Statistical Properties of Training & Generalization
Pith reviewed 2026-06-26 15:34 UTC · model grok-4.3
The pith
A physics-informed lens explains how neural scaling laws interact with constraints to shape deep learning training and generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Deep learning evades numerous intuitions from classical statistics to achieve high performance; neural scaling laws interplay with the constraints and inductive biases present when applying machine learning to problems in physics, and a physics-informed perspective can justify many model choices while revealing key statistical features of training and generalization.
What carries the argument
Neural scaling laws, which capture power-law improvements in performance with model size, data volume, and compute, modulated by physics-derived constraints and inductive biases.
If this is right
- Scaling laws can be used to forecast performance improvements when physics constraints are added to models.
- Inductive biases from physics reduce the effective data requirements for generalization compared to generic deep learning.
- Training dynamics in physics applications exhibit statistical regularities that classical statistics alone cannot predict.
- Model architecture choices become justifiable when they respect physical symmetries or conservation laws.
Where Pith is reading between the lines
- Hybrid models that embed physics equations directly may exhibit distinct scaling regimes not captured by standard neural scaling laws.
- The same perspective could be tested on non-physics domains by substituting domain-specific constraints for physical ones.
- If the interplay holds, it predicts that removing physics biases from a trained model would degrade scaling behavior predictably.
Load-bearing premise
A physics-informed perspective can meaningfully justify choices in deep learning models and reveal key statistical features of training and generalization.
What would settle it
A controlled comparison showing that scaling exponents and generalization curves in physics tasks remain unchanged when all physical constraints and biases are removed would falsify the claimed interplay.
Figures
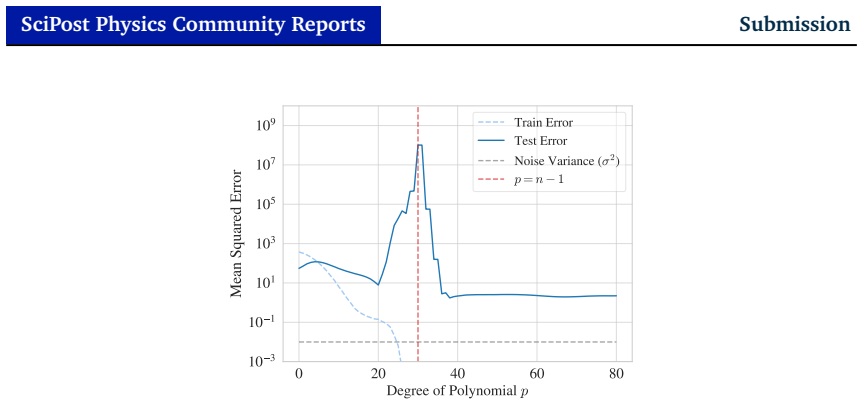
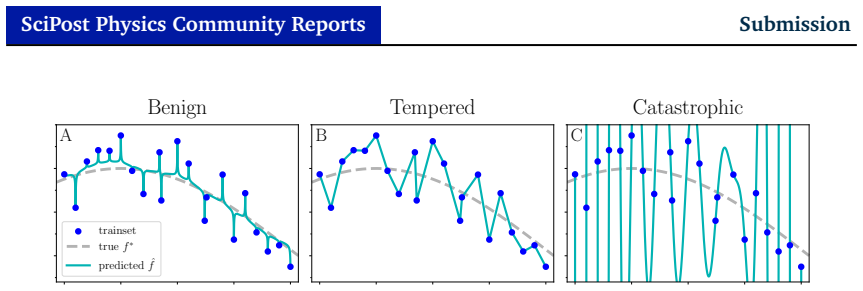
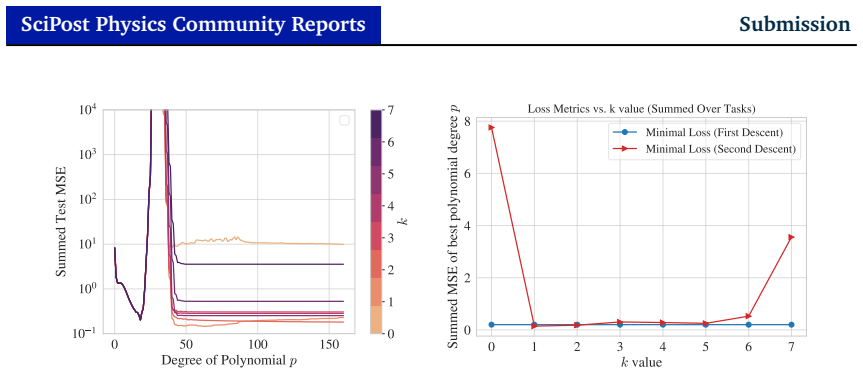
read the original abstract
Deep learning has managed to evade numerous intuitions from classical statistics to achieve unprecedented performance on a number of real-world tasks. In this article, we investigate the key features and surprises of deep learning from a physics-informed perspective, taking care to point out and justify where possible the many choices inherent in constructing a deep learning model. In particular, we review the phenomenon of neural scaling laws and discuss their interplay with the constraints and inductive biases which may be present when applying machine learning to problems in physics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates key features and surprises of deep learning from a physics-informed perspective. It reviews the phenomenon of neural scaling laws and discusses their interplay with constraints and inductive biases in physics applications, while taking care to justify choices in constructing deep learning models and noting how DL evades classical statistical intuitions.
