Creating Multilingual Mental Health Dialogue Datasets: Limits of Persona-Based Localization via Nationality and Language
Pith reviewed 2026-06-26 20:26 UTC · model grok-4.3
The pith
Modifying only nationality and language in English mental health personas produces inconsistent depression severity across languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
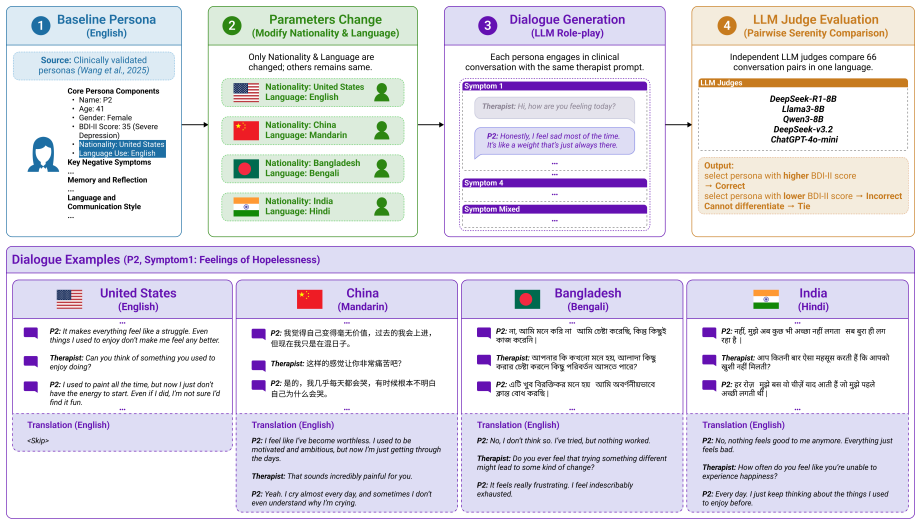
We modified nationality and language parameters in personas to generate clinical dialogues in Mandarin, Bengali, and Hindi. We then examined how different LLMs perform when evaluating the depression severity of these generated multilingual datasets against the baseline in English. Our findings indicate that just adding nationality and language parameters in personas might not be adequate, as it can introduce clinical inconsistency across languages. LLM judge models often exhibit inaccuracies in assessing depression severity in non-English texts, with performance varying across different models. This exposes the systemic limitations of applying English-centric personas to multilingual context
What carries the argument
The localization method that changes only nationality and language fields inside validated English clinical personas, followed by LLM-based consistency checks on generated dialogue depression severity.
If this is right
- Simple nationality and language swaps in personas are insufficient to maintain clinical consistency across languages.
- LLM judges show language-dependent inaccuracies when scoring depression severity, limiting their use for multilingual validation.
- English-centric persona libraries cannot be directly extended to other languages without additional adaptation steps.
- Equitable global mental health AI systems require generation methods that incorporate cultural context beyond basic parameters.
Where Pith is reading between the lines
- Native clinician review or culturally specific instruments may be needed to validate multilingual synthetic data before use.
- The observed model-to-model variation in non-English scoring suggests that evaluation pipelines themselves need language-specific calibration.
- Future dataset creation could test whether adding explicit cultural values or symptom expression norms reduces the inconsistencies found here.
Load-bearing premise
That comparing LLM depression-severity scores on non-English dialogues against an English baseline reliably reveals true clinical inconsistency.
What would settle it
A controlled study in which native-speaking clinicians rate the generated Mandarin, Bengali, and Hindi dialogues as having the same depression severity distribution as the English originals, with no detectable inconsistencies.
Figures
read the original abstract
AI and large language models (LLMs) have emerged as promising tools to address global mental health challenges. Despite the global nature of these challenges, there remains a critical shortage of high-quality datasets for training and evaluating such systems. To mitigate this gap, researchers increasingly generate synthetic clinical personas to simulate user data and test digital mental health support systems. However, most validated personas rely on English-centric contexts. This paper investigates whether similar persona-based methods can be used to generate multilingual mental health datasets. We modified nationality and language parameters in personas to generate clinical dialogues in Mandarin, Bengali, and Hindi. We then examined how different LLMs perform when evaluating the depression severity of these generated multilingual datasets against the baseline in English. Our findings indicate that just adding nationality and language parameters in personas might not be adequate, as it can introduce clinical inconsistency across languages. LLM judge models often exhibit inaccuracies in assessing depression severity in non-English texts, with performance varying across different models. This exposes the systemic limitations of applying English-centric personas to multilingual contexts. Ultimately, our work highlights the urgent need for culturally responsive data generation to ensure equitable mental health systems globally.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates whether modifying English-centric clinical personas with nationality and language parameters can produce consistent multilingual mental health dialogue datasets. Dialogues are generated in Mandarin, Bengali, and Hindi; LLM judges then score depression severity in these outputs against English baselines. The central finding is that persona localization introduces clinical inconsistency across languages and that LLM judges exhibit inaccuracies and model-dependent variation when evaluating non-English text.
