Sparsity Curse: Understanding RLVR Model Parameter Space from Model Merging
Pith reviewed 2026-06-27 00:54 UTC · model grok-4.3
The pith
Sparse RLVR updates spread farther apart in parameter space than SFT updates, forming near-orthogonal directions that break standard model merging.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
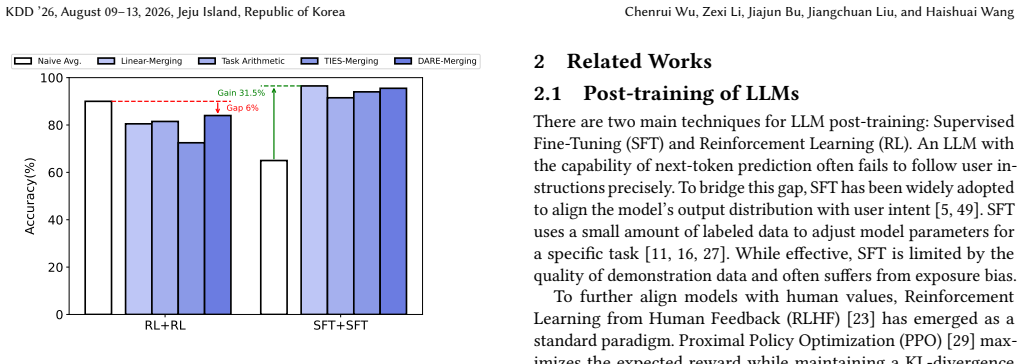
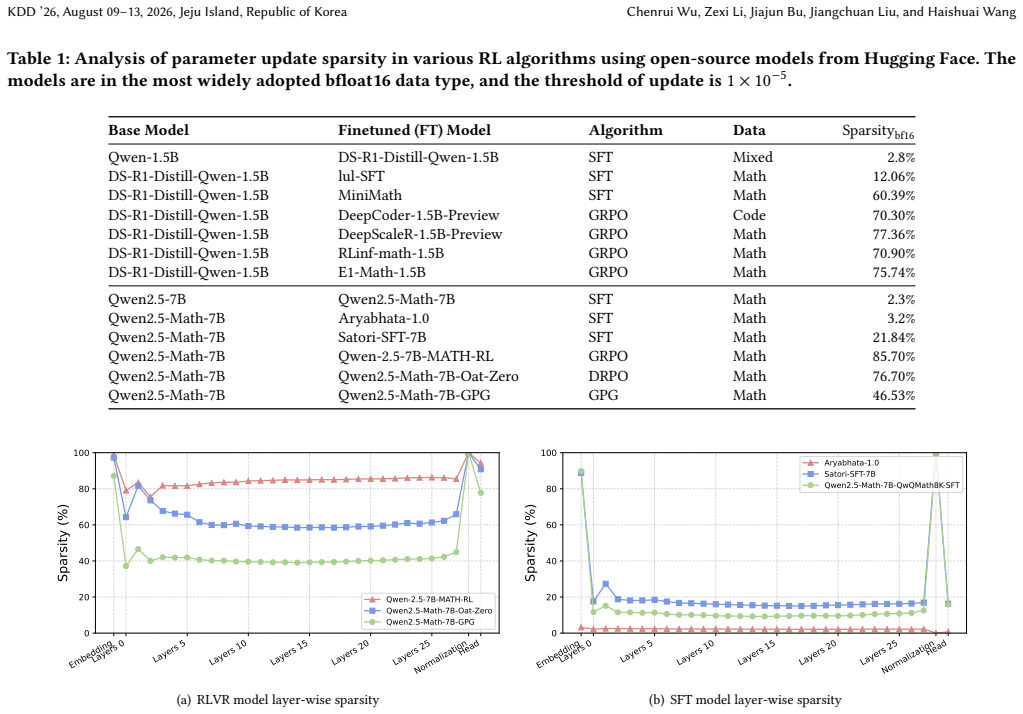
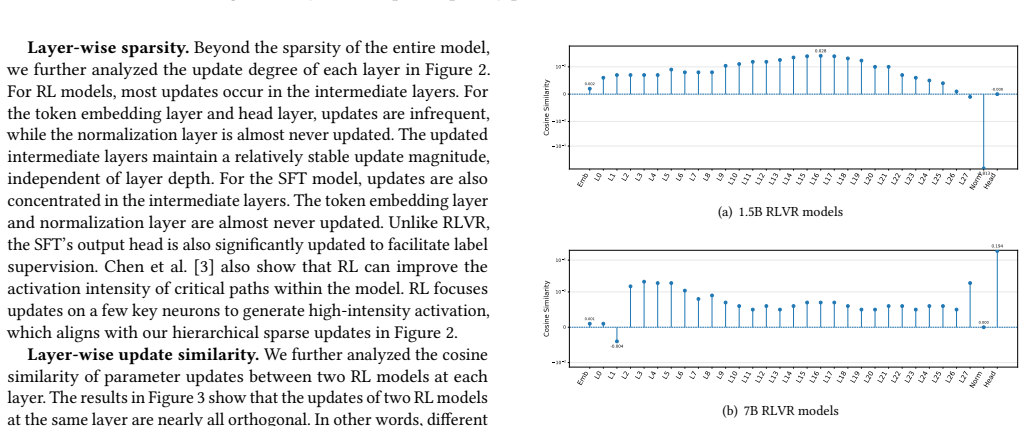
