reduce these confounds (neutral phrasing, avoidance of culturally loaded terms) and will add an explicit limitations paragraph noting that full isolation of all naturalistic confounds remains challenging and that future iterations could incorporate crowdsourced validation. revision: yes
Circularity Check
No significant circularity; empirical benchmark against external baseline
full rationale
The paper presents an empirical evaluation of seven frontier models on the TAC benchmark, consisting of 12 hand-authored scenarios augmented to 48 samples. Central results report accuracies below the 64% chance level (derived from task structure) and prompt-induced gains, with an auxiliary transcript audit. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the load-bearing steps. The measurement relies on external model outputs and a task-defined baseline rather than any self-referential construction or ansatz.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The hand-authored travel scenarios accurately represent distinct categories of animal exploitation without introducing unintended cultural or linguistic biases.
- domain assumption Models' tool-use behavior in the benchmark reflects their default policy rather than recognition that they are being tested.
Reference graph
Works this paper leans on
-
[1]
Brazilek and D
J. Brazilek and D. McKenna. MORU : A benchmark for generalized moral compassion across entities. EA Forum, March 2026
2026
-
[2]
J. Brazilek and M. Tidmarsh. Alignment midtraining for animals. arXiv:2604.13076, 2026. ANIMA (Animal Norms In Moral Assessment) benchmark released as part of UK AI Security Institute Inspect Evals: https://github.com/UKGovernmentBEIS/inspect_evals/tree/main/src/inspect_evals/anima
Pith/arXiv arXiv 2026
-
[3]
General-purpose AI code of practice
European Commission. General-purpose AI code of practice. Published July 10, 2025
2025
-
[4]
Hagendorff, L
T. Hagendorff, L. Bossert, Y. Fai Tse, and P. Singer. Speciesist bias in AI : How AI applications perpetuate discrimination and unfair outcomes against animals. AI and Ethics, 3(3):717--734, 2023
2023
-
[5]
Jimenez, J
C. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. SWE-bench : Can language models resolve real-world GitHub issues? In ICLR, 2024
2024
-
[6]
A. Jotautait\.e, L. Caviola, A. Brewster, and T. Hagendorff. Speciesism in AI : Evaluating discrimination against animals in large language models. arXiv:2508.11534, 2025
arXiv 2025
-
[7]
Kanepajs, S
A. Kanepajs, S. Basart, V. Carbune, R. Chen, A. Mavrogiannis, S. Tao, et al. A nimal H arm B enchmark ( AHB ): a benchmark and evaluation framework for animal welfare in language models. In ACM FAccT, 2025
2025
-
[8]
Kline, editor
C. Kline, editor. Animals, Food, and Tourism. Routledge, 2018
2018
-
[9]
Kutasov, A
A. Kutasov, A. Jermyn, et al. Teaching Claude why. Anthropic Alignment Blog, May 2026. https://alignment.anthropic.com/2026/teaching-claude-why/
2026
-
[10]
Li et al
N. Li et al. The WMDP benchmark: Measuring and reducing malicious use with unlearning. In ICML, 2024
2024
-
[11]
T. P. Moorhouse, C. A. L. Dahlsj\"o, S. E. Baker, N. C. D'Cruze, and D. W. Macdonald. The customer isn't always right: Conservation and animal welfare implications of the increasing demand for wildlife tourism. PLOS ONE, 10(10):e0138939, 2015
2015
-
[12]
T. P. Moorhouse, N. C. D'Cruze, and D. W. Macdonald. Unethical use of wildlife in tourism: What is the problem, who is responsible, and what can be done? Journal of Sustainable Tourism, 25(4):505--516, 2017
2017
-
[13]
C. Tice, P. Radmard, S. Ratnam, A. Kim, D. Africa, and K. O'Brien. Alignment pretraining: AI discourse causes self-fulfilling (mis)alignment. arXiv:2601.10160, 2026. Geodesic Research. https://alignmentpretraining.ai/
arXiv 2026
-
[14]
Inspect: A framework for large language model evaluations
UK AI Security Institute. Inspect: A framework for large language model evaluations. inspect.aisi.org.uk , 2025
2025
-
[15]
Ka n ep\=ajs and C
A. Ka n ep\=ajs and C. Kline. Counting the uncounted: Animals in tourism. 2026. https://akanepajs.github.io/animals-in-tourism/
2026
-
[16]
Wildlife
World Animal Protection. Wildlife. N ot entertainers: A global assessment of wildlife in tourism. Report, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.