Significance. If the methodological concerns are addressed, the work would usefully document practical limits of simple persona localization for clinical data and reinforce the need for culturally grounded dataset creation in mental-health NLP. The empirical focus on three languages and multiple judge models provides a concrete starting point, though the absence of ground-truth validation currently limits the strength of the conclusions.
major comments (2)
- [Experimental design / evaluation protocol] The central claim—that nationality/language modifications introduce clinical inconsistency—rests on discrepancies in LLM-judge severity scores between English and target-language dialogues. Because the paper simultaneously reports that the same judges are inaccurate on non-English text, any observed discrepancy could arise from judge failure modes rather than from the persona changes themselves. This circularity is load-bearing for the main conclusion.
- No information is supplied on the number of generated dialogues, the precise depression-severity metric or scale employed by the judges, statistical tests for cross-language differences, or any human-expert validation of the LLM judgments. These omissions prevent assessment of whether the reported inconsistencies are reliable or merely artifacts of small or uncontrolled samples.
minor comments (1)
- [Abstract] The abstract conflates two distinct observations (inconsistency in generated data vs. judge inaccuracy); separating them would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, clarifying our experimental approach and committing to revisions where the manuscript can be strengthened without altering its core findings.
read point-by-point responses
-
Referee: The central claim—that nationality/language modifications introduce clinical inconsistency—rests on discrepancies in LLM-judge severity scores between English and target-language dialogues. Because the paper simultaneously reports that the same judges are inaccurate on non-English text, any observed discrepancy could arise from judge failure modes rather than from the persona changes themselves. This circularity is load-bearing for the main conclusion.
Authors: We agree that the evaluation protocol creates interdependence between the measured inconsistencies and judge reliability. Our intent was to demonstrate that persona localization produces outputs whose clinical properties (as scored by LLMs) diverge across languages, while separately documenting judge inaccuracy via model-to-model variation. The central finding is therefore the joint limitation rather than an isolated claim about persona effects. We will revise the manuscript to explicitly discuss this interdependence, reframe the conclusion around the need for improved multilingual evaluation methods, and avoid language that attributes discrepancies solely to persona changes. revision: partial
-
Referee: No information is supplied on the number of generated dialogues, the precise depression-severity metric or scale employed by the judges, statistical tests for cross-language differences, or any human-expert validation of the LLM judgments. These omissions prevent assessment of whether the reported inconsistencies are reliable or merely artifacts of small or uncontrolled samples.
Authors: We will add the requested details on the number of generated dialogues, the exact depression-severity metric and scale used by each judge model, and the statistical tests performed for cross-language comparisons. These elements exist in our experimental logs and can be reported in the revision. We did not conduct human-expert validation of the LLM judgments; the study was designed to examine LLM-as-judge behavior rather than to benchmark against clinicians. revision: partial
- Human-expert validation of the LLM judgments (not performed in the original study)
Circularity Check
No circularity; direct empirical reporting of generation and LLM evaluation results
full rationale
The paper is an observational empirical study: personas are modified with nationality/language, dialogues are generated, and LLM judges score depression severity. No equations, fitted parameters, predictions derived from inputs, or self-citation chains are present. Claims rest on experimental observations rather than any derivation that reduces to prior inputs by construction. The noted limitation (LLM judge accuracy in non-English) is a methodological concern but does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Synthetic clinical personas can be localized via nationality and language parameters to produce dialogues in target languages
- domain assumption LLM judge models provide a usable proxy for assessing depression severity in generated dialogues
Reference graph
Works this paper leans on
-
[1]
and Mensa-Kwao, Augustina and Gonese, Gloria and Kamamia, Christine K
Moitra, Modhurima and Owens, Shanise and Hailemariam, Maji and Wilson, Katherine S. and Mensa-Kwao, Augustina and Gonese, Gloria and Kamamia, Christine K. and White, Belinda and Young, Dorraine M. and Collins, Pamela Y. , urldate =. Global Mental Health: Where We Are and Where We Are Going , volume =. Current Psychiatry Reports , shortjournal =. 2023 , la...
-
[2]
Liu, Junjiao and Liu, Yueyang and Ma, Wenjun and Tong, Yan and Zheng, Jianzhong , urldate =. Temporal and spatial trend analysis of all-cause depression burden based on Global Burden of Disease (. Scientific Reports , shortjournal =. 2024 , langid =. doi:10.1038/s41598-024-62381-9 , abstract =
-
[3]
Hasan, M. Tasdik and Anwar, Tasnim and Christopher, Enryka and Hossain, Sahadat and Hossain, Md Mahbub and Koly, Kamrun Nahar and Saif-Ur-Rahman, K. M. and Ahmed, Helal Uddin and Arman, Nazish and Hossain, Saima Wazed , urldate =. The current state of mental healthcare in Bangladesh: part 1 – an updated country profile , volume =. 2021 , langid =. doi:10....
-
[4]
Wang, Xi and Perez, Anxo and Parapar, Javier and Crestani, Fabio , urldate =. Proceedings of the 34th. 2025 , file =. doi:10.1145/3746252.3761617 , series =
-
[5]
Gender differences in depression and anxiety: The role of age , volume =
Faravelli, Carlo and Alessandra Scarpato, Maria and Castellini, Giovanni and Lo Sauro, Carolina , urldate =. Gender differences in depression and anxiety: The role of age , volume =. Psychiatry Research , shortjournal =. 2013 , keywords =. doi:10.1016/j.psychres.2013.09.027 , shorttitle =
-
[6]
The Journal of Nervous and Mental Disease , author =
The Role of Age in the Relationship of Gender and Marital Status to Depression , volume =. The Journal of Nervous and Mental Disease , author =. 1982 , langid =
1982
-
[7]
Diagnostic and Statistical Manual of Mental Disorders:
-
[8]
Language Patterns Discriminate Mild Depression From Normal Sadness and Euthymic State , volume =
Smirnova, Daria and Cumming, Paul and Sloeva, Elena and Kuvshinova, Natalia and Romanov, Dmitry and Nosachev, Gennadii , urldate =. Language Patterns Discriminate Mild Depression From Normal Sadness and Euthymic State , volume =. 2018 , keywords =. doi:10.3389/fpsyt.2018.00105 , journal =
-
[9]
Al-Mosaiwi, Mohammed and Johnstone, Tom , urldate =. In an Absolute State: Elevated Use of Absolutist Words Is a Marker Specific to Anxiety, Depression, and Suicidal Ideation , volume =. Clinical Psychological Science , publisher =. 2018 , keywords =. doi:10.1177/2167702617747074 , shorttitle =
-
[10]
Sociological Methodology , author =
Linking Life Histories and Mental Health: A Person-Centered Strategy , volume =. Sociological Methodology , author =. 1998 , langid =. doi:10.1111/0081-1750.00041 , shorttitle =
-
[11]
and Gore, Susan and Colten, Mary Ellen , year =
Aseltine, Robert H. and Gore, Susan and Colten, Mary Ellen , year =. Depression and the social developmental context of adolescence , volume =. Journal of Personality and Social Psychology , publisher =. doi:10.1037/0022-3514.67.2.252 , pages =
-
[12]
Brown, George W. , urldate =. Social Roles, Context and Evolution in the Origins of Depression , volume =. Journal of Health and Social Behavior , publisher =. doi:10.2307/3090203 , pages =
-
[13]
, year =
Bickley, Lynn and Szilagyi, Peter G. , year =. Bates' Guide to Physical Examination and History-Taking , isbn =
-
[14]
A meta-analysis of the problematic social media use and mental health , volume =
Huang, Chiungjung , urldate =. A meta-analysis of the problematic social media use and mental health , volume =. International Journal of Social Psychiatry , shortjournal =. doi:10.1177/0020764020978434 , abstract =
-
[15]
Berryman, Chloe and Ferguson, Christopher J. and Negy, Charles , urldate =. Social Media Use and Mental Health among Young Adults , volume =. Psychiatric Quarterly , shortjournal =. 2018 , langid =. doi:10.1007/s11126-017-9535-6 , abstract =
-
[16]
One Persona, Many Cues, Different Results: How Sociodemographic Cues Impact LLM Personalization
Weeber, Franziska and Neplenbroek, Vera and Batzner, Jan and Padó, Sebastian , urldate =. One Persona, Many Cues, Different Results: How Sociodemographic Cues Impact. 2026 , eprinttype =. doi:10.48550/arXiv.2601.18572 , shorttitle =. 2601.18572 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.18572 2026
-
[17]
and Craighead, W
Weiner, Irving B. and Craighead, W. Edward , year =. The Corsini Encyclopedia of Psychology, Volume 1 , isbn =
-
[18]
and Zhang, Xiao Chi and Cameron, Kenzie A
Papanagnou, Dimitrios and Klein, Matthew R. and Zhang, Xiao Chi and Cameron, Kenzie A. and Doty, Amanda and. Developing standardized patient-based cases for communication training: lessons learned from training residents to communicate diagnostic uncertainty , volume =. Advances in Simulation , shortjournal =. 2021 , file =. doi:10.1186/s41077-021-00176-y...
-
[19]
2024 , eprinttype =. doi:10.48550/arXiv.2303.08774 , abstract =. 2303.08774 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2024
-
[20]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and others , urldate =. The Llama 3 Herd of Models , url =. 2024 , eprinttype =. doi:10.48550/arXiv.2407.21783 , abstract =. 2407.21783 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[21]
Yang, An and Li, Anfeng and Yang, Baosong and others , urldate =. Qwen3 Technical Report , url =. 2025 , eprinttype =. doi:10.48550/arXiv.2505.09388 , abstract =. 2505.09388 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI and Guo, Daya and Yang, Dejian and others , urldate =. Nature , shortjournal =. 2025 , eprinttype =. doi:10.1038/s41586-025-09422-z , shorttitle =. 2501.12948 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z 2025
-
[23]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI and Liu, Aixin and Mei, Aoxue and Lin, Bangcai and Xue, Bing and others , urldate =. 2025 , eprinttype =. doi:10.48550/arXiv.2512.02556 , shorttitle =. 2512.02556 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.02556 2025
-
[24]
Chen, Zhuang and Deng, Jiawen and Zhou, Jinfeng and Wu, Jincenzi and Qian, Tieyun and Huang, Minlie , editor =. Depression. Proceedings of the 2024. doi:10.18653/v1/2024.naacl-long.452 , urldate =
-
[25]
doi:10.48550/arXiv.2501.17510 , urldate =
Ignashina, Mariia and Bondaronek, Paulina and Santel, Dan and Pestian, John and Ive, Julia , year = 2025, number =. doi:10.48550/arXiv.2501.17510 , urldate =. 2501.17510 , primaryclass =
-
[26]
Li, Yi and Ding, Xuanxuan and Chen, Yifan and Li, Yeye and Ma, Nan , year = 2025, series =. Customizable. Proceedings of the 2025. doi:10.1145/3715336.3735795 , urldate =
-
[27]
Zhang, Qiyang and Zhang, Renwen and Xiong, Yiying and Sui, Yuan and Tong, Chang and Lin, Fu-Hung , year = 2025, journal =. Generative. doi:10.2196/78238 , urldate =
-
[28]
Jin, Yiqiao and Chandra, Mohit and Verma, Gaurav and Hu, Yibo and Choudhury, Munmun De and Kumar, Srijan , year = 2023, number =. Better to. doi:10.48550/arXiv.2310.13132 , urldate =. 2310.13132 , primaryclass =
-
[29]
Raihan, Nishat and Puspo, Sadiya Sayara Chowdhury and Bucur, Ana-Maria and Chancellor, Stevie and Zampieri, Marcos , year = 2026, number =. Large. doi:10.48550/arXiv.2602.02440 , urldate =. 2602.02440 , primaryclass =
-
[30]
Kang, Andrea and Chen, Jun Yu and. Synthetic. doi:10.48550/arXiv.2411.17672 , urldate =. 2411.17672 , primaryclass =
-
[31]
Computers in Biology and Medicine , volume =
Detecting the Clinical Features of Difficult-to-Treat Depression Using Synthetic Data from Large Language Models , author =. Computers in Biology and Medicine , volume =. doi:10.1016/j.compbiomed.2025.110246 , urldate =
-
[32]
