Token-Operations-Oriented Inference Optimization Techniques for Large Models
Pith reviewed 2026-06-26 16:13 UTC · model grok-4.3
The pith
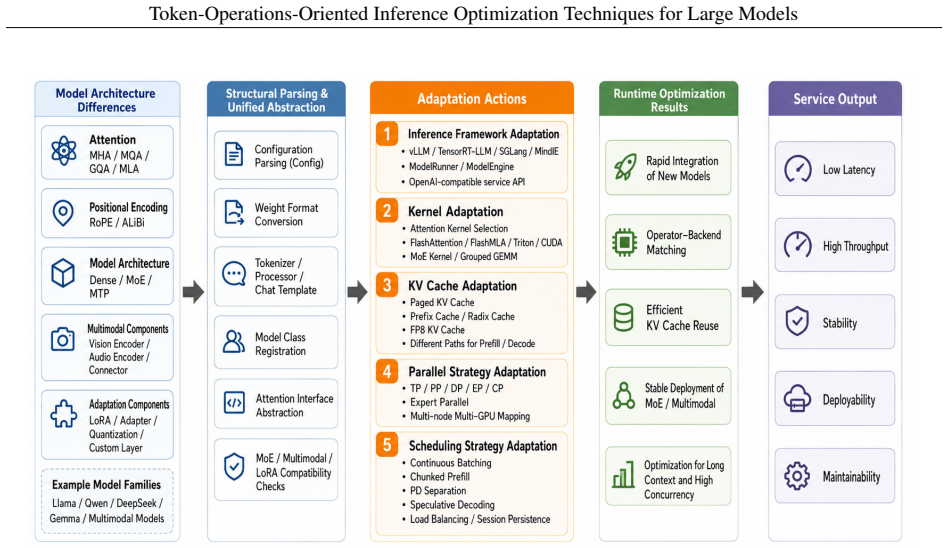
Large-model inference optimization can be organized into a four-layer architecture of Multi-model Fusion, Model Optimization, Compute-Model Fusion, and Compute-Network-Model Fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Centered on token-oriented inference optimization technology, this paper proposes for the first time a four-layer technical architecture consisting of Multi-model Fusion, Model Optimization, Compute-Model Fusion, and Compute-Network-Model Fusion. It systematically reviews the key technologies and current industry status across these four levels and analyzes the application value of related technologies in real-world business scenarios.
What carries the argument
The four-layer technical architecture (Multi-model Fusion, Model Optimization, Compute-Model Fusion, Compute-Network-Model Fusion) that categorizes all token-oriented inference optimization techniques.
If this is right
- Enables a systematic review of technologies at each of the four layers.
- Supports analysis of how each layer contributes to cost reduction and stability in business settings.
- Supplies a concrete path toward lower token production costs.
- Leads to higher token service efficiency and more stable token supply.
- Moves large-model services from callable to reliably operable.
Where Pith is reading between the lines
- The same layering could be used to classify new techniques that appear after the paper's publication.
- Industry groups might adopt the four layers as a shared vocabulary when comparing vendor offerings.
- A follow-up mapping exercise could test whether every published optimization paper fits inside one layer.
Load-bearing premise
The four layers form a complete and non-overlapping way to group every relevant token-oriented optimization technique.
What would settle it
Discovery of a concrete optimization technique for token production that cannot be placed in any of the four layers without significant overlap or forcing.
Figures















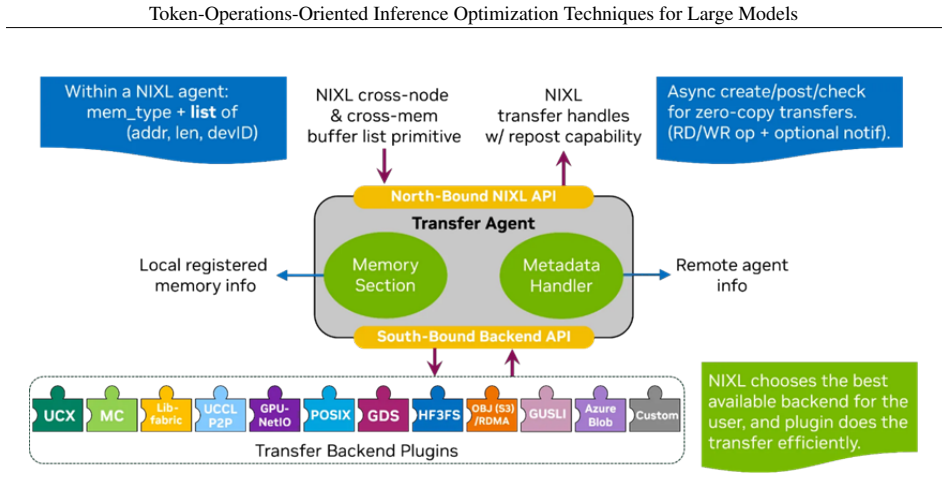
read the original abstract
Large model inference optimization serves as a key foundation for supporting the scalable, low-cost, and highly stable operation of large model services. Centered on token-oriented inference optimization technology, this paper proposes for the first time a four-layer technical architecture consisting of Multi-model Fusion, Model Optimization, Compute-Model Fusion, and Compute-Network-Model Fusion. It systematically reviews the key technologies and current industry status across these four levels and analyzes the application value of related technologies in real-world business scenarios. This paper provides a practical technical path for reducing token production costs, improving token service efficiency, ensuring the stability of token supply, and driving the transition of large model services from being merely callable to being operable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes for the first time a four-layer technical architecture for token-operations-oriented inference optimization in large models—Multi-model Fusion, Model Optimization, Compute-Model Fusion, and Compute-Network-Model Fusion—and systematically reviews key technologies and industry status across these layers while analyzing their value for reducing token production costs, improving efficiency, and ensuring stability in real-world business scenarios.
