Code-Augur: Agentic Vulnerability Detection via Specification Inference
Pith reviewed 2026-06-26 20:51 UTC · model grok-4.3
The pith
Code-Augur makes an LLM agent's security assumptions explicit as testable specifications and refines them through guided fuzzing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
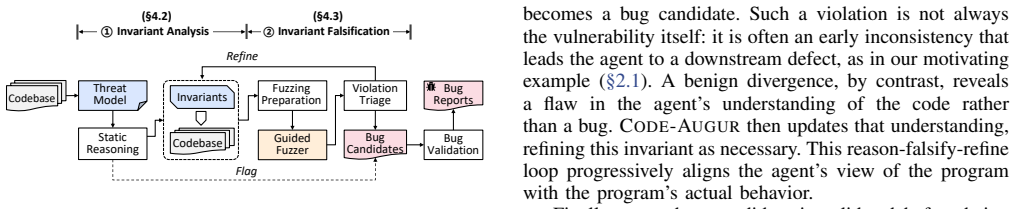
Code-Augur analyzes each component of a codebase; when the agent deems a component secure it records the local invariants as assertions, then runs a guided fuzzer to falsify those assertions, either revealing a vulnerability or a flawed specification that is refined, thereby aligning the agent's view of code intent with actual runtime behavior and yielding more detections than prior agentic methods.
What carries the argument
The Code-Augur harness that extracts local invariants into in-source assertions and drives a guided fuzzer to falsify them.
If this is right
- Agentic audits produce explicit, auditable security specifications rather than opaque yes/no verdicts.
- Specification refinement continues until assertions survive fuzzing, reducing reliance on unvalidated LLM assumptions.
- The same workflow works with widely available models such as Sonnet and DeepSeek without needing curated specialized models.
- Detected issues include both previously unknown vulnerabilities and specification errors that can be corrected.
Where Pith is reading between the lines
- The same specification-inference loop could be applied to functional correctness properties beyond security.
- Projects that already maintain test suites could seed the fuzzer with existing inputs to accelerate falsification.
- If many triggered assertions turn out to be specification errors rather than bugs, the method may also serve as a lightweight way to improve documentation.
Load-bearing premise
The guided fuzzer supplies enough coverage that any triggered assertion reliably indicates either a real vulnerability or a correctable specification error rather than an artifact of incomplete testing.
What would settle it
Replace the guided fuzzer with random inputs on the same subjects and measure whether the number of reported vulnerabilities and the count of newly discovered issues both fall by more than half.
Figures


read the original abstract
The advent of agentic vulnerability detection is already becoming a watershed moment for software security. Audits conducted entirely by autonomous LLM agents are uncovering critical vulnerabilities in fundamental software underpinning digital society. Many of these vulnerabilities remained masked for years, surfacing only now with AI agents. Yet the reasoning behind these discoveries remains alarmingly opaque and unvalidated. What assumptions did the agent make about a function's inputs when it deemed that function to be secure? Failures in reasoning and incorrect assumptions can lead to missed vulnerabilities and reduce trust in agentic analysis. We propose a security-specification-first paradigm that (1) exposes the agent's tacit assumptions explicitly as security specifications and (2) continuously refines those specifications via runtime falsification. We realize our approach in Code-Augur, a novel harness for agentic vulnerability detection. Given a codebase, Code-Augur analyzes each component of the system for vulnerable code. When it deems a component to be secure, it commits the local invariants behind that judgment as in-source assertions. In parallel, Code-Augur leverages a guided fuzzer to attempt to falsify those assumptions. When the fuzzer triggers an assertion, this either reveals a genuine vulnerability or a flawed specification to refine. In both cases, this process grounds the agent's understanding, aligning its view of code intent with how the code actually behaves. On real-world subjects, Code-Augur effectively leverages security specifications to detect more vulnerabilities than other state-of-the-art agents. Additionally, Code-Augur found 22 new vulnerabilities in key open-source projects. Compared to curated specialized models like Claude Mythos, Code-Augur offers effective agentic vulnerability detection built on widely available LLMs like Sonnet and DeepSeek.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Code-Augur, a harness for agentic vulnerability detection that extracts an LLM agent's tacit assumptions about code security as explicit in-source assertions (security specifications), then employs a guided fuzzer to attempt runtime falsification of those assertions. When an assertion is triggered, the outcome is interpreted as either a genuine vulnerability or a flawed specification requiring refinement. The central empirical claims are that Code-Augur detects more vulnerabilities than other state-of-the-art agents on real-world subjects and that it discovered 22 new vulnerabilities in key open-source projects, all while relying on widely available LLMs rather than specialized models.
