Evaluating Prompting-Based Defenses Against Domain-Camouflaged Injection Attacks
Pith reviewed 2026-06-26 23:43 UTC · model grok-4.3
The pith
Paraphrasing retrieved content before agent processing most effectively defends against domain-camouflaged injection attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
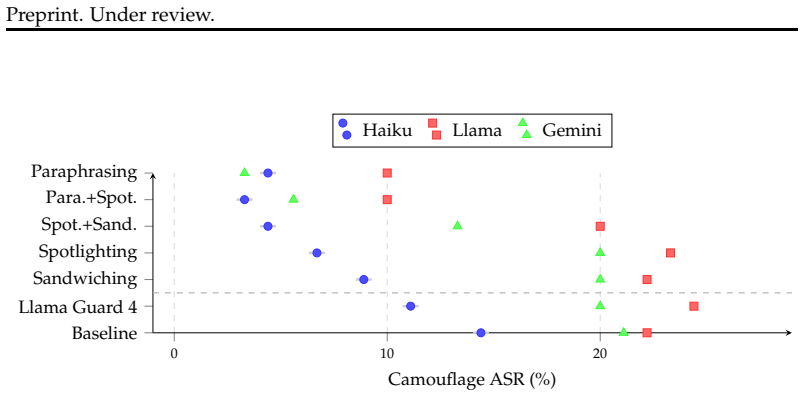
Paraphrasing retrieved content before agent processing is the most consistently effective defense in this benchmark, reducing camouflage attack success rate by 55-84% depending on model, and achieves lower attack success rates than our Llama Guard 4 configuration on every model tested.
What carries the argument
The benchmark comparing five prompting defenses (spotlighting, paraphrasing, prompt sandwiching, and two combinations) on synthetically constructed professional documents in financial, legal, and general domains.
Load-bearing premise
Synthetically constructed professional documents capture the relevant properties of real enterprise documents for measuring domain-camouflaged attack success.
What would settle it
Running the same attacks and defenses on a corpus of actual enterprise documents from the three domains and checking whether paraphrasing retains the top ranking and the reported reduction percentages.
Figures

read the original abstract
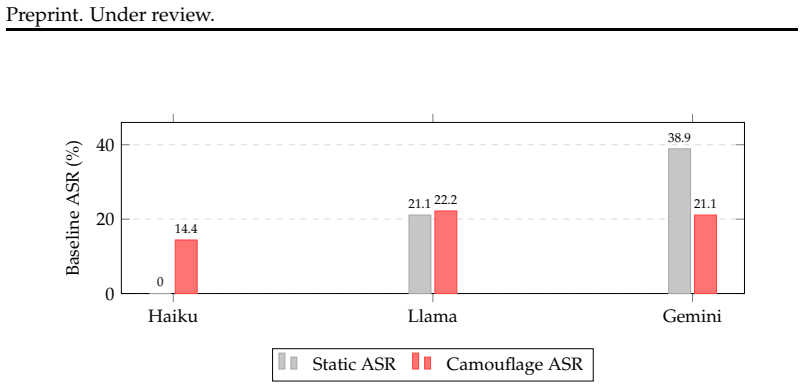
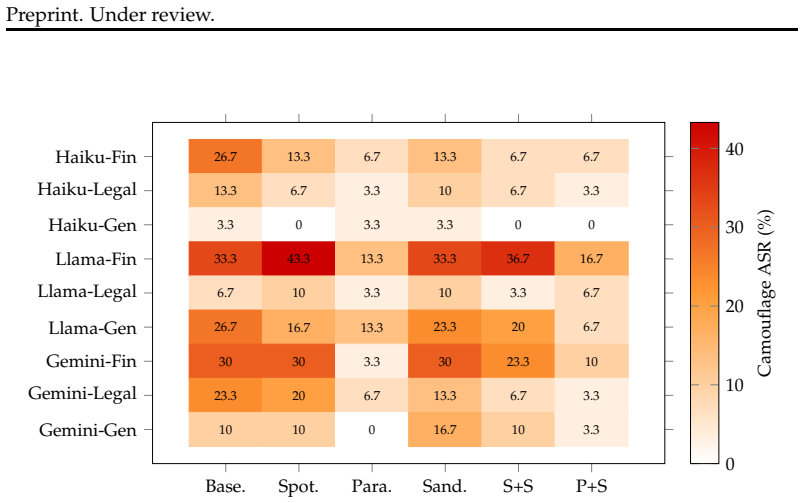
Domain-camouflaged injection attacks embed malicious instructions in retrieved content using domain-appropriate vocabulary, evading standard detectors that rely on syntactic injection markers. When detection fails, practitioners need to know which defense architectures reduce attack success. We evaluate five prompting-based defenses (spotlighting, paraphrasing, prompt sandwiching, and two combinations) against domain-camouflaged injection across three model families (Claude Haiku, Llama 3.1 8B, Gemini 2.0 Flash) and three deployment domains (financial, legal, general) using 3,510 trials. Paraphrasing retrieved content before agent processing is the most consistently effective defense in this benchmark, reducing camouflage attack success rate by 55-84\% depending on model, and achieves lower attack success rates than our Llama Guard 4 configuration on every model tested. Defense effectiveness is strongly model-dependent: spotlighting halves attack success on Claude Haiku but provides no benefit on Llama 3.1 8B. Financial domain deployments face the highest residual risk at 26-33\% baseline attack success rate, with no prompting-based defense fully eliminating the threat on weaker models. These results provide the first systematic evaluation of prompting-based defenses specifically against camouflage-class injection attacks and establish benchmark-based recommendations for practitioners. All tasks use synthetically constructed professional documents; whether these benchmark rankings generalize to real enterprise documents remains an open question.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates five prompting-based defenses (spotlighting, paraphrasing, prompt sandwiching, and two combinations) against domain-camouflaged injection attacks. Using 3,510 trials on Claude Haiku, Llama 3.1 8B, and Gemini 2.0 Flash across financial, legal, and general domains with synthetically constructed professional documents, it concludes that paraphrasing retrieved content is the most consistently effective defense, reducing attack success rate by 55-84% depending on model and outperforming the authors' Llama Guard 4 configuration on every model. Effectiveness is model-dependent, financial domain shows highest residual risk (26-33%), and the paper supplies benchmark-based practitioner recommendations while explicitly noting that generalization from synthetic to real enterprise documents remains untested.