Significance. If the four-layer categorization is shown to be complete, non-overlapping, and superior to existing organizing principles, the work could provide a useful systematic framework for practitioners seeking to reduce costs and improve stability in large-model inference services.
major comments (1)
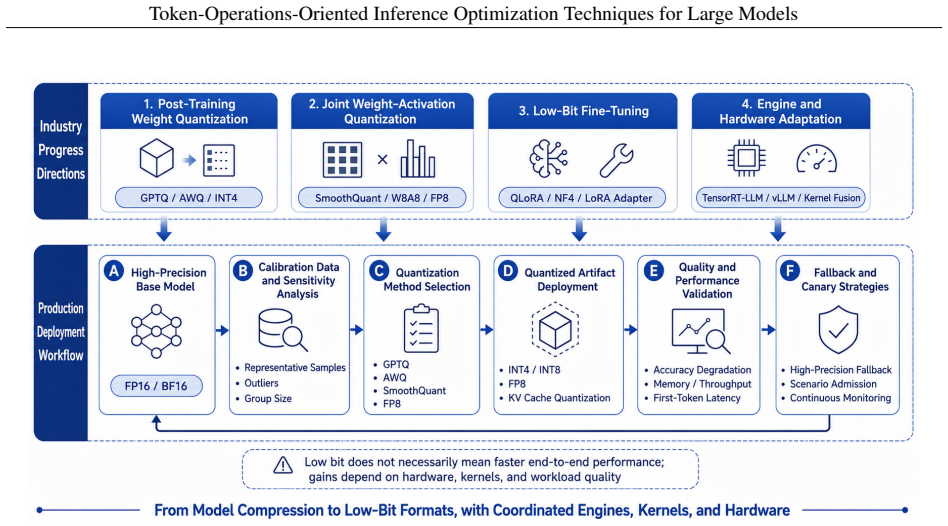
- Abstract (central claim): the manuscript asserts that the four-layer architecture is proposed 'for the first time' and provides a complete organizing principle, yet supplies no explicit assignment rules, coverage argument, or comparison to prior taxonomies; without these, it is impossible to verify whether techniques such as speculative decoding or continuous batching fall cleanly into one layer or span multiple layers, undermining the claim that the structure advances the stated goals of cost reduction and stability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the central claim of the four-layer architecture. The comment correctly identifies areas where the manuscript can be strengthened to better support the novelty and utility of the proposed taxonomy. We will revise accordingly.
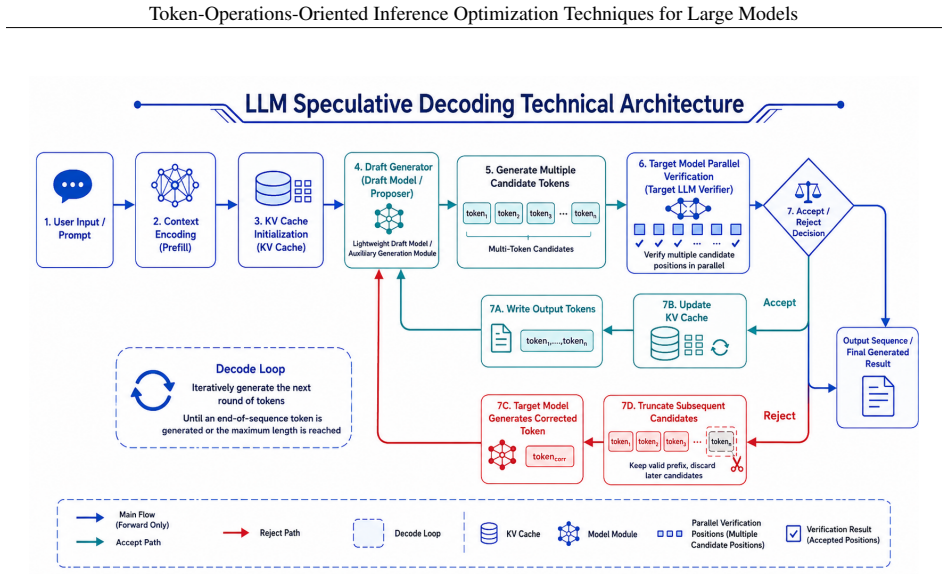
read point-by-point responses
-
Referee: Abstract (central claim): the manuscript asserts that the four-layer architecture is proposed 'for the first time' and provides a complete organizing principle, yet supplies no explicit assignment rules, coverage argument, or comparison to prior taxonomies; without these, it is impossible to verify whether techniques such as speculative decoding or continuous batching fall cleanly into one layer or span multiple layers, undermining the claim that the structure advances the stated goals of cost reduction and stability.
Authors: We agree that explicit assignment rules, a coverage argument, and comparisons to prior taxonomies are needed to substantiate the claim of a complete, non-overlapping organizing principle. The manuscript will be revised to include a new subsection (likely in Section 2 or as an expanded introduction) that: (1) defines assignment criteria based on the primary scope of optimization (e.g., Multi-model Fusion addresses cross-model coordination, Model Optimization targets intra-model improvements, Compute-Model Fusion integrates hardware scheduling with model execution, and Compute-Network-Model Fusion extends to distributed networking); (2) provides a mapping for representative techniques, placing speculative decoding under Model Optimization (as it primarily augments token generation at the model level) and continuous batching under Compute-Model Fusion (due to its dynamic scheduling of compute resources with model inference); and (3) compares the four-layer structure against existing taxonomies in the literature (e.g., those focused solely on model compression or system-level scheduling). This addition will clarify how the framework organizes techniques to achieve cost reduction and stability without claiming the layers are individually unprecedented. We maintain that the integrated four-layer view offers a novel practical lens for practitioners, but acknowledge the current presentation requires this elaboration to fully validate the central claim. revision: yes
Circularity Check
No circularity: survey paper with no derivations or fitted predictions
full rationale
The paper is a review and taxonomy proposal centered on a four-layer architecture for token-oriented inference optimization. It contains no equations, no parameter fitting, no predictions derived from data, and no self-citation chains that reduce a central claim to prior unverified work by the same authors. The categorization is presented as an organizing framework rather than a mathematical derivation, so no step reduces by construction to its inputs. This matches the default expectation for non-circular survey papers.
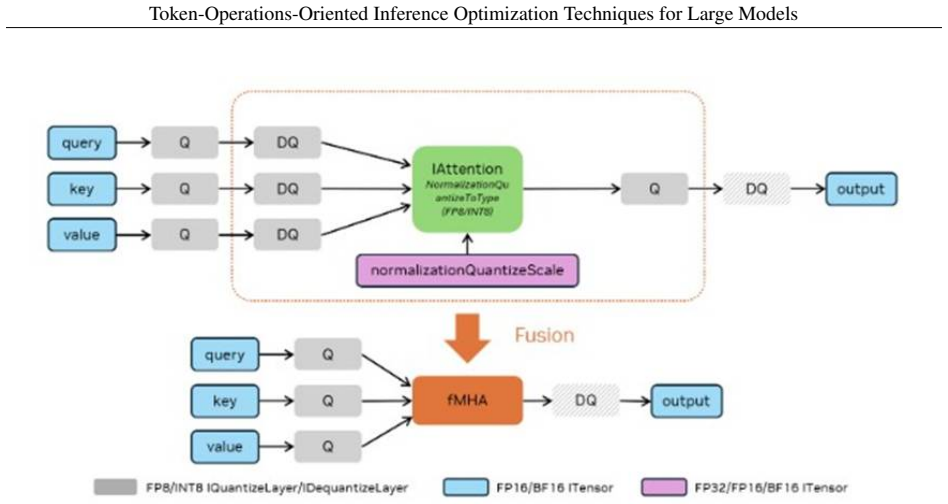
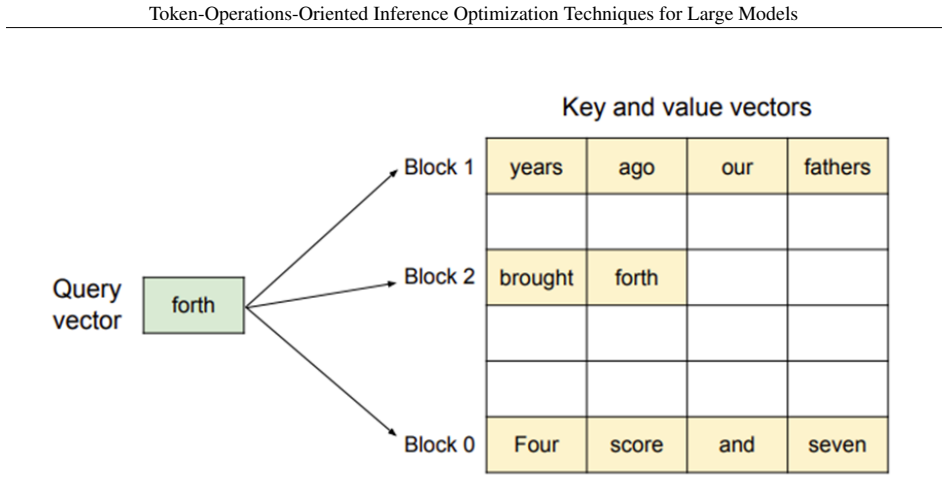
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Survey on Large Language Model Benchmarks, 2025
Shiwen Ni, Guhong Chen, Shuaimin Li, et al. A Survey on Large Language Model Benchmarks, 2025. URL https://arxiv.org/abs/2508.15361
arXiv 2025
-
[2]
Yupeng Chang, Xu Wang, Jindong Wang, et al. A Survey on Evaluation of Large Language Models.ACM Transactions on Intelligent Systems and Technology, 15(3):1–45, 2024. doi: 10.1145/3641289. URL https: //doi.org/10.1145/3641289
-
[3]
Measuring Massive Multitask Language Understanding,
Dan Hendrycks, Collin Burns, Steven Basart, et al. Measuring Massive Multitask Language Understanding,
-
[4]
URLhttps://arxiv.org/abs/2009.03300
Pith/arXiv arXiv 2009
-
[5]
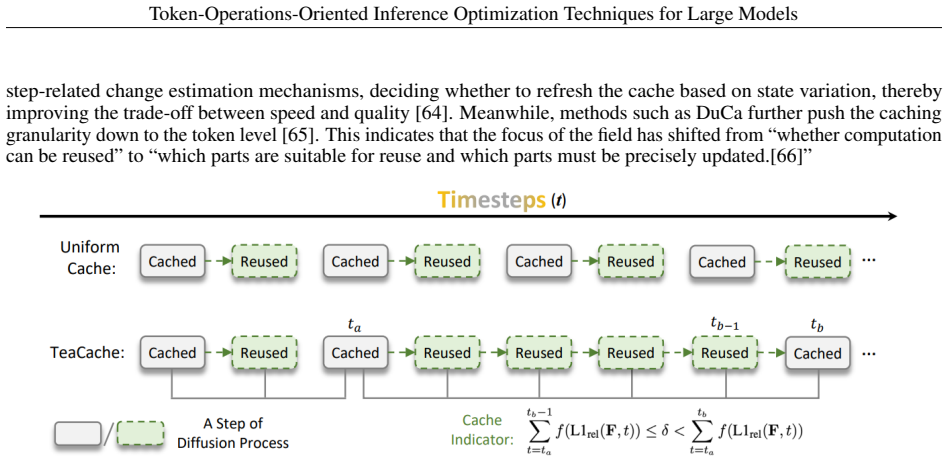
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, et al. Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models.Transactions on Machine Learning Research, 2023. URL https://arxiv.org/abs/2206.04615
Pith/arXiv arXiv 2023
-
[6]
Holistic Evaluation of Language Models.Transactions on Machine Learning Research, 2023
Percy Liang, Rishi Bommasani, Tony Lee, et al. Holistic Evaluation of Language Models.Transactions on Machine Learning Research, 2023. URLhttps://openreview.net/forum?id=iO4LZibEqW
2023
-
[7]
Artificial Analysis intelligence benchmarking methodology, n.d
Artificial Analysis. Artificial Analysis intelligence benchmarking methodology, n.d. URL https://artifici alanalysis.ai/methodology/intelligence-benchmarking
-
[8]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, et al. Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. InProceedings of the 41st International Conference on Machine Learning, pages 8359–8388. PMLR, 2024. URLhttps://proceedings.mlr.press/v235/chiang24b.html
2024
-
[9]
Leaderboard, n.d
Arena.AI. Leaderboard, n.d. URLhttps://arena.ai/leaderboard
-
[10]
Quantifying Capability Boundaries: An Application-Driven Analysis for Large Language Model Selection
Kaikai Zhao, Zhaoxiang Liu, Shun Lu, et al. Quantifying Capability Boundaries: An Application-Driven Analysis for Large Language Model Selection. InProceedings of the 2025 9th International Conference on Computer Science and Artificial Intelligence, pages 595–601, 2025. doi: 10.1145/3788149.3788170. URL https://doi.org/10.1145/3788149.3788170
-
[11]
Kaikai Zhao, Zhaoxiang Liu, Xuejiao Lei, et al. Quantifying the Capability Boundary of DeepSeek Models: An Application-Driven Performance Analysis, 2025. URLhttps://arxiv.org/abs/2502.11164
arXiv 2025
-
[12]
What is the Best Model? Application-Driven Evaluation for Large Language Models
Shiguo Lian, Kaikai Zhao, Xinhui Liu, et al. What is the Best Model? Application-Driven Evaluation for Large Language Models. InNatural Language Processing and Chinese Computing, volume 15361 ofLecture Notes in Computer Science, pages 67–79, 2025. doi: 10.1007/978-981-97-9437-9_6. URL https://doi.org/10.100 7/978-981-97-9437-9_6
-
[13]
Pinchbench-upgraded, n.d
UnicomAI. Pinchbench-upgraded, n.d. URLhttps://github.com/UnicomAI/pinchbench-upgraded
-
[14]
OrchestraLLM: Efficient Orchestration of Language Models for Dialogue State Tracking
Chia-Hsuan Lee, Hao Cheng, and Mari Ostendorf. OrchestraLLM: Efficient Orchestration of Language Models for Dialogue State Tracking. InProceedings of NAACL-HLT 2024 (Long Papers), pages 1434–1445, 2024. URL https://arxiv.org/abs/2311.09758
arXiv 2024
-
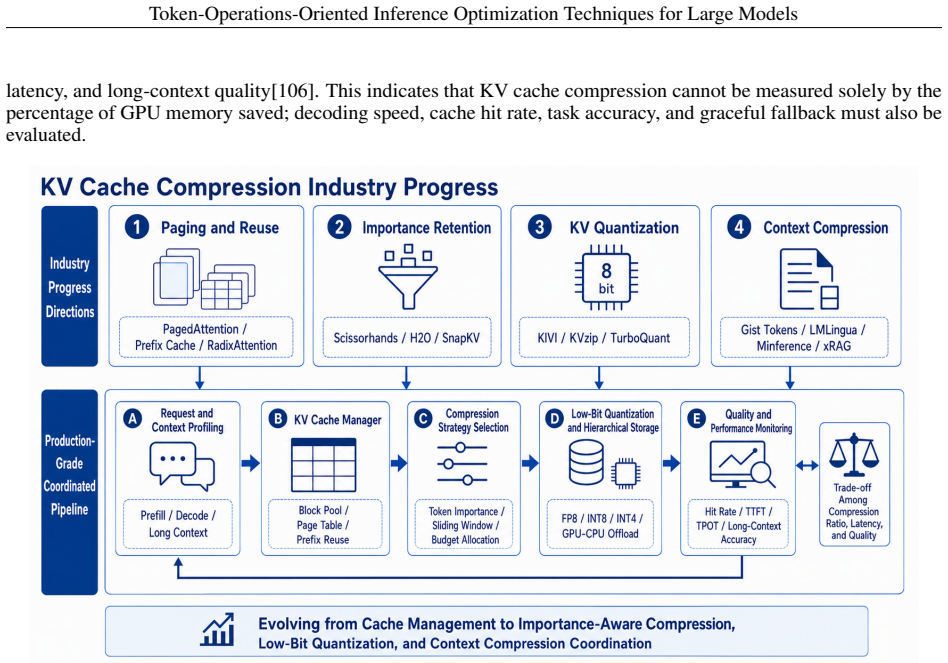
[15]
Semantic Router, n.d
