AI Sandboxes: A Threat Model, Taxonomy, and Measurement Framework
Pith reviewed 2026-06-26 23:39 UTC · model grok-4.3
The pith
AI sandboxes receive a formalized threat model, taxonomy, and measurement framework that clarify valid tests, containable risks, and evidence for assurance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
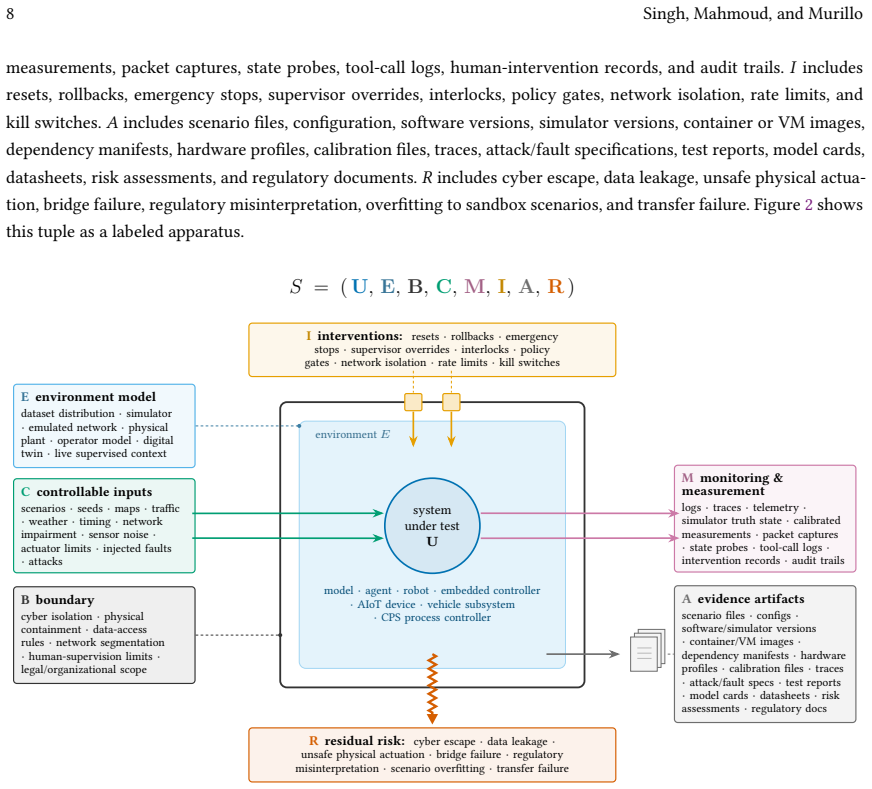
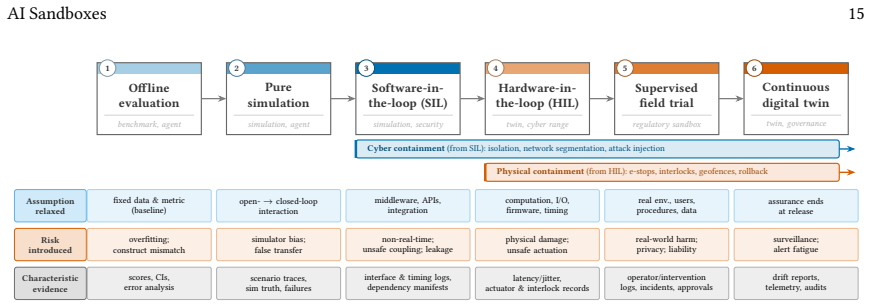
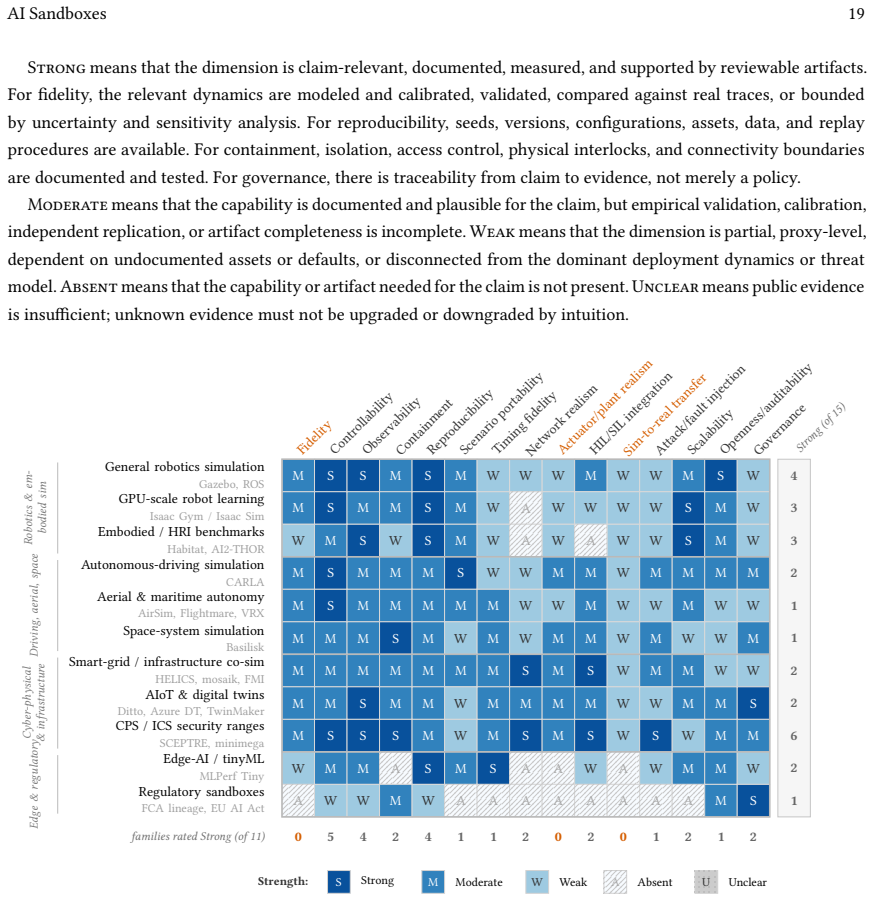
The paper formalizes the sandbox boundary and a weakest-link rule for composing per-dimension evidence into a bounded deployment claim; separates major sandbox archetypes; defines a cyber-physical threat model that includes attacks on the assurance apparatus itself; and introduces a measurement framework spanning fidelity, controllability, observability, containment, reproducibility, and governance artifacts, instantiated on three worked case studies.
