Leadership as Coordination Control: Behavioral Signatures and the Recovery-Advantage Boundary in Multi-Agent LLM Teams
Pith reviewed 2026-06-26 21:12 UTC · model grok-4.3
The pith
Coordination controllers in multi-agent LLM teams improve accuracy only when the round-0 majority is unreliable, the task is recoverable, and plain interaction fails to repair it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
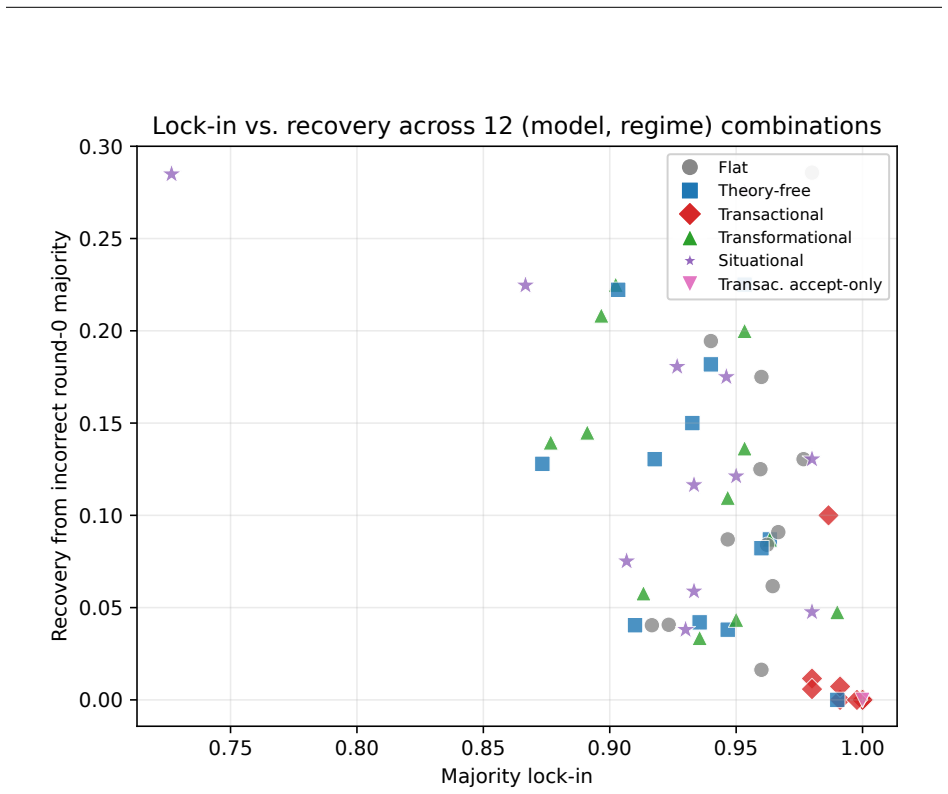
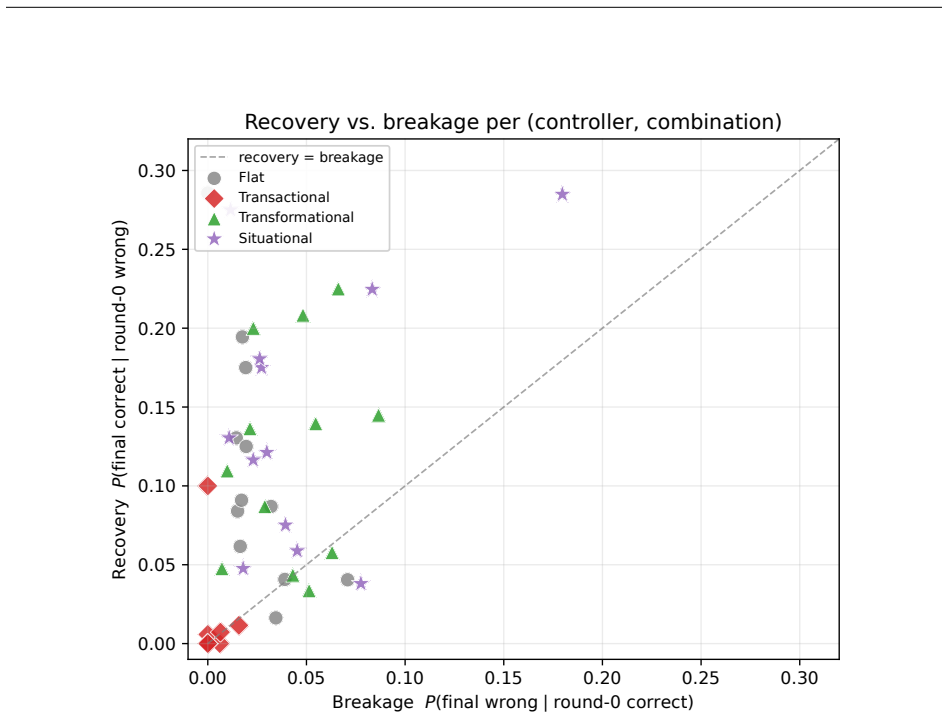
A recovery-advantage account, tested with four boundary probes, says a controller beats plain interaction only where the round-0 majority is unreliable, the task is recoverable, and undirected interaction does not already repair it. These regions map onto contingency theory (leadership substitutes, path-goal redundancy, the situational readiness gap), so a largely null accuracy result is what the theory predicts, not a failure of the controllers. Transactional control matches a shared round-0 vote on all 12 combinations to within 1.3pp, and gains appear only on the one combination where the round-0 majority is unreliable.
