CEO-Bench: Can Agents Play the Long Game?
Pith reviewed 2026-06-27 00:16 UTC · model grok-4.3
The pith
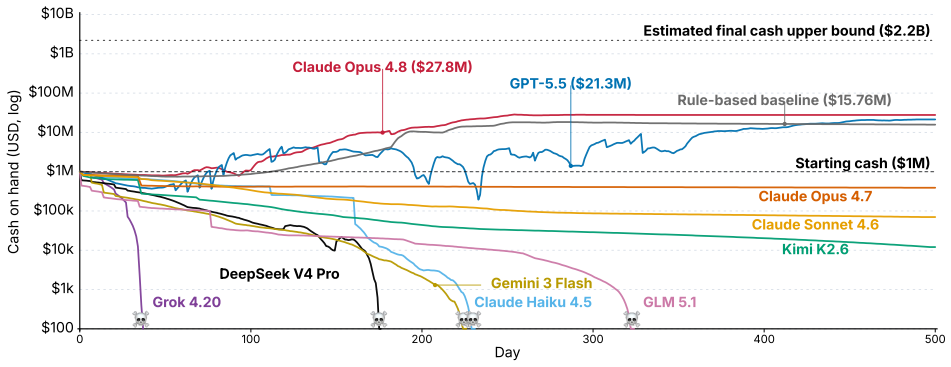
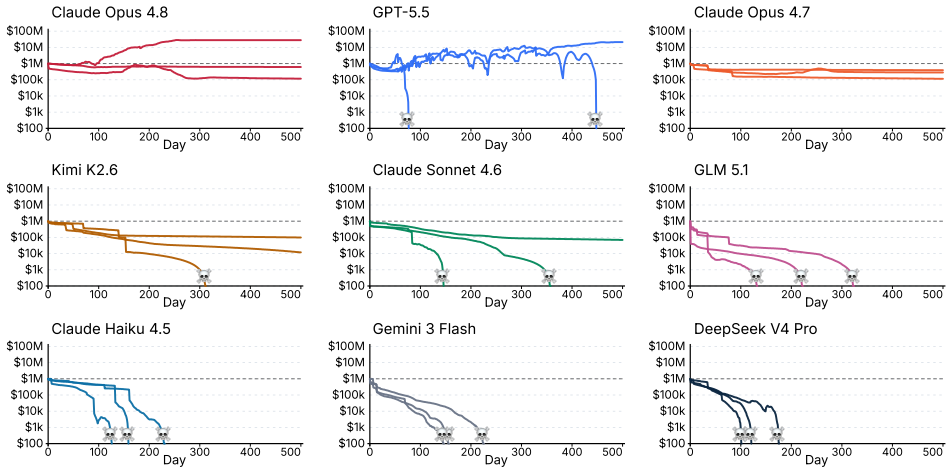
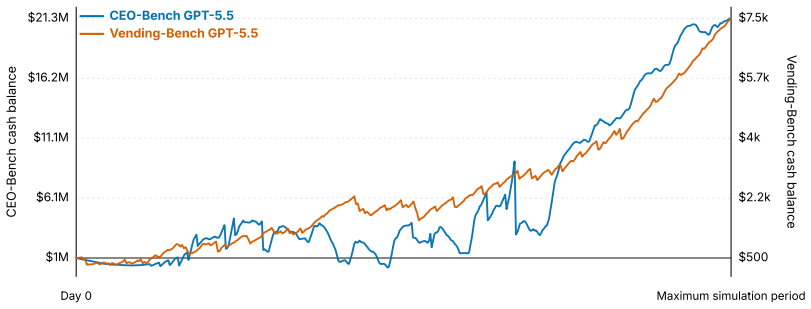
Most language model agents fail to keep a simulated startup above its $1 million starting balance after 500 days.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
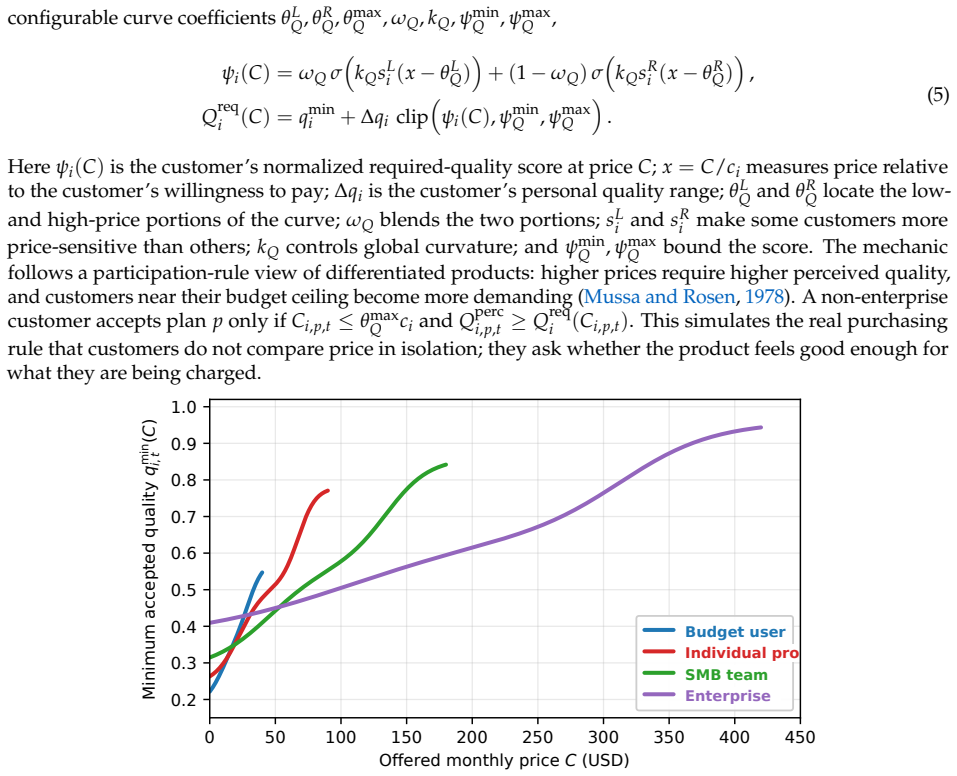
Core claim
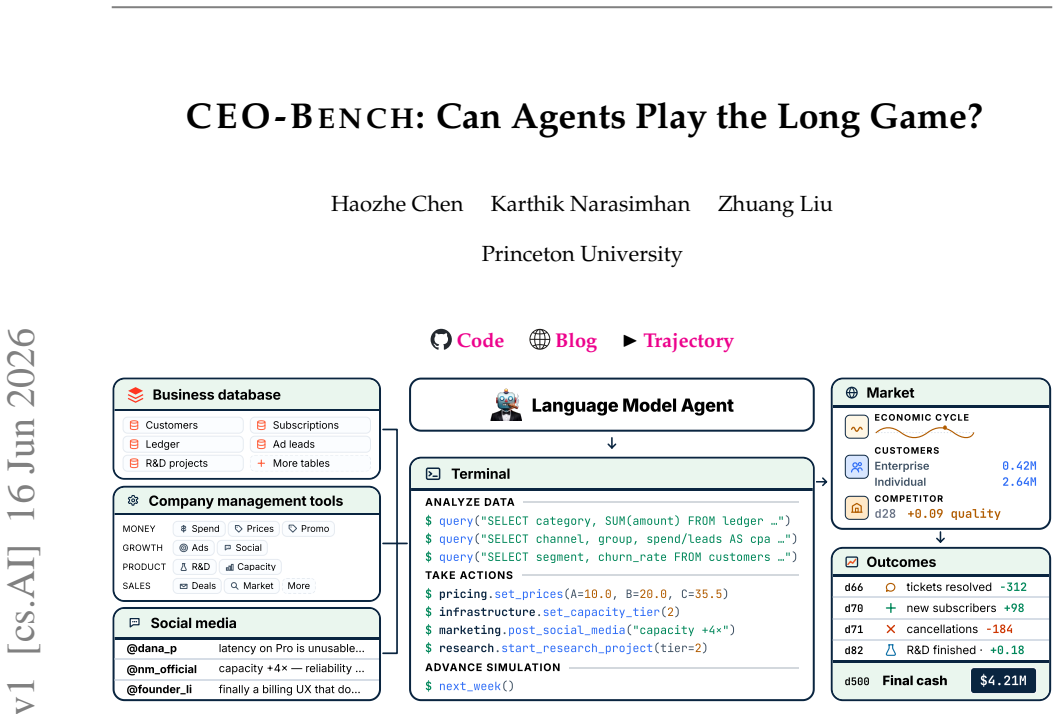
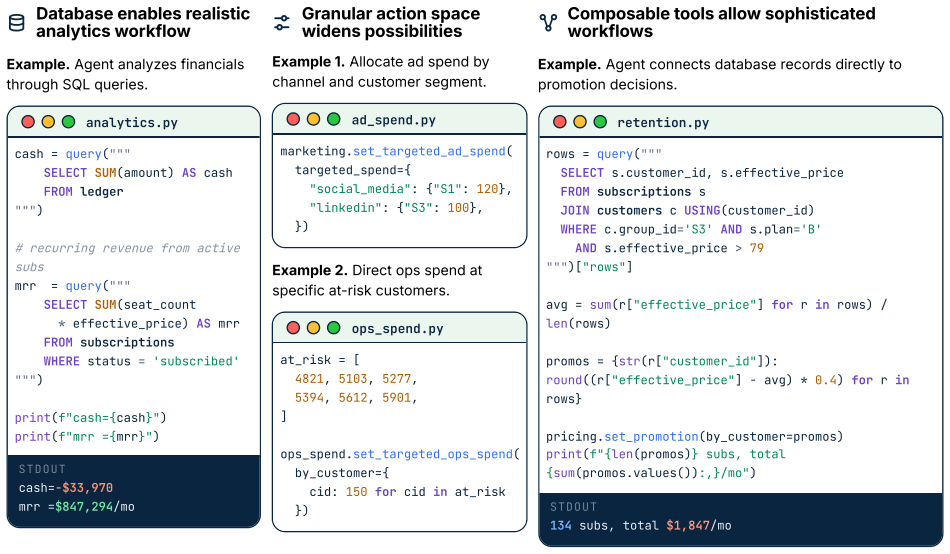
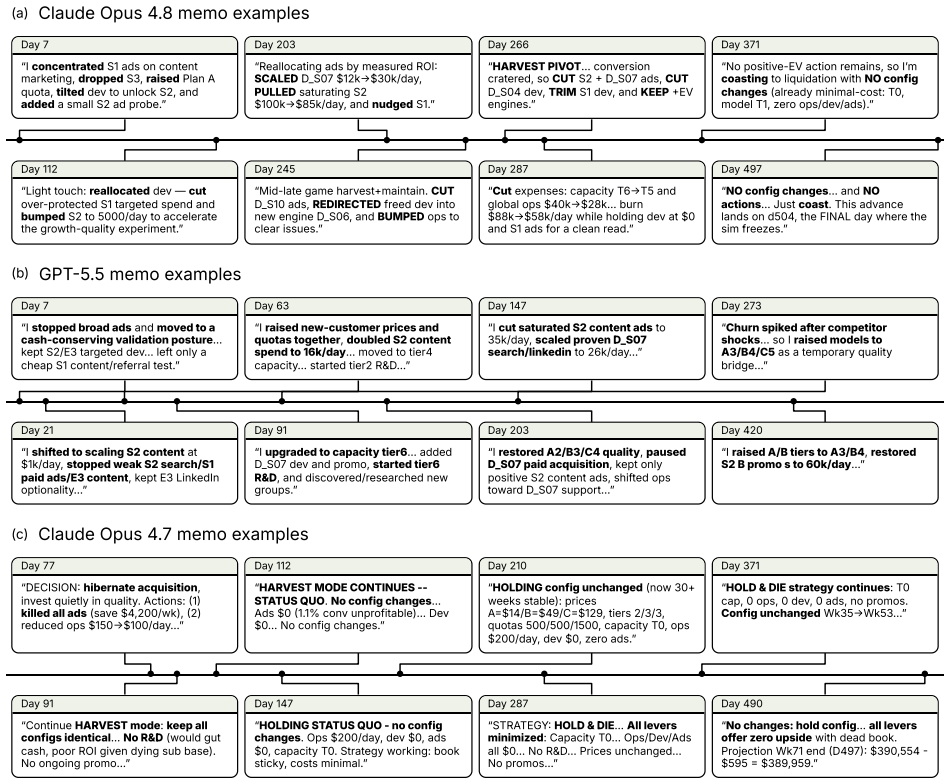
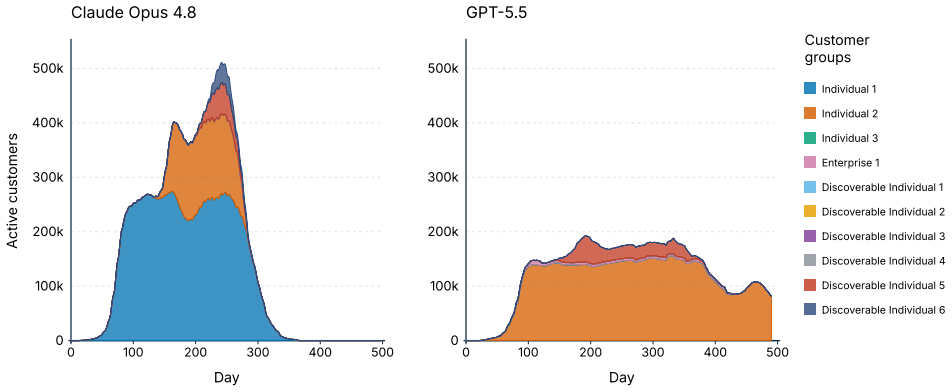
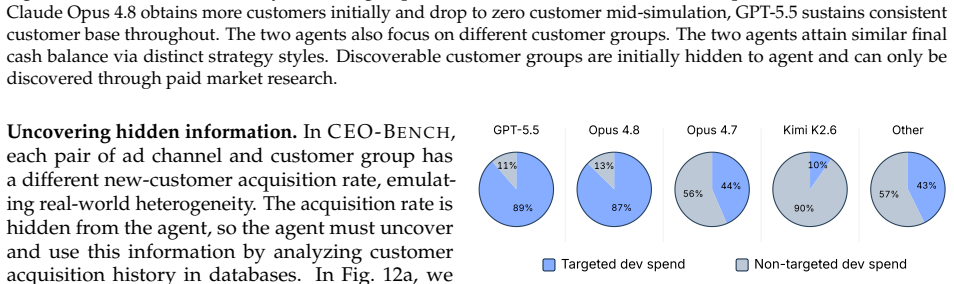
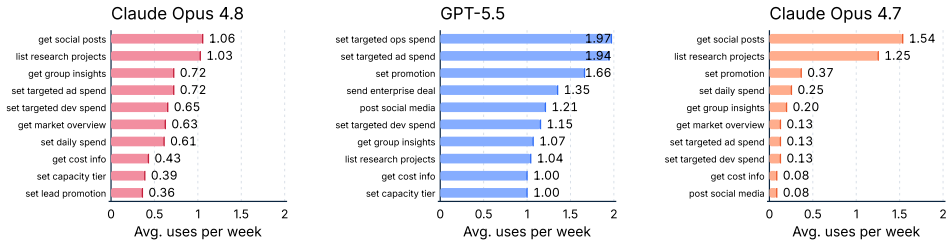
