Efficiently Representing Algorithms With Chain-of-Thought Transformers
Pith reviewed 2026-06-26 18:39 UTC · model grok-4.3
The pith
Chain-of-thought transformers simulate Word RAM algorithms with only poly-logarithmic overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CoT can efficiently simulate any Word RAM algorithm with only a poly-logarithmic overhead in n. This overhead reduces to log-square when the Word RAM has a “flat” instruction set, and only logarithmic for multiplication-free flat instructions. The simulation holds for finite-precision transformers with poly-logarithmic width and rightmost unique hard attention, as well as for continuous CoT and hybrid RNN-transformer architectures with finite width and log-precision.
What carries the argument
The chain-of-thought (CoT) output sequence in transformers, which is used to simulate the memory accesses and operations of the Word RAM model through a series of reasoning steps.
If this is right
- Sorting n items requires only O(n log n polylog n) CoT steps instead of quadratic in n.
- Dijkstra's algorithm on graphs with V vertices and E edges runs in O((E + V log V) polylog V) steps.
- Algorithms with flat instruction sets achieve log-squared overhead, and multiplication-free ones achieve logarithmic overhead.
- CoT transformers can represent a wider range of practical algorithms efficiently compared to Turing machine simulations.
Where Pith is reading between the lines
- Designers of reasoning models may prioritize architectures supporting hard attention or hybrid RNN layers to achieve better algorithmic efficiency.
- This could lead to new ways of training models to perform algorithmic tasks by directly targeting Word RAM simulations.
- Future work might explore whether real-world language models exhibit similar efficiency when prompted with chain-of-thought for algorithmic problems.
Load-bearing premise
The transformer must use rightmost unique hard attention or the specified continuous or hybrid architectures to achieve the poly-log overhead.
What would settle it
A demonstration that some Word RAM algorithm, such as sorting, requires super-polylogarithmic steps in any chain-of-thought transformer of the described types.
Figures

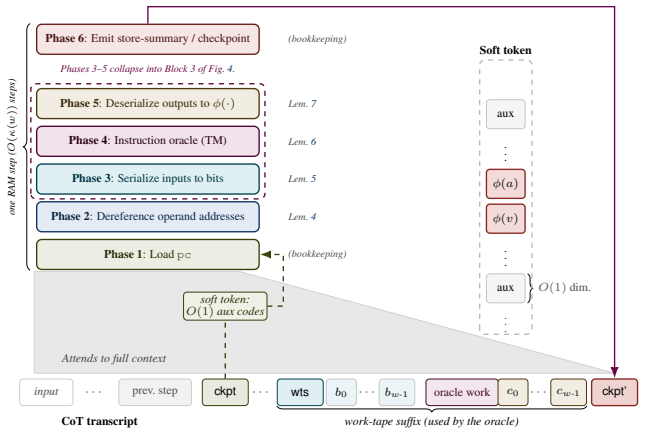
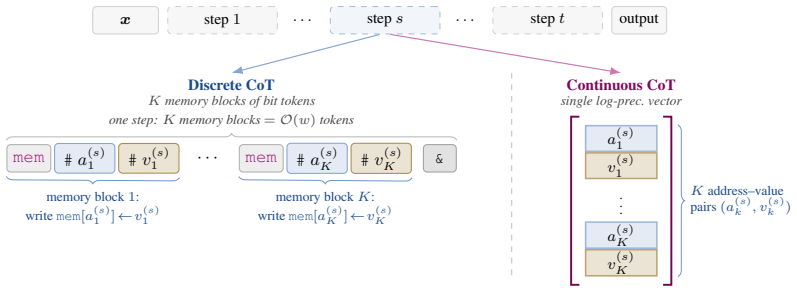
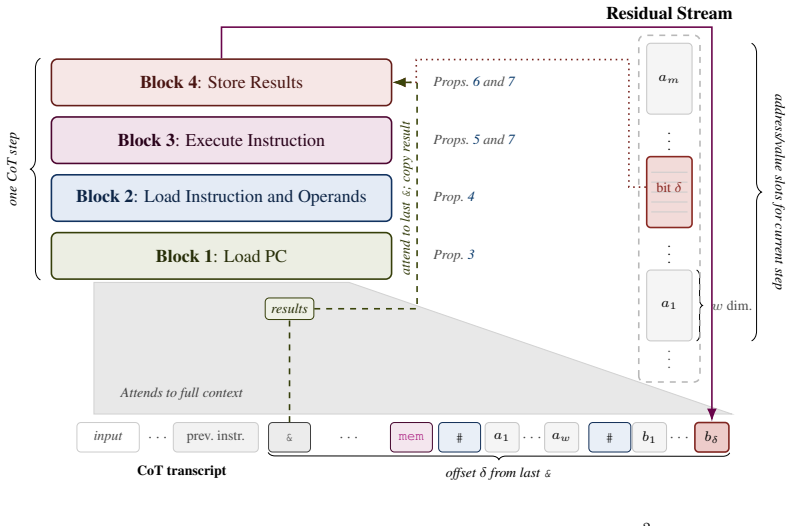
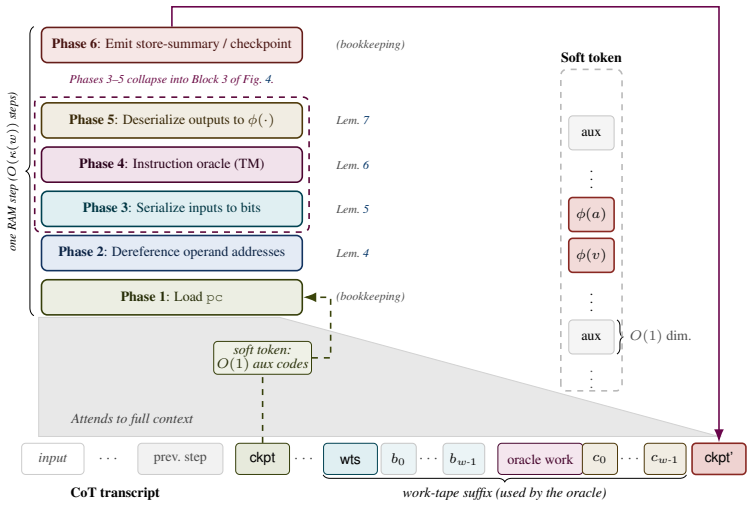
read the original abstract
