VOiLA: Vectorized Online Planning with Learned Diffusion Model for POMDP Agents
Pith reviewed 2026-06-26 17:37 UTC · model grok-4.3
The pith
VOiLA learns diffusion-based POMDP models that match RL performance with under 10 percent of the training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
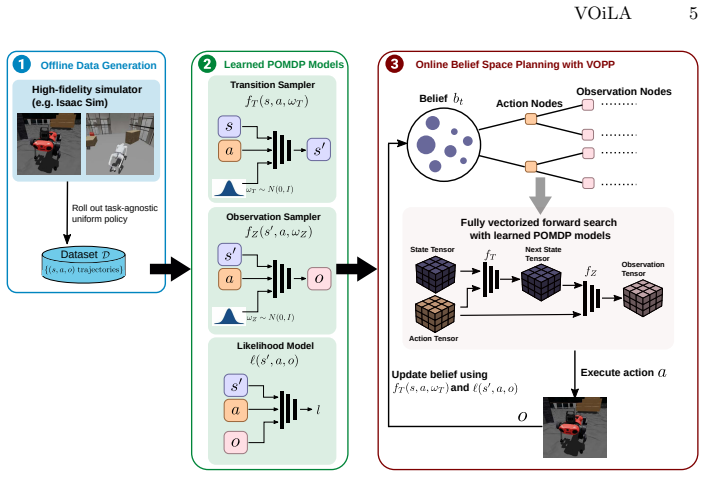
VOiLA learns task-agnostic POMDP models for online planning under uncertainty by using conditional diffusion models to learn transition and observation samplers, learning observation-likelihood models for particle-based belief updates, distilling the diffusion samplers into compact feedforward generators, and integrating them with the Vectorized Online POMDP Planner (VOPP) for GPU-parallelized planning, resulting in up to nearly three orders of magnitude reduction in sampling cost and strong performance on benchmarks and physical robots.
What carries the argument
Conditional diffusion models for POMDP transition and observation samplers, distilled into feedforward generators and paired with vectorized online planning.
If this is right
- The distillation reduces sampling cost by up to nearly three orders of magnitude.
- VOiLA achieves equal or better performance than Recurrent Soft Actor Critic on three benchmark problems while using less than 10% training data.
- It generalizes much better to unseen environment configurations.
- The learned models transfer to physical robots and succeed in 10 of 10 runs using only simulated data.
- VOiLA enables efficient online planning with learned generative POMDP models.
Where Pith is reading between the lines
- The approach may lower the barrier for using POMDP planning in domains where collecting large amounts of real data is costly or unsafe.
- Vectorization on GPUs could allow scaling to higher-dimensional or more complex POMDP problems.
- Distilling diffusion models might be useful in other model-based planning or control settings beyond POMDPs.
- Further work could test whether the method works with different underlying planners or on a wider range of robot tasks.
Load-bearing premise
The diffusion models trained only in simulation produce accurate enough transition and observation samples to support successful planning and control on the physical robot without any additional adaptation.
What would settle it
Observing failure rates above 50 percent in the physical robot task when relying solely on the simulation-trained models would falsify the claim of effective sim-to-real transfer.