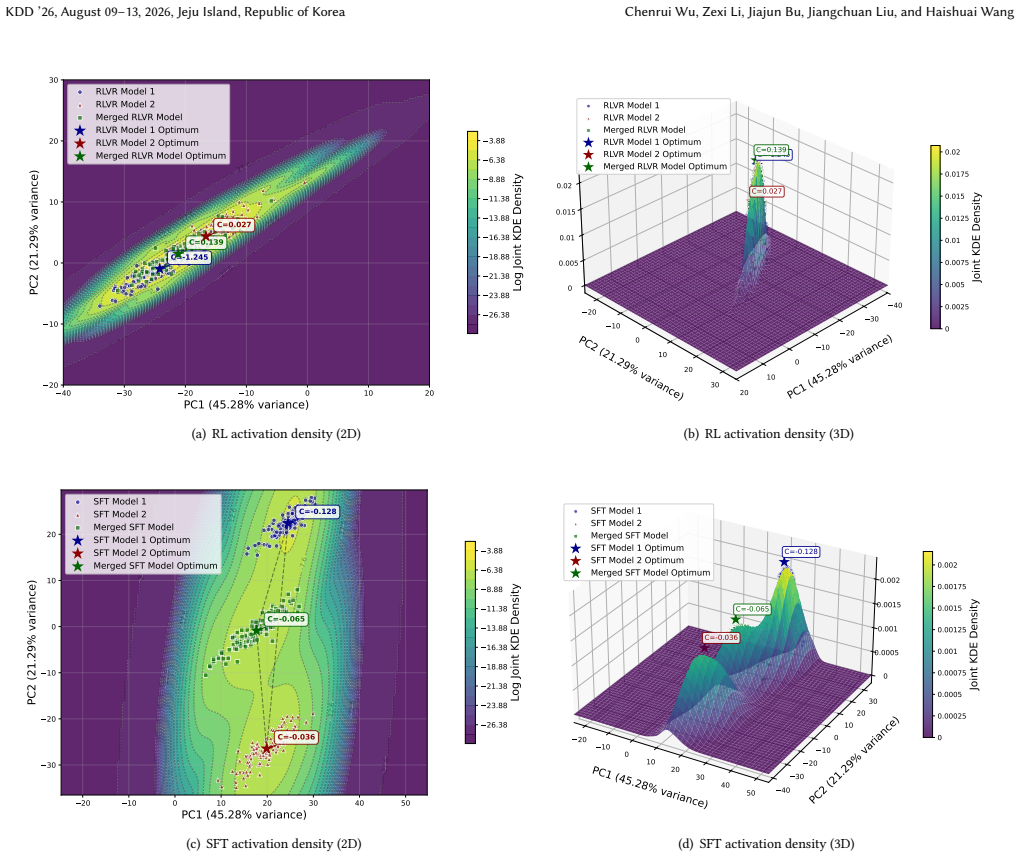
The sparse RLVR updates are spread farther apart in parameter space, forming near-orthogonal shortcuts that make aggregation inherently fragile. This is likely rooted in the stochasticity of RL optimization and the diversity of emergent reasoning patterns. Unlike SFT models that converge to shared, flat basins and merge naturally, RLVR models suffer severe degradation under standard merging methods.