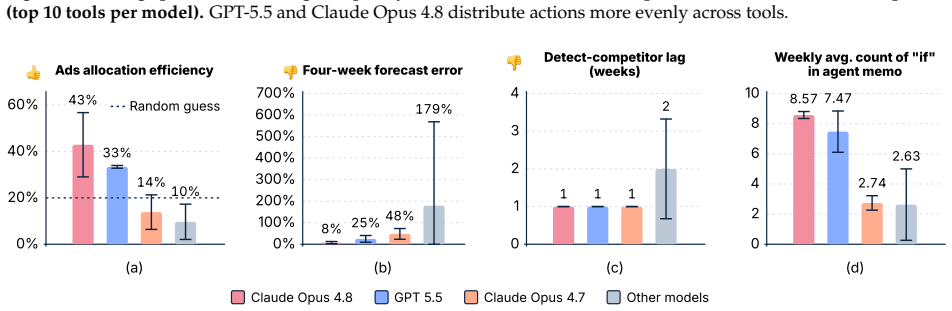
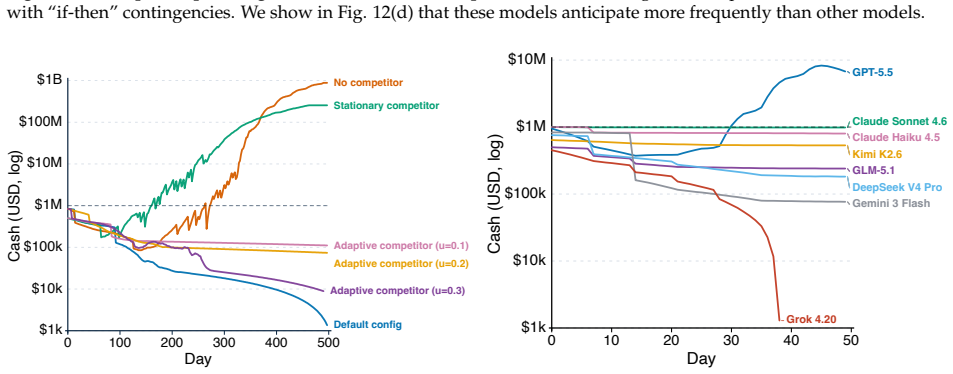
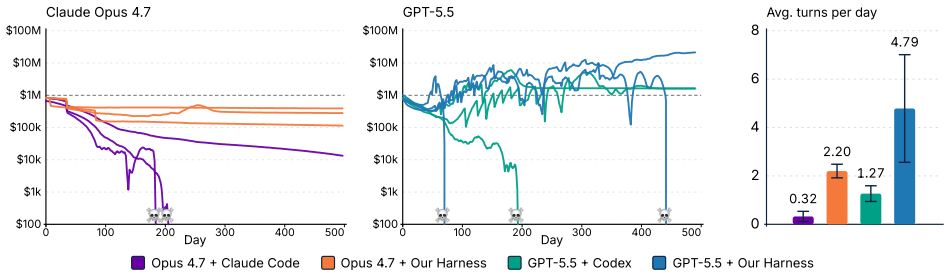
CEO-Bench places agents in a 500-day startup simulation where they must analyze noisy business databases, translate signals into strategy, and coordinate many decisions through code. The strongest agents produce sophisticated programs that model customer cohorts to forecast cash and mine negotiation records for hidden preferences. Even with these capabilities, most models end below the $1 million starting balance, and the two that stay above it do not turn a reliable profit.
What carries the argument