The increasing popularity of \emph{reasoning} models -- language models that output a series of reasoning or thought tokens before producing an answer -- is justified, in part, by theoretical results showing that chain-of-thought (CoT) transformers can simulate Turing machines, and thus perform arbitrary computation. However, the Turing machine, while suitable for complexity-theoretic analysis, is not convenient, intuitive, or efficient for discussing algorithms. Algorithms are typically designed and analyzed at a higher level of abstraction, captured by the \emph{Word RAM} model with random-access memory and unit-cost operations on $\bigO(\log n)$-bit words. As a result, Word RAM algorithms can be substantially more efficient than their Turing machine counterparts, raising the question: \emph{Can CoT transformers efficiently simulate Word RAM algorithms?} For instance, can they sort $n$ items in $\bigO(n \log n)$ steps or run Dijkstra's algorithm in $\bigO(E + V \log V)$ steps? We answer affirmatively, up to poly-logarithmic overhead. We first establish this for finite-precision transformers with poly-logarithmic width and rightmost unique hard attention, then strengthen the result to two more practical settings with finite width and log-precision: \emph{continuous} CoT, where reasoning takes the form of vectors rather than tokens, and a \emph{hybrid} architecture in which transformer layers sit atop a recurrent (linear RNN) layer. In all three cases, we find that CoT \emph{can} efficiently simulate any Word RAM algorithm with only a poly-logarithmic overhead in $n$. This overhead reduces to log-square when the Word RAM has a ``flat'' instruction set, and only logarithmic for multiplication-free flat instructions -- in stark contrast to known CoT simulations of Turing machines, which require quadratic overhead over Word RAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that chain-of-thought (CoT) transformers can simulate arbitrary Word RAM algorithms with only polylogarithmic overhead in n (poly-log in general; log² for flat instruction sets; log for multiplication-free flat instructions). Explicit constructions are given for three settings: finite-precision transformers with poly-log width and rightmost unique hard attention; continuous CoT (vector reasoning) with finite width and log precision; and a hybrid architecture with transformer layers over a linear RNN. This improves on prior quadratic-overhead CoT simulations of Turing machines.
Significance. If the constructions and bounds hold, the result is significant: it supplies a realistic complexity-theoretic justification for CoT reasoning models by showing they can implement standard algorithms (sorting, Dijkstra, etc.) with near-optimal step counts under the Word RAM model. The explicit overhead reductions and the three architecture variants constitute a clear advance over TM-based analyses.
major comments (2)
- [Abstract / finite-precision case] Abstract and the finite-precision construction: the central claim rests on the existence of explicit attention constructions and precision handling that achieve the stated polylog bounds; these derivations are not visible, leaving the soundness of the overhead claims unverifiable from the provided text. This is load-bearing for the main result.
- [overhead-reduction claims] The reduction from general Word RAM to flat and multiplication-free instruction sets is stated to improve the overhead, but without the corresponding simulation details or the precise definition of the instruction-set restrictions, it is impossible to confirm that no hidden logarithmic factors are introduced.
minor comments (1)
- Define 'rightmost unique hard attention' and 'flat instruction set' with a short formal paragraph or reference to prior work on the first occurrence.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the significance of our results and for the constructive feedback. We address each major comment below with clarifications drawn from the manuscript and indicate where revisions will improve accessibility.
read point-by-point responses
-
Referee: [Abstract / finite-precision case] Abstract and the finite-precision construction: the central claim rests on the existence of explicit attention constructions and precision handling that achieve the stated polylog bounds; these derivations are not visible, leaving the soundness of the overhead claims unverifiable from the provided text. This is load-bearing for the main result.
Authors: The finite-precision construction with poly-log width and rightmost unique hard attention is given explicitly in Sections 3–4, including the precise attention masks, head configurations, and bit-precision bounds that yield the claimed polylogarithmic overhead. The derivations appear in the proofs of Theorems 3.1 and 4.2. To address verifiability concerns, we will add a concise high-level outline of the attention construction to the abstract and a one-paragraph roadmap at the start of Section 3. revision: partial
-
Referee: [overhead-reduction claims] The reduction from general Word RAM to flat and multiplication-free instruction sets is stated to improve the overhead, but without the corresponding simulation details or the precise definition of the instruction-set restrictions, it is impossible to confirm that no hidden logarithmic factors are introduced.
Authors: Section 5 formally defines the flat and multiplication-free instruction sets (Definitions 5.1–5.2) and provides the simulation reductions (Theorems 5.3 and 5.5). The proofs show that each reduction incurs at most an additional O(log n) factor, preserving the overall polylogarithmic bound with no hidden terms. We will expand Section 5 with a short pseudocode table summarizing the instruction-set mappings to make the absence of extra logarithmic factors immediately apparent. revision: partial
Circularity Check
No significant circularity; construction against external model
full rationale
The paper presents explicit theoretical constructions for CoT transformers (finite-precision with poly-log width and rightmost unique hard attention; continuous CoT; hybrid RNN-transformer) that simulate arbitrary Word RAM algorithms. The claimed polylog(n) overhead bounds (reducing to log² or log under flat/multiplication-free instruction sets) are derived from these constructions against the external Word RAM model, with no equations, parameters, or claims reducing by definition or self-citation to the target simulation bounds themselves. Architectural assumptions are stated upfront without circular reduction, and no load-bearing self-citations, fitted inputs renamed as predictions, or ansatz smuggling appear in the abstract or described claims. The derivation is self-contained as a new simulation result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Word RAM model permits unit-cost operations on O(log n)-bit words with random access memory.
- domain assumption Rightmost unique hard attention and the continuous/hybrid variants admit the required memory and control operations.