Significance. If the evaluation is sound, the specification-inference-plus-falsification paradigm could meaningfully increase the transparency and reliability of LLM-based vulnerability detection by aligning agent reasoning with observable runtime behavior. The explicit credit given to using commodity models (Sonnet, DeepSeek) rather than curated specialized ones is a practical contribution. No machine-checked proofs or parameter-free derivations are present; the work is empirical.
major comments (2)
- [Evaluation] Evaluation section: the claims of superior detection performance and discovery of 22 new vulnerabilities are presented without any quantitative results, baseline comparisons, dataset sizes, coverage metrics, or controls for selection bias, making it impossible to assess whether the central empirical claim holds.
- [Approach and Evaluation] Falsification and validation procedure (described in the approach and evaluation): the load-bearing assumption that fuzzer-triggered assertions correspond to genuine vulnerabilities or correctable specification errors (rather than false positives or missed cases) is invoked to support both the performance comparison and the count of 22 new vulnerabilities, yet no details on false-positive filtering, independent validation (e.g., maintainer confirmation or CVE assignment), or coverage adequacy are supplied.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative metric (e.g., number of subjects, detection counts vs. baselines) to allow readers to gauge the scale of the reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation and validation procedures. We agree that the current manuscript presentation requires strengthening in these areas to better support the empirical claims. Below we respond point by point and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the claims of superior detection performance and discovery of 22 new vulnerabilities are presented without any quantitative results, baseline comparisons, dataset sizes, coverage metrics, or controls for selection bias, making it impossible to assess whether the central empirical claim holds.
Authors: We acknowledge that the evaluation section as currently written summarizes the outcomes at a high level without the requested quantitative breakdowns. In the revised version we will add a dedicated results subsection containing: (1) a table comparing vulnerability detection counts and rates against the cited state-of-the-art agents on the same subject programs, (2) the exact number of functions/components analyzed per project, (3) aggregate and per-project fuzzer coverage metrics (e.g., branch coverage achieved during falsification), and (4) an explicit discussion of subject-selection criteria and any steps taken to mitigate selection bias. These additions will make the performance claims directly verifiable. revision: yes
-
Referee: [Approach and Evaluation] Falsification and validation procedure (described in the approach and evaluation): the load-bearing assumption that fuzzer-triggered assertions correspond to genuine vulnerabilities or correctable specification errors (rather than false positives or missed cases) is invoked to support both the performance comparison and the count of 22 new vulnerabilities, yet no details on false-positive filtering, independent validation (e.g., maintainer confirmation or CVE assignment), or coverage adequacy are supplied.
Authors: The manuscript currently describes the logical outcome of a triggered assertion (either a vulnerability or a specification to refine) but does not detail the subsequent filtering or external validation steps. We will expand both the approach and evaluation sections to include: (a) the concrete criteria and manual review process used to classify a triggered assertion as a true vulnerability versus a specification error, (b) the status of the 22 reported vulnerabilities (e.g., which have been disclosed to maintainers, received CVE assignments, or been confirmed as previously unknown), and (c) quantitative coverage data from the guided fuzzer together with any limitations on coverage adequacy. This will clarify how false-positive risk is managed and how the 22-count claim is substantiated. revision: yes
Circularity Check
No circularity: empirical claims rest on external evaluation, not self-referential derivation
full rationale
The paper describes an agentic system that infers security specifications and uses guided fuzzing for falsification, with central claims consisting of empirical performance comparisons against SOTA agents and the count of 22 newly discovered vulnerabilities on real-world subjects. No equations, parameters, uniqueness theorems, or derivation steps appear in the provided text. The evaluation is benchmarked against external agents and open-source projects rather than reducing any result to its own inputs by construction, satisfying the self-contained criterion for a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude Mythos preview,
N. Carlini, N. Cheng, K. Lucas, M. Moore, M. Nasr, V . Prabhushankar, W. Xiao Hakeem Angulu, E. Ben Asher, J. Bow, K. Bradwell, B. Buchanan, D. Forsythe, D. Freeman, A. Gaynor, X. Ge, L. Graham, K. Guru, H. Lakhani, M. McNiece, M. Mehrara, R. Nichol, A. Pirzada, S. Porter, A. Terzis, and K. Troy, “Claude Mythos preview,” 2026. [Online]. Available: https:/...