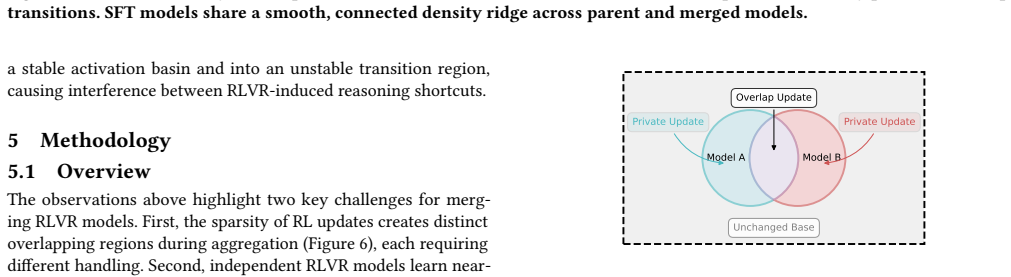
What carries the argument
SAR-Merging, which resolves conflicts in overlapping update regions via Fisher Information-based sensitivity arbitration, followed by magnitude-aware sparsification and rescaling to preserve fragile reasoning pathways.
If this is right
- Standard merging methods cause severe degradation on RLVR models.
- SAR-Merging enables single-task enhancement and multi-capability fusion on mathematical and coding benchmarks.
- The sparsity curse arises from the stochastic nature of RL optimization and varied emergent reasoning patterns.
- RLVR models do not merge naturally like SFT models that reach shared flat basins.
Where Pith is reading between the lines
- Merging methods for RL models may need to incorporate explicit handling of update geometry instead of assuming compatibility across runs.
- Future experiments that hold training data and hyperparameters fixed could more cleanly isolate whether sparsity alone drives the observed merging fragility.
- The same update-geometry issues could appear in other RL settings that produce sparse changes outside of reasoning tasks.
Load-bearing premise
The degradation seen when merging RLVR models is caused by the geometry of their sparse updates rather than differences in training data or optimization hyperparameters.
What would settle it
Train several RLVR models on the exact same data and hyperparameters then apply a standard merging method; persistent degradation would support the geometry explanation, while its absence would point to other factors.
