One Demo is Worth a Thousand Trajectories: Action-View Augmentation for Visuomotor Policies
Pith reviewed 2026-06-26 20:28 UTC · model grok-4.3
The pith
Augmenting one fisheye demonstration via scene reconstruction and trajectory optimization improves visuomotor policy success rates on manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
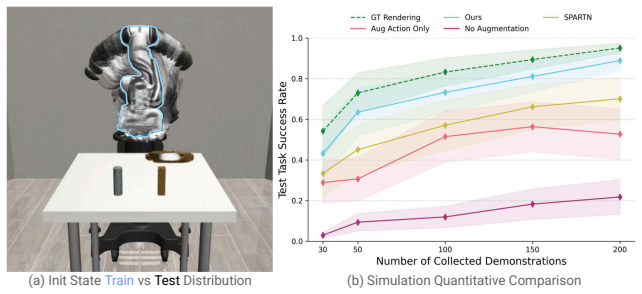
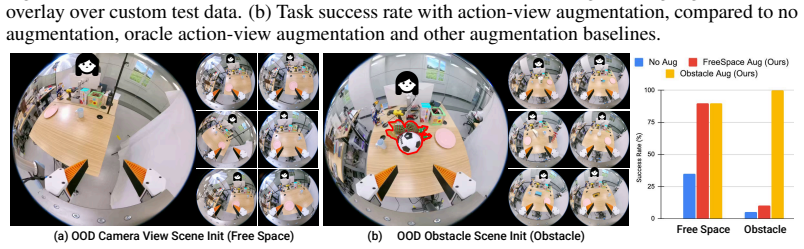
The central claim is that the proposed augmentation framework generates visually realistic fisheye image sequences and corresponding physically feasible action trajectories from real-world eye-in-hand demonstrations by using a novel Gaussian Splatting formulation adapted to wide field-of-view fisheye cameras to reconstruct and edit the 3D scene, along with trajectory optimization to produce smooth collision-free paths, leading to higher success rates in both the original and augmented scenes.
What carries the argument
A Gaussian Splatting formulation adapted to fisheye cameras for 3D scene reconstruction and editing, paired with trajectory optimization to create new executable action sequences.
If this is right
- The framework improves success rates for various manipulation tasks in the same scene.
- Success rates also rise in scenes with added obstacles that require collision avoidance.
- The improvements appear in both simulation experiments and real-world tests.
- The generated trajectories remain physically feasible and executable on the robot.
Where Pith is reading between the lines
- The method could extend to other types of cameras or robot configurations if the underlying reconstruction holds up.
- Adding dynamic elements to the edited scenes might enable training for tasks with moving obstacles.
- Measuring the reduction in required original demonstrations for a target performance level would test its efficiency gains.
Load-bearing premise
The Gaussian Splatting must reconstruct the fisheye scene accurately enough to support realistic rendering of novel views and edited scenes with obstacles.
What would settle it
If a policy trained on the augmented data achieves the same or lower success rate than one trained only on the single original demonstration when tested with new obstacles, the claim would be false.
Figures




read the original abstract
Visuomotor policies for manipulation have demonstrated remarkable potential in modeling complex robotic behaviors, yet minor alterations in the robot's initial configuration and unseen obstacles easily lead to out-of-distribution observations. Without extensive data collection effort, these result in catastrophic execution failures. In this work, we introduce an effective data augmentation framework that generates visually realistic fisheye image sequences and corresponding physically feasible action trajectories from real-world eye-in-hand demonstrations, captured with a portable parallel gripper with a single fisheye camera. We introduce a novel Gaussian Splatting formulation, adapted to wide FoV fisheye cameras, to reconstruct and edit the 3D scene with unseen objects. We utilize trajectory optimization to generate smooth, collision-free, view-rendering-friendly action trajectories and render visual observations from corresponding novel views. Comprehensive experiments in simulation and the real world show that our augmentation framework improves the success rate for various manipulation tasks in both the same scene and the augmented scene with obstacles requiring collision avoidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an action-view augmentation framework for visuomotor policies that reconstructs 3D scenes from a single real-world eye-in-hand fisheye demonstration using a novel wide-FoV Gaussian Splatting adaptation, optimizes smooth collision-free trajectories, renders novel views, and augments training data to improve policy success rates on manipulation tasks in both original and obstacle-augmented scenes.