2026
-
[2]
Behind the scenes hardening firefox with claude mythos preview,
B. Grinstead, C. Holler, and F. Braun, “Behind the scenes hardening firefox with claude mythos preview,” May 2026. [Online]. Available: https://hacks.mozilla.org/2026/05/ behind-the-scenes-hardening-firefox/
2026
-
[3]
SpecRover: Code intent extraction via LLMs,
H. Ruan, Y . Zhang, and A. Roychoudhury, “SpecRover: Code intent extraction via LLMs,” in2025 IEEE/ACM 47th International Con- ference on Software Engineering (ICSE), 2025
2025
-
[4]
Specgen: Automated generation of formal program specifications via large language mod- els,
L. Ma, S. Liu, Y . Li, X. Xie, and L. Bu, “Specgen: Automated generation of formal program specifications via large language mod- els,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 16–28
2025
-
[5]
From Naptime to Big Sleep: Using large language models to catch vulnerabilities in real-world code,
B. S. Team, “From Naptime to Big Sleep: Using large language models to catch vulnerabilities in real-world code,” 2024. [Online]. Available: https://projectzero.google/2024/10/ from-naptime-to-big-sleep.html
2024
-
[6]
(2025) Claude Code: An agentic coding tool
Anthropic. (2025) Claude Code: An agentic coding tool. https: //claude.com/product/claude-code
2025
-
[7]
(2025) AI Cyber Challenge (AIxCC)
DARPA. (2025) AI Cyber Challenge (AIxCC). https: //aicyberchallenge.com/
2025
-
[8]
(2021) OSV: Open source vulnerabilities database and triage service
Google. (2021) OSV: Open source vulnerabilities database and triage service. https://github.com/google/osv.dev
2021
-
[9]
(2025) Atlantis: Team atlanta’s cyber reasoning sys- tem for the DARPA AIxCC final competition
Team Atlanta. (2025) Atlantis: Team atlanta’s cyber reasoning sys- tem for the DARPA AIxCC final competition. https://github.com/ Team-Atlanta/aixcc-afc-atlantis
2025
-
[10]
GPSd: Put your GPS on the net!
The GPSd Project, “GPSd: Put your GPS on the net!” 2026. [Online]. Available: https://gpsd.io/
2026
-
[11]
Ad- dressSanitizer: A fast address sanity checker,
K. Serebryany, D. Bruening, A. Potapenko, and D. Vyukov, “Ad- dressSanitizer: A fast address sanity checker,”2012 USENIX Annual Technical Conference, 2012
2012
-
[12]
An empirical study of the reliability of UNIX utilities,
B. P. Miller, L. Fredriksen, and B. So, “An empirical study of the reliability of UNIX utilities,”Communications of the ACM, vol. 33, no. 12, pp. 32–44, 1990
1990
-
[13]
libFuzzer: A library for coverage-guided fuzz test- ing,
LLVM Project, “libFuzzer: A library for coverage-guided fuzz test- ing,” https://llvm.org/docs/LibFuzzer.html
-
[14]
Jazzer: Coverage-guided, in-process fuzzing for the JVM,
Code Intelligence, “Jazzer: Coverage-guided, in-process fuzzing for the JVM,” https://github.com/CodeIntelligenceTesting/jazzer
-
[15]
(2026) Pi: An AI agent toolkit
earendil-works. (2026) Pi: An AI agent toolkit. https://github.com/ earendil-works/pi/releases/tag/v0.77.0
2026
-
[16]
ATLANTIS: AI-driven threat localization, analysis, and triage intelligence system,
T. Kim, H. Han, S. Park, D. R. Jeong, D. Kim, D. Kim, E. Kim, J. Kim, J. Wang, K. Kimet al., “ATLANTIS: AI-driven threat localization, analysis, and triage intelligence system,”arXiv preprint arXiv:2509.14589, 2025