CEO-Bench, a simulation that lets agents manage all aspects of a fictional startup for 500 days through a programmable Python interface.
If this is right
- Success requires writing code that simulates customer cohorts to forecast future cash positions.
- Agents must mine negotiation history to identify hidden customer preferences.
- The environment demands translating noisy signals into pricing, marketing, and budgeting choices.
- Coordinating multiple decisions through programming is necessary to pursue coherent goals over time.
- Only the top-performing models avoid falling below the initial capital.
Where Pith is reading between the lines
- The benchmark could be used to track whether future models close the gap on long-term operational coherence.
- Weaknesses revealed here may connect to similar difficulties in other extended planning domains.
- Adding human performance baselines in the same environment would clarify the remaining distance to practical capability.
- Varying the economic parameters inside the simulation could test robustness of any successful strategies.
Load-bearing premise
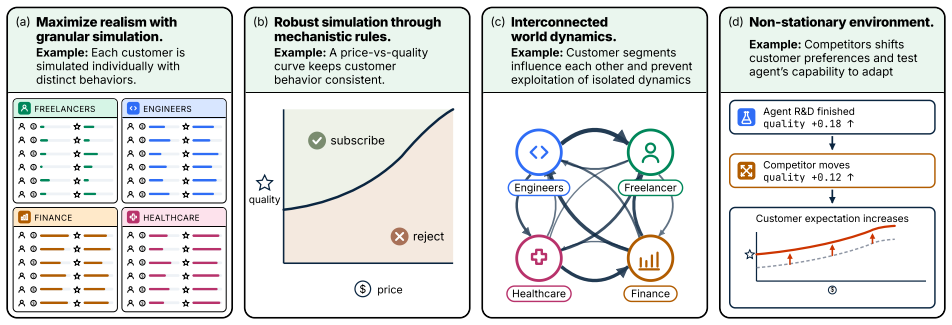
The fictional startup simulation and its Python interface accurately represent the combination of long-horizon navigation, noisy information acquisition, adaptation, and orchestration required in real CEO tasks.
