Be Your Own Teacher: Steering Protein Language Models via Unsupervised Reward Optimization
Pith reviewed 2026-06-26 21:39 UTC · model grok-4.3
The pith
Task-agnostic rewards from model uncertainty and semantic consistency enable unsupervised steering of protein language models without labels or experiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Task-agnostic rewards that combine intrinsic model uncertainty with extrinsic semantic consistency informed by protein representation models exhibit strong correlation with controllability measures, and two offline algorithms, Soft Reward Optimization (SRO) and Binarized Reward Optimization (BRO), maximize the classical RLHF objective induced by these proxies to produce steerable protein generation.
What carries the argument
Task-agnostic proxy rewards formed by combining intrinsic model uncertainty with extrinsic semantic consistency, optimized through the SRO and BRO offline algorithms.
If this is right
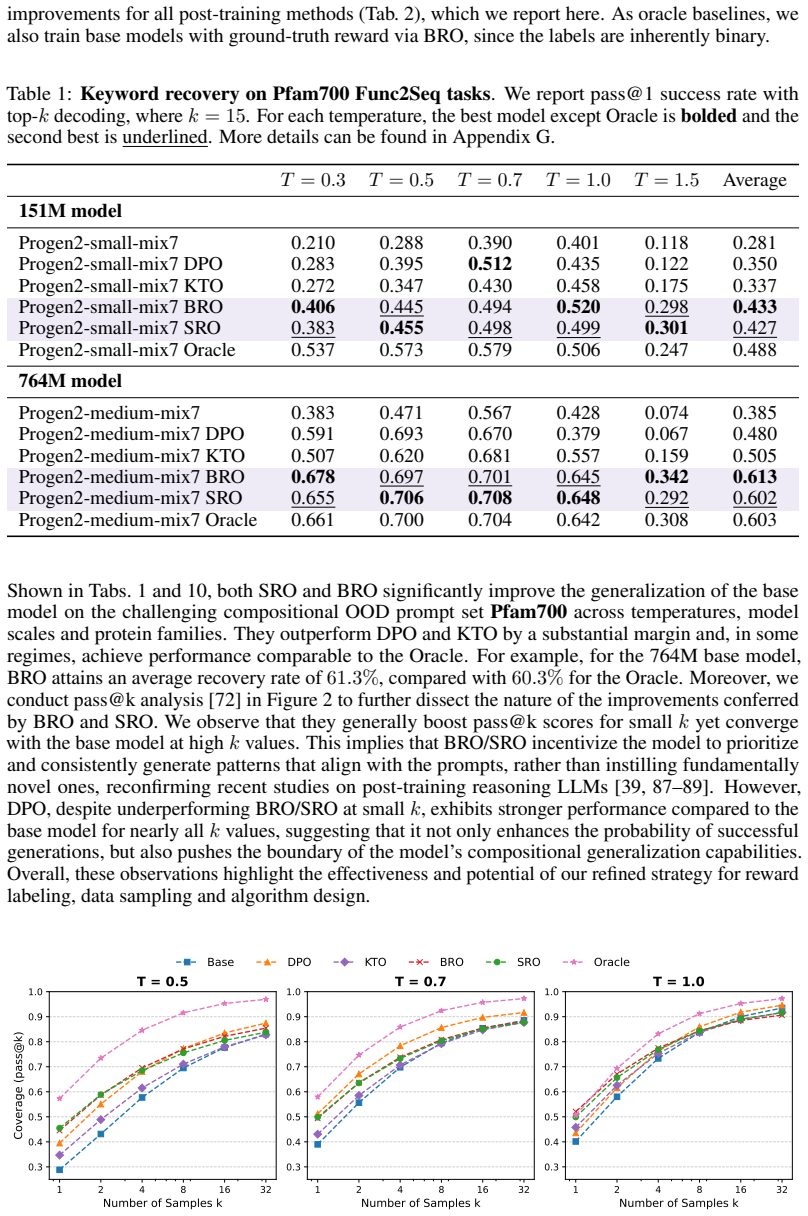
- SRO and BRO both outperform DPO and KTO on compositional out-of-distribution prompts.
- Performance approaches that of an oracle reward model across multiple sampling temperatures, model scales, and protein families.
- Fine-tuned models achieve consistently higher coverage than the base model in pass@k evaluations.