Significance. If the reported gains are substantiated with quantitative validation, the method offers a practical route to data-efficient visuomotor learning by synthesizing diverse, physically feasible training trajectories and views from minimal demonstrations, directly addressing out-of-distribution failures in real-world manipulation.
major comments (2)
- [Abstract] Abstract: the central claim that the framework 'improves the success rate for various manipulation tasks' is stated without any numerical results, baseline comparisons, ablation studies, or statistical details, rendering the empirical contribution unverifiable from the provided text.
- [Method] Gaussian Splatting adaptation (method section): the claim that rendered novel fisheye views are sufficiently realistic to train generalizable policies rests on the adapted 3DGS reconstruction, yet no quantitative metrics (PSNR, SSIM, or held-out view-synthesis error on real fisheye frames) are supplied to validate reconstruction fidelity or artifact levels.
minor comments (1)
- [Experiments] Clarify in the experiments section how trajectory optimization constraints ensure direct executability on the physical robot without additional compliance adjustments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the framework 'improves the success rate for various manipulation tasks' is stated without any numerical results, baseline comparisons, ablation studies, or statistical details, rendering the empirical contribution unverifiable from the provided text.
Authors: We agree that the abstract would benefit from greater specificity. In the revised version we will include key quantitative results from the simulation and real-world experiments, such as success-rate improvements relative to baselines, to make the empirical claims verifiable directly from the abstract. revision: yes
-
Referee: [Method] Gaussian Splatting adaptation (method section): the claim that rendered novel fisheye views are sufficiently realistic to train generalizable policies rests on the adapted 3DGS reconstruction, yet no quantitative metrics (PSNR, SSIM, or held-out view-synthesis error on real fisheye frames) are supplied to validate reconstruction fidelity or artifact levels.
Authors: We acknowledge that the current manuscript does not report quantitative reconstruction metrics. While downstream policy performance serves as the primary validation, we agree that PSNR, SSIM, and held-out view-synthesis error would strengthen the claim of reconstruction fidelity. We will add these metrics, computed on held-out real fisheye frames, in the revised manuscript. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an engineering framework for data augmentation via adapted Gaussian Splatting reconstruction of fisheye scenes followed by trajectory optimization to generate novel views and actions. No equations, fitted parameters, or self-citations are described that reduce any reported success-rate improvement to an input by construction. The central claims rest on experimental validation in simulation and real-world settings rather than on any self-referential definition or renaming of known results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.arXiv preprint arXiv:2303.04137, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
N. M. Shafiullah, Z. Cui, A. A. Altanzaya, and L. Pinto. Behavior transformers: Cloningk modes with one stone.Advances in neural information processing systems, 35:22955–22968, 2022
2022
-
[4]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011
2011
-
[5]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
S. Mirchandani, S. Belkhale, J. Hejna, E. Choi, M. S. Islam, and D. Sadigh. So you think you can scale up autonomous robot data collection?arXiv preprint arXiv:2411.01813, 2024. 9
-
[7]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[8]
Shorten and T
C. Shorten and T. M. Khoshgoftaar. A survey on image data augmentation for deep learning. Journal of big data, 6(1):1–48, 2019
2019
-
[9]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Hansen and X
N. Hansen and X. Wang. Generalization in reinforcement learning by soft data augmentation. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13611– 13617. IEEE, 2021
2021
-
[11]
Laskin, K
M. Laskin, K. Lee, A. Stooke, L. Pinto, P. Abbeel, and A. Srinivas. Reinforcement learning with augmented data.Advances in neural information processing systems, 33:19884–19895, 2020
2020
-
[12]
Yarats, I
D. Yarats, I. Kostrikov, and R. Fergus. Image augmentation is all you need: Regularizing deep reinforcement learning from pixels. InInternational conference on learning representations, 2021
2021
-
[13]
Z. Chen, Z. Mandi, H. Bharadhwaj, M. Sharma, S. Song, A. Gupta, and V . Kumar. Semanti- cally controllable augmentations for generalizable robot learning.The International Journal of Robotics Research, page 02783649241273686, 2024