Figures

read the original abstract
Planning under uncertainty is an essential capability for autonomous robots. The Partially Observable Markov Decision Process (POMDP) provides a powerful framework for such a capability. Although POMDP-based planning has advanced significantly, its application to real-world problems is often limited by the difficulty of obtaining faithful POMDP models. We present Vectorized Online planning wIth Learned diffusion model for POMDP Agents (VOiLA), a framework that learns task-agnostic POMDP models for online planning under uncertainty. VOiLA learns transition and observation samplers using conditional diffusion models and learns observation-likelihood models for particle-based belief updates. To enable efficient online planning, the diffusion samplers are distilled into compact feedforward generators and integrated with Vectorized Online POMDP Planner (VOPP), an online POMDP planner designed to leverage GPU parallelization. Experimental results indicate the distillation strategy reduces sampling cost by up to nearly three orders of magnitude, making learned generative POMDP models practical for online planning. Evaluation of VOiLA on three benchmark problems indicate that VOiLA achieves equal or better performance than Recurrent Soft Actor Critic while using less than 10% training data, and generalizes much better to unseen environment configurations. Physical robot evaluation indicates VOiLA uses the models learned using only simulated data and generates a policy that successfully accomplish the task in 10 of 10 runs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents VOiLA, a framework for learning task-agnostic POMDP transition and observation models via conditional diffusion models, distilling the samplers into compact feedforward generators, and integrating them with the vectorized online planner VOPP for GPU-parallelized planning under uncertainty. It claims up to three orders of magnitude reduction in sampling cost via distillation, equal or superior performance to Recurrent Soft Actor-Critic on three benchmarks using <10% training data with improved generalization to unseen configurations, and successful sim-to-real transfer yielding 10/10 physical robot task success using only simulation-trained models.
Significance. If the experimental claims hold with proper validation, the work would demonstrate a practical route to deploying learned generative POMDP models for online planning, addressing data efficiency and sim-to-real gaps in robotics applications that require uncertainty handling.
major comments (3)
- [Abstract] Abstract: the reported 10/10 physical success rate and the claim of using only simulated data without fine-tuning are presented without any experimental protocol, statistical tests, error bars, ablation studies, or details on how simulation fidelity was achieved (e.g., domain randomization or calibration), rendering the support for the central sim-to-real claim impossible to assess.
- [Physical robot evaluation] Physical robot evaluation: the assertion that diffusion-based transition and observation models transfer directly from simulation to hardware without further adaptation is load-bearing for the generalization claim, yet no information is supplied on domain randomization, sensor noise modeling, or parameter matching between sim and real dynamics.
- [Benchmark evaluation] Benchmark evaluation: the statements of equal/better performance than Recurrent SAC with <10% data and superior generalization lack reported statistical tests, variance measures, or ablation details on the contribution of the diffusion models versus the planner, undermining assessment of the data-efficiency claim.
minor comments (2)
- Clarify the exact architecture and training procedure for the observation-likelihood models used in particle-based belief updates.
- Provide quantitative timing or FLOPs comparisons to substantiate the 'nearly three orders of magnitude' sampling-cost reduction from distillation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental clarity and validation. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 10/10 physical success rate and the claim of using only simulated data without fine-tuning are presented without any experimental protocol, statistical tests, error bars, ablation studies, or details on how simulation fidelity was achieved (e.g., domain randomization or calibration), rendering the support for the central sim-to-real claim impossible to assess.
Authors: We agree the abstract is space-constrained and omits protocol details. The full manuscript (physical robot evaluation section) describes the 10 independent hardware trials using only simulation-trained models with no fine-tuning. We will revise the abstract to cross-reference the detailed protocol and add a concise note on simulation fidelity. We will also report variance across seeds where applicable and note hardware constraints limiting trial count. revision: yes
-
Referee: [Physical robot evaluation] Physical robot evaluation: the assertion that diffusion-based transition and observation models transfer directly from simulation to hardware without further adaptation is load-bearing for the generalization claim, yet no information is supplied on domain randomization, sensor noise modeling, or parameter matching between sim and real dynamics.
Authors: We acknowledge the need for explicit details on the sim-to-real bridge. The manuscript states successful transfer but will be expanded in the physical evaluation section to describe the domain randomization applied during diffusion model training, sensor noise modeling in simulation, and parameter matching/randomization between sim and real dynamics. These additions will directly support the generalization claim. revision: yes
-
Referee: [Benchmark evaluation] Benchmark evaluation: the statements of equal/better performance than Recurrent SAC with <10% data and superior generalization lack reported statistical tests, variance measures, or ablation details on the contribution of the diffusion models versus the planner, undermining assessment of the data-efficiency claim.