- Steerable biomolecular design becomes feasible in regimes where labeled preferences or experimental feedback are unavailable.
Where Pith is reading between the lines
- The same uncertainty-plus-consistency proxy construction may transfer to other sequence-generation domains if the correlation with controllability holds there.
- Iterative self-improvement loops become possible by repeatedly applying the method to the model's own outputs.
- The framework could reduce dependence on wet-lab validation for initial steering of generative models in biomolecular design.
Load-bearing premise
The proxy rewards derived from uncertainty and semantic consistency accurately stand in for actual controllability and can drive RLHF-style optimization without ground-truth labels.
What would settle it
A controlled test in which models fine-tuned with SRO or BRO show no gain, or a loss, in measured controllability on held-out compositional prompts relative to the base model or to DPO/KTO.
Figures
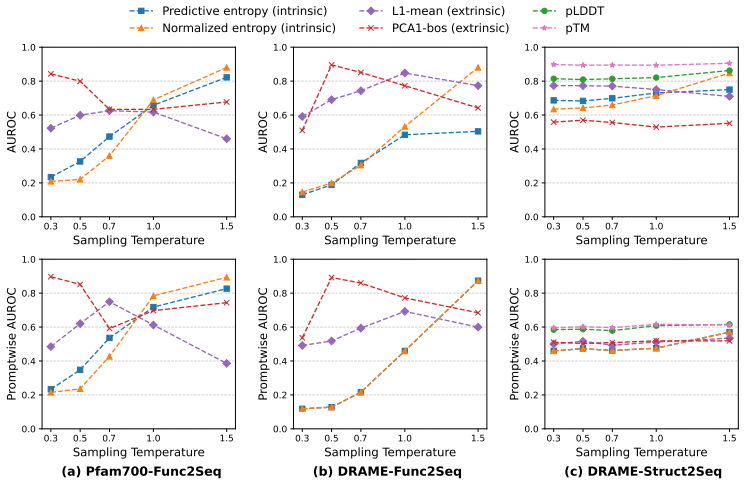
read the original abstract
Protein language models (PLMs) have emerged as powerful tools for controllable biomolecular design, yet their post-training adaptation typically relies on costly wet-lab validation or curated preference datasets. To overcome this supervision bottleneck, we introduce unsupervised reward optimization of PLMs, a comprehensive framework for steerable protein generation without ground-truth labels. Our key insight is that task-agnostic rewards, which combine intrinsic model uncertainty with extrinsic semantic consistency informed by protein representation models, exhibit strong correlation with controllability measures across base models and temperature regimes. Building upon this discovery, we propose two offline algorithms: Soft Reward Optimization (SRO) and Binarized Reward Optimization (BRO), which effectively maximize the classical RLHF objective induced by these proxy rewards. Extensive experiments on compositional out-of-distribution prompts demonstrate that both methods significantly outperform competitive baselines (DPO, KTO), while approaching oracle performance across multiple sampling temperatures, model scales and protein families. Moreover, PLMs fine-tuned with unsupervised rewards can achieve consistently higher coverage compared to their base model in pass@k evaluations. By enabling self-improvement of PLMs through their own generated experience, our framework provides a scalable pathway toward controllable biomolecular design in settings where labeled preferences or experimental feedback are scarce or unavailable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces unsupervised reward optimization for protein language models (PLMs), claiming that task-agnostic proxy rewards—combining intrinsic model uncertainty with extrinsic semantic consistency from protein representation models—strongly correlate with controllability across base models and temperatures. It proposes two offline algorithms, Soft Reward Optimization (SRO) and Binarized Reward Optimization (BRO), to maximize the induced RLHF objective without ground-truth labels, and reports that these methods outperform DPO and KTO on compositional out-of-distribution prompts while approaching oracle performance and improving pass@k coverage across scales and families.
Significance. If the reported correlations and performance gains hold under the held-out controllability metrics, this provides a scalable, label-free pathway for self-improvement of PLMs in biomolecular design. The experiments across multiple temperatures, model scales, protein families, and comparisons to DPO/KTO supply independent checks that address potential circularity concerns in the proxy rewards, strengthening the case for practical utility where experimental feedback is unavailable.
minor comments (3)
- The abstract asserts strong correlation and outperformance but would benefit from one or two key quantitative metrics (e.g., correlation coefficient or relative improvement) to allow readers to assess the claims without the full text.