Significance. If substantiated, the work could bridge statistical ML theory with physics applications by linking scaling laws to inductive biases and constraints, potentially aiding model design in scientific domains. The abstract signals an intent for careful discussion of modeling choices, which is a positive feature for a review-style contribution in stat.ML.
major comments (1)
- [Abstract] Abstract: the central claim that a physics-informed perspective meaningfully justifies DL modeling choices and reveals key statistical features of training/generalization is stated without specifying the validation method or evidence used; this is load-bearing for the paper's contribution and cannot be assessed from the provided abstract alone.
Simulated Author's Rebuttal
We thank the referee for their comments. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that a physics-informed perspective meaningfully justifies DL modeling choices and reveals key statistical features of training/generalization is stated without specifying the validation method or evidence used; this is load-bearing for the paper's contribution and cannot be assessed from the provided abstract alone.
Authors: The manuscript is a review-style contribution whose central claims are substantiated by synthesis and citation of the existing literature on neural scaling laws, inductive biases, and physics-constrained ML applications, as developed in the body of the paper. We agree that the abstract does not explicitly identify the review-based nature of the evidence or point to the specific bodies of work being synthesized. We will revise the abstract to state that the discussion draws on a review of the relevant empirical and theoretical literature. revision: yes
Circularity Check
No significant circularity; review perspective with no load-bearing derivations or self-referential fits
full rationale
The supplied abstract and context describe a review paper examining neural scaling laws and physics-informed choices in deep learning, without presenting equations, fitted parameters, predictions, or uniqueness theorems. No derivation chain is exhibited that reduces to its own inputs by construction, self-citation, or renaming. The central claim is a perspective on interplay between scaling laws and inductive biases, which remains independent of any internal fitting or self-citation load-bearing step. This matches the default expectation of a non-circular review format.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[2]
2015 , howpublished=
Keras , author=. 2015 , howpublished=
2015
-
[3]
Paquette, Elliot and Paquette, Courtney and Xiao, Lechao and Pennington, Jeffrey , month = nov, year =. 4+3
-
[4]
Journal of Machine Learning Research , author =
Scaling. Journal of Machine Learning Research , author =. 2022 , pages =
2022
-
[5]
Bordelon, Blake and Atanasov, Alexander and Pehlevan, Cengiz , month = jun, year =. A. doi:10.48550/arXiv.2402.01092 , abstract =
-
[6]
Bordelon, Blake and Atanasov, Alexander and Pehlevan, Cengiz , month = sep, year =. How
-
[7]
Bahri, Yasaman and Dyer, Ethan and Kaplan, Jared and Lee, Jaehoon and Sharma, Utkarsh , month = feb, year =. Explaining. doi:10.48550/arXiv.2102.06701 , abstract =
-
[8]
Journal of Statistical Mechanics: Theory and Experiment , author =
Scaling description of generalization with number of parameters in deep learning , volume =. Journal of Statistical Mechanics: Theory and Experiment , author =. 2020 , note =. doi:10.1088/1742-5468/ab633c , abstract =
-
[9]
Choromanska and M
A. Choromanska and M. Henaff and M. Mathieu and G. B. Arous and Y. LeCun , year =. The Loss Surfaces of Multilayer Networks , publisher =
-
[10]
Draxler and K
F. Draxler and K. Veschgini and M. Salmhofer and F. Hamprecht , year =. Essentially No Barriers in Neural Network Energy Landscapes , publisher =
-
[11]
Belkin and D
M. Belkin and D. Hsu and S. Ma and S. Mandal , year =. Reconciling modern machine-learning practice and the classical bias-variance trade-off , journal =
-
[12]
Hochreiter and J
S. Hochreiter and J. Schmidhuber , year =. Flat Minima , journal =
-
[13]
Kaