SenFlow: Inter-Sentence Flow Modeling for AI-Generated Text Detection in Hybrid Documents
Pith reviewed 2026-06-26 20:46 UTC · model grok-4.3
The pith
Inter-sentence graph modeling improves detection of AI text in hybrid documents over independent sentence classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
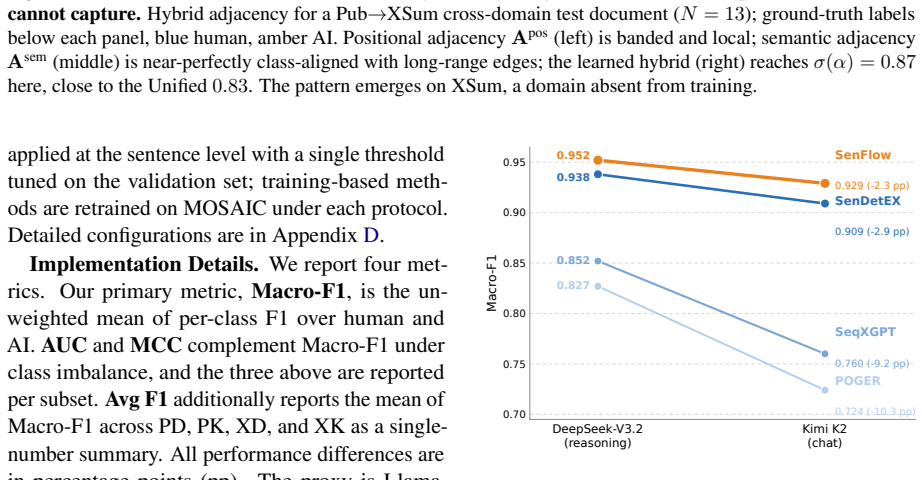
The paper claims that recasting sentence-level AI-generated text detection as structured prediction over the document sentence sequence, instantiated as SenFlow with graph-based inter-sentence propagation and linear-chain CRF decoding, reaches state-of-the-art performance on the MOSAIC benchmark, with a 4.15 percentage point average Macro-F1 margin on cross-domain transfer.
What carries the argument
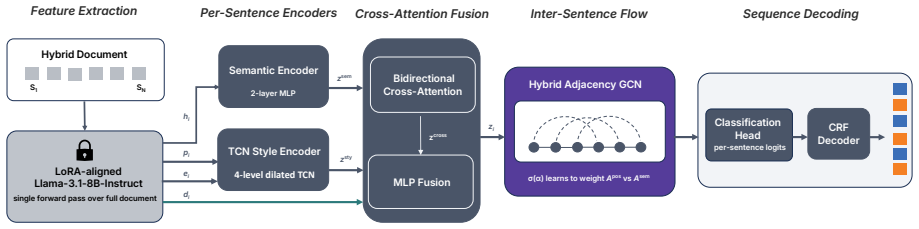
SenFlow, which integrates graph-based propagation of inter-sentence information with linear-chain CRF decoding over a sentence graph to capture dependencies across the document.
If this is right
- Modeling dependencies between sentences supplies additional signal that isolated classifiers miss.
- Even after the perplexity filter removes some overt cues, generator-dependent sentence-length patterns remain and aid detection.
- The largest gains appear on cross-domain transfer, the hardest of the three evaluation protocols.
- The full model runs in a single document-level pass rather than sentence-by-sentence.
Where Pith is reading between the lines
- The same graph-plus-CRF structure could apply to other sequence-labeling problems where units are edited or anomalous relative to their neighbors.
- The persistent length gap finding suggests length normalization as a cheap baseline feature worth testing on future detectors.
- Evaluating the method on documents that humans have lightly edited after AI generation would test robustness to realistic hybrid use.
Load-bearing premise
Inter-sentence dependencies supply detection signal beyond what independent per-sentence classifiers already capture.
What would settle it
Compare SenFlow against a strong independent sentence classifier on the same test documents after randomly shuffling sentence order inside each document; if the performance gap disappears, the inter-sentence modeling claim is falsified.