What carries the argument
Explicit controllers over the shared action vocabulary (explore, revise, accept, synthesize) that operationalize transactional, transformational, and situational leadership styles, evaluated via behavioral signatures of majority lock-in, exploration, and recovery.
If this is right
- A matched controller using an arbitrary rule recovers no better than majority voting, showing the theory-derived rule does the work.
- Situational control yields an 8pp gain over flat interaction only in the single unreliable round-0 case with llama-4-scout on social tasks.
- No controller dominates accuracy across four task regimes and three open-weight model families.
- Behavioral signatures allow clean per-action ablations because each controller is an explicit action set rather than a monolithic prompt.
Where Pith is reading between the lines
- The same boundary-probe method could be applied to test whether human-AI hybrid teams exhibit analogous recovery thresholds.
- Designers of multi-agent systems might add controllers only after measuring round-0 reliability and recoverability on the target task distribution.
- The finding implies that universal coordination prompts may impose unnecessary overhead when undirected interaction already suffices.
Load-bearing premise
The operationalization of classical leadership styles as explicit controllers over a shared action vocabulary validly captures the intended theoretical constructs.
What would settle it
Observing no recovery advantage from a theory-derived controller in a regime where the round-0 majority is unreliable, the task is recoverable, and undirected interaction does not already repair errors would falsify the account.
Figures
read the original abstract
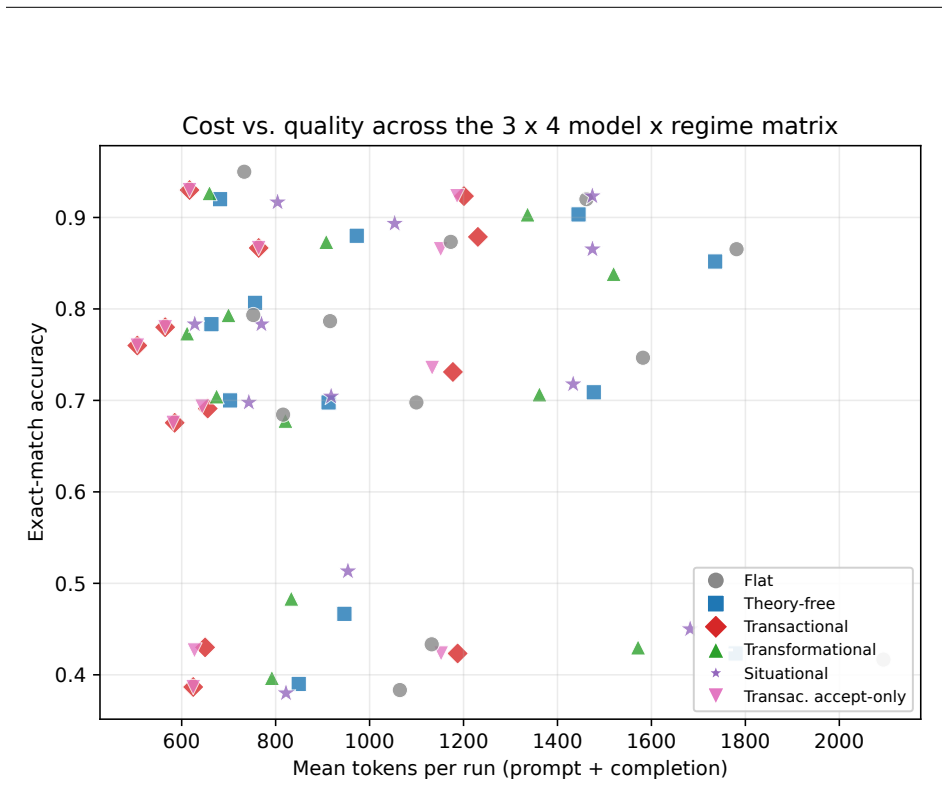
Team science holds that leadership is contingent: it helps only under specific conditions, and capable, autonomous teams may need none at all. We ask the analogous question for multi-agent LLM teams: under what measurable conditions does process-level coordination control add value, and do those conditions match what team science predicts? We use behavioral signatures (majority lock-in, exploration, recovery from an incorrect round-0 consensus) and per-action ablations, clean because each controller is an explicit action set, not a monolithic prompt. We operationalize three classical leadership styles (transactional, transformational, situational) as controllers over a shared action vocabulary (explore, revise, accept, synthesize). A matched controller with the same actions but an arbitrary rule recovers no better than majority voting, so the theory-derived rule, not the vocabulary, does the work. Across four task regimes and three open-weight model families, no controller dominates by accuracy, as the contingency view predicts: transactional control matches a shared round-0 vote on all 12 (model, regime) combinations to within 1.3pp, and gains appear only on the one combination where the round-0 majority is unreliable (llama-4-scout social; situational +8pp over flat). A recovery-advantage account, tested with four boundary probes, says a controller beats plain interaction only where the round-0 majority is unreliable, the task is recoverable, and undirected interaction does not already repair it. These regions map onto contingency theory (leadership substitutes, path-goal redundancy, the situational readiness gap), so a largely null accuracy result is what the theory predicts, not a failure of the controllers. We read process-level coordination control as a contingency to be measured and theory-mapped, not a leaderboard to be topped.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that process-level coordination control in multi-agent LLM teams adds value only under specific conditions matching contingency theory from team science. Operationalizing transactional, transformational, and situational leadership as explicit controllers over a shared action vocabulary (explore, revise, accept, synthesize), the authors report largely null accuracy results across 12 (model, regime) pairs, with gains only on the single case where round-0 majority is unreliable (llama-4-scout social, situational +8pp). A matched arbitrary-rule controller using the same vocabulary performs no better than flat majority voting. Behavioral signatures (majority lock-in, exploration, recovery) and four boundary probes support a recovery-advantage account: controllers outperform plain interaction only when the round-0 majority is unreliable, the task is recoverable, and undirected interaction does not already repair it; these regions are argued to map onto contingency-theory constructs such as leadership substitutes and the situational readiness gap.
Significance. If the recovery-advantage account and its mapping hold, the work provides a falsifiable, theory-linked framework for when coordination control is beneficial in LLM teams rather than seeking universal gains. Strengths include the matched arbitrary-rule controller isolating the effect of theory-derived rules (not the action vocabulary), the use of observable behavioral signatures tied to process outcomes, and testing across multiple open-weight models and regimes. This approach turns a largely null accuracy result into a predicted outcome under contingency theory and offers a measurable alternative to leaderboard-style evaluation of multi-agent systems.
major comments (2)
- [boundary probes / recovery-advantage account] Section describing the four boundary probes: the recovery-advantage account is tested by identifying regions where controllers outperform plain interaction. It is not stated whether the conditions (unreliable round-0 majority, recoverable task, undirected interaction fails to repair) were pre-registered or defined prior to inspecting results; if identified post-hoc, this introduces selection-bias risk that undermines the claim that the observed regions map onto contingency theory.
- [controller definitions / operationalization] Methods section on controller operationalization: the claim that the three classical styles are validly instantiated as controllers over the shared action vocabulary rests on the authors' rule definitions. Explicit pseudocode or decision tables for each style (transactional, transformational, situational) are needed to allow independent verification that the rules capture the intended constructs without circularity in the mapping to contingency theory.
minor comments (2)
- [abstract / results] Abstract and results: the statement that transactional control 'matches a shared round-0 vote on all 12 combinations to within 1.3pp' would be strengthened by reporting per-condition standard errors, confidence intervals, or statistical tests for equivalence rather than point differences alone.