Reference graph
Works this paper leans on
-
[1]
The Transformer Cookbook , url =
Andy Yang and Christopher Watson and Anton Xue and Satwik Bhattamishra and Jose Llarena and William Merrill and Emile Dos Santos Ferreira and Anej Svete and David Chiang , issn =. The Transformer Cookbook , url =. TMLR , note =
-
[2]
Masked Hard-Attention Transformers Recognize Exactly the Star-Free Languages , url =
Andy Yang and David Chiang and Dana Angluin , booktitle =. Masked Hard-Attention Transformers Recognize Exactly the Star-Free Languages , url =
-
[3]
On the Reasoning Abilities of Masked Diffusion Language Models , url =
Anej Svete and Ashish Sabharwal , booktitle =. On the Reasoning Abilities of Masked Diffusion Language Models , url =
-
[4]
ICML , year=
Revisiting Padded Transformer Expressivity: Which Architectural Choices Matter and Which Don't , author=. ICML , year=
-
[5]
Anej Svete and William Merrill and Ashish Sabharwal , title =
-
[6]
Gomez and Lukasz Kaiser and Illia Polosukhin , bibsource =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , bibsource =. Attention is All you Need , url =. NeurIPS , pages =
-
[7]
Dagstuhl Reports , number =
Barcelo, Pablo and Chiang, David and Cybenko, George and Strobl, Lena and Yang, Andy , doi =. Dagstuhl Reports , number =
-
[8]
Wind and Tianyi Wu and Daniel Wuttke and Christian Zhou-Zheng , booktitle =
Bo Peng and Ruichong Zhang and Daniel Goldstein and Eric Alcaide and Xingjian Du and Haowen Hou and Jiaju Lin and Jiaxing Liu and Janna Lu and William Merrill and Guangyu Song and Kaifeng Tan and Saiteja Utpala and Nathan Wilce and Johan S. Wind and Tianyi Wu and Daniel Wuttke and Christian Zhou-Zheng , booktitle =
-
[9]
Ian , booktitle =
Brodnik, Andrej and Miltersen, Peter Bro and Munro, J. Ian , booktitle =. Trans-dichotomous algorithms without multiplication --- some upper and lower bounds , year =
-
[10]
arXiv , author =:2209.11895 , journal =
In-context Learning and Induction Heads , url =. arXiv , author =:2209.11895 , journal =
-
[11]
Pause Tokens Strictly Increase the Expressivity of Constant-Depth Transformers , url =
Charles London and Varun Kanade , booktitle =. Pause Tokens Strictly Increase the Expressivity of Constant-Depth Transformers , url =
-
[12]
arXiv , author =:2408.03314 , journal =
Scaling. arXiv , author =:2408.03314 , journal =
-
[14]
DeepSeek-AI and : Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Boc...
-
[15]
Forty-first International Conference on Machine Learning , title =
Ekin Aky. Forty-first International Conference on Machine Learning , title =
-
[16]
Hennie , doi =
F.C. Hennie , doi =. One-tape, off-line Turing machine computations , url =. Information and Control , number =
-
[17]
Sorting and Searching on the Word RAM , year =
Hagerup, Torben , booktitle =. Sorting and Searching on the Word RAM , year =
-
[18]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , bibsource =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =. NeurIPS , timestamp =
-
[19]
Jeonghoon Kim and Byeongchan Lee and Cheonbok Park and Yeontaek Oh and Beomjun Kim and Taehwan Yoo and Seongjin Shin and Dongyoon Han and Jinwoo Shin and Kang Min Yoo , booktitle =. Peri-
-
[20]
Unique Hard Attention: A Tale of Two Sides , url =
Jerad, Selim and Svete, Anej and Li, Jiaoda and Cotterell, Ryan , booktitle =. Unique Hard Attention: A Tale of Two Sides , url =. doi:10.18653/v1/2025.acl-short.76 , month = jul, pages =
-
[21]
Characterizing the Expressivity of Fixed-Precision Transformer Language Models , url =
Jiaoda Li and Ryan Cotterell , booktitle =. Characterizing the Expressivity of Fixed-Precision Transformer Language Models , url =
-
[22]