Figures


read the original abstract
Reinforcement Learning with Verifiable Reward (RLVR) has emerged as a powerful post-training paradigm that surpasses Supervised Fine-Tuning (SFT) in eliciting reasoning intelligence and resisting catastrophic forgetting. Recent studies further reveal that RLVR induces highly sparse and off-principal parameter updates compared to SFT. This naturally raises the question: does such sparsity make RLVR models more amenable to model merging? If so, model merging would offer a scalable, training-free path to aggregate diverse reasoning capabilities from independently trained RLVR models. Surprisingly, we find the opposite, uncovering a sparsity curse: the sparse RLVR updates are spread farther apart in parameter space, forming near-orthogonal shortcuts that make aggregation inherently fragile. This is likely rooted in the stochasticity of RL optimization and the diversity of emergent reasoning patterns. Unlike SFT models that converge to shared, flat basins and merge naturally, RLVR models suffer severe degradation under standard merging methods. Through systematic empirical analysis of the update geometry, we characterize the mechanisms behind this failure and propose Sensitivity-aware Resolving Merging (SAR-Merging), a merging recipe tailored for the unique structure of RLVR parameter spaces. SAR-Merging resolves conflicts in overlapping update regions via Fisher Information-based sensitivity arbitration, followed by magnitude-aware sparsification and rescaling to preserve fragile reasoning pathways. Experiments on mathematical and coding benchmarks demonstrate that SAR-Merging substantially outperforms existing merging methods on RLVR models, enabling both single-task enhancement and multi-capability fusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RLVR induces highly sparse, off-principal parameter updates that lie farther apart in parameter space and form near-orthogonal directions compared to SFT, rendering standard merging methods ineffective due to a 'sparsity curse' rooted in RL stochasticity and reasoning diversity. Unlike SFT models that converge to shared flat basins, RLVR models suffer severe degradation under merging; the authors characterize this via update geometry analysis and propose SAR-Merging, which arbitrates conflicts using Fisher Information sensitivity, applies magnitude-aware sparsification, and rescales to preserve reasoning pathways, demonstrating superior performance on math and coding benchmarks for single-task enhancement and multi-capability fusion.
Significance. If the geometric characterization and causal attribution hold after appropriate controls, the work would be significant for explaining why RLVR models resist aggregation and for providing a practical, training-free method to combine diverse reasoning capabilities. The tailored SAR-Merging recipe and benchmark results offer a concrete advance over generic merging techniques, with potential implications for scalable post-training of reasoning models.
major comments (3)
- [Abstract and §3] Abstract and §3 (Experimental Setup): The load-bearing claim that merging fragility is caused by the geometry of sparse RLVR updates (farther apart, near-orthogonal) rather than other factors requires explicit confirmation that data distributions, optimization schedules, and random seeds were matched between RLVR and SFT models. The abstract states models are 'independently trained' and attributes the effect to RL stochasticity, but without matched controls the geometry observation risks being a downstream correlate.
- [§4] §4 (Update Geometry Analysis): The characterization of update distances and angles as 'near-orthogonal shortcuts' should report quantitative metrics (e.g., cosine similarities or pairwise distances with error bars across multiple seeds) and test whether these properties persist when training conditions are controlled; otherwise the mechanism behind the 'sparsity curse' remains under-supported.
- [§5] §5 (SAR-Merging): The Fisher Information-based sensitivity arbitration and subsequent rescaling steps are presented as resolving conflicts in overlapping regions, but the manuscript should include an ablation isolating the contribution of each component (sensitivity arbitration vs. magnitude-aware sparsification) on the reported benchmark gains to confirm they address the identified geometry issue rather than generic sparsity.
minor comments (2)
- [§2] Notation for parameter updates (e.g., Δθ_RLVR) should be defined consistently in the first section where geometry is introduced to avoid ambiguity in later equations.
- [Figure 2] Figure captions for geometry visualizations should explicitly state the number of model pairs and random seeds used to generate the plotted distributions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the presentation of our geometric analysis and the SAR-Merging method. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Experimental Setup): The load-bearing claim that merging fragility is caused by the geometry of sparse RLVR updates (farther apart, near-orthogonal) rather than other factors requires explicit confirmation that data distributions, optimization schedules, and random seeds were matched between RLVR and SFT models. The abstract states models are 'independently trained' and attributes the effect to RL stochasticity, but without matched controls the geometry observation risks being a downstream correlate.
Authors: We agree that matched controls are essential to isolate the effect of the RLVR paradigm. All models share the same base checkpoint and are trained on overlapping task distributions drawn from the same math and coding corpora; however, the fundamental difference in objectives (verifiable reward vs. supervised pairs) and the stochastic nature of RL policy optimization preclude identical schedules and seeds while preserving the intended comparison. We will revise §3 to tabulate all shared and differing hyperparameters, explicitly note the sources of non-matched elements, and add a short discussion of why these differences are intrinsic to the RLVR vs. SFT contrast rather than confounds. revision: partial
-
Referee: [§4] §4 (Update Geometry Analysis): The characterization of update distances and angles as 'near-orthogonal shortcuts' should report quantitative metrics (e.g., cosine similarities or pairwise distances with error bars across multiple seeds) and test whether these properties persist when training conditions are controlled; otherwise the mechanism behind the 'sparsity curse' remains under-supported.