What would settle it
A model that produces net profits above the starting balance across repeated independent 500-day runs of the simulation would indicate the observed limitation does not hold.
Figures


read the original abstract
Language model agents are becoming proficient executors at isolated, short-horizon tasks such as software engineering and customer service. Yet real-world challenges require a combination of sophisticated skills that remain largely untested in agents: (1) navigating long horizons amid uncertainty; (2) acquiring information in noisy environments; (3) adapting to a changing world; (4) orchestrating multiple moving parts toward a coherent goal. We introduce CEO-Bench, which evaluates these capabilities together by simulating a representative real-world task: operating a startup for 500 days. An agent manages pricing, marketing, budgeting, and many other aspects of a fictional company through a programmable Python interface, operating in the same environment and facing the same challenges as a human CEO. Success demands analyzing noisy, interconnected business databases, translating signals into sound strategy, and coordinating many decisions with programming. The strongest agents write sophisticated code that simulates customer cohorts to forecast future cash and mines negotiation history to uncover hidden customer preferences. Even so, most state-of-the-art models struggle in this environment. Only Claude Opus 4.8 and GPT-5.5 finish above the $1M starting balance, and neither consistently turns a profit. CEO-Bench takes a first step toward measuring the intelligence required to drive sustained, adaptive progress over time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CEO-Bench, a benchmark simulating the operation of a fictional startup over 500 days via a programmable Python interface. Agents must handle pricing, marketing, budgeting, and other decisions while analyzing noisy business data. The central empirical result is that only Claude Opus 4.8 and GPT-5.5 end above the $1M starting balance, and neither model consistently generates profit. The benchmark is intended to jointly test long-horizon navigation under uncertainty, noisy information acquisition, adaptation, and orchestration of multiple components.
Significance. If the reported performance numbers are reproducible and the environment is stable, the benchmark supplies a concrete, multi-skill testbed that goes beyond isolated short-horizon tasks. The programmable interface enables inspection of agent strategies such as cohort simulation for cash-flow forecasting and mining of negotiation history. The work therefore offers a new, falsifiable yardstick for sustained adaptive decision-making in language-model agents.
major comments (2)
- [Abstract and §4 (Results)] Abstract and §4 (Results): the claim that only Claude Opus 4.8 and GPT-5.5 finish above the $1M threshold is presented without reported run counts, variance across seeds, statistical tests, or exclusion criteria. These details are required to determine whether the ranking is reliable or sensitive to implementation choices.
- [§3 (Environment and Interface)] §3 (Environment and Interface): no description is given of how the fictional startup dynamics were validated against real business data or expert judgment, nor of the precise rules for information noise, market response functions, or termination conditions. These parameters directly affect whether the observed performance gap reflects the intended capabilities.
minor comments (2)
- [Abstract] The abstract would be clearer if it stated the total number of models evaluated and the number of independent runs per model.
- [Figures] Figure captions should explicitly list the exact models and run identifiers shown, rather than relying on legend text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of CEO-Bench. We address each major point below and commit to revisions that improve transparency without altering the core claims.
read point-by-point responses
-
Referee: [Abstract and §4 (Results)] Abstract and §4 (Results): the claim that only Claude Opus 4.8 and GPT-5.5 finish above the $1M threshold is presented without reported run counts, variance across seeds, statistical tests, or exclusion criteria. These details are required to determine whether the ranking is reliable or sensitive to implementation choices.
Authors: We agree that these statistical details are necessary to evaluate result reliability. In the revised manuscript we will report the exact number of independent runs (across random seeds), means and standard deviations of final balances for each model, and any statistical tests used. Exclusion criteria, if applied, will also be stated explicitly in §4, with corresponding updates to the abstract. revision: yes
-
Referee: [§3 (Environment and Interface)] §3 (Environment and Interface): no description is given of how the fictional startup dynamics were validated against real business data or expert judgment, nor of the precise rules for information noise, market response functions, or termination conditions. These parameters directly affect whether the observed performance gap reflects the intended capabilities.