What carries the argument
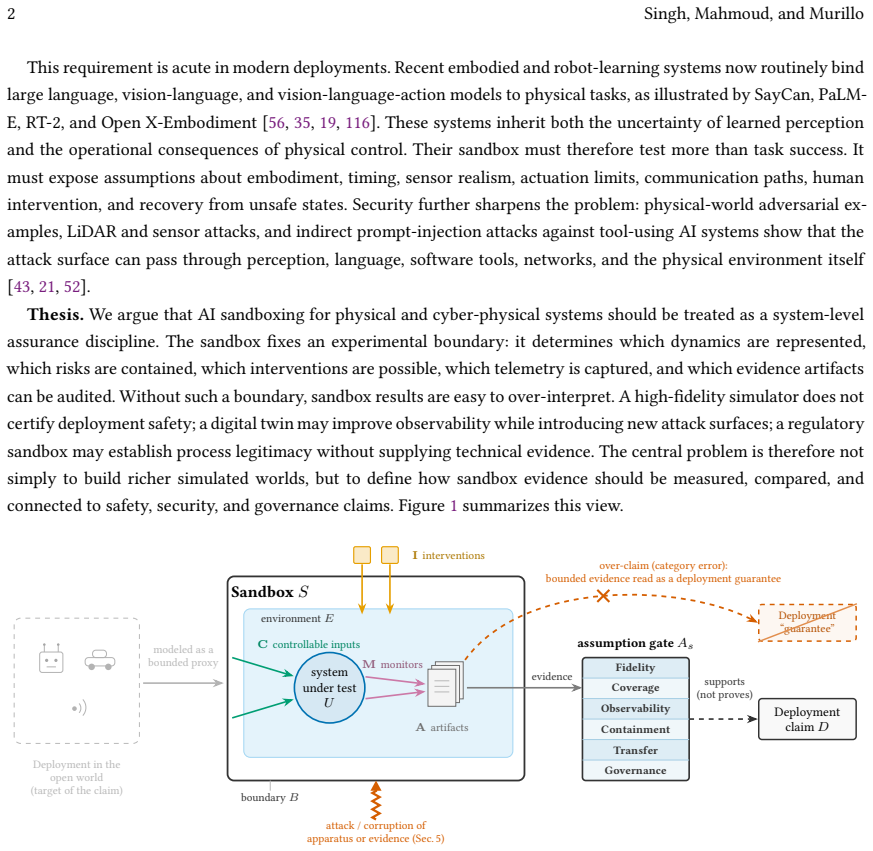
The sandbox boundary and weakest-link rule, which together compose evidence from multiple dimensions into a single bounded claim about what risks a sandbox can contain and what deployment assurances it can support.
If this is right
- Sandboxes can be separated into distinct archetypes with different testing and containment properties.
- The threat model requires considering attacks aimed at the sandbox's own assurance mechanisms.
- Evidence collected in a sandbox supports safety and regulatory claims only within the limits set by the weakest-link composition.
- The six measurement dimensions allow assessment of whether a sandbox can validly test specific risks.
- Governance artifacts become a required dimension for any claim of regulatory assurance from sandbox results.
Where Pith is reading between the lines
- Regulators could adopt the taxonomy to define minimum requirements for sandbox evidence in AI certification processes.
- Sandbox designers might prioritize improvements along the weakest dimensions identified by the measurement framework for their specific use cases.
- The approach could be extended to compare assurance levels across sandboxes used by different organizations or for different AI domains.
Load-bearing premise
The paper assumes that the formalized sandbox boundary and weakest-link rule for composing per-dimension evidence into a bounded deployment claim can be applied without providing the explicit formalization or validation steps for this rule.
What would settle it
A case where the weakest-link rule is applied to evidence from one of the studied sandboxes and the resulting bounded claim is contradicted by observed failures or un-contained risks in actual deployment would falsify the framework.