Authors: We will expand §4 with the requested quantitative metrics: mean cosine similarities and Euclidean distances between update vectors, each accompanied by standard-error bars computed over at least three independent random seeds per training paradigm. We will also include a controlled-condition experiment that re-trains a subset of models with matched data order and learning-rate schedules where feasible, confirming that the near-orthogonality and larger distances persist under these controls. revision: yes
-
Referee: [§5] §5 (SAR-Merging): The Fisher Information-based sensitivity arbitration and subsequent rescaling steps are presented as resolving conflicts in overlapping regions, but the manuscript should include an ablation isolating the contribution of each component (sensitivity arbitration vs. magnitude-aware sparsification) on the reported benchmark gains to confirm they address the identified geometry issue rather than generic sparsity.
Authors: We will add a dedicated ablation subsection in §5 that systematically disables each SAR-Merging component in turn (sensitivity arbitration, magnitude-aware sparsification, and rescaling) while keeping the others fixed. The results will be reported on the same math and coding benchmarks, allowing direct comparison of incremental gains and demonstrating that the sensitivity-based conflict resolution specifically mitigates the geometric interference identified in §4, beyond what generic sparsity techniques achieve. revision: yes
Circularity Check
Empirical observations with no derivation chain or self-referential reductions
full rationale
The paper reports experimental findings on merging degradation for RLVR models versus SFT, attributes it to observed update geometry (sparsity, distance, orthogonality), and proposes SAR-Merging based on Fisher sensitivity. No equations, parameter fits presented as predictions, self-citations as load-bearing premises, or ansatzes are present in the abstract or described structure. The central claims rest on direct empirical comparisons rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. 2025. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?. InProceedings of Advances in Neural Information Processing Systems (NeurIPS), Vol. 38. 57654–57689
2025
-
[4]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training Verifiers to Solve Math Word Problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [5]
-
[6]
Ronald A Fisher. 1922. On the mathematical foundations of theoretical statistics. Philosophical transactions of the Royal Society of London. Series A, containing papers of a mathematical or physical character222, 594-604 (1922), 309–368
1922
-
[7]
Zichuan Fu, Xian Wu, Guojing Li, Yingying Zhang, Yefeng Zheng, Tianshi Ming, Yejing Wang, Wanyu Wang, and Xiangyu Zhao. 2025. Model merging for knowl- edge editing. InProceedings of the Annual Meeting of the Association for Compu- tational Linguistics, Industry Track (ACL). 433–443
2025
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring Mathematical Problem Solving With the MATH Dataset. InProceedings of Advances in Neural Information Processing Systems (NeurIPS)
2021
-
[11]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.. InProceedings of International Conference on Learning Repre- sentations (ICLR)
2022
-
[12]
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Han- naneh Hajishirzi, and Ali Farhadi. 2023. Editing models with task arithmetic. In Proceedings of International Conference on Learning Representations (ICLR)
2023
-
[13]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. 2024. Openai o1 system card.arXiv preprint arXiv:2412.16720(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B.arXiv preprint ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [15]
-
[16]
Xiang Lisa Li and Percy Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL). 4582–4597
2021
-
[17]
Zexi Li, Zhiqi Li, Jie Lin, Tao Shen, Jun Xiao, Yike Guo, Tao Lin, and Chao Wu
-
[18]
Improving Model Fusion by Training-time Neuron Alignment with Fixed Neuron Anchors.IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[19]
Zexi Li, Tao Lin, Xinyi Shang, and Chao Wu. 2023. Revisiting Weighted Aggrega- tion in Federated Learning with Neural Networks. InProceedings of International Conference on Machine Learning (ICML). 19767–19788