Attention is Turing-Complete , url =
Jorge Pérez and Pablo Barceló and Javier Marinkovic , journal =. Attention is Turing-Complete , url =
-
[23]
, isbn =
Knuth, Donald E. , isbn =. The art of computer programming, volume 2 (3rd ed.): seminumerical algorithms , url =
-
[24]
The Parallelism Tradeoff: Limitations of Log-Precision Transformers , volume =
Merrill, William and Sabharwal, Ashish , journal =. The Parallelism Tradeoff: Limitations of Log-Precision Transformers , volume =
-
[25]
Open Data Structures: An Introduction , volume =
Morin, Pat , publisher =. Open Data Structures: An Introduction , volume =
-
[26]
On the Representational Capacity of Neural Language Models with Chain-of-Thought Reasoning , url =
Nowak, Franz and Svete, Anej and Butoi, Alexandra and Cotterell, Ryan , booktitle =. On the Representational Capacity of Neural Language Models with Chain-of-Thought Reasoning , url =. doi:10.18653/v1/2024.acl-long.676 , month = aug, pages =
-
[27]
arXiv , author =:2412.16720 , journal =
-
[28]
Linear Transformers Are Secretly Fast Weight Programmers , url =
Schlag, Imanol and Irie, Kazuki and Schmidhuber, J. Linear Transformers Are Secretly Fast Weight Programmers , url =. Proceedings of the 38th International Conference on Machine Learning , editor =
-
[29]
Finite automata, formal logic, and circuit complexity , year =
Straubing, Howard , isbn =. Finite automata, formal logic, and circuit complexity , year =
-
[30]
What Formal Languages Can Transformers Express? A Survey , url =
Strobl, Lena and Merrill, William and Weiss, Gail and Chiang, David and Angluin, Dana , doi =. What Formal Languages Can Transformers Express? A Survey , url =. TACL , pages =
-
[31]
Transformers Can Represent n -gram Language Models , url =
Svete, Anej and Cotterell, Ryan , booktitle =. Transformers Can Represent n -gram Language Models , url =. doi:10.18653/v1/2024.naacl-long.381 , month = jun, pages =
-
[32]
arXiv , author =:2512.13961 , primaryclass =
Olmo 3 , url =. arXiv , author =:2512.13961 , primaryclass =
-
[33]
Thorup, Mikkel , booktitle =. On
-
[34]
William Hesse and Eric Allender and David A. Uniform constant-depth threshold circuits for division and iterated multiplication , url =. Journal of Computer and System Sciences , note =. doi:https://doi.org/10.1016/S0022-0000(02)00025-9 , issn =
-
[35]
The Expressive Power of Transformers with Chain of Thought , url =
William Merrill and Ashish Sabharwal , bibsource =. The Expressive Power of Transformers with Chain of Thought , url =. ICLR , publisher =
-
[36]
A Little Depth Goes a Long Way: the Expressive Power of Log-Depth Transformers , url =
William Merrill and Ashish Sabharwal , booktitle =. A Little Depth Goes a Long Way: the Expressive Power of Log-Depth Transformers , url =
-
[37]
A Logic for Expressing Log-Precision Transformers , year =
William Merrill and Ashish Sabharwal , booktitle =. A Logic for Expressing Log-Precision Transformers , year =
-
[38]
arXiv , author =:2603.03612 , journal =
Why Are Linear RNNs More Parallelizable? , url =. arXiv , author =:2603.03612 , journal =
-
[39]
Parallelizing Linear Transformers with the Delta Rule over Sequence Length , url =
Yang, Songlin and Wang, Bailin and Zhang, Yu and Shen, Yikang and Kim, Yoon , booktitle =. Parallelizing Linear Transformers with the Delta Rule over Sequence Length , url =. doi:10.52202/079017-3668 , pages =
-
[40]
Chain of Thought Empowers Transformers to Solve Inherently Serial Problems , url =
Zhiyuan Li and Hong Liu and Denny Zhou and Tengyu Ma , booktitle =. Chain of Thought Empowers Transformers to Solve Inherently Serial Problems , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.