Aurelio Labs. Semantic Router, n.d. URLhttps://github.com/aurelio-labs/semantic-router
-
[16]
LiteLLM: Python SDK & Proxy Server (AI Gateway) for 100+ LLM APIs, n.d
Berriai. LiteLLM: Python SDK & Proxy Server (AI Gateway) for 100+ LLM APIs, n.d. URL https: //github.com/BerriAI/litellm
-
[17]
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Dujian Ding, Ankur Mallick, Chi Wang, et al. Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing. InProceedings of the 12th International Conference on Learning Representations (ICLR), 2024. URL https: //arxiv.org/abs/2404.14618
arXiv 2024
-
[18]
RouteLLM: Learning to Route LLMs with Preference Data,
Isaac Ong, Amjad Almahairi, Vincent Wu, et al. RouteLLM: Learning to Route LLMs with Preference Data,
-
[19]
URLhttps://arxiv.org/abs/2406.18665
-
[20]
Large Language Model Routing with Benchmark Datasets
Tal Shnitzer, Anthony Ou, Mirian Silva, et al. Large Language Model Routing with Benchmark Datasets. In Conference on Language Modeling (COLM), 2024. URLhttps://arxiv.org/abs/2309.15789. 53 Token-Operations-Oriented Inference Optimization Techniques for Large Models
arXiv 2024
-
[21]
Curran Associates, Inc., Vancouver, Canada (2024)
Shuhao Chen, Weisen Jiang, James Kwok, et al. RouterDC: Query-Based Router by Dual Contrastive Learning for Assembling Large Language Models. InAdvances in Neural Information Processing Systems, volume 37, pages 66305–66328. Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2024. doi: 10.52202/0 79017-2120. URLhttps://doi.org/10.52202/079017-2120
work page doi:10.52202/0 2024
-
[22]
Fusing Models with Complementary Expertise
Hongyi Wang, Felipe Maia Polo, Yuekai Sun, et al. Fusing Models with Complementary Expertise. In Proceedings of the 12th International Conference on Learning Representations (ICLR), 2024. URL https: //arxiv.org/abs/2310.01542
arXiv 2024
-
[23]
Understanding intelligent prompt routing in Amazon Bedrock, n.d
Amazon Web Services. Understanding intelligent prompt routing in Amazon Bedrock, n.d. URL https: //docs.aws.amazon.com/bedrock/latest/userguide/prompt-routing.html
-
[24]
Introducing Martian - Better AI Tools Through Better Understanding, 2023
Martian. Introducing Martian - Better AI Tools Through Better Understanding, 2023. URL https://withma rtian.com/post/introducing-martian---better-ai-tools-through-better-understanding
2023
-
[25]
Model Routing for Agents, n.d
Not Diamond. Model Routing for Agents, n.d. URLhttps://www.notdiamond.ai
-
[26]
OpenRouter — One API for hundreds of models, n.d
Openrouter. OpenRouter — One API for hundreds of models, n.d. URLhttps://openrouter.ai/
-
[27]
Introducing GPT-5, 2025
OpenAI. Introducing GPT-5, 2025. URLhttps://openai.com/index/introducing-gpt-5/
2025
-
[28]
Using LLM intelligent routing to improve inference efficiency, n.d