2023
-
[20]
Haohao Luo, Zexi Li, Yuexiang Xie, Wenhao Zhang, Yaliang Li, and Ying Shen
-
[21]
InProceedings of International Conference on Machine Learning (ICML)
IntentRL: Training Proactive User-intent Agents for Open-ended Deep Research via Reinforcement Learning. InProceedings of International Conference on Machine Learning (ICML)
-
[22]
Michael S Matena and Colin A Raffel. 2022. Merging models with fisher-weighted averaging. InProceedings of Advances in Neural Information Processing Systems (NeurIPS), Vol. 35. 17703–17716
2022
-
[23]
Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tur, and Hao Peng. 2025. Rein- forcement Learning Finetunes Small Subnetworks in Large Language Models. In Proceedings of Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[24]
Amin Heyrani Nobari, Kaveh Alim, Ali ArjomandBigdeli, Akash Srivastava, Faez Ahmed, and Navid Azizan. 2025. Activation-informed merging of large language models. InProceedings of Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[25]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. InPro- ceedings of Advances in Neural Information Processing Systems (NeurIPS), Vol. 35. 27730–27744
2022
-
[26]
Zhenting Qi, Fan Nie, Alexandre Alahi, James Zou, Himabindu Lakkaraju, Yilun Du, Eric Xing, Sham Kakade, and Hanlin Zhang. 2025. EvoLM: In Search of Lost Language Model Training Dynamics. InProceedings of Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[27]
Zihuan Qiu, Lei Wang, Yang Cao, Runtong Zhang, Bing Su, Yi Xu, Fanman Meng, Linfeng Xu, Qingbo Wu, and Hongliang Li. 2026. Null-Space Filtering for Data- Free Continual Model Merging: Preserving Transparency, Promoting Fidelity. In Proceedings of International Conference on Learning Representations (ICLR)
2026
-
[28]
Zihuan Qiu, Yi Xu, Chiyuan He, Fanman Meng, Linfeng Xu, Qingbo Wu, and Hongliang Li. 2025. MINGLE: Mixture of Null-Space Gated Low-Rank Experts for Test-Time Continual Model Merging. InProceedings of Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[29]
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al . 2018. Improving language understanding by generative pre-training. (2018)
2018
-
[30]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. InProceedings of Advances in Neural Information Processing Systems (NeurIPS), Vol. 36. 53728–53741
2023
-
[31]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[32]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Donald Shenaj, Ondrej Bohdal, Taha Ceritli, Mete Ozay, Pietro Zanuttigh, and Umberto Michieli. 2026. K-Merge: Online Continual Merging of Adapters for On-device Large Language Models. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL)
2026
-
[34]
George Stoica, Pratik Ramesh, Boglarka Ecsedi, Leshem Choshen, and Judy Hoffman. 2025. Model merging with svd to tie the knots. InProceedings of International Conference on Learning Representations (ICLR)
2025
-
[35]
Anke Tang, Enneng Yang, Li Shen, Yong Luo, Han Hu, Lefei Zhang, Bo Du, and Dacheng Tao. 2025. Merging on the Fly Without Retraining: A Sequential Approach to Scalable Continual Model Merging. InProceedings of Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[36]
Wanxin Tian, Shijie Zhang, Kevin Zhang, Xiaowei Chi, Chun-Kai Fan, Junyu Lu, Yulin Luo, Qiang Zhou, Yiming Zhao, Ning Liu, et al . 2025. Seea-r1: Tree- structured reinforcement fine-tuning for self-evolving embodied agents. InPro- ceedings of Advances in Neural Information Processing Systems (NeurIPS). 78458– 78499
2025
-
[37]
Hongyi Wang, Mikhail Yurochkin, Yuekai Sun, Dimitris Papailiopoulos, and Yasaman Khazaeni. 2020. Federated Learning with Matched Averaging. InPro- ceedings of International Conference on Learning Representations (ICLR)
2020
-
[38]
Peng Wang, Zexi Li, Ningyu Zhang, Ziwen Xu, Yunzhi Yao, Yong Jiang, Pengjun Xie, Fei Huang, and Huajun Chen. 2024. WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models. InProceedings of Advances in Neural Information Processing Systems (NeurIPS). 53764–53797
2024
-
[39]
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Si- mon Kornblith, et al. 2022. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. InProceedings of International Conference on Machine Learnin...