- [§3] §3 (method): the precise formulation of the combined reward (uncertainty + semantic consistency) and how it induces the classical RLHF objective should include an explicit equation for reproducibility.
- Figure captions for the correlation plots and pass@k results could explicitly state the number of independent runs and error bars to clarify statistical robustness.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the recognition of its potential impact, and the recommendation for minor revision. We are pleased that the experiments across scales, temperatures, and families were viewed as addressing potential concerns about circularity in the proxy rewards.
Circularity Check
No significant circularity identified
full rationale
The paper frames the correlation between its task-agnostic proxy rewards (intrinsic uncertainty + extrinsic semantic consistency from separate protein representation models) and controllability measures as an empirical observation tested across base models, temperatures, and families. SRO and BRO are then defined as offline maximizers of the induced RLHF objective; the central results rest on held-out pass@k, compositional OOD, and baseline comparisons rather than any definitional reduction, fitted-input renaming, or self-citation chain. No equation or step equates a claimed prediction to its own construction inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task-agnostic rewards combining model uncertainty and semantic consistency correlate with controllability measures.
Reference graph
Works this paper leans on
-
[1]
Lawrence Zitnick, Jerry Ma, and Rob Fergus
Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences.PNAS, 2019. doi: 10.1101/622803. URLhttps://www.biorxiv.org/content/10.1101/622803v4
-
[2]
Unified rational protein engineering with sequence-based deep representation learning
Ethan C Alley, Grigory Khimulya, Surojit Biswas, Mohammed AlQuraishi, and George M Church. Unified rational protein engineering with sequence-based deep representation learning. Nature methods, 16(12):1315–1322, 2019
2019
-
[3]
Prottrans: Toward understanding the language of life through self-supervised learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):7112–7127,
Ahmed Elnaggar, Michael Heinzinger, Christian Dallago, Ghalia Rehawi, Yu Wang, Llion Jones, Tom Gibbs, Tamas Feher, Christoph Angerer, Martin Steinegger, Debsindhu Bhowmik, and Burkhard Rost. Prottrans: Toward understanding the language of life through self-supervised learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):7112–7127,
-
[4]
doi: 10.1109/TPAMI.2021.3095381
-
[5]
Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
2021
-
[6]
Accurate prediction of protein structures and interactions using a three-track neural network.Science, 373(6557):871–876, 2021
Minkyung Baek, Frank DiMaio, Ivan Anishchenko, Justas Dauparas, Sergey Ovchinnikov, Gyu Rie Lee, Jue Wang, Qian Cong, Lisa N Kinch, R Dustin Schaeffer, et al. Accurate prediction of protein structures and interactions using a three-track neural network.Science, 373(6557):871–876, 2021
2021
-
[7]
Jiayang Chen, Zhihang Hu, Siqi Sun, Qingxiong Tan, Yixuan Wang, Qinze Yu, Licheng Zong, Liang Hong, Jin Xiao, Tao Shen, et al. Interpretable rna foundation model from unannotated data for highly accurate rna structure and function predictions.arXiv preprint arXiv:2204.00300, 2022
-
[8]
Large language models generate functional protein sequences across diverse families.Nature biotechnology, 41 (8):1099–1106, 2023
Ali Madani, Ben Krause, Eric R Greene, Subu Subramanian, Benjamin P Mohr, James M Holton, Jose Luis Olmos Jr, Caiming Xiong, Zachary Z Sun, Richard Socher, et al. Large language models generate functional protein sequences across diverse families.Nature biotechnology, 41 (8):1099–1106, 2023
2023
-
[9]
De novo design of protein structure and function with rfdiffusion.Nature, 620(7976):1089–1100, 2023
Joseph L Watson, David Juergens, Nathaniel R Bennett, Brian L Trippe, Jason Yim, Helen E Eisenach, Woody Ahern, Andrew J Borst, Robert J Ragotte, Lukas F Milles, et al. De novo design of protein structure and function with rfdiffusion.Nature, 620(7976):1089–1100, 2023
2023
-
[10]
Saprot: Protein language modeling with structure-aware vocabulary