Alibaba Cloud Pai. Using LLM intelligent routing to improve inference efficiency, n.d. URL https://help.a liyun.com/zh/pai/user-guide/use-llm-intelligent-router-to-improve-inference-efficie ncy
-
[29]
Intelligent model routing, n.d
V olcengine Ark. Intelligent model routing, n.d. URL https://www.volcengine.com/docs/82379/182878 8
-
[30]
Lingjiao Chen, Matei Zaharia, and James Zou. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.Transactions on Machine Learning Research (TMLR), 2024. URL https://arxiv.org/abs/2305.05176
Pith/arXiv arXiv 2024
-
[31]
Murong Yue, Jie Zhao, Min Zhang, et al. Large Language Model Cascades with Mixture of Thoughts Rep- resentations for Cost-efficient Reasoning. InProceedings of the 12th International Conference on Learning Representations (ICLR), 2024. URLhttps://arxiv.org/abs/2310.03094
arXiv 2024
-
[32]
AutoMix: Automatically Mixing Language Models
Pranjal Aggarwal, Aman Madaan, Ankit Anand, et al. AutoMix: Automatically Mixing Language Models. In Advances in Neural Information Processing Systems (NeurIPS), 2024. URL https://arxiv.org/abs/2310 .12963
2024
-
[33]
Tabi: An Efficient Multi-Level Inference System for Large Language Models
Yiding Wang, Kai Chen, Haisheng Tan, et al. Tabi: An Efficient Multi-Level Inference System for Large Language Models. InProceedings of the Eighteenth European Conference on Computer Systems, pages 233–248. ACM, 2023. doi: 10.1145/3552326.3587438. URLhttps://doi.org/10.1145/3552326.3587438
-
[34]
Jieyu Zhang, Ranjay Krishna, Ahmed H. Awadallah, et al. EcoAssistant: Using LLM Assistant More Affordably and Accurately, 2023. URLhttps://arxiv.org/abs/2310.03046
arXiv 2023
-
[35]
Fast Inference from Transformers via Speculative Decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast Inference from Transformers via Speculative Decoding. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023. URL https: //arxiv.org/abs/2211.17192
Pith/arXiv arXiv 2023
-
[36]
Unity AI Gateway: Configure Fallbacks on Model Serving Endpoints, n.d
Databricks. Unity AI Gateway: Configure Fallbacks on Model Serving Endpoints, n.d. URL https://docs.d atabricks.com/aws/en/ai-gateway/
-
[37]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, et al. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InProceedings of the 11th International Conference on Learning Representations (ICLR),
-
[38]
URLhttps://arxiv.org/abs/2203.11171
-
[39]
More Agents Is All You Need.Transactions on Machine Learning Research (TMLR), 2024
Junyou Li, Qin Zhang, Yangbin Yu, et al. More Agents Is All You Need.Transactions on Machine Learning Research (TMLR), 2024. URLhttps://arxiv.org/abs/2402.05120
arXiv 2024
-
[40]
LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
Dongfu Jiang, Xiang Ren, and Bill Lin. LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14165–14178. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.acl-long.792. URLhttps...