2024
-
[14]
T. Yu, T. Xiao, A. Stone, J. Tompson, A. Brohan, S. Wang, J. Singh, C. Tan, J. Peralta, B. Ichter, et al. Scaling robot learning with semantically imagined experience.arXiv preprint arXiv:2302.11550, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Zero-Shot Robotic Manipulation with Pretrained Image-Editing Diffusion Models
K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine. Zero- shot robotic manipulation with pretrained image-editing diffusion models.arXiv preprint arXiv:2310.10639, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [16]
- [17]
-
[18]
Florence, L
P. Florence, L. Manuelli, and R. Tedrake. Self-supervised correspondence in visuomotor policy learning.IEEE Robotics and Automation Letters, 5(2):492–499, 2019
2019
- [19]
-
[20]
Deshpande, L
A. Deshpande, L. Ke, Q. Pfeifer, A. Gupta, and S. S. Srinivasa. Data efficient behavior cloning for fine manipulation via continuity-based corrective labels. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8531–8538. IEEE, 2024
2024
-
[21]
P. Mitrano and D. Berenson. Data augmentation for manipulation.arXiv preprint arXiv:2205.02886, 2022
-
[22]
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. arXiv preprint arXiv:2310.17596, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [23]
- [24]
- [25]
-
[26]
C. Pan, B. Okorn, H. Zhang, B. Eisner, and D. Held. Tax-pose: Task-specific cross-pose esti- mation for robot manipulation. InConference on Robot Learning, pages 1783–1792. PMLR, 2023
2023
-
[27]
Tagliabue and J
A. Tagliabue and J. P. How. Tube-nerf: Efficient imitation learning of visuomotor policies from mpc via tube-guided data augmentation and nerfs.IEEE Robotics and Automation Letters, 2024
2024
-
[28]
J. Low, M. Adang, J. Yu, K. Nagami, and M. Schwager. Sous vide: Cooking visual drone navigation policies in a gaussian splatting vacuum.IEEE Robotics and Automation Letters, 2025
2025
-
[29]
A. Zhou, M. J. Kim, L. Wang, P. Florence, and C. Finn. Nerf in the palm of your hand: Cor- rective augmentation for robotics via novel-view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17907–17917, 2023
2023
- [30]
-
[31]
Hoque, A
R. Hoque, A. Mandlekar, C. Garrett, K. Goldberg, and D. Fox. Intervengen: Interventional data generation for robust and data-efficient robot imitation learning. In2024 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), pages 2840–2846. IEEE, 2024
2024
-
[32]
C. Garrett, A. Mandlekar, B. Wen, and D. Fox. Skillmimicgen: Automated demonstration generation for efficient skill learning and deployment.arXiv preprint arXiv:2410.18907, 2024
-
[33]
S. Yang, W. Yu, J. Zeng, J. Lv, K. Ren, C. Lu, D. Lin, and J. Pang. Novel demonstration generation with gaussian splatting enables robust one-shot manipulation.RSS, 2025
2025
- [34]
-
[35]
J. L. Sch ¨onberger and J.-M. Frahm. Structure-from-motion revisited. InConference on Com- puter Vision and Pattern Recognition (CVPR), 2016
2016
-
[36]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4):1–14, 2023
2023
-
[37]
Kannala and S
J. Kannala and S. S. Brandt. A generic camera model and calibration method for conven- tional, wide-angle, and fish-eye lenses.IEEE transactions on pattern analysis and machine intelligence, 28(8):1335–1340, 2006
2006
-
[38]
Deitke, D
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. VanderBilt, L. Schmidt, K. Ehsani, A. Kembhavi, and A. Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13142–13153, 2023. 11
2023
-
[39]
Karaman and E
S. Karaman and E. Frazzoli. Sampling-based algorithms for optimal motion planning.The international journal of robotics research, 30(7):846–894, 2011
2011
-
[40]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
2021
-
[41]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transform- ers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[42]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[44]
Z. Zhu, Z. Fan, Y . Jiang, and Z. Wang. Fsgs: Real-time few-shot view synthesis using gaussian splatting. InEuropean conference on computer vision, pages 145–163. Springer, 2024
2024
-
[45]
Chung, J
J. Chung, J. Oh, and K. M. Lee. Depth-regularized optimization for 3d gaussian splatting in few-shot images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 811–820, 2024
2024
-
[46]
Huang, Z
B. Huang, Z. Yu, A. Chen, A. Geiger, and S. Gao. 2d gaussian splatting for geometrically accurate radiance fields. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024. 12 A.1 How Much to Augment? Fig. A1:How much to augment?While larger augmentation range could increase the data diver- sity, it also reduces the image rendering quality due to limited d...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.