Figures
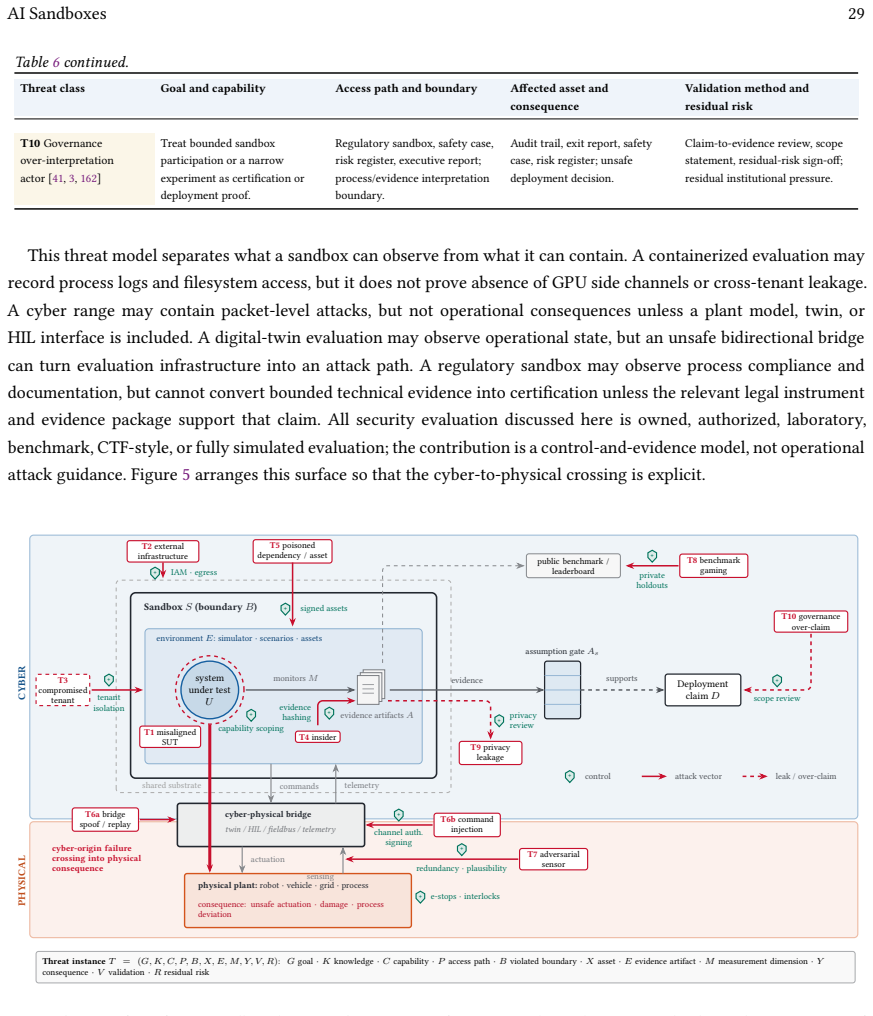

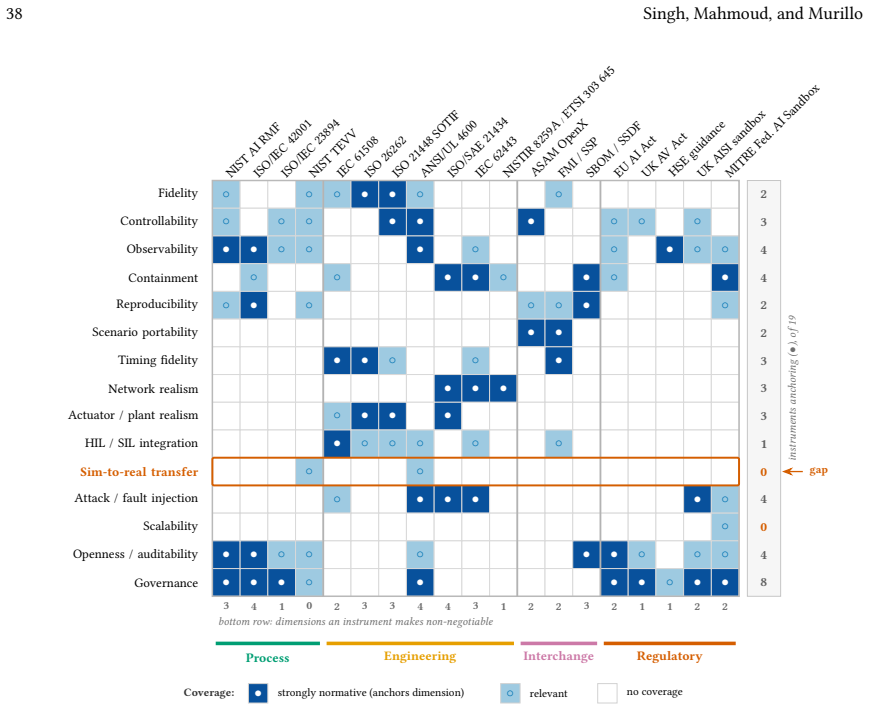
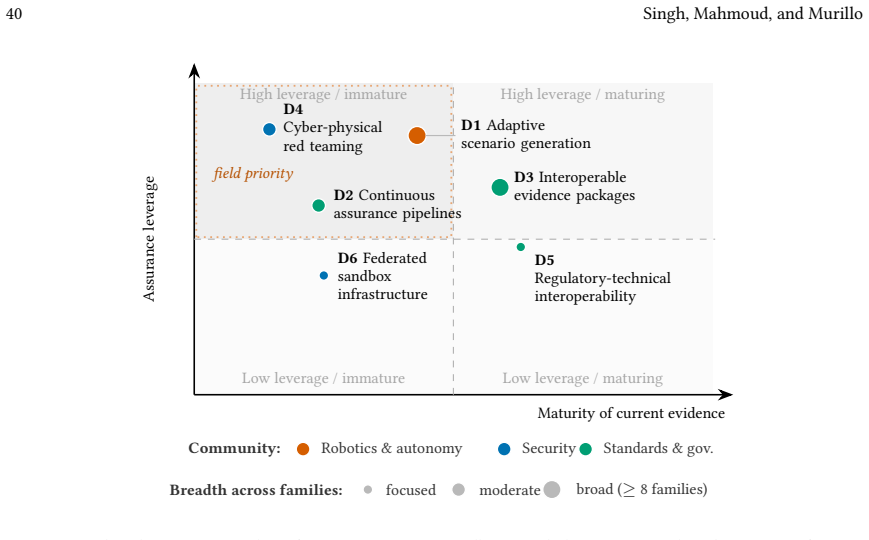
read the original abstract
AI systems are increasingly evaluated in bounded environments that combine isolation, simulation, instrumentation, supervision, and evidence capture. For physical AI, AIoT, and cyber-physical systems, this shift is not a matter of terminology: the system under test may sense, decide, actuate, communicate, and fail through physical processes, networked devices, and human operators. This article develops an assurance-oriented account of AI sandboxes as controlled environments for testing, evaluation, verification, and validation across digital AI, embodied autonomy, and cyber-physical deployments. We formalize the sandbox boundary and a weakest-link rule for composing per-dimension evidence into a bounded deployment claim; separate major sandbox archetypes; define a cyber-physical threat model that includes attacks on the assurance apparatus itself; and introduce a measurement framework spanning fidelity, controllability, observability, containment, reproducibility, and governance artifacts, instantiated on three worked case studies of real sandboxes. The resulting threat model, taxonomy, and measurement framework clarify what a sandbox can validly test, which risks it can contain, and what forms of evidence it can support for safety, security, and regulatory assurance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an assurance-oriented account of AI sandboxes as controlled environments for testing, evaluation, verification, and validation of digital AI, embodied autonomy, and cyber-physical systems. It claims to formalize the sandbox boundary and a weakest-link rule for composing per-dimension evidence into a bounded deployment claim, separate major sandbox archetypes, define a cyber-physical threat model that includes attacks on the assurance apparatus, and introduce a measurement framework spanning fidelity, controllability, observability, containment, reproducibility, and governance artifacts, instantiated on three worked case studies.
Significance. If the announced formalization and weakest-link rule can be supplied with explicit statements and validation, the resulting threat model, taxonomy, and measurement framework would clarify what a sandbox can validly test and the forms of evidence it can support for safety, security, and regulatory assurance. The paper's inclusion of three case studies and a threat model that accounts for attacks on the assurance apparatus itself are concrete strengths that could ground the taxonomy in practice.
major comments (1)
- [Abstract] Abstract: The central claim requires that the formalized sandbox boundary and weakest-link rule can be applied to turn per-dimension evidence into a bounded deployment claim. The manuscript announces this formalization but supplies neither the explicit mathematical statement of the rule (e.g., an axiom or composition operator) nor any validation procedure showing how the rule is applied without circularity or hidden assumptions.
minor comments (2)
- [Abstract] Abstract: The description of the measurement framework lists six dimensions but does not indicate how they are combined or scored in the case studies, leaving the framework's operational use unclear.
- [Abstract] Abstract: The claim that the framework 'clarify what a sandbox can validly test' is presented as a result, but without the missing formalization it functions more as a definitional taxonomy than a derived assurance method.
Simulated Author's Rebuttal
We thank the referee for identifying the gap between the abstract's announcement of a formalization and the absence of explicit mathematical statements and validation procedures in the manuscript. We will revise accordingly to strengthen the central claim.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim requires that the formalized sandbox boundary and weakest-link rule can be applied to turn per-dimension evidence into a bounded deployment claim. The manuscript announces this formalization but supplies neither the explicit mathematical statement of the rule (e.g., an axiom or composition operator) nor any validation procedure showing how the rule is applied without circularity or hidden assumptions.
Authors: We agree that the manuscript announces the formalization of the sandbox boundary and weakest-link rule in the abstract and introduction but does not supply an explicit mathematical statement (such as an axiom or composition operator) or a validation procedure demonstrating application to per-dimension evidence without circularity. This is a substantive omission that weakens the central claim. We will add a dedicated subsection (likely in Section 3 or 4) that provides: (1) a formal definition of the sandbox boundary as a tuple of the six measurement dimensions with explicit containment predicates; (2) the weakest-link rule stated as a composition operator over evidence tuples, with the rule that the overall deployment claim is bounded by the minimum strength across dimensions; and (3) a non-circular validation procedure that applies the operator to the three case studies by mapping each dimension's evidence to a bounded claim and showing the resulting composite bound. This addition will be cross-referenced back to the abstract. revision: yes
Circularity Check
No significant circularity; framework is definitional with independent content
full rationale
The paper develops a threat model, taxonomy, and measurement framework by formalizing a sandbox boundary and weakest-link rule for evidence composition, then instantiating on case studies. No quoted equations or steps reduce any claimed prediction or first-principles result to its own inputs by construction. No fitted parameters are renamed as predictions, no load-bearing self-citations justify uniqueness theorems, and no ansatz is smuggled via prior work. The central claims rest on the introduced formalization and measurement dimensions rather than self-referential reduction, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The weakest-link rule validly composes per-dimension evidence into a bounded deployment claim.
invented entities (2)
-
Sandbox boundary
no independent evidence
-
Weakest-link rule
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chuadhry Mujeeb Ahmed, Venkata Reddy Palleti, and Aditya P. Mathur. 2017. WADI: A Water Distribution Testbed for Research in the Design of Secure Cyber Physical Systems. InProceedings of the 3rd International Workshop on Cyber-Physical Systems for Smart Water Networks. ACM, New York, NY, USA, 25-28. doi:10.1145/3055366.3055375
-
[2]
Cristina Alcaraz and Javier Lopez. 2022. Digital Twin: A Comprehensive Survey of Security Threats.IEEE Communications Surveys & Tutorials 24, 3 (2022), 1475-1503. doi:10.1109/COMST.2022.3171465
-
[3]
Hilary J. Allen. 2019. Regulatory Sandboxes.George Washington Law Review87, 3 (2019), 579-645. https://www.gwlr.org/wp-content/uploads/ 2019/06/87-Geo.-Wash.-L.-Rev.-579.pdf
2019
-
[4]
Mohammed Alshiekh, Roderick Bloem, Rüdiger Ehlers, Bettina Könighofer, Scott Niekum, and Ufuk Topcu. 2018. Safe Reinforcement Learning via Shielding. InProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence. AAAI Press, New Orleans, Louisiana, USA, 2669-2678. doi:10.1609/aaai.v32i1.11797
-
[5]
Amazon Web Services. 2026. AWS IoT TwinMaker Documentation. https://docs.aws.amazon.com/iot-twinmaker/ Accessed 17 May 2026
2026
-
[6]
Aaron D. Ames, Xiangru Xu, Jessy W. Grizzle, and Paulo Tabuada. 2017. Control Barrier Function Based Quadratic Programs for Safety Critical Systems.IEEE Trans. Automat. Control62, 8 (2017), 3861-3876. doi:10.1109/TAC.2016.2638961
-
[7]
Yashwanth Annpureddy, Che Liu, Georgios Fainekos, and Sriram Sankaranarayanan. 2011. S-TaLiRo: A Tool for Temporal Logic Falsification for Hybrid Systems. InProceedings of TACAS. 254-257
2011
-
[8]
ASAM e.V. 2026. ASAM OpenSCENARIO DSL. https://www.asam.net/standards/detail/openscenario-dsl/ Accessed 30 April 2026
2026
-
[9]
2018.ASME V&V 40-2018
ASME. 2018.ASME V&V 40-2018. American Society of Mechanical Engineers. https://www.asme.org/codes-standards Assessing Credibility of Computational Modeling through Verification and Validation: Application to Medical Devices; official ASME standard metadata page, accessed 17 May 2026
2018
-
[10]
Autonomous Vehicle Systems Laboratory. 2026. Basilisk: Astrodynamics Simulation Framework. https://avslab.github.io/basilisk/ Accessed 17 May 2026
2026
-
[11]
Colby Banbury, Vijay Janapa Reddi, Peter Torelli, Jeremy Holleman, Nat Jeffries, Csaba Király, Pietro Montino, David Kanter, Sebastian Ahmed, Danilo Pau, Urmish Thakker, Antonio Torrini, Peter Warden, Jay Cordaro, Giuseppe Di Guglielmo, Javier Duarte, Stephen Jia, Honson Tran, Nhan Tran, Niu Wenxu, and Xu Xuesong. 2021. MLPerf Tiny Benchmark. Proceedings ...
2021
-
[12]
Barbara Rita Barricelli, Elena Casiraghi, and Daniela Fogli. 2019. A Survey on Digital Twin: Definitions, Characteristics, Applications, and Design Implications.IEEE Access7 (2019), 167653-167671. doi:10.1109/ACCESS.2019.2953499
-
[13]
Jeffrey J. Biesiadecki, P. Chris Leger, and Mark W. Maimone. 2007. Tradeoffs Between Directed and Autonomous Driving on the Mars Exploration Rovers.The International Journal of Robotics Research26, 1 (2007), 91-104. doi:10.1177/0278364907073777
-
[14]
Battista Biggio, Blaine Nelson, and Pavel Laskov. 2012. Poisoning Attacks against Support Vector Machines. InProceedings of the 29th International Conference on Machine Learning (ICML’12). Omnipress, Edinburgh, Scotland, 1467-1474. https://icml.cc/2012/papers/880.pdf
2012
-
[15]
Blattnig, Lawrence L
Steve R. Blattnig, Lawrence L. Green, James M. Luckring, Joseph H. Morrison, Ram K. Tripathi, and Thomas A. Zang. 2008. Towards a Credibility Assessment of Models and Simulations. In10th AIAA Non-Deterministic Approaches Conference. Schaumburg, IL. https://ntrs.nasa.gov/citations/ 20080015742 NASA NTRS Document ID 20080015742
2008
-
[16]
Robin Bloomfield and Peter Bishop. 2010. Safety and Assurance Cases: Past, Present and Possible Future - an Adelard Perspective.Proceedings of the 18th Safety-Critical Systems Symposium(2010), 51-67. doi:10.1007/978-1-84996-086-1_4
-
[17]
Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth
Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H. Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. 2017. Practical Secure Aggregation for Privacy-Preserving Machine Learning. InProceedings of the ACM Conference on Computer and Communications Security (CCS). 1175-1191
2017
-
[18]
Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, and D. Sculley. 2017. The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction. In2017 IEEE International Conference on Big Data. IEEE, Piscataway, NJ, USA, 1123-1132. doi:10.1109/BigData.2017.8258038
-
[19]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. 2023. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. arXiv preprint arXiv:2307.15818. https://arxiv.org/abs/2307.15818 AI Sandboxes 43
Pith/arXiv arXiv 2023
-
[20]
Alessio Buscemi, Thibault Simonetto, Daniele Pagani, German Castignani, Maxime Cordy, and Jordi Cabot. 2025. The Sandbox Configurator: A Framework to Support Technical Assessment in AI Regulatory Sandboxes. arXiv preprint arXiv:2509.25256. https://arxiv.org/abs/2509.25256
arXiv 2025
-
[21]
Yulong Cao, Chaowei Xiao, Benjamin Cyr, Yimeng Zhou, Won Park, Sara Rampazzi, Qi Alfred Chen, Kevin Fu, and Z. Morley Mao. 2019. Adver- sarial Sensor Attack on LiDAR-Based Perception in Autonomous Driving. InProceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security. ACM, New York, NY, USA, 2267-2281. doi:10.1145/3319535.3339815
-
[22]
Cárdenas, Saurabh Amin, and Shankar Sastry
Alvaro A. Cárdenas, Saurabh Amin, and Shankar Sastry. 2008. Secure Control: Towards Survivable Cyber-Physical Systems. InProceedings of the 28th International Conference on Distributed Computing Systems Workshops. 495-500
2008
-
[23]
CARLA Simulator Team. 2026. CARLA Autonomous Driving Simulator. https://carla.org/ Accessed 10 May 2026
2026
-
[24]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. 2024. A Survey on Evaluation of Large Language Models.ACM Transactions on Intelligent Systems and Technology15, 3 (2024). doi:10.1145/3641289
-
[25]
Léo Cosseron, Louis Rilling, Matthieu Simonin, and Martin Quinson. 2024. Simulating the Network Environment of Sandboxes to Hide Virtual Machine Introspection Pauses. InProceedings of the 17th European Workshop on Systems Security. ACM, New York, NY, USA, 1-7. doi:10.1145/ 3642974.3652280
arXiv 2024
-
[26]
Jonathan Crussell, Jeremy Erickson, David Fritz, and John Floren. 2016. minimega v. 3.0. doi:10.11578/dc.20171025.1714
-
[27]
Das, Mohammad Helal Uddin, and Sabur Baidya
Sumit K. Das, Mohammad Helal Uddin, and Sabur Baidya. 2022. Edge-Assisted Collaborative Digital Twin for Safety-Critical Robotics in Industrial IoT. arXiv preprint arXiv:2209.12854. https://arxiv.org/abs/2209.12854
arXiv 2022
-
[28]
Harm de Vries, Dzmitry Bahdanau, and Christopher Manning. 2020. Towards Ecologically Valid Research on Language User Interfaces. arXiv preprint arXiv:2007.14435. https://arxiv.org/abs/2007.14435
arXiv 2020
-
[29]
Tom Deckenbrunnen, Alessio Buscemi, Marco Almada, Alfredo Capozucca, and German Castignani. 2026. Bathtubs, Boundaries, and Sandboxes: AI Regulatory Learning under Legal Uncertainty. arXiv preprint arXiv:2601.04094. https://arxiv.org/abs/2601.04094
Pith/arXiv arXiv 2026
-
[30]
Ewen Denney and Ganesh Pai. 2018. Tool Support for Assurance Case Development.Automated Software Engineering25, 3 (2018), 435-499. doi:10.1007/s10515-017-0230-5
-
[31]
Wenhao Ding, Chejian Xu, Mansur Arief, Haohong Lin, Bo Li, and Ding Zhao. 2023. A Survey on Safety-Critical Driving Scenario Generation - a Methodological Perspective.IEEE Transactions on Intelligent Transportation Systems24, 7 (2023), 6971-6988
2023
-
[32]
Jesse Dodge, Suchin Gururangan, Dallas Card, Roy Schwartz, and Noah A. Smith. 2019. Show Your Work: Improved Reporting of Experimental Results. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Ling...
-
[33]
Alexandre Donzé. 2010. Breach, a Toolbox for Verification and Parameter Synthesis of Hybrid Systems. InProceedings of CA V. 167-170
2010
-
[34]
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. 2017. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning (Proceedings of Machine Learning Research, Vol. 78), Sergey Levine, Vincent Vanhoucke, and Ken Goldberg (Eds.). PMLR, Mountain View, CA, USA, 1-16. https://proceedi...