- [results tables/figures] Figure or table presenting the 12 model-regime accuracy values: include error bars and the arbitrary-rule controller baseline in the same panel to facilitate direct visual comparison with the theory-derived controllers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important issues of transparency and verifiability that we address below. We are prepared to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [boundary probes / recovery-advantage account] Section describing the four boundary probes: the recovery-advantage account is tested by identifying regions where controllers outperform plain interaction. It is not stated whether the conditions (unreliable round-0 majority, recoverable task, undirected interaction fails to repair) were pre-registered or defined prior to inspecting results; if identified post-hoc, this introduces selection-bias risk that undermines the claim that the observed regions map onto contingency theory.
Authors: The four boundary probes were motivated by contingency-theory constructs (leadership substitutes, path-goal redundancy, situational readiness gap) and defined prior to inspecting the per-(model, regime) accuracy tables. However, they were not formally pre-registered. To mitigate any appearance of post-hoc selection, we will add an explicit subsection that (a) states the theoretical derivation of each probe, (b) lists the exact operational criteria used, and (c) reports the probes as confirmatory tests of the recovery-advantage account rather than exploratory discoveries. This revision will make the mapping to theory fully transparent without altering the reported results. revision: yes
-
Referee: [controller definitions / operationalization] Methods section on controller operationalization: the claim that the three classical styles are validly instantiated as controllers over the shared action vocabulary rests on the authors' rule definitions. Explicit pseudocode or decision tables for each style (transactional, transformational, situational) are needed to allow independent verification that the rules capture the intended constructs without circularity in the mapping to contingency theory.
Authors: We agree that explicit decision tables and pseudocode are necessary for independent verification. In the revised Methods section we will insert (i) a decision table for each controller showing the exact conditions under which each action (explore, revise, accept, synthesize) is selected and (ii) concise pseudocode that implements those rules. These additions will allow readers to confirm that the operationalizations are non-circular with respect to the contingency-theory constructs they are intended to instantiate. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper derives its central recovery-advantage account from direct empirical tests: per-action ablations, a matched arbitrary-rule controller that performs no better than majority voting, and four boundary probes across models and regimes. Observable signatures (lock-in, exploration, recovery) and accuracy deltas are measured independently of the contingency-theory mapping, which is presented as post-hoc interpretive alignment with external team-science literature rather than a self-derived definition or fitted input. No equations, self-citations, or ansatzes reduce the load-bearing claims to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Leadership styles can be faithfully operationalized as controllers over a fixed action set (explore, revise, accept, synthesize) without loss of theoretical meaning.
- domain assumption Behavioral signatures (majority lock-in, exploration, recovery from incorrect round-0 consensus) are valid proxies for the process-level differences predicted by contingency theory.
Reference graph
Works this paper leans on
-
[1]
URL https://openlibrary.org/books/OL2861879M/Leadership_and_performance_beyond_expectations. Chandra Bhagavatula, Ronan Le Bras, Chaitanya Malaviya, Keisuke Sakaguchi, Ari Holtzman, Hannah Rashkin, Doug Downey, Scott Wen-tau Yih, and Yejin Choi. Abductive commonsense reasoning.arXiv preprint arXiv:1908.05739,
-
[2]
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu
URL https://openlibrary.org/books/ OL22822398M/Leadership. Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. InInternational conference on learning representations, volume 2024, pp. 9079–9093,
2024
-
[3]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. InInternational Conference on Learning Representations, volume 2024, pp. 20094–20136,
2024
-
[4]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate.arXiv preprint arXiv:2305.14325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Social chemistry 101: Learning to reason about social and moral norms
Maxwell Forbes, Jena D Hwang, Vered Shwartz, Maarten Sap, and Yejin Choi. Social chemistry 101: Learning to reason about social and moral norms. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 653–670,
2020
-
[6]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, volume 2024, pp. 23247–23275,
2024
-
[8]
Encouraging divergent thinking in large language models through multi-agent debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi-agent debate. In Proceedings of the 2024 conference on empirical methods in natural language processing, pp. 17889–17904,
2024
-
[9]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pp. 39578–39601,
2024
-
[10]
Rasika Muralidharan, Haewoon Kwak, and Jisun An. Can lessons from human teams be applied to multi-agent systems? the role of structure, diversity, and interaction dynamics.arXiv preprint arXiv:2510.07488,
-
[11]
Commonsenseqa: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4149–4158,
2019
-
[12]
A Curation Protocol and Reporting Layers This appendix documents the evaluation construction logic used throughout the paper. Our goal is not to optimize subsets for any single policy, but to isolate coordination regimes that are otherwise diluted by trivial items, annotation-sensitive items, or task formulations that do not induce the intended interactio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.