Figures

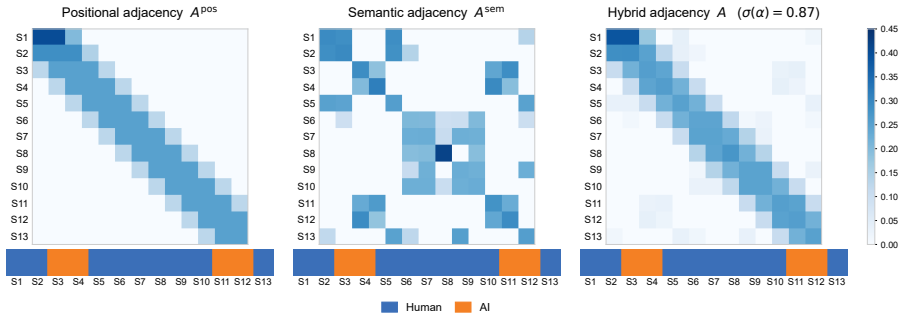
read the original abstract
Sentence-level AI-generated text detection (S-AGTD) for hybrid documents, where humans and LLMs co-author one text, faces two gaps: existing methods classify each sentence in isolation, discarding inter-sentence dependencies, and existing benchmarks omit the newest generation of generators. We construct MOSAIC, a benchmark of 16,000 hybrid documents over PubMed and XSum, generated by DeepSeek-V3.2 and Kimi K2 under stringent quality controls including a perplexity-consistency filter absent from prior benchmarks. We recast S-AGTD as structured prediction over the document sentence sequence and instantiate it as SenFlow, integrating graph-based inter-sentence propagation with linear-chain CRF decoding in a single document-level pass over a sentence graph. SenFlow reaches state-of-the-art performance on MOSAIC, with a +4.15 pp average Macro-F1 margin on cross-domain transfer, the hardest of three protocols of increasing difficulty. We further find that even after the perplexity filter equalizes overt cues, AI insertions retain a generator-dependent sentence-length gap that sentence-level detectors still exploit. Code and data: https://github.com/luojingkun22/SenFlow
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MOSAIC, a benchmark of 16,000 hybrid documents from PubMed and XSum generated by DeepSeek-V3.2 and Kimi K2 under quality controls including a perplexity-consistency filter. It recasts sentence-level AI-generated text detection as structured prediction and proposes SenFlow, which integrates graph-based inter-sentence propagation with linear-chain CRF decoding. The paper reports state-of-the-art results on MOSAIC, including a +4.15 pp average Macro-F1 margin on the cross-domain transfer protocol, the hardest of three evaluation settings.
Significance. If the reported gains are shown to arise from the inter-sentence modeling rather than benchmark construction artifacts, the work would establish the utility of graph propagation and CRF decoding for hybrid-document detection tasks. The release of code and data, together with the new benchmark addressing gaps in prior evaluations, would constitute a concrete contribution to the field.
major comments (2)
- [Abstract] The headline claim that inter-sentence flow modeling supplies the observed +4.15 pp Macro-F1 margin on the cross-domain protocol is not supported by any ablation that removes the graph edges while retaining the identical sentence encoder, CRF, and MOSAIC splits. Without this isolation, it remains possible that the gains trace to sentence-level cues (including the residual length gap noted in the abstract) rather than the graph propagation component.
- [Abstract] The assertion that the perplexity-consistency filter produces an unbiased benchmark representative of real hybrid documents is undercut by the paper's own observation of a generator-dependent sentence-length gap that any sentence-level detector can exploit; this directly affects whether the cross-domain gains can be attributed to flow modeling.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for clearer isolation of the inter-sentence modeling contribution and for more precise language on benchmark construction. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] The headline claim that inter-sentence flow modeling supplies the observed +4.15 pp Macro-F1 margin on the cross-domain protocol is not supported by any ablation that removes the graph edges while retaining the identical sentence encoder, CRF, and MOSAIC splits. Without this isolation, it remains possible that the gains trace to sentence-level cues (including the residual length gap noted in the abstract) rather than the graph propagation component.
Authors: We agree that the manuscript lacks a direct ablation removing only the graph edges while retaining the identical sentence encoder, CRF decoder, and MOSAIC data splits. The reported comparisons are against prior sentence-level baselines rather than an internal SenFlow variant without propagation. In the revision we will add this ablation to quantify the incremental benefit of the graph component on the cross-domain protocol. revision: yes
-
Referee: [Abstract] The assertion that the perplexity-consistency filter produces an unbiased benchmark representative of real hybrid documents is undercut by the paper's own observation of a generator-dependent sentence-length gap that any sentence-level detector can exploit; this directly affects whether the cross-domain gains can be attributed to flow modeling.