2017
-
[35]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. 2023. PaLM-E: An Embodied Multimodal Language Model. arXiv preprint arXiv:2303.03378. https://arxiv.org/abs/2303.03378
Pith/arXiv arXiv 2023
-
[36]
Yuqing Du, Olivia Watkins, Trevor Darrell, Pieter Abbeel, and Deepak Pathak. 2021. Auto-Tuned Sim-to-Real Transfer. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA). IEEE, Piscataway, NJ, USA, 1290-1296. doi:10.1109/ICRA48506.2021.9562091
-
[37]
Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, and Cheston Tan. 2022. A Survey of Embodied AI: From Simulators to Research Tasks.IEEE Transactions on Emerging Topics in Computational Intelligence6, 2 (April 2022), 230-244. doi:10.1109/TETCI.2022.3141105
-
[38]
Eclipse Foundation. 2026. Eclipse Ditto Documentation. https://eclipse.dev/ditto/ Accessed 17 May 2026
2026
-
[39]
Asher Elmquist, Radu Serban, and Dan Negrut. 2025. A Methodology to Quantify Simulation-Versus-Reality Differences in Images for Autonomous Robots.IEEE Sensors Journal25, 4 (2025), 6522-6533. doi:10.1109/JSEN.2024.3522050
-
[40]
Jeremy P Erickson and James H Anderson. 2022. Soft real-time scheduling. InHandbook of Real-Time Computing. Springer, Cham, Switzerland, 233-267. https://link.springer.com/rwe/10.1007/978-981-287-251-7_4
-
[41]
European Parliament and Council of the European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence. Official Journal of the European Union. https://eur-lex.europa.eu/eli/reg/ 2024/1689/oj/eng
2024
-
[42]
European Telecommunications Standards Institute. 2024. ETSI EN 303 645 V3.1.3: Cyber Security for Consumer Internet of Things: Baseline Requirements. https://www.etsi.org/deliver/etsi_en/303600_303699/303645/03.01.03_60/en_303645v030103p.pdf Accessed 30 April 2026
2024
-
[43]
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. 2018. Robust Physical-World Attacks on Deep Learning Visual Classification. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, Piscataway, NJ, USA, 1625-1634. doi:10.1109/CVPR.2018.00175
-
[44]
Megas, Karen Scarfone, and Matthew Smith
Michael Fagan, Katerina N. Megas, Karen Scarfone, and Matthew Smith. 2020.IoT Device Cybersecurity Capability Core Baseline. Technical Report NISTIR 8259A. National Institute of Standards and Technology. doi:10.6028/NIST.IR.8259A
-
[45]
Financial Conduct Authority. 2015. Regulatory Sandbox. FCA Research Paper. https://www.fca.org.uk/publication/research/regulatory-sandbox. pdf 44 Singh, Mahmoud, and Murillo
2015
-
[46]
2017.Regulatory Sandbox Lessons Learned Report
Financial Conduct Authority. 2017.Regulatory Sandbox Lessons Learned Report. Technical Report. Financial Conduct Authority. https://www. fca.org.uk/publication/research-and-data/regulatory-sandbox-lessons-learned-report.pdf Accessed 17 May 2026
2017
-
[48]
João Gama, Indr ˙e Žliobait ˙e, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. 2014. A Survey on Concept Drift Adaptation.Comput. Surveys46, 4 (2014), 44:1-44:37
2014
-
[49]
Tal Garfinkel and Mendel Rosenblum. 2003. A Virtual Machine Introspection Based Architecture for Intrusion Detection. InProceedings of the Network and Distributed System Security Symposium. Internet Society, Reston, VA, USA, 191-206. https://www.ndss-symposium.org/ndss2003/ virtual-machine-introspection-based-architecture-intrusion-detection/
2003
-
[50]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé, and Kate Crawford. 2021. Datasheets for Datasets.Commun. ACM64, 12 (2021), 86-92. doi:10.1145/3458723
-
[51]
Jairo Giraldo, David I. Urbina, Alvaro Cárdenas, Junia Valente, Mustafa Amir Faisal, Justin Ruths, Nils Ole Tippenhauer, Henrik Sandberg, and Richard Candell. 2018. A Survey of Physics-Based Attack Detection in Cyber-Physical Systems.Comput. Surveys51, 4, Article 76 (2018), 36 pages. doi:10.1145/3203245
-
[52]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security. ACM, New York, NY, USA, 79-90. doi:10.1145/3605764.3623985
-
[53]
Hahn and Robert E
Adam S. Hahn and Robert E. Fasano. 2021.OT Emulation Data Broker (SCEPTRE Capability). Technical Report. Sandia National Laboratories. https://www.sandia.gov/emulytics/
2021
-
[54]
Health and Safety Executive. 2026. HSE’s Regulatory Approach to Artificial Intelligence (AI). https://www.hse.gov.uk/news/hse-ai.htm. Accessed 17 May 2026
2026
-
[55]
HELICS Project. 2026. HELICS Co-Simulation Framework. https://helics.org/ Accessed 10 May 2026
2026
-
[56]
Brian Ichter, Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, et al. 2023. Do As I Can, Not As I Say: Grounding Language in Robotic Affordances. InProceedings of the 6th Conference on Robot Learning (Proceedings of Machine Learning Research, Vol. 205). PMLR, Auckland, New Zeal...
2023
-
[57]
2010.IEC 61508: Functional Safety of Electrical/Electronic/Programmable Electronic Safety-Related Systems(2nd ed.)
International Electrotechnical Commission. 2010.IEC 61508: Functional Safety of Electrical/Electronic/Programmable Electronic Safety-Related Systems(2nd ed.). https://www.iec.ch/functionalsafety/standards Parts 1-7
2010
-
[58]
International Electrotechnical Commission. 2026. ISA/IEC 62443 series: Industrial communication networks - Network and system security. https://www.iec.ch/cyber-security-sector Accessed 30 April 2026
2026
-
[59]
2018.ISO 26262: Road Vehicles - Functional Safety(2nd ed.)