Jin Su, Chenchen Han, Yuyang Zhou, Junjie Shan, Xibin Zhou, and Fajie Yuan. Saprot: Protein language modeling with structure-aware vocabulary. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[11]
Sequence modeling and design from molecular to genome scale with evo.Science, 386(6723):eado9336, 2024
Eric Nguyen, Michael Poli, Matthew G Durrant, Brian Kang, Dhruva Katrekar, David B Li, Liam J Bartie, Armin W Thomas, Samuel H King, Garyk Brixi, et al. Sequence modeling and design from molecular to genome scale with evo.Science, 386(6723):eado9336, 2024
2024
-
[12]
Simulating 500 million years of evolution with a language model.Science, 387(6736):850–858, 2025
Thomas Hayes, Roshan Rao, Halil Akin, Nicholas J Sofroniew, Deniz Oktay, Zeming Lin, Robert Verkuil, Vincent Q Tran, Jonathan Deaton, Marius Wiggert, et al. Simulating 500 million years of evolution with a language model.Science, 387(6736):850–858, 2025
2025
-
[13]
Scalable emulation of protein equilibrium ensembles with generative deep learning.Science, 389(6761): eadv9817, 2025
Sarah Lewis, Tim Hempel, José Jiménez-Luna, Michael Gastegger, Yu Xie, Andrew YK Foong, Victor García Satorras, Osama Abdin, Bastiaan S Veeling, Iryna Zaporozhets, et al. Scalable emulation of protein equilibrium ensembles with generative deep learning.Science, 389(6761): eadv9817, 2025
2025
-
[14]
Boltz-2: Towards accurate and efficient binding affinity prediction.BioRxiv, 2025
Saro Passaro, Gabriele Corso, Jeremy Wohlwend, Mateo Reveiz, Stephan Thaler, Vignesh Ram Somnath, Noah Getz, Tally Portnoi, Julien Roy, Hannes Stark, et al. Boltz-2: Towards accurate and efficient binding affinity prediction.BioRxiv, 2025
2025
-
[15]
xtrimopglm: unified 100-billion-parameter pretrained transformer for deciphering the language of proteins.Nature Methods, 22(5):1028–1039, 2025
Bo Chen, Xingyi Cheng, Pan Li, Yangli-ao Geng, Jing Gong, Shen Li, Zhilei Bei, Xu Tan, Boyan Wang, Xin Zeng, et al. xtrimopglm: unified 100-billion-parameter pretrained transformer for deciphering the language of proteins.Nature Methods, 22(5):1028–1039, 2025. 10
2025
-
[16]
Shentong Mo and Lanqing Li. Sadit: Efficient protein backbone design via latent structural tokenization and diffusion transformers.arXiv preprint arXiv:2602.06706, 2026
-
[17]
Modeling aspects of the language of life through transfer-learning protein sequences.BMC bioinformatics, 20(1):723, 2019
Michael Heinzinger, Ahmed Elnaggar, Yu Wang, Christian Dallago, Dmitrii Nechaev, Florian Matthes, and Burkhard Rost. Modeling aspects of the language of life through transfer-learning protein sequences.BMC bioinformatics, 20(1):723, 2019
2019
-
[18]
Language models enable zero-shot prediction of the effects of mutations on protein function.Advances in neural information processing systems, 34:29287–29303, 2021
Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu, and Alex Rives. Language models enable zero-shot prediction of the effects of mutations on protein function.Advances in neural information processing systems, 34:29287–29303, 2021
2021
-
[19]
Transformer protein language models are unsupervised structure learners
Roshan Rao, Joshua Meier, Tom Sercu, Sergey Ovchinnikov, and Alexander Rives. Transformer protein language models are unsupervised structure learners. InInternational Conference on Learning Representations, 2021
2021
-
[20]
Progen2: exploring the boundaries of protein language models.Cell systems, 14(11):968–978, 2023
Erik Nijkamp, Jeffrey A Ruffolo, Eli N Weinstein, Nikhil Naik, and Ali Madani. Progen2: exploring the boundaries of protein language models.Cell systems, 14(11):968–978, 2023
2023
-
[21]
Controllable protein design with language models.Nature Machine Intelligence, 4(6):521–532, 2022
Noelia Ferruz and Birte Höcker. Controllable protein design with language models.Nature Machine Intelligence, 4(6):521–532, 2022
2022
-
[22]
Aligning protein generative models with experimental fitness via direct preference optimization.bioRxiv, pages 2024–05, 2024
Talal Widatalla, Rafael Rafailov, and Brian Hie. Aligning protein generative models with experimental fitness via direct preference optimization.bioRxiv, pages 2024–05, 2024
2024
-
[23]
Guiding generative protein language models with reinforcement learning, 2024
Filippo Stocco, Maria Artigues-Lleixa, Andrea Hunklinger, Talal Widatalla, Marc Guell, and Noelia Ferruz. Guiding generative protein language models with reinforcement learning, 2024. URLhttps://arxiv.org/abs/2412.12979
-
[24]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[25]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[26]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[28]
Pretraining language models with human preferences
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Vinayak Bhalerao, Christopher Buckley, Jason Phang, Samuel R Bowman, and Ethan Perez. Pretraining language models with human preferences. InInternational conference on machine learning, pages 17506–17533. PMLR, 2023
2023
-
[29]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[31]
Qwq-32b: Embracing the power of reinforcement learning, 2025
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, 2025. URL https: //qwenlm.github.io/blog/qwq-32b/
2025
-
[32]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Weak-to-strong generalization: Eliciting strong capabilities with weak supervision
Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold As- chenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, et al. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. InForty-first International Conference on Machine Learning
-
[35]
Welcome to the era of experience.Google AI, 1:11, 2025
David Silver and Richard S Sutton. Welcome to the era of experience.Google AI, 1:11, 2025
2025
-
[36]
How far can unsupervised RLVR scale LLM training? InThe Thirteenth International Conference on Learning Representations, 2026
Bingxiang He, Yuxin Zuo, Zeyuan Liu, Shangziqi Zhao, Zixuan Fu, Junlin Yang, Cheng Qian, Kaiyan Zhang, Yuchen Fan, Ganqu Cui, Xiusi Chen, Youbang Sun, Xingtai Lv, Xuekai Zhu, Li Sheng, Ran Li, Huan ang Gao, Yuchen Zhang, Lifan Yuan, Bowen Zhou, et al. How far can unsupervised RLVR scale LLM training? InThe Thirteenth International Conference on Learning R...
2026
-
[37]
Generalist biological artificial intelligence in modeling the language of life.Nature Biotechnology, pages 1–16, 2026
Vishwanatha M Rao, Serena Zhang, Brian S Plosky, Patrick D Hsu, Bo Wang, James Zou, Marinka Zitnik, Eric J Topol, and Pranav Rajpurkar. Generalist biological artificial intelligence in modeling the language of life.Nature Biotechnology, pages 1–16, 2026
2026
-
[38]
Absolute zero: Reinforced self-play reasoning with zero data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[39]
TTRL: Test-time reinforcement learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, Biqing Qi, Youbang Sun, Zhiyuan Ma, Lifan Yuan, Ning Ding, and Bowen Zhou. TTRL: Test-time reinforcement learning. InThirty-ninth Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum? id=VuVhgEiu20. Po...
2025
-
[40]
Right question is already half the answer: Fully unsupervised llm reasoning incentivization
Qingyang Zhang, Haitao Wu, Changqing Zhang, Peilin Zhao, and Yatao Bian. Right question is already half the answer: Fully unsupervised llm reasoning incentivization. InThirty-ninth Conference on Neural Information Processing Systems, 2025. URL https://openreview. net/forum?id=k8Mim6RI5O. Spotlight Presentation
2025
-
[41]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[42]
Model alignment as prospect theoretic optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Model alignment as prospect theoretic optimization. InInternational Conference on Machine Learning, pages 12634–12651. PMLR, 2024
2024
-
[43]
Pfam: the protein families database.Nucleic acids research, 42(D1):D222–D230, 2014
Robert D Finn, Alex Bateman, Jody Clements, Penelope Coggill, Ruth Y Eberhardt, Sean R Eddy, Andreas Heger, Kirstie Hetherington, Liisa Holm, Jaina Mistry, et al. Pfam: the protein families database.Nucleic acids research, 42(D1):D222–D230, 2014
2014
-
[44]
Generative artificial intelligence for de novo protein design.Current Opinion in Structural Biology, 86:102794, 2024
Adam Winnifrith, Carlos Outeiral, and Brian L Hie. Generative artificial intelligence for de novo protein design.Current Opinion in Structural Biology, 86:102794, 2024
2024
-
[45]
De novo protein design—from new structures to programmable functions
Tanja Kortemme. De novo protein design—from new structures to programmable functions. Cell, 187(3):526–544, 2024
2024
-
[46]