Authors: The manuscript already notes the residual generator-dependent length gap after the perplexity filter. We accept that this observation weakens the claim of an unbiased benchmark. In the revision we will revise the abstract to state that the filter equalizes overt perplexity cues but leaves other distributional differences, and we will qualify the attribution of cross-domain gains accordingly while retaining the description of the filter's purpose. revision: yes
Circularity Check
No circularity; empirical application of standard graph/CRF components to new benchmark.
full rationale
The paper constructs MOSAIC benchmark under explicit quality controls (perplexity-consistency filter) and applies established graph propagation plus linear-chain CRF to recast sentence-level detection as structured prediction. The +4.15 pp Macro-F1 claim is an empirical measurement on held-out cross-domain splits, not a quantity derived by construction from fitted parameters or self-referential definitions. No equations, self-citations, or ansatzes are presented that reduce the central result to its inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Graph-based message passing and linear-chain CRF can be combined for structured sequence labeling
Reference graph
Works this paper leans on
-
[2]
Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, and Yue Zhang. 2024. Fast- D etect GPT : Efficient zero-shot detection of machine-generated text via conditional probability curvature. In International Conference on Learning Representations
2024
-
[3]
Steven Bird, Ewan Klein, and Edward Loper. 2009. Natural language processing with P ython: analyzing text with the natural language toolkit . O'Reilly Media, Inc
2009
-
[4]
Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. 2018. A discourse-aware attention model for abstractive summarization of long documents. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, volume 2, pages...
2018
-
[5]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The L lama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. D eep S eek- R 1: Incentivizing reasoning capability in LLM s via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. 2024. Spotting LLM s with binoculars: Zero-shot detection of machine-generated text. In Proceedings of the 41st International Conference on Machine Learning, pages 17519--17537
2024
-
[8]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, and 1 others. 2022. Lo RA : Low-rank adaptation of large language models. In International Conference on Learning Representations
2022
-
[9]
Xiaomeng Hu, Pin-Yu Chen, and Tsung-Yi Ho. 2023. RADAR : Robust AI -text detection via adversarial learning. Advances in Neural Information Processing Systems, 36:15077--15095
2023
-
[10]
Guanhua Huang, Yuchen Zhang, Zhe Li, Yongjian You, Mingze Wang, and Zhouwang Yang. 2024. Are AI -generated text detectors robust to adversarial perturbations? In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, volume 1, pages 6005--6024
2024
-
[11]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, and 1 others. 2024. O pen AI o1 system card. arXiv preprint arXiv:2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Lei Jiang, Desheng Wu, and Xiaolong Zheng. 2025. SenDetEX : Sentence-level AI -generated text detection for human- AI hybrid content via style and context fusion. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5287--5302
2025
-
[14]
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. 2023. A watermark for large language models. In International Conference on Machine Learning, pages 17061--17084. PMLR
2023
-
[15]
John Lafferty, Andrew McCallum, and Fernando CN Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning, pages 282--289
2001
-
[16]
Mina Lee, Percy Liang, and Qian Yang. 2022. C o A uthor: Designing a human- AI collaborative writing dataset for exploring language model capabilities. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pages 1--19
2022
-
[17]
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Zhilin Wang, Longyue Wang, Linyi Yang, Shuming Shi, and Yue Zhang. 2024. MAGE : Machine-generated text detection in the wild. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, volume 1, pages 36--53
2024
-
[18]
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll \'a r. 2017. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, pages 2980--2988
2017
-
[19]
Ilya Loshchilov and Frank Hutter. 2016. SGDR : Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [21]
-
[22]
Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. 2023. D etect GPT : Zero-shot machine-generated text detection using probability curvature. In International Conference on Machine Learning, pages 24950--24962. PMLR
2023
-
[23]
Shashi Narayan, Shay B Cohen, and Mirella Lapata. 2018. Don't give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1797--1807
2018
-
[24]
Hoang-Quoc Nguyen-Son, Minh-Son Dao, and Koji Zettsu. 2024. S im LLM : Detecting sentences generated by large language models using similarity between the generation and its re-generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22340--22352
2024
-
[26]
Nils Reimers and Iryna Gurevych. 2019. Sentence- BERT : Sentence embeddings using siamese BERT -networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 3982--3992
2019
-
[27]
Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. 2023. Can AI -generated text be reliably detected? arXiv preprint arXiv:2303.11156
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Sunil Kumar Sahu, Fenia Christopoulou, Makoto Miwa, and Sophia Ananiadou. 2019. Inter-sentence relation extraction with document-level graph convolutional neural network. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4309--4316
2019
-
[29]
Yuhui Shi, Qiang Sheng, Juan Cao, Hao Mi, Beizhe Hu, and Danding Wang. 2024. Ten words only still help: Improving black-box AI -generated text detection via proxy-guided efficient re-sampling. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 494--502
2024
-
[31]
Zhixiong Su, Yichen Wang, Herun Wan, Zhaohan Zhang, and Minnan Luo. 2025. HACo - D et: A study towards fine-grained machine-generated text detection under human- AI coauthoring. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, volume 1, pages 22015--22036
2025
-
[32]
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. 2016. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2818--2826
2016
-
[33]
Pengyu Wang, Linyang Li, Ke Ren, Botian Jiang, Dong Zhang, and Xipeng Qiu. 2023. SeqXGPT : Sentence-level AI -generated text detection. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1144--1156
2023
-
[34]
Debora Weber-Wulff, Alla Anohina-Naumeca, Sonja Bjelobaba, Tom \'a s Folt \`y nek, Jean Guerrero-Dib, Olumide Popoola, Petr S igut, and Lorna Waddington. 2023. Testing of detection tools for AI -generated text. International Journal for Educational Integrity, 19(1):1--39
2023
-
[35]
Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Lidia Sam Chao, and Derek Fai Wong. 2025. A survey on LLM -generated text detection: Necessity, methods, and future directions. Computational Linguistics, 51(1):275--338
2025
-
[36]
Xianjun Yang, Wei Cheng, Yue Wu, Linda Petzold, William Wang, and Haifeng Chen. 2024. DNA - GPT : Divergent n-gram analysis for training-free detection of GPT -generated text. In International Conference on Learning Representations
2024
-
[38]
Cong Zeng, Shengkun Tang, Xianjun Yang, Yuanzhou Chen, Yiyou Sun, Zhiqiang Xu, Yao Li, Haifeng Chen, Wei Cheng, and Dongkuan Xu. 2024. DALD : Improving logits-based detector without logits from black-box LLM s. Advances in Neural Information Processing Systems, 37:54947--54973
2024
-
[39]
Qihui Zhang, Chujie Gao, Dongping Chen, Yue Huang, Yixin Huang, Zhenyang Sun, Shilin Zhang, Weiye Li, Zhengyan Fu, Yao Wan, and 1 others. 2024. LLM -as-a-coauthor: Can mixed human-written and machine-generated text be detected? In Findings of the Association for Computational Linguistics: NAACL 2024, pages 409--436
2024
- [41]
-
[42]
A Survey of Large Language Models
A survey of large language models , author=. arXiv preprint arXiv:2303.18223 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
A survey on
Wu, Junchao and Yang, Shu and Zhan, Runzhe and Yuan, Yulin and Chao, Lidia Sam and Wong, Derek Fai , journal=. A survey on
-
[44]
2023 , organization=
Mitchell, Eric and Lee, Yoonho and Khazatsky, Alexander and Manning, Christopher D and Finn, Chelsea , booktitle=. 2023 , organization=
2023
-
[45]
Bao, Guangsheng and Zhao, Yanbin and Teng, Zhiyang and Yang, Linyi and Zhang, Yue , booktitle=. Fast-
-
[46]
Yang, Xianjun and Cheng, Wei and Wu, Yue and Petzold, Linda and Wang, William and Chen, Haifeng , booktitle=
-
[47]
International Conference on Machine Learning , pages=
A watermark for large language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[48]
Jiang, Lei and Wu, Desheng and Zheng, Xiaolong , booktitle=
-
[49]
Wang, Pengyu and Li, Linyang and Ren, Ke and Jiang, Botian and Zhang, Dong and Qiu, Xipeng , booktitle=
-
[50]
Spotting
Hans, Abhimanyu and Schwarzschild, Avi and Cherepanova, Valeriia and Kazemi, Hamid and Saha, Aniruddha and Goldblum, Micah and Geiping, Jonas and Goldstein, Tom , booktitle=. Spotting