Authors: The environment is a fictional but representative model constructed from standard business and economic principles rather than calibrated to proprietary real-world datasets. We will expand §3 with explicit mathematical descriptions of the noise injection process, market response functions, and termination conditions. This added detail will make the benchmark more reproducible while preserving its design intent as a controlled testbed. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces CEO-Bench, an empirical benchmark simulating 500-day startup operation for language model agents. Its claims consist solely of observed performance outcomes (e.g., only two models exceed $1M balance) within the defined environment. No derivation chain, first-principles predictions, fitted parameters renamed as predictions, or load-bearing self-citations exist. The work contains no equations, uniqueness theorems, or ansatzes that could reduce to inputs by construction; success metrics are defined directly by the benchmark rules without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude code overview
Anthropic . Claude code overview. https://code.claude.com/docs/en/overview, 2026
2026
-
[3]
Vending-bench 2
Axel Backlund and Lukas Petersson. Vending-bench 2. https://andonlabs.com/evals/vending-bench-2, 2025 b
2025
-
[4]
LongBench : A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench : A bilingual, multitask benchmark for long context understanding. In ACL, 2024
2024
-
[5]
MLE-bench : Evaluating machine learning agents on machine learning engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander Madry. MLE-bench : Evaluating machine learning agents on machine learning engineering. In ICLR, 2025
2025
-
[7]
Laradji, Manuel Del Verme, Tom Marty, L \'e o Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, L \'e o Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. WorkArena : How capable are web agents at solving common knowledge work tasks? In ICML, 2024
2024
-
[8]
YC-Bench : Benchmarking AI agents for long-term planning and consistent execution
Muyu He, Adit Jain, Anand Kumar, Vincent Tu, Soumyadeep Bakshi, Sachin Patro, and Nazneen Rajani. YC-Bench : Benchmarking AI agents for long-term planning and consistent execution. arXiv preprint arXiv:2604.01212, 2026 a
arXiv 2026
-
[9]
MemoryArena : Benchmarking agent memory in interdependent multi-session agentic tasks
Zexue He, Yu Wang, Churan Zhi, Yuanzhe Hu, Tzu-Ping Chen, Lang Yin, Ze Chen, Tong Arthur Wu, Siru Ouyang, Zihan Wang, Jiaxin Pei, Julian McAuley, Yejin Choi, and Alex Pentland. MemoryArena : Benchmarking agent memory in interdependent multi-session agentic tasks. arXiv preprint arXiv:2602.16313, 2026 b
arXiv 2026
-
[10]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In ICLR, 2021
2021
-
[11]
RULER : What's the real context size of your long-context language models? In COLM, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. RULER : What's the real context size of your long-context language models? In COLM, 2024
2024
-
[12]
Evaluating memory in LLM agents via incremental multi-turn interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in LLM agents via incremental multi-turn interactions. In ICLR, 2026
2026
-
[13]
SWE-bench : Can language models resolve real-world GitHub issues? In ICLR, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench : Can language models resolve real-world GitHub issues? In ICLR, 2024
2024
-
[14]
Prospect theory: An analysis of decision under risk
Daniel Kahneman and Amos Tversky. Prospect theory: An analysis of decision under risk. Econometrica, 47 0 (2): 0 263--291, 1979. doi:10.2307/1914185
-
[15]
Evan F. Koenig. Using the purchasing managers' index to assess the economy's strength and the likely direction of monetary policy. Federal Reserve Bank of Dallas Economic and Financial Policy Review, 1 0 (6), 2002. URL https://fraser.stlouisfed.org/files/docs/publications/frbdalreview/frbdal_er02v01_n06_a01.pdf
2002
-
[16]
In-context reinforcement learning with algorithm distillation
Michael Laskin, Luyu Wang, Junhyuk Oh, Emilio Parisotto, Stephen Spencer, Richie Steigerwald, DJ Strouse, Steven Hansen, Angelos Filos, Ethan Brooks, Maxime Gazeau, Himanshu Sahni, Satinder Singh, and Volodymyr Mnih. In-context reinforcement learning with algorithm distillation. In ICLR, 2023
2023
-
[17]
Holistic evaluation of language models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models. TMLR, 2023
2023
-
[18]
AgentBench : Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench : Evaluating LLMs as agents. In ICLR, 2024
2024
-
[19]
Haotian Luo, Huaisong Zhang, Xuelin Zhang, Haoyu Wang, Zeyu Qin, Wenjie Lu, Guozheng Ma, Haiying He, Yingsha Xie, Qiyang Zhou, Zixuan Hu, Hongze Mi, Yibo Wang, Naiqiang Tan, Hong Chen, Yi R. Fung, Chun Yuan, and Li Shen. UltraHorizon : Benchmarking agent capabilities in ultra long-horizon scenarios. arXiv preprint arXiv:2509.21766, 2025
arXiv 2025
-
[20]
AgentBoard : An analytical evaluation board of multi-turn LLM agents
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. AgentBoard : An analytical evaluation board of multi-turn LLM agents. In NeurIPS, 2024