International Organization for Standardization. 2018.ISO 26262: Road Vehicles - Functional Safety(2nd ed.). https://www.iso.org/standard/68383. html Parts 1-12
2018
-
[60]
2022.ISO 21448: Road Vehicles - Safety of the Intended Functionality (SOTIF)
International Organization for Standardization. 2022.ISO 21448: Road Vehicles - Safety of the Intended Functionality (SOTIF). https://www.iso.org/ standard/77490.html
2022
-
[61]
International Organization for Standardization. 2023. ISO/IEC 23894:2023 Information technology - Artificial intelligence - Guidance on risk management. https://www.iso.org/standard/77304.html
2023
-
[62]
International Organization for Standardization. 2023. ISO/IEC 42001:2023 Information technology - Artificial intelligence - Management system. https://www.iso.org/standard/42001
2023
-
[63]
2021.ISO/SAE 21434: Road Vehicles - Cybersecurity Engineering
International Organization for Standardization and SAE International. 2021.ISO/SAE 21434: Road Vehicles - Cybersecurity Engineering. https: //www.iso.org/standard/70918.html
2021
-
[64]
Abigail Z. Jacobs and Hanna Wallach. 2021. Measurement and Fairness. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT). ACM, New York, NY, USA, 375-385. doi:10.1145/3442188.3445901
-
[65]
David Jones, Chris Snider, Aydin Nassehi, Jason Yon, and Ben Hicks. 2020. Characterising the Digital Twin: A Systematic Literature Review.CIRP Journal of Manufacturing Science and Technology29 (2020), 36-52. doi:10.1016/j.cirpj.2020.02.002
-
[66]
Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al
Peter Kairouz, H. Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. 2021. Advances and Open Problems in Federated Learning.Foundations and Trends in Machine Learning14, 1-2 (2021), 1-210
2021
-
[67]
Nidhi Kalra and Susan M. Paddock. 2016. Driving to Safety: How Many Miles of Driving Would It Take to Demonstrate Autonomous Vehicle Reliability?Transportation Research Part A: Policy and Practice94 (2016), 182-193. doi:10.1016/j.tra.2016.09.010
-
[68]
Prabhjot Kaur, Samira Taghavi, Zhaofeng Tian, and Weisong Shi. 2021. A Survey on Simulators for Testing Self-Driving Cars. In2021 Fourth International Conference on Connected and Autonomous Driving (MetroCAD). IEEE, Piscataway, NJ, USA, 62-70. doi:10.1109/MetroCAD51599.2021. 00018
-
[69]
Tim Kelly and Rob Weaver. 2004. The Goal Structuring Notation: A Safety Argument Notation. InProceedings of the Dependable Systems and Networks Workshop on Assurance Cases. IEEE Computer Society, Florence, Italy, 1-6. https://www-users.cs.york.ac.uk/~tpk/dsn2004.pdf
2004
-
[70]
Kenneally, Scott Piggott, and Hanspeter Schaub
Patrick W. Kenneally, Scott Piggott, and Hanspeter Schaub. 2020. Basilisk: A Flexible, Scalable and Modular Astrodynamics Simulation Framework. Journal of Aerospace Information Systems17, 9 (2020), 496-507. doi:10.2514/1.I010762 AI Sandboxes 45
-
[71]
2007.Guidelines for performing Systematic Literature Reviews in Software Engineering
Barbara Kitchenham and Stuart Charters. 2007.Guidelines for performing Systematic Literature Reviews in Software Engineering. Technical Report EBSE 2007-001. Keele University and Durham University Joint Report. https://ebse.webspace.durham.ac.uk/ebse-bibliography/guidelines-for- performing-systematic-literature-reviews-in-software-engineering/
2007
-
[72]
Nathan Koenig and Andrew Howard. 2004. Design and use paradigms for Gazebo, an open-source multi-robot simulator. In2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No. 04CH37566), Vol. 3. IEEE, Piscataway, NJ, USA, 2149-2154. doi:10. 1109/IROS.2004.1389727
arXiv 2004
-
[73]
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, Aniruddha Kembhavi, Abhinav Gupta, and Ali Farhadi. 2017. AI2-THOR: An Interactive 3D Environment for Visual AI. arXiv preprint arXiv:1712.05474. https://arxiv.org/abs/1712.05474
Pith/arXiv arXiv 2017
-
[74]
Philip Koopman and Michael Wagner. 2017. Autonomous Vehicle Safety: An Interdisciplinary Challenge.IEEE Intelligent Transportation Systems Magazine9, 1 (2017), 90-96. doi:10.1109/MITS.2016.2583491
-
[75]
Edward A. Lee. 2008. Cyber Physical Systems: Design Challenges. In2008 11th IEEE International Symposium on Object and Component-Oriented Real-Time Distributed Computing. IEEE, Piscataway, NJ, USA, 363-369. doi:10.1109/ISORC.2008.25
-
[76]
Nancy G. Leveson. 2011.Engineering a Safer World: Systems Thinking Applied to Safety. MIT Press, Cambridge, MA
2011
-
[77]
Guanpeng Li, Yiran Li, Saurabh Jha, Timothy Tsai, Michael Sullivan, Siva Kumar Sastry Hari, Zbigniew Kalbarczyk, and Ravishankar Iyer. 2020. AV-FUZZER: Finding Safety Violations in Autonomous Driving Systems. InProceedings of the 31st IEEE International Symposium on Software Reliability Engineering (ISSRE). 25-36
2020
-
[78]
Guowen Li, Zhiyao Yang, Yangyang Fu, Lingyu Ren, Zheng O’Neill, and Chirag Parikh. 2022. Development of a Hardware-in-the-Loop (HIL) Testbed for Cyber-Physical Security in Smart Buildings. arXiv preprint arXiv:2210.11234. https://arxiv.org/abs/2210.11234
arXiv 2022
-
[79]
Percy Liang, Rishi Bommasani, Tony Lee, et al. 2023. Holistic Evaluation of Language Models. Transactions on Machine Learning Research; arXiv:2211.09110. https://arxiv.org/abs/2211.09110
Pith/arXiv arXiv 2023
-
[80]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang
-
[81]
The Twelfth International Conference on Learning Representations
AgentBench: Evaluating LLMs as Agents. The Twelfth International Conference on Learning Representations. https://openreview.net/ forum?id=zAdUB0aCTQ
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.