-
[51]
Release Strategies and the Social Impacts of Language Models
Release strategies and the social impacts of language models , author=. arXiv preprint arXiv:1908.09203 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[52]
Hu, Xiaomeng and Chen, Pin-Yu and Ho, Tsung-Yi , journal=
-
[53]
Zeng, Cong and Tang, Shengkun and Yang, Xianjun and Chen, Yuanzhou and Sun, Yiyou and Xu, Zhiqiang and Li, Yao and Chen, Haifeng and Cheng, Wei and Xu, Dongkuan , journal=
-
[54]
Ten words only still help: Improving black-box
Shi, Yuhui and Sheng, Qiang and Cao, Juan and Mi, Hao and Hu, Beizhe and Wang, Danding , booktitle=. Ten words only still help: Improving black-box
-
[55]
Jaech, Aaron and Kalai, Adam and Lerer, Adam and Richardson, Adam and El-Kishky, Ahmed and Low, Aiden and Helyar, Alec and Madry, Aleksander and Beutel, Alex and Carney, Alex and others , journal=
-
[56]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and others , journal=
-
[57]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
A discourse-aware attention model for abstractive summarization of long documents , author=. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2018
-
[58]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
Don't give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[59]
Natural language processing with
Bird, Steven and Klein, Ewan and Loper, Edward , year=. Natural language processing with
-
[60]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal=. The
-
[61]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Liang and Chen, Weizhu and others , booktitle=. Lo
-
[62]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
An empirical evaluation of generic convolutional and recurrent networks for sequence modeling , author=. arXiv preprint arXiv:1803.01271 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Semi-Supervised Classification with Graph Convolutional Networks
Semi-supervised classification with graph convolutional networks , author=. arXiv preprint arXiv:1609.02907 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Proceedings of the Eighteenth International Conference on Machine Learning , pages=
Conditional random fields: Probabilistic models for segmenting and labeling sequence data , author=. Proceedings of the Eighteenth International Conference on Machine Learning , pages=
-
[65]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Focal loss for dense object detection , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[66]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Rethinking the inception architecture for computer vision , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[68]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Loshchilov, Ilya and Hutter, Frank , journal=
-
[70]
Lee, Mina and Liang, Percy and Yang, Qian , booktitle=
-
[71]
Sadasivan, Vinu Sankar and Kumar, Aounon and Balasubramanian, Sriram and Wang, Wenxiao and Feizi, Soheil , journal=. Can
-
[72]
Testing of detection tools for
Weber-Wulff, Debora and Anohina-Naumeca, Alla and Bjelobaba, Sonja and Folt. Testing of detection tools for. International Journal for Educational Integrity , volume=. 2023 , publisher=
2023
-
[73]
Huang, Guanhua and Zhang, Yuchen and Li, Zhe and You, Yongjian and Wang, Mingze and Yang, Zhouwang , booktitle=. Are
-
[74]
Li, Yafu and Li, Qintong and Cui, Leyang and Bi, Wei and Wang, Zhilin and Wang, Longyue and Yang, Linyi and Shi, Shuming and Zhang, Yue , booktitle=
-
[75]
Mao, Chengzhi and Vondrick, Carl and Wang, Hao and Yang, Junfeng , journal=
-
[76]
Nguyen-Son, Hoang-Quoc and Dao, Minh-Son and Zettsu, Koji , booktitle=
-
[77]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
Inter-sentence relation extraction with document-level graph convolutional neural network , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
-
[78]
Su, Zhixiong and Wang, Yichen and Wan, Herun and Zhang, Zhaohan and Luo, Minnan , booktitle=
-
[79]
arXiv preprint arXiv:1912.07225 , year=
Graph-based neural sentence ordering , author=. arXiv preprint arXiv:1912.07225 , year=
-
[80]
Zhang, Qihui and Gao, Chujie and Chen, Dongping and Huang, Yue and Huang, Yixin and Sun, Zhenyang and Zhang, Shilin and Li, Weiye and Fu, Zhengyan and Wan, Yao and others , booktitle=
-
[81]
Provable robust watermarking for
Zhao, Xuandong and Ananth, Prabhanjan and Li, Lei and Wang, Yu-Xiang , journal=. Provable robust watermarking for
-
[82]
Sentence-
Reimers, Nils and Gurevych, Iryna , booktitle=. Sentence-
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.