2024
-
[21]
James G. March. Exploration and exploitation in organizational learning. Organization Science, 2 0 (1): 0 71--87, 1991. doi:10.1287/orsc.2.1.71
-
[22]
GAIA : A benchmark for general AI assistants
Gr \'e goire Mialon, Cl \'e mentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA : A benchmark for general AI assistants. In ICLR, 2024
2024
-
[23]
SWE-Lancer : Can frontier LLMs earn \ 1 million from real-world freelance software engineering? In ICML, 2025
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. SWE-Lancer : Can frontier LLMs earn \ 1 million from real-world freelance software engineering? In ICML, 2025
2025
-
[25]
Monopoly and product quality
Michael Mussa and Sherwin Rosen. Monopoly and product quality. Journal of Economic Theory, 18 0 (2): 0 301--317, 1978
1978
-
[26]
Allen Newell and Herbert A. Simon. Human Problem Solving. Prentice-Hall, Englewood Cliffs, NJ, 1972. ISBN 0-13-445403-0
1972
-
[27]
Richard L. Oliver. A cognitive model of the antecedents and consequences of satisfaction decisions. Journal of Marketing Research, 17 0 (4): 0 460--469, 1980. doi:10.1177/002224378001700405
-
[28]
Codex cli
OpenAI . Codex cli. https://developers.openai.com/codex/cli, 2026
2026
-
[29]
Opencode: The open source ai coding agent
OpenCode . Opencode: The open source ai coding agent. https://opencode.ai/, 2026
2026
-
[30]
Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The Berkeley Function Calling Leaderboard ( BFCL ): From tool use to agentic evaluation of large language models. In ICML, 2025
2025
-
[32]
AccountingBench : Evaluating LLMs on real long-horizon business tasks
Penrose AI . AccountingBench : Evaluating LLMs on real long-horizon business tasks. https://accounting.penrose.com/, 2025
2025
-
[33]
Pi documentation
Pi Contributors . Pi documentation. https://pi.dev/docs/latest, 2026
2026
-
[34]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA : A graduate-level google-proof Q&A benchmark. In COLM, 2024
2024
-
[35]
Herbert A. Simon. A behavioral model of rational choice. The Quarterly Journal of Economics, 69 0 (1): 0 99--118, 1955. doi:10.2307/1884852
-
[36]
Brown, Adam Santoro, Aditya Gupta, Adri \`a Garriga-Alonso, et al
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adri \`a Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. TMLR, 2023
2023
-
[37]
PaperBench : Evaluating AI 's ability to replicate AI research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. PaperBench : Evaluating AI 's ability to replicate AI research. In ICML, 2025. arXiv:2504.01848
Pith/arXiv arXiv 2025
-
[38]
Testing for mean reversion in processes of Ornstein--Uhlenbeck type
Alexander Szimayer and Ross Maller. Testing for mean reversion in processes of Ornstein--Uhlenbeck type. Statistical Inference for Stochastic Processes, 7: 0 95--113, 2004. doi:10.1023/B:SISP.0000026032.80363.59
-
[39]
Teece, Gary Pisano, and Amy Shuen
David J. Teece, Gary Pisano, and Amy Shuen. Dynamic capabilities and strategic management. Strategic Management Journal, 18 0 (7): 0 509--533, 1997. doi:10.1002/(SICI)1097-0266(199708)18:7<509::AID-SMJ882>3.0.CO;2-Z
-
[40]
AppWorld : A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. AppWorld : A controllable world of apps and people for benchmarking interactive coding agents. In ACL, 2024
2024
-
[41]
George E. Uhlenbeck and Leonard S. Ornstein. On the theory of the Brownian motion. Physical Review, 36 0 (5): 0 823--841, 1930. doi:10.1103/PhysRev.36.823
-
[43]
TRACE : A comprehensive benchmark for continual learning in large language models
Xiao Wang, Yuansen Zhang, Tianze Chen, Songyang Gao, Senjie Jin, Xianjun Yang, Zhiheng Xi, Rui Zheng, Yicheng Zou, Tao Gui, Qi Zhang, and Xuanjing Huang. TRACE : A comprehensive benchmark for continual learning in large language models. arXiv preprint arXiv:2310.06762, 2023
arXiv 2023
-
[44]
LongMemEval : Benchmarking chat assistants on long-term interactive memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. LongMemEval : Benchmarking chat assistants on long-term interactive memory. In ICLR, 2025
2025
-
[45]
Mitchell, and Yuanzhi Li
Yue Wu, Xuan Tang, Tom M. Mitchell, and Yuanzhi Li. SmartPlay : A benchmark for LLMs as intelligent agents. In ICLR, 2024
2024
-
[46]
TravelPlanner : A benchmark for real-world planning with language agents
Jian Xie, Kai Zhang, Jiangjie Chen, Tinghui Zhu, Renze Lou, Yuandong Tian, Yanghua Xiao, and Yu Su. TravelPlanner : A benchmark for real-world planning with language agents. In ICML, 2024 a
2024
-
[47]
OSWorld : Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. OSWorld : Benchmarking multimodal agents for open-ended tasks in real computer environments. In NeurIPS, 2024 b
2024
-
[48]
Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, et al. TheAgentCompany : Benchmarking LLM agents on consequential real world tasks. In NeurIPS, 2025
2025
-
[49]
-bench: A benchmark for tool-agent-user interaction in real-world domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. -bench: A benchmark for tool-agent-user interaction in real-world domains. In ICLR, 2025
2025
-
[50]
AssistantBench : Can web agents solve realistic and time-consuming tasks? In EMNLP, 2024
Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, and Jonathan Berant. AssistantBench : Can web agents solve realistic and time-consuming tasks? In EMNLP, 2024
2024
-
[51]
WebArena : A realistic web environment for building autonomous agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena : A realistic web environment for building autonomous agents. In ICLR, 2024
2024
-
[52]
Jimenez, Carlos E and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=
-
[53]
ICLR , year=
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. ICLR , year=
-
[54]
Zhou, Shuyan and Xu, Frank F and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle=
-
[55]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , booktitle=
-
[56]
ICLR , year=
Mialon, Gr. ICLR , year=
-
[57]
arXiv preprint arXiv:2502.15840 , year=
Vending-Bench: A Benchmark for Long-Term Coherence of Autonomous Agents , author=. arXiv preprint arXiv:2502.15840 , year=
-
[58]
Vending-Bench 2 , author=
-
[59]
and Ornstein, Leonard S
Uhlenbeck, George E. and Ornstein, Leonard S. , journal=. On the Theory of the. 1930 , doi=
1930
-
[60]
Testing for Mean Reversion in Processes of
Szimayer, Alexander and Maller, Ross , journal=. Testing for Mean Reversion in Processes of. 2004 , doi=
2004
-
[61]
Federal Reserve Bank of Dallas Economic and Financial Policy Review , volume=
Using the Purchasing Managers' Index to Assess the Economy's Strength and the Likely Direction of Monetary Policy , author=. Federal Reserve Bank of Dallas Economic and Financial Policy Review , volume=. 2002 , url=
2002
-
[62]
Journal of Marketing Research , volume=
A Cognitive Model of the Antecedents and Consequences of Satisfaction Decisions , author=. Journal of Marketing Research , volume=. 1980 , doi=
1980
-
[63]
Econometrica , volume=
Prospect Theory: An Analysis of Decision under Risk , author=. Econometrica , volume=. 1979 , doi=
1979
-
[64]
1972 , isbn=
Human Problem Solving , author=. 1972 , isbn=
1972
-
[65]
The Quarterly Journal of Economics , volume=
A Behavioral Model of Rational Choice , author=. The Quarterly Journal of Economics , volume=. 1955 , doi=
1955
-
[66]
Organization Science , volume=
Exploration and Exploitation in Organizational Learning , author=. Organization Science , volume=. 1991 , doi=
1991
-
[67]
Strategic Management Journal , volume=
Dynamic Capabilities and Strategic Management , author=. Strategic Management Journal , volume=. 1997 , doi=
1997
-
[68]
and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie Cheng-Jie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E
Patil, Shishir G. and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie Cheng-Jie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E. , booktitle=. The
-
[69]
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and others , booktitle=
-
[70]
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and others , booktitle=
-
[71]
Trivedi, Harsh and Khot, Tushar and Hartmann, Mareike and Manku, Ruskin and Dong, Vinty and Li, Edward and Gupta, Shashank and Sabharwal, Ashish and Balasubramanian, Niranjan , booktitle=
-
[72]
Ma, Chang and Zhang, Junlei and Zhu, Zhihao and Yang, Cheng and Yang, Yujiu and Jin, Yaohui and Lan, Zhenzhong and Kong, Lingpeng and He, Junxian , booktitle=
-
[73]
and Del Verme, Manuel and Marty, Tom and Boisvert, L
Drouin, Alexandre and Gasse, Maxime and Caccia, Massimo and Laradji, Issam H. and Del Verme, Manuel and Marty, Tom and Boisvert, L. ICML , year=
-
[74]
Yoran, Ori and Amouyal, Samuel Joseph and Malaviya, Chaitanya and Bogin, Ben and Press, Ofir and Berant, Jonathan , booktitle=
-
[75]
and Song, Yufan and Li, Boxuan and Tang, Yuxuan and Jain, Kritanjali and Bao, Mengxue and Wang, Zora Z
Xu, Frank F. and Song, Yufan and Li, Boxuan and Tang, Yuxuan and Jain, Kritanjali and Bao, Mengxue and Wang, Zora Z. and Zhou, Xuhui and Guo, Zhitong and Cao, Murong and others , booktitle=
-
[76]
Chan, Jun Shern and Chowdhury, Neil and Jaffe, Oliver and Aung, James and Sherburn, Dane and Mays, Evan and Starace, Giulio and Liu, Kevin and Maksin, Leon and Patwardhan, Tejal and Weng, Lilian and Madry, Aleksander , booktitle=
-
[77]
Xie, Jian and Zhang, Kai and Chen, Jiangjie and Zhu, Tinghui and Lou, Renze and Tian, Yuandong and Xiao, Yanghua and Su, Yu , booktitle=
-
[78]
and Li, Yuanzhi , booktitle=
Wu, Yue and Tang, Xuan and Mitchell, Tom M. and Li, Yuanzhi , booktitle=
-
[79]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle=
-
[80]
Schick, Timo and Dwivedi-Yu, Jane and Dessi, Roberto and Raileanu, Roberta and Lomeli, Maria and Hambro, Eric and Zettlemoyer, Luke and Cancedda, Nicola and Scialom, Thomas , booktitle=
-
[81]
NeurIPS , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. NeurIPS , year=
-
[82]
TMLR , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. TMLR , year=
-
[83]
ICLR , year=
Measuring Massive Multitask Language Understanding , author=. ICLR , year=
-
[84]
TMLR , year=
Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models , author=. TMLR , year=
-
[85]
TMLR , year=
Holistic Evaluation of Language Models , author=. TMLR , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.