The past, present and future of de novo protein design.Nature, 652(8112):1139–1152, 2026
Wei Yang, Shunzhi Wang, Gyu Rie Lee, Jason Z Zhang, Alexis Courbet, David Juergens, Xinru Wang, Thomas Schlichthaerle, Mohamad Abedi, Robert Ragotte, et al. The past, present and future of de novo protein design.Nature, 652(8112):1139–1152, 2026
2026
-
[47]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 12
2017
-
[48]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[49]
Prollama: A protein large language model for multi-task protein language processing.IEEE Transactions on Artificial Intelligence, 2025
Liuzhenghao Lv, Zongying Lin, Hao Li, Yuyang Liu, Jiaxi Cui, Calvin Yu-Chian Chen, Li Yuan, and Yonghong Tian. Prollama: A protein large language model for multi-task protein language processing.IEEE Transactions on Artificial Intelligence, 2025
2025
-
[50]
Rapid in silico directed evolution by a protein language model with evolvepro.Science, 387 (6732):eadr6006, 2024
Kaiyi Jiang, Zhaoqing Yan, Matteo Di Bernardo, Samantha R Sgrizzi, Lukas Villiger, Alisan Kayabolen, BJ Kim, Josephine K Carscadden, Masahiro Hiraizumi, Hiroshi Nishimasu, et al. Rapid in silico directed evolution by a protein language model with evolvepro.Science, 387 (6732):eadr6006, 2024
2024
-
[51]
Machine-learning-guided directed evolution for protein engineering.Nature methods, 16(8):687–694, 2019
Kevin K Yang, Zachary Wu, and Frances H Arnold. Machine-learning-guided directed evolution for protein engineering.Nature methods, 16(8):687–694, 2019
2019
-
[52]
Steering protein language models
Long-Kai Huang, Rongyi Zhu, Bing He, and Jianhua Yao. Steering protein language models. InInternational Conference on Machine Learning, pages 26247–26260. PMLR, 2025
2025
-
[53]
Evaluating Large Language Models in Scientific Discovery
Zhangde Song, Jieyu Lu, Yuanqi Du, Botao Yu, Thomas M Pruyn, Yue Huang, Kehan Guo, Xiuzhe Luo, Yuanhao Qu, Yi Qu, et al. Evaluating large language models in scientific discovery. arXiv preprint arXiv:2512.15567, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Learning to reason without external rewards
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to reason without external rewards. 2026. URL https://openreview.net/forum?id= OU9nFEYR2M
2026
-
[55]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
The unreasonable effectiveness of entropy minimization in LLM reasoning
Shivam Agarwal, Zimin Zhang, Lifan Yuan, Jiawei Han, and Hao Peng. The unreasonable effectiveness of entropy minimization in LLM reasoning. InThirty-ninth Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= UfFTBEsLgI. Poster Presentation
2025
-
[57]
Parshin Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K
Sheikh Shafayat, Fahim Tajwar, Ruslan Salakhutdinov, Jeff Schneider, and Andrea Zanette. Can large reasoning models self-train?arXiv preprint arXiv:2505.21444, 2025
-
[58]
No free lunch: Rethinking internal feedback for llm reasoning.arXiv preprint arXiv:2506.17219, 2025
Yanzhi Zhang, Zhaoxi Zhang, Haoxiang Guan, Yilin Cheng, Yitong Duan, Chen Wang, Yue Wang, Shuxin Zheng, and Jiyan He. No free lunch: Rethinking internal feedback for llm reasoning.arXiv preprint arXiv:2506.17219, 2025
-
[59]
Reinforcement pre-training.arXiv preprint arXiv:2506.08007, 2025
Qingxiu Dong, Li Dong, Yao Tang, Tianzhu Ye, Yutao Sun, Zhifang Sui, and Furu Wei. Reinforcement pre-training.arXiv preprint arXiv:2506.08007, 2025
-
[60]
Rlp: Reinforcement as a pretraining objective.arXiv preprint arXiv:2510.01265, 2025
Ali Hatamizadeh, Syeda Nahida Akter, Shrimai Prabhumoye, Jan Kautz, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, and Yejin Choi. Rlp: Reinforcement as a pretraining objective.arXiv preprint arXiv:2510.01265, 2025
-
[61]
Shuaijie She, Yu Bao, Yu Lu, Lu Xu, Tao Li, Wenhao Zhu, Shujian Huang, Shanbo Cheng, Lu Lu, and Yuxuan Wang. Dupo: Enabling reliable llm self-verification via dual preference optimization.arXiv preprint arXiv:2508.14460, 2025
-
[62]
Nemotron- crossthink: Scaling self-learning beyond math reasoning
Syeda Nahida Akter, Shrimai Prabhumoye, Matvei Novikov, Seungju Han, Ying Lin, Evelina Bakhturina, Eric Nyberg, Yejin Choi, Mostofa Patwary, Mohammad Shoeybi, et al. Nemotron- crossthink: Scaling self-learning beyond math reasoning. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Lon...