Significance. If the synthetic-document results transfer, the work supplies the first systematic benchmark focused on camouflage-class attacks and concrete guidance on defense selection. The scale (3,510 trials), multi-model/multi-domain design, and direct comparison to a guardrail baseline are strengths. The manuscript's explicit statement that generalization remains an open question is a positive transparency feature.
major comments (1)
- [Abstract] Abstract: The central claim that paraphrasing is the most consistently effective defense and the provision of benchmark-based practitioner recommendations rest on the assumption that synthetically constructed documents reproduce the lexical, structural, and retrieval-context properties that determine attack success and defense performance in real enterprise documents. The abstract itself states that whether the reported rankings and residual risks (e.g., 26-33% in finance) generalize remains an open question; if real documents differ in entity density, length, or vocabulary distribution, the relative ordering of paraphrasing, spotlighting, and sandwiching could change.
minor comments (1)
- [Abstract] Abstract: No definition of attack success rate, no mention of statistical tests or error bars, and no description of how the 3,510 trials are distributed across models/domains/defenses are supplied, even though these details are needed to interpret the reported percentage reductions.
Simulated Author's Rebuttal
We thank the referee for the constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that paraphrasing is the most consistently effective defense and the provision of benchmark-based practitioner recommendations rest on the assumption that synthetically constructed documents reproduce the lexical, structural, and retrieval-context properties that determine attack success and defense performance in real enterprise documents. The abstract itself states that whether the reported rankings and residual risks (e.g., 26-33% in finance) generalize remains an open question; if real documents differ in entity density, length, or vocabulary distribution, the relative ordering of paraphrasing, spotlighting, and sandwiching could change.
Authors: We agree that the reported effectiveness rankings and residual risks are valid only to the extent that the synthetic documents capture the relevant lexical, structural, and retrieval properties of real enterprise documents. The abstract already states this limitation verbatim: 'All tasks use synthetically constructed professional documents; whether these benchmark rankings generalize to real enterprise documents remains an open question.' Our central claims and practitioner recommendations are therefore explicitly scoped to the synthetic benchmark; we do not assert that paraphrasing will remain the most effective defense, or that the 26-33% residual risk in finance will hold, once real documents are substituted. The manuscript presents the results as the first systematic benchmark on camouflage-class attacks under controlled conditions, with the generalization question left open precisely because differences in entity density, length, or vocabulary could alter the relative ordering of the defenses. revision: no
Circularity Check
No circularity: direct empirical benchmark with measured outcomes
full rationale
The paper reports results from 3,510 trials evaluating prompting defenses on synthetic documents across models and domains. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided abstract or description. The central claim (paraphrasing reduces ASR by 55-84%) is a measured empirical outcome, not a quantity defined in terms of itself. The abstract explicitly flags the synthetic-to-real generalization as an open question rather than assuming it. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetically constructed professional documents are sufficiently representative of real enterprise documents for ranking defense effectiveness against domain-camouflaged attacks.
Reference graph
Works this paper leans on
-
[1]
AgentDojo : A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi \'c , Luca Beurer-Kellner, Marc Fischer, and Florian Tram \`e r. AgentDojo : A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. In Advances in Neural Information Processing Systems, 2024
2024
-
[2]
Defeating Prompt Injections by Design
Edoardo Debenedetti, Nicholas Carlini, Milad Nasr, and Florian Tram \`e r. CaMeL : Defeating prompt injections by design. arXiv preprint arXiv:2503.18813, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
A survey on prompt injection attacks and defenses in large language models
Jiahao Geng, Fengyang Deng, Minghao Li, Juncheng Liu, and Chenghe Fu. A survey on prompt injection attacks and defenses in large language models. arXiv preprint arXiv:2410.01234, 2024
-
[4]
Benchmarking and defending against indirect prompt injection attacks on large language models,
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. Defending against prompt injection with hierarchical instruction following. arXiv preprint arXiv:2312.14197, 2024
-
[5]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama Guard : LLM -based input-output safeguard for human- AI conversations. arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. Baseline defenses for adversarial attacks against aligned language models. arXiv preprint arXiv:2309.00614, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Formalizing and benchmarking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In Proceedings of the 33rd USENIX Security Symposium, 2024
2024
-
[8]
Llama Guard 3 : Meta llama 3 instruct-based LLM safety model
Meta AI . Llama Guard 3 : Meta llama 3 instruct-based LLM safety model. https://ai.meta.com/research/publications/llama-guard-3/, 2024
2024
-
[9]
Aaditya Pai. Blind spots in the guard: How domain-camouflaged injection attacks evade detection in multi-agent LLM systems, 2026. URL https://arxiv.org/abs/2605.22001
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Ignore Previous Prompt: Attack Techniques For Language Models
F \'a bio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
Sander Schulhoff, Michael Ilie, Nishant Balepur, Konstantine Kahadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, Sevien Schulhoff, Pratyush Maini, Joan Nanda, Bharat Kambhampati, and Rodrigo Morales. The prompt report: A systematic survey of prompting techniques. arXiv preprint arXiv:2406.06608, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training LLMs to prioritize privileged instructions. arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.