Authors: We agree that additional statistical reporting and ablations would improve rigor. We will update the benchmark results to include means, standard deviations, and error bars over multiple random seeds, conduct appropriate statistical tests (e.g., paired t-tests) for comparisons, and add ablations isolating the diffusion model contributions from the VOPP planner. These changes will be included in the revised manuscript. revision: yes
Circularity Check
No circularity in derivation or performance claims
full rationale
The paper describes an empirical framework: conditional diffusion models are trained to learn transition/observation samplers, distilled into feedforward generators, and integrated with VOPP for online POMDP planning. Performance claims (equal/better than RSAC with <10% data, 10/10 physical-robot success) are presented as direct experimental outcomes on benchmarks and hardware transfer, not as quantities derived from or forced by fitted parameters within the method itself. No equations, self-definitional loops, or load-bearing self-citations appear in the abstract or method summary that would reduce reported results to inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arulampalam, M., Maskell, S., Gordon, N., Clapp, T.: A tutorial on particle filters for online nonlinear/non-gaussian bayesian tracking. IEEE Transac- tions on Signal Processing 50(2), 174–188 (2002). DOI 10.1109/78.978374
-
[2]
IMA Journal of Numerical Analysis 41(4), 2311–2330 (2021)
Blanchard, P., Higham, D.J., Higham, N.J.: Accurately computing the log- sum-exp and softmax functions. IMA Journal of Numerical Analysis 41(4), 2311–2330 (2021)
2021
-
[3]
IJRR (2022)
Collins, N., Kurniawati, H.: Locally-connected interrelated network: A for- ward propagation primitive. IJRR (2022)
2022
-
[4]
In: L4DC, pp
Deglurkar, S., Lim, M.H., Tucker, J., Sunberg, Z.N., Faust, A., Tomlin, C.: Compositional learning-based planning for vision POMDPs. In: L4DC, pp. 469–482. PMLR (2023)
2023
-
[5]
In: ICLR (2020)
Hafner, D., Lillicrap, T., Ba, J., Norouzi, M.: Dream to control: Learning behaviors by latent imagination. In: ICLR (2020)
2020
-
[6]
In: AAAI fall symposia, vol
Hausknecht, M.J., Stone, P.: Deep Recurrent Q-Learning for Partially Ob- servable MDPs. In: AAAI fall symposia, vol. 45, p. 141 (2015)
2015
-
[7]
Ad- vances in neural information processing systems 33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Ad- vances in neural information processing systems 33, 6840–6851 (2020)
2020
-
[8]
In: ICRA (to appear)
Hoerger, M., Sudrajat, M., Kurniawati, H.: Vectorized online POMDP plan- ning. In: ICRA (to appear). IEEE, Vienna, Austria (2026)
2026
-
[9]
In: ICLR (2018)
Kapturowski, S., Ostrovski, G., Quan, J., Munos, R., Dabney, W.: Recurrent experience replay in distributed reinforcement learning. In: ICLR (2018)
2018
-
[10]
NeurIPS 30 (2017)
Karkus, P., Hsu, D., Lee, W.S.: Qmdp-net: Deep learning for planning under partial observability. NeurIPS 30 (2017)
2017
-
[11]
In: IJCAI (2025)
Kim, E., Kurniawati, H.: Partially Observable Reference Policy Program- ming: Approximately Solving POMDPs. In: IJCAI (2025)
2025
-
[12]
Annual Review of Control, Robotics, and Autonomous Systems 5(1) (2022) 16 Marcus Hoerger et al
Kurniawati, H.: Partially Observable Markov Decision Processes and Robotics. Annual Review of Control, Robotics, and Autonomous Systems 5(1) (2022) 16 Marcus Hoerger et al
2022
-
[13]
In: ISRR, pp
Kurniawati, H., Yadav, V.: An online POMDP solver for uncertainty plan- ning in dynamic environment. In: ISRR, pp. 611–629. Springer (2016)