2026
-
[63]
Toby Simonds and Akira Yoshiyama. Ladder: Self-improving llms through recursive problem decomposition.arXiv preprint arXiv:2503.00735, 2025. 13
-
[64]
Deepseekmath-v2: Towards self-verifiable mathematical reasoning
Zhihong Shao, Yuxiang Luo, Chengda Lu, ZZ Ren, Jiewen Hu, Tian Ye, Zhibin Gou, Shirong Ma, and Xiaokang Zhang. Deepseekmath-v2: Towards self-verifiable mathematical reasoning. arXiv preprint arXiv:2511.22570, 2025
-
[65]
Olympiad-level formal mathematical reasoning with reinforcement learning.Nature, pages 1–3, 2025
Thomas Hubert, Rishi Mehta, Laurent Sartran, Miklós Z Horváth, Goran Žuži´c, Eric Wieser, Aja Huang, Julian Schrittwieser, Yannick Schroecker, Hussain Masoom, et al. Olympiad-level formal mathematical reasoning with reinforcement learning.Nature, pages 1–3, 2025
2025
-
[66]
Esm cambrian: Revealing the mysteries of proteins with unsupervised learning,
ESM Team. Esm cambrian: Revealing the mysteries of proteins with unsupervised learning,
-
[67]
URLhttps://evolutionaryscale.ai/blog/esm-cambrian
-
[68]
Finetuned language models are zero-shot learners
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. In International Conference on Learning Representations, 2022
2022
-
[69]
Maximum entropy inverse reinforcement learning
Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, Anind K Dey, et al. Maximum entropy inverse reinforcement learning. InAaai, volume 8, pages 1433–1438. Chicago, IL, USA, 2008
2008
-
[70]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. InInternational conference on machine learning, pages 1352–1361. PMLR, 2017
2017
-
[71]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[72]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[73]
Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
2024
-
[74]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[75]
Hot or cold? adaptive temperature sampling for code generation with large language models
Yuqi Zhu, Jia Li, Ge Li, YunFei Zhao, Zhi Jin, and Hong Mei. Hot or cold? adaptive temperature sampling for code generation with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 437–445, 2024
2024
-
[76]
Shimao Zhang, Yu Bao, and Shujian Huang. Edt: Improving large language models’ generation by entropy-based dynamic temperature sampling.arXiv preprint arXiv:2403.14541, 2024
-
[77]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[78]
https://doi.org/10.1109/BIBM62325.2024.10821806
Hugo Hrbá ˇn and David Hoksza. Protein family sequence generation through progen2 fine- tuning. In2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 7037–7039, 2024. doi: 10.1109/BIBM62325.2024.10821712
-
[79]
Interpro in 2022.Nucleic acids research, 51(D1):D418–D427, 2023
Typhaine Paysan-Lafosse, Matthias Blum, Sara Chuguransky, Tiago Grego, Beatriz Lázaro Pinto, Gustavo A Salazar, Maxwell L Bileschi, Peer Bork, Alan Bridge, Lucy Colwell, et al. Interpro in 2022.Nucleic acids research, 51(D1):D418–D427, 2023
2022
-
[80]
Learning inverse folding from millions of predicted structures
Chloe Hsu, Robert Verkuil, Jason Liu, Zeming Lin, Brian Hie, Tom Sercu, Adam Lerer, and Alexander Rives. Learning inverse folding from millions of predicted structures. InInternational conference on machine learning, pages 8946–8970. PMLR, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.