-
[41]
Knowledge Fusion of Large Language Models
Fanqi Wan, Xinting Huang, Deng Cai, et al. Knowledge Fusion of Large Language Models. InProceedings of the 12th International Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/ab s/2401.10491
arXiv 2024
-
[42]
Mixture-of-Agents Enhances Large Language Model Capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, et al. Mixture-of-Agents Enhances Large Language Model Capabilities. InConference on Language Modeling (COLM), 2024. URL https://arxiv.org/abs/ 2406.04692. 54 Token-Operations-Oriented Inference Optimization Techniques for Large Models
Pith/arXiv arXiv 2024
-
[43]
Efficient Attention Mechanisms for Large Language Models: A Survey,
Yutao Sun, Zhenyu Li, Yike Zhang, et al. Efficient Attention Mechanisms for Large Language Models: A Survey,
-
[44]
URLhttps://arxiv.org/abs/2507.19595
-
[45]
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 Technical Report, 2025. URL https://arxiv.org/abs/ 2505.09388
Pith/arXiv arXiv 2025
-
[46]
DeepSeek-V3 Technical Report, 2024
DeepSeek-AI, Aixin Liu, Bei Feng, et al. DeepSeek-V3 Technical Report, 2024. URL https://arxiv.org/ abs/2412.19437
Pith/arXiv arXiv 2024
-
[47]
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence, 2026
MiniMax, Aili Chen, Aonian Li, et al. The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence, 2026. URLhttps://arxiv.org/abs/2605.26494
Pith/arXiv arXiv 2026
-
[48]
Tri Dao, Daniel Y . Fu, Stefano Ermon, et al. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.Advances in Neural Information Processing Systems, 35:16344–16359, 2022. URL https://arxiv.org/abs/2205.14135
Pith/arXiv arXiv 2022
-
[49]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. InInternational Conference on Learning Representations, pages 35549–35562, 2024. URL https://arxiv.org/abs/2307.0 8691
2024
-
[50]
DeepSeek-V4: towards highly efficient million-token context intelligence, 2026
Deepseek-AI. DeepSeek-V4: towards highly efficient million-token context intelligence, 2026. URL https: //huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
2026
-
[51]
GLM-5: from Vibe Coding to Agentic Engineering, 2026
GLM-5-Team, Aohan Zeng, Xin Lv, et al. GLM-5: from Vibe Coding to Agentic Engineering, 2026. URL https://arxiv.org/abs/2602.15763
Pith/arXiv arXiv 2026
-
[52]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, et al. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles, pages 611–
-
[53]
ACM, 2023. doi: 10.1145/3600006.3613165. URLhttps://doi.org/10.1145/3600006.3613165
-
[54]
MiniMax M3: Frontier Coding, 1M Context, Native Multimodality in One Model, 2026
MiniMax Research. MiniMax M3: Frontier Coding, 1M Context, Native Multimodality in One Model, 2026. URLhttps://www.minimaxi.com/blog/minimax-m3
2026
-
[55]
Qwen3.5-Omni Technical Report, 2026
Qwen Team. Qwen3.5-Omni Technical Report, 2026. URLhttps://arxiv.org/abs/2604.15804
Pith/arXiv arXiv 2026
-
[56]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, 2025
DeepSeek-AI, Aixin Liu, Aoxue Mei, et al. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, 2025. URLhttps://arxiv.org/abs/2512.02556
Pith/arXiv arXiv 2025
-
[57]
A Survey on Mixture of Experts in Large Language Models , ISSN=
Weilin Cai, Juyong Jiang, Fan Wang, et al. A Survey on Mixture of Experts in Large Language Models.IEEE Transactions on Knowledge and Data Engineering, pages 1–20, 2025. doi: 10.1109/tkde.2025.3554028. URL https://doi.org/10.1109/tkde.2025.3554028
-
[58]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, et al. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. InInternational Conference on Learning Representations, 2021. URL https://arxiv.org/abs/2006.16668
Pith/arXiv arXiv 2021
-
[59]
William Fedus, Barret Zoph, and Noam Shazeer. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022. URL https://arxiv.org/abs/2101.03961
Pith/arXiv arXiv 2022
-
[60]
Jiang, Alexandre Sablayrolles, Antoine Roux, et al
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, et al. Mixtral of Experts, 2024. URL https: //arxiv.org/abs/2401.04088
Pith/arXiv arXiv 2024
-
[61]
doi: 10.18653/v1/2024.acl-long.70
Damai Dai, Chengqi Deng, Chenggang Zhao, et al. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1280–1297. Association for Computational Linguistics, 2024. doi: 10.18653/v1/2024.acl-long.70. UR...