arXiv 2025
-
[17]
Sok: Darpa’s ai cyber chal- lenge (aixcc): Competition design, architectures, and lessons learned,
C. Zhang, Y . Park, F. Fleischer, Y .-F. Fu, J. Kim, D. Kim, Y . Kim, Q. Xu, A. Chin, Z. Shenget al., “Sok: Darpa’s ai cyber chal- lenge (aixcc): Competition design, architectures, and lessons learned,” Usenix Security, 2026
2026
-
[18]
OSS-CRS: Liberating AIxCC cyber reasoning systems for real-world open-source security,
A. Chin, D. Kim, Y .-F. Fu, F. Fleischer, Y . Kim, H. Han, C. Zhang, B. J. Lee, H. Zhao, and T. Kim, “OSS-CRS: Liberating AIxCC cyber reasoning systems for real-world open-source security,”arXiv preprint arXiv:2603.08566, 2026
arXiv 2026
-
[19]
(2024) AIxCC competition: Procedures and scoring guide
DARPA. (2024) AIxCC competition: Procedures and scoring guide. https://aicyberchallenge.com/wp-content/uploads/2024/06/ ASC-Procedures-and-Scoring-Guide-v4.pdf
2024
-
[20]
(2026) Claude Sonnet 4.6
Anthropic. (2026) Claude Sonnet 4.6. https://docs.anthropic.com/en/ docs/about-claude/models/overview
2026
-
[21]
(2026) DeepSeek V4 Pro
DeepSeek-AI. (2026) DeepSeek V4 Pro. https://api-docs.deepseek. com
2026
-
[22]
(2026) Claude Code bug-finding agent (crs-bug-finding-claude-code)
Team Atlanta. (2026) Claude Code bug-finding agent (crs-bug-finding-claude-code). https://github.com/Team-Atlanta/ crs-bug-finding-claude-code
2026
-
[23]
OSS-Fuzz: Google’s continuous fuzzing for open- source software
K. Serebryany, “OSS-Fuzz: Google’s continuous fuzzing for open- source software.” Vancouver, BC: USENIX Association, Aug 2017
2017
-
[24]
(2026) OSV-2026-189: Out-of-bounds read in gpsd
OSV. (2026) OSV-2026-189: Out-of-bounds read in gpsd. https://osv. dev/vulnerability/OSV-2026-189
2026
-
[25]
OSS-Fuzz-Gen: LLM powered fuzzing via OSS-Fuzz,
Google, “OSS-Fuzz-Gen: LLM powered fuzzing via OSS-Fuzz,”
-
[26]
Available: https://github.com/google/oss-fuzz-gen
[Online]. Available: https://github.com/google/oss-fuzz-gen
-
[27]
Prompt fuzzing for fuzz driver generation,
Y . Lyu, Y . Xie, P. Chen, and H. Chen, “Prompt fuzzing for fuzz driver generation,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 3793–3807
2024
-
[28]
Promefuzz: A knowledge-driven approach to fuzzing harness generation with large language models,
Y . Liu, J. Deng, X. Jia, Y . Wang, M. Wang, L. Huang, T. Wei, and P. Su, “Promefuzz: A knowledge-driven approach to fuzzing harness generation with large language models,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, 2025, pp. 1559–1573
2025
-
[29]
Enhancing protocol fuzzing via diverse seed corpus generation,
Z. Luo, Q. Du, Y . Wang, A. Roychoudhury, and Y . Jiang, “Enhancing protocol fuzzing via diverse seed corpus generation,”IEEE Transac- tions on Software Engineering, 2025
2025
-
[30]
Firmagent: Leveraging fuzzing to assist llm agents with iot firmware vulnerability discovery
J. Ji, C. Zhang, S. Gan, L. Jian, H. Liu, T. Liu, L. Zheng, and Z. Jia, “Firmagent: Leveraging fuzzing to assist llm agents with iot firmware vulnerability discovery.” inNDSS, 2026
2026
-
[31]
Z. Sheng, Q. Xu, J. Huang, M. Woodcock, H. Huang, A. F. Don- aldson, G. Gu, and J. Huang, “All you need is a Fuzzing Brain: An LLM-powered system for automated vulnerability detection and patching,”arXiv preprint arXiv:2509.07225, 2025