2022
-
[40]
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal
-
[41]
InAdvances in Neural Information Processing Systems (NeurIPS), Vol
Ties-merging: Resolving interference when merging models. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36. 7093–7115
-
[42]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. 2024. Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement. arXiv preprint arXiv:2409.12122(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Enneng Yang, Anke Tang, Li Shen, Guibing Guo, Xingwei Wang, Xiaochun Cao, and Jie Zhang. 2025. Continual Model Merging without Data: Dual Projections for Balancing Stability and Plasticity. InProceedings of Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[44]
Enneng Yang, Zhenyi Wang, Li Shen, Shiwei Liu, Guibing Guo, Xingwei Wang, and Dacheng Tao. 2024. Adamerging: Adaptive model merging for multi-task learning. InProceedings of International Conference on Learning Representations (ICLR), Vol. 2024. 22743–22763
2024
-
[45]
Yuxuan Yao, Shuqi Liu, Zehua Liu, Qintong Li, Mingyang Liu, Xiongwei Han, Zhi- jiang Guo, Han Wu, and Linqi Song. 2025. Activation-Guided Consensus Merging for Large Language Models. InProceedings of Advances in Neural Information Processing Systems (NeurIPS). Sparsity Curse: Understanding RLVR Model Parameter Space from Model Merging KDD ’26, August 09–1...
2025
-
[46]
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. 2024. Language models are super mario: Absorbing abilities from homologous models as a free lunch. In Proceedings of International Conference on Machine Learning (ICML)
2024
-
[47]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. 2025. Dapo: An open- source llm reinforcement learning system at scale. InProceedings of Advances in Neural Information Processing Systems (NeurIPS). 113222–113244
2025
- [48]
-
[49]
Fanhu Zeng, Haiyang Guo, Fei Zhu, Li Shen, and Hao Tang. 2025. RobustMerge: Parameter-Efficient Model Merging for MLLMs with Direction Robustness. In Proceedings of Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[50]
Honglin Zhang, Qianyue Hao, Fengli Xu, and Yong Li. 2026. Reinforcement Learning Fine-Tuning Enhances Activation Intensity and Diversity in the Inter- nal Circuitry of LLMs. InProceedings of International Conference on Learning Representations (ICLR)
2026
-
[51]
Haobo Zhang and Jiayu Zhou. 2025. Unraveling lora interference: Orthogonal subspaces for robust model merging. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL). 26459–26472
2025
-
[52]
Wenhao Zhang, Yuexiang Xie, Yuchang Sun, Yanxi Chen, Guoyin Wang, Yaliang Li, Bolin Ding, and Jingren Zhou. 2026. On-Policy RL Meets Off-Policy Experts: Harmonizing Supervised Fine-Tuning and Reinforcement Learning via Dynamic Weighting. InProceedings of International Conference on Learning Representations (ICLR)
2026
-
[53]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.182231, 2 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Ziyu Zhao, Tao Shen, Didi Zhu, Zexi Li, Jing Su, Xuwu Wang, Kun Kuang, and Fei Wu. 2025. Merging loras like playing lego: Pushing the modularity of lora to extremes through rank-wise clustering. InProceedings of International Conference on Learning Representations (ICLR)
2025
-
[55]
Yuqi Zhou, Sunhao Dai, Shuai Wang, Kaiwen Zhou, Qinglin Jia, and Jun Xu. 2025. Gui-g1: Understanding r1-zero-like training for visual grounding in gui agents. InProceedings of Advances in Neural Information Processing Systems (NeurIPS). 95683–95705
2025
- [56]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.