Ge, Tao and Chan, Xin and Wang, Xiaoyang and Yu, Dian and Mi, Haitao and Yu, Dong , year = 2025, number =. Scaling. doi:10.48550/arXiv.2406.20094 , urldate =. 2406.20094 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.20094 2025
-
[33]
Proceedings of the 2024
Na, Hongbin , editor =. Proceedings of the 2024
2024
-
[34]
and Chui, Celine Sze Ling and Ip, Patrick , year = 2025, journal =
Chen, Chen and Lam, Kok Tai and Yip, Ka Man and So, Hung Kwan and Lum, Terry Yat Sang and Wong, Ian Chi Kei and Yam, Jason C. and Chui, Celine Sze Ling and Ip, Patrick , year = 2025, journal =. Comparison of an. doi:10.2196/65785 , urldate =
-
[35]
Chakraborty, Tanmoy and Sinha Deb, Koushik and Kulkarni, Himanshu and Masud, Sarah and Math, Suresh Bada and Oke, Gayatri and Sagar, Rajesh and Sharma, Mona , year = 2025, journal =. The Promise of Generative. doi:10.1038/s42256-025-00992-1 , urldate =
-
[36]
Ahmed, Istiaq and Mohtasim, Syed Niaz and Arpita, Faiza Omar and Islam, Ashraful and Amin, M. Ashraful , editor =. A. doi:10.1007/978-3-031-78561-0_1 , isbn =
-
[37]
R. A. Proceedings of the 28th. doi:10.1145/3340631.3394879 , urldate =
-
[38]
Gui, Tao and Zhu, Liang and Zhang, Qi and Peng, Minlong and Zhou, Xu and Ding, Keyu and Chen, Zhigang , year = 2019, journal =. Cooperative. doi:10.1609/aaai.v33i01.3301110 , urldate =
-
[39]
and Kim, Jinman and Khushi, Matloob , year = 2022, series =
Naseem, Usman and Dunn, Adam G. and Kim, Jinman and Khushi, Matloob , year = 2022, series =. Early. Proceedings of the. doi:10.1145/3485447.3512128 , urldate =
-
[40]
Parapar, Javier and Perez, Anxo and Wang, Xi and Crestani, Fabio , editor =. Overview of. Experimental. doi:10.1007/978-3-032-04354-2_15 , isbn =
-
[41]
Language Resources and Evaluation , volume =
dos Santos, Wesley Ramos and. Language Resources and Evaluation , volume =. doi:10.1007/s10579-022-09633-0 , urldate =
-
[42]
doi:10.48550/arXiv.2508.12733 , abstract =
Ning, Zhiyuan and Gu, Tianle and Song, Jiaxin and Hong, Shixin and Li, Lingyu and Liu, Huacan and Li, Jie and Wang, Yixu and Lingyu, Meng and Teng, Yan and Wang, Yingchun , year = 2025, number =. doi:10.48550/arXiv.2508.12733 , urldate =. 2508.12733 , primaryclass =
-
[43]
doi:10.48550/arXiv.2506.19468 , urldate =
Han, Wenhan and Zhang, Yifan and Chen, Zhixun and Liu, Binbin and Lin, Haobin and Zhang, Bingni and Wang, Taifeng and Pechenizkiy, Mykola and Fang, Meng and Zheng, Yin , year = 2025, number =. doi:10.48550/arXiv.2506.19468 , urldate =. 2506.19468 , primaryclass =
-
[44]
doi:10.48550/arXiv.2503.10497 , urldate =
Xuan, Weihao and Yang, Rui and Qi, Heli and Zeng, Qingcheng and Xiao, Yunze and Feng, Aosong and Liu, Dairui and Xing, Yun and Wang, Junjue and Gao, Fan and Lu, Jinghui and Jiang, Yuang and Li, Huitao and Li, Xin and Yu, Kunyu and Dong, Ruihai and Gu, Shangding and Li, Yuekang and Xie, Xiaofei and. doi:10.48550/arXiv.2503.10497 , urldate =. 2503.10497 , p...