arXiv 2025
-
[32]
Large language models in software security analysis,
D. Wolff, M. Mirchev, and A. Roychoudhury, “Large language models in software security analysis,”Communications of the ACM, vol. 69, no. 6, pp. 60–67, 2026
2026
-
[33]
Agentic concolic execution,
Z. Luo, H. Zhao, D. Wolff, C. Cadar, and A. Roychoudhury, “Agentic concolic execution,” inProceedings of the IEEE Symposium on Security and Privacy (S&P), 2026, pp. 1–19
2026
-
[34]
Fuzz4All: Universal fuzzing with large language models,
C. S. Xia, M. Paltenghi, J. Le Tian, M. Pradel, and L. Zhang, “Fuzz4All: Universal fuzzing with large language models,” inPro- ceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
2024
-
[35]
Vul-RAG: Enhancing LLM-based vulnerability detection via knowledge-level RAG,
X. Du, G. Zheng, K. Wang, Y . Zou, Y . Wang, W. Deng, J. Feng, M. Liu, B. Chen, X. Penget al., “Vul-RAG: Enhancing LLM-based vulnerability detection via knowledge-level RAG,”ACM Transactions on Software Engineering and Methodology, 2024
2024
-
[36]
Agentic fuzzing: Opportunities and challenges,
J. Park and I. Yun, “Agentic fuzzing: Opportunities and challenges,” arXiv preprint arXiv:2605.10074, 2026
Pith/arXiv arXiv 2026
-
[37]
VulAgent: Hypothesis- validation based multi-agent vulnerability detection,
Z. Wang, G. Li, J. Li, H. Zhu, and Z. Jin, “VulAgent: Hypothesis- validation based multi-agent vulnerability detection,”arXiv preprint arXiv:2509.11523, 2025
arXiv 2025
-
[38]
Advanced smart contract vulnerability detection via LLM-powered multi-agent systems,
Z. Wei, J. Sun, Y . Sun, Y . Liu, D. Wu, Z. Zhang, X. Zhang, M. Li, Y . Liu, C. Li, M. Wan, J. Dong, and L. Zhu, “Advanced smart contract vulnerability detection via LLM-powered multi-agent systems,”IEEE Transactions on Software Engineering, vol. 51, no. 10, pp. 2830– 2846, 2025
2025
-
[39]
Large lan- guage model-powered smart contract vulnerability detection: New perspectives,
S. Hu, T. Huang, F. ˙Ilhan, S. F. Tekin, and L. Liu, “Large lan- guage model-powered smart contract vulnerability detection: New perspectives,” in2023 5th IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS- ISA). IEEE, 2023, pp. 297–306
2023
-
[40]
The daikon system for dynamic detection of likely invariants,
M. D. Ernst, J. H. Perkins, P. J. Guo, S. McCamant, C. Pacheco, M. S. Tschantz, and C. Xiao, “The daikon system for dynamic detection of likely invariants,”Science of computer programming, vol. 69, no. 1-3, pp. 35–45, 2007
2007
-
[41]
General ltl specification mining (t),
C. Lemieux, D. Park, and I. Beschastnikh, “General ltl specification mining (t),” in2015 30th IEEE/ACM international conference on automated software engineering (ASE). IEEE, 2015, pp. 81–92
2015
-
[42]
Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification,
F. Mu, L. Shi, S. Wang, Z. Yu, B. Zhang, C. Wang, S. Liu, and Q. Wang, “Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification,”Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, pp. 2332–2354, 2024
2024
-
[43]
Can large language models transform natural language intent into formal method postconditions?