2016
-
[14]
Predicting structured data 1(0) (2006)
LeCun, Y., Chopra, S., Hadsell, R., Ranzato, M., Huang, F., et al.: A tuto- rial on energy-based learning. Predicting structured data 1(0) (2006)
2006
-
[15]
Advances in neural information processing systems 33, 741–752 (2020)
Lee, A.X., Nagabandi, A., Abbeel, P., Levine, S.: Stochastic latent actor- critic: Deep reinforcement learning with a latent variable model. Advances in neural information processing systems 33, 741–752 (2020)
2020
-
[16]
In: Robotics: Science and Systems
Lee, Y., Cai, P., Hsu, D.: MAGIC: Learning Macro-Actions for Online POMDP Planning . In: Robotics: Science and Systems. Virtual (2021)
2021
-
[17]
arXiv preprint arXiv:2511.04831 (2025)
Mittal, M., Roth, P., Tigue, J., Richard, A., Zhang, O., Du, P., Serrano- Munoz, A., Yao, X., Zurbr¨ ugg, R., Rudin, N., et al.: Isaac lab: A gpu- accelerated simulation framework for multi-modal robot learning. arXiv preprint arXiv:2511.04831 (2025)
Pith/arXiv arXiv 2025
-
[18]
In: Reinforcement Learning Conference (RLC) (2024)
Moss, R.J., Corso, A., Caers, J., Kochenderfer, M.J.: BetaZero: Belief-State Planning for Long-Horizon POMDPs using Learned Approximations. In: Reinforcement Learning Conference (RLC) (2024)
2024
-
[19]
In: ICML, pp
Ni, T., Eysenbach, B., Salakhutdinov, R.: Recurrent model-free RL can be a strong baseline for many POMDPs. In: ICML, pp. 16,691–16,723 (2022)
2022
-
[20]
arXiv preprint arXiv:1807.03748 (2018)
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018)
Pith/arXiv arXiv 2018
-
[21]
Mathematics of Operations Research 12(3), 441–450 (1987)
Papadimitriou, C.H., Tsitsiklis, J.N.: The complexity of Markov decision processes. Mathematics of Operations Research 12(3), 441–450 (1987)
1987
-
[22]
In: ICML, pp
Parisotto, E., Song, F., Rae, J., Pascanu, R., Gulcehre, C., Jayakumar, S., Jaderberg, M., Kaufman, R.L., Clark, A., Noury, S., et al.: Stabilizing transformers for reinforcement learning. In: ICML, pp. 7487–7498 (2020)
2020
-
[23]
NeurIPS 32 (2019)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An im- perative style, high-performance deep learning library. NeurIPS 32 (2019)
2019
-
[24]
In: CoRL, pp
Rudin, N., Hoeller, D., Reist, P., Hutter, M.: Learning to walk in minutes using massively parallel deep reinforcement learning. In: CoRL, pp. 91–100. PMLR (2022)
2022
-
[25]
arXiv preprint arXiv:2202.00512 (2022)
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512 (2022)
Pith/arXiv arXiv 2022
-
[26]
Nature 588(7839), 604–609 (2020)
Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T., et al.: Mas- tering atari, go, chess and shogi by planning with a learned model. Nature 588(7839), 604–609 (2020)
2020
-
[27]
In: NeurIPS, vol
Silver, D., Veness, J.: Monte Carlo planning in large POMDPs. In: NeurIPS, vol. 2, p. 2164–2172. Red Hook, New York (2010)
2010
-
[28]
In: ICLR (2021)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: ICLR (2021)
2021
-
[29]
In: ICAPS, pp
Sunberg, Z., Kochenderfer, M.: Online algorithms for POMDPs with contin- uous state, action, and observation spaces. In: ICAPS, pp. 259–263 (2018)
2018
-
[30]
Ye, N., Somani, A., Hsu, D., Lee, W.S.: DESPOT: Online POMDP planning with regularization. JAIR 58, 231–266 (2017). DOI 10.1613/jair.5328
-
[31]
In: CVPR, pp
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation representations in neural networks. In: CVPR, pp. 5745–5753 (2019)
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.