-
[45]
and Murphy, David and Tabirca, Sabin , year = 2025, journal =
Ronan, Isabel and Crowley, Patrice and Rombouts, Eva and Cornally, Nicola and Saab, Mohamad M. and Murphy, David and Tabirca, Sabin , year = 2025, journal =. A. doi:10.1016/j.jbi.2025.104936 , urldate =
-
[46]
Wang, Ke and Zhu, Jiahui and Ren, Minjie and Liu, Zeming and Li, Shiwei and Zhang, Zongye and Zhang, Chenkai and Wu, Xiaoyu and Zhan, Qiqi and Liu, Qingjie and Wang, Yunhong , year = 2024, number =. A. doi:10.48550/arXiv.2410.12896 , urldate =. 2410.12896 , primaryclass =
-
[47]
Zhezherau, Alexey and Yanockin, Alexei , year = 2024, number =. Hybrid. doi:10.48550/arXiv.2410.09168 , urldate =. 2410.09168 , primaryclass =
-
[48]
Frontiers in Psychiatry , volume =
Leveraging Reddit Data for Context-Enhanced Synthetic Health Data Generation to Identify Low Self Esteem , author =. Frontiers in Psychiatry , volume =. doi:10.3389/fpsyt.2025.1726100 , urldate =
-
[49]
doi:10.48550/arXiv.2602.11684 , urldate =
Sabour, Sahand and NG, TszYam and Huang, Minlie , year = 2026, number =. doi:10.48550/arXiv.2602.11684 , urldate =. 2602.11684 , primaryclass =
-
[50]
Bhowmik, Shimanto and Dipto, Tawsif Tashwar and Islam, Md Sazzad and Hsu, Sheryl and Reasat, Tahsin , year = 2025, number =. Evaluating. doi:10.48550/arXiv.2507.23248 , urldate =. 2507.23248 , primaryclass =
-
[51]
Personas -
Nielsen, Lene , year = 2019, publisher =. Personas -
2019
-
[52]
Personas: Practice and Theory , booktitle =
Pruitt, John and Grudin, Jonathan , year = 2003, series =. Personas: Practice and Theory , booktitle =. doi:10.1145/997078.997089 , urldate =
-
[53]
Salminen, Joni and Amin, Danial and Jung, Soon-Gyo and Jansen, Bernard , year = 2025, series =. The. Proceedings of the. doi:10.1145/3745900.3746108 , urldate =
-
[54]
Available: https://doi.org/10.1016/j.ijhcs.2025.103445
PersonaCraft: Leveraging Language Models for Data-Driven Persona developmentPersonaCraft , author =. International Journal of Human-Computer Studies , volume =. doi:10.1016/j.ijhcs.2025.103445 , urldate =
-
[55]
Wu, Shenghan and Zhu, Yimo and Hsu, Wynne and Lee, Mong-Li and Deng, Yang , editor =. From. Proceedings of the 2025. doi:10.18653/v1/2025.emnlp-main.277 , urldate =
-
[56]
Faithful
Jandaghi, Pegah and Sheng, Xianghai and Bai, Xinyi and Pujara, Jay and Sidahmed, Hakim , editor =. Faithful. Proceedings of the 6th
-
[57]
Kaur, Arshnoor and Aird, Amanda and Borman, Harris and Nicastro, Andrea and Leontjeva, Anna and Pizzato, Luiz and Jermyn, Dan , year = 2025, pages =. Synthetic. Proceedings of the 33rd. doi:10.1145/3699682.3728339 , urldate =
-
[58]
doi:10.48550/arXiv.2503.16527 , urldate =
Li, Ang and Chen, Haozhe and Namkoong, Hongseok and Peng, Tianyi , year = 2025, number =. doi:10.48550/arXiv.2503.16527 , urldate =. 2503.16527 , primaryclass =
-
[59]
Batzner, Jan and Stocker, Volker and Tang, Bingjun and Natarajan, Anusha and Chen, Qinhao and Schmid, Stefan and Kasneci, Gjergji , year = 2025, journal =. Whose. doi:10.1609/aies.v8i1.36553 , urldate =
-
[60]
Zhang, Saizheng and Dinan, Emily and Urbanek, Jack and Szlam, Arthur and Kiela, Douwe and Weston, Jason , editor =. Personalizing. Proceedings of the 56th. doi:10.18653/v1/P18-1205 , urldate =
-
[61]
Xiao, Yunze and He, Tingyu and Wang, Lionel Z. and Ma, Yiming and Song, Xingyu and Xu, Xiaohang and Diab, Mona and Li, Irene and Ng, Ka Chung , year = 2026, number =. doi:10.48550/arXiv.2503.21679 , urldate =. 2503.21679 , primaryclass =
-
[62]
Agarwal, Kaustubh and Dhingra, Bhavya , editor =. Deep. Proceedings of the 18th
-
[63]
PAWS - X : A Cross-lingual Adversarial Dataset for Paraphrase Identification