M. Endres, S. Fakhoury, S. Chakraborty, and S. K. Lahiri, “Can large language models transform natural language intent into formal method postconditions?”Proceedings of the ACM on Software Engi- neering, vol. 1, no. FSE, pp. 1889–1912, 2024
1912
-
[44]
Evaluating llm-driven user-intent formalization for verification-aware languages,
S. K. Lahirie, “Evaluating llm-driven user-intent formalization for verification-aware languages,” in2024 Formal Methods in Computer- Aided Design (FMCAD). IEEE, 2024, pp. 142–147
2024
-
[45]
ECG: Augmenting embedded operating system fuzzing via LLM- based corpus generation,
Q. Zhang, Y . Shen, J. Liu, Y . Xu, H. Shi, Y . Jiang, and W. Chang, “ECG: Augmenting embedded operating system fuzzing via LLM- based corpus generation,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 43, no. 11, pp. 4238– 4249, 2024
2024
-
[46]
Everything is good for something: Counterexample-guided directed fuzzing via likely in- variant inference,
H. Huang, A. Zhou, M. Payer, and C. Zhang, “Everything is good for something: Counterexample-guided directed fuzzing via likely in- variant inference,” in2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024, pp. 1956–1973
2024
-
[47]
Locus: Agentic predicate synthesis for directed fuzzing,
J. Zhu, C. Shen, Z. Li, J. Yu, Y . Chen, and K. Pei, “Locus: Agentic predicate synthesis for directed fuzzing,” in Proceedings of the ACM/IEEE 48th International Conference on Software Engineering, ser. ICSE ’26. New York, NY , USA: Association for Computing Machinery, 2026. [Online]. Available: https://doi.org/10.1145/3744916.3773102
-
[48]
The use of likely invari- ants as feedback for fuzzers,
A. Fioraldi, D. C. D’Elia, and D. Balzarotti, “The use of likely invari- ants as feedback for fuzzers,” in30th USENIX Security Symposium (USENIX Security 21), 2021, pp. 2829–2846
2021
-
[49]
FM-Agent: Scaling formal meth- ods to large systems via LLM-based Hoare-style reasoning,
H. Ding, Z. Wang, and H. Chen, “FM-Agent: Scaling formal meth- ods to large systems via LLM-based Hoare-style reasoning,”arXiv preprint arXiv:2604.11556, 2026
Pith/arXiv arXiv 2026
-
[50]
Llm-assisted static analysis for detecting security vulnerabilities,
Z. Li, S. Dutta, and M. Naik, “Llm-assisted static analysis for detecting security vulnerabilities,”arXiv preprint arXiv:2405.17238, 2024
arXiv 2024
-
[51]
Enhancing static analysis for practical bug detection: An LLM-integrated approach,
H. Li, Y . Hao, Y . Zhai, and Z. Qian, “Enhancing static analysis for practical bug detection: An LLM-integrated approach,”Proceedings of the ACM on Programming Languages, vol. 8, no. OOPSLA1, pp. 474–499, 2024
2024
-
[52]
To the cutoff... and beyond? a longitudinal perspective on llm data contamination,
M. Roberts, H. Thakur, C. Herlihy, C. White, and S. Dooley, “To the cutoff... and beyond? a longitudinal perspective on llm data contamination,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[53]
Benchmark probing: Investigating data leakage in large language models,
C. Deng, Y . Zhao, X. Tang, M. Gerstein, and A. Cohan, “Benchmark probing: Investigating data leakage in large language models,” inNeurIPS 2023 Workshop on Backdoors in Deep Learning - The Good, the Bad, and the Ugly, 2024. [Online]. Available: https://openreview.net/forum?id=a34bgvner1
2023
-
[54]
ANT-2026-6615Y595: wolfSSL vulnerability finding,
Anthropic, “ANT-2026-6615Y595: wolfSSL vulnerability finding,”
2026
-
[55]
Available: https://red.anthropic.com/2026/cvd/ findings/ANT-2026-6615Y595
[Online]. Available: https://red.anthropic.com/2026/cvd/ findings/ANT-2026-6615Y595
2026
-
[56]
SemFix: Program repair via semantic analysis,
H. Nguyen, D. Qi, A. Roychoudhury, and S. Chandra, “SemFix: Program repair via semantic analysis,” in2013 35th International Conference on Software Engineering (ICSE), 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.