-
[62]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, 2024
DeepSeek-AI, Aixin Liu, Bei Feng, et al. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, 2024. URLhttps://arxiv.org/abs/2405.04434
Pith/arXiv arXiv 2024
-
[63]
TensorRT-LLM expert parallelism documentation, n.d
NVIDIA. TensorRT-LLM expert parallelism documentation, n.d.. URL https://nvidia.github.io/Tenso rRT-LLM/1.1.0rc1/advanced/expert-parallelism.html
-
[64]
Capacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts, 2025
Shwai He, Weilin Cai, Jiayi Huang, et al. Capacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts, 2025. URLhttps://arxiv.org/abs/2503.05066
Pith/arXiv arXiv 2025
-
[65]
Mixture of Heterogeneous Grouped Experts for Language Modeling, 2026
Zhicheng Ma, Xiang Liu, Zhaoxiang Liu, et al. Mixture of Heterogeneous Grouped Experts for Language Modeling, 2026. URLhttps://arxiv.org/abs/2604.23108. 55 Token-Operations-Oriented Inference Optimization Techniques for Large Models
Pith/arXiv arXiv 2026
-
[66]
Optimizing for the Shortest Path in Denoising Diffusion Model
Ping Chen, Xingpeng Zhang, Zhaoxiang Liu, et al. Optimizing for the Shortest Path in Denoising Diffusion Model. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18021–18030. IEEE,
-
[67]
CoT-VLA: Visual chain-of-thought reasoning for vision- language-action models,
doi: 10.1109/cvpr52734.2025.01679. URLhttps://doi.org/10.1109/cvpr52734.2025.01679
-
[68]
A Survey on Cache Methods in Diffusion Models: Toward Efficient Multi-Modal Generation, 2025
Jiacheng Liu, Xinyu Wang, Yuqi Lin, et al. A Survey on Cache Methods in Diffusion Models: Toward Efficient Multi-Modal Generation, 2025. URLhttps://arxiv.org/abs/2510.19755
arXiv 2025
-
[69]
V*: Guided visual search as a core mechanism in multimodal llms
Xinyin Ma, Gongfan Fang, and Xinchao Wang. DeepCache: Accelerating Diffusion Models for Free. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15762–15772. IEEE, 2024. doi: 10.1109/cvpr52733.2024.01492. URLhttps://doi.org/10.1109/cvpr52733.2024.01492
-
[70]
Timestep Embedding Tells: It’s Time to Cache for Video Diffusion Model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, et al. Timestep Embedding Tells: It’s Time to Cache for Video Diffusion Model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. CVPR, 2025. URLhttps://arxiv.org/abs/2411.19108
arXiv 2025
-
[71]
Chang Zou, Evelyn Zhang, Runlin Guo, et al. Rethinking Token-wise Feature Caching: Accelerating Diffusion Transformers with Dual Feature Caching, 2024. URLhttps://arxiv.org/abs/2412.18911
arXiv 2024
-
[72]
LeMiCa: Lexicographic Minimax Path Caching for Efficient Diffusion-Based Video Generation
Huanlin Gao, Ping Chen, Fuyuan Shi, et al. LeMiCa: Lexicographic Minimax Path Caching for Efficient Diffusion-Based Video Generation. InAdvances in Neural Information Processing Systems. NeurIPS, 2025. URLhttps://arxiv.org/abs/2511.00090
arXiv 2025
-
[73]
MeanCache: From Instantaneous to Average Velocity for Accelerating Flow Matching Inference
Huanlin Gao, Ping Chen, Fuyuan Shi, et al. MeanCache: From Instantaneous to Average Velocity for Accelerating Flow Matching Inference. InProceedings of the International Conference on Learning Representations, 2026. URLhttps://arxiv.org/abs/2601.19961
arXiv 2026
-
[74]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, volume 35, 2022. URL https: //proceedings.neurips.cc/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-C onference.html
2022
-
[75]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Denny Zhou, Nathanael Scharli, Le Hou, et al. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. InProceedings of the 11th International Conference on Learning Representations, 2023. URLhttps://arxiv.org/abs/2205.10625
Pith/arXiv arXiv 2023
-
[76]
STaR: Bootstrapping Reasoning With Reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, et al. STaR: Bootstrapping Reasoning With Reasoning. InAdvances in Neural Information Processing Systems. NeurIPS, 2022. URLhttps://arxiv.org/abs/2203.14465
arXiv 2022
-
[77]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, et al. ReAct: Synergizing Reasoning and Acting in Language Models. In Proceedings of the 11th International Conference on Learning Representations, 2023. URL https://arxiv. org/abs/2210.03629v3
Pith/arXiv arXiv 2023
-
[78]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. InAdvances in Neural Information Processing Systems. NeurIPS, 2023. URLhttps://arxiv.org/ abs/2305.10601
Pith/arXiv arXiv 2023
-
[79]
PAL: Program-aided Language Models
Luyu Gao, Aman Madaan, Shuyan Zhou, et al. PAL: Program-aided Language Models. InProceedings of the 40th International Conference on Machine Learning. ICML, 2023. URLhttps://arxiv.org/abs/2211.10435
Pith/arXiv arXiv 2023
-
[80]
Introducing OpenAI o1-preview, 2024
OpenAI. Introducing OpenAI o1-preview, 2024. URL https://openai.com/index/introducing-opena i-o1-preview/
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.