Yang, Yinfei and Zhang, Yuan and Tar, Chris and Baldridge, Jason , editor =. Proceedings of the 2019. doi:10.18653/v1/D19-1382 , urldate =
-
[64]
and Antypas, Dimosthenis and Borkakoty, Hsuvas and Kim, Eunsu and
Myung, Junho and Lee, Nayeon and Zhou, Yi and Jin, Jiho and Putri, Rifki A. and Antypas, Dimosthenis and Borkakoty, Hsuvas and Kim, Eunsu and. Advances in Neural Information Processing Systems , volume =
-
[65]
Restrepo, David and Wu, Chenwei and Tang, Zhengxu and Shuai, Zitao and Phan, Thao Nguyen Minh and Ding, Jun-En and Dao, Cong-Tinh and Gallifant, Jack and Dychiao, Robyn Gayle and Artiaga, Jose Carlo and Bando, Andr. Multi-. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. doi:10.1609/aaai.v39i27.35053 , urldate =
-
[66]
Generating personas using LLMs and assessing their viability,
Schuller, Andreas and Janssen, Doris and Blumenr. Generating Personas Using. Extended. doi:10.1145/3613905.3650860 , urldate =
-
[67]
Kamruzzaman, Mahammed and Al Monsur, Abdullah and Kim, Gene Louis and Chhabra, Anshuman , editor =. From. Proceedings of the 14th
-
[68]
Kamruzzaman, Mahammed and Kim, Gene Louis , editor =. Exploring. Proceedings of the 2025. doi:10.18653/v1/2025.emnlp-main.181 , urldate =
-
[69]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , editor =. G-. Proceedings of the 2023. doi:10.18653/v1/2023.emnlp-main.153 , urldate =
-
[70]
Fu, Xiyan and Liu, Wei , editor =. How. Findings of the. doi:10.18653/v1/2025.findings-emnlp.587 , urldate =
-
[71]
Chen, Guiming Hardy and Chen, Shunian and Liu, Ziche and Jiang, Feng and Wang, Benyou , editor =. Humans or. Proceedings of the 2024. doi:10.18653/v1/2024.emnlp-main.474 , urldate =
-
[72]
Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge
Ye, Jiayi and Wang, Yanbo and Huang, Yue and Chen, Dongping and Zhang, Qihui and Moniz, Nuno and Gao, Tian and Geyer, Werner and Huang, Chao and Chen, Pin-Yu and Chawla, Nitesh V. and Zhang, Xiangliang , year = 2024, number =. Justice or. doi:10.48550/arXiv.2410.02736 , urldate =. 2410.02736 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.02736 2024
-
[73]
Teja, J. S. and Narang, R. L. and Aggarwal, A. K. , year = 1971, journal =. Depression. doi:10.1192/bjp.119.550.253 , urldate =
-
[74]
Sakai, Shintaro and An, Jisun and Kang, Migyeong and Kwak, Haewoon , year = 2025, number =. Somatic in the. doi:10.48550/arXiv.2508.03247 , urldate =. 2508.03247 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.03247 2025
-
[75]
Peng, Shixin and Jiang, Kun and Yang, Yu and Chen, Jingying and Xu, Guandong , editor =. Framework for. Behavioural and. doi:10.1007/978-981-95-7138-3_26 , isbn =
-
[76]
2023 , url =
Ethnologue: Languages of the World , author =. 2023 , url =
2023
-
[77]
Goodmann and Sariah Daouk and Megan Sullivan and Juan Cabrera and Nancy H
Danielle R. Goodmann and Sariah Daouk and Megan Sullivan and Juan Cabrera and Nancy H. Liu and Suzanne Barakat and Ricardo F. Muñoz and Yan Leykin , keywords =. Factor analysis of depression symptoms across five broad cultural groups , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.jad.2020.12.159 , url =
-
[78]
Jovanovi. Depression and anxiety symptoms in adolescents across 30 countries: Cross-national measurement invariance and relationships with subjective well-being , journal =. 2026 , issn =. doi:10.1016/j.jad.2026.121693 , url =
-
[79]
Communications Medicine , year=
Demographic variation in symptoms of depression and anxiety across 22 Global Flourishing Study countries , author=. Communications Medicine , year=
-
[80]
Elwahsh, Sarah and Stern, Nora and Singh, Aneesha and Ayobi, Amid , year = 2025, series =. Linguistic. Proceedings of the 7th. doi:10.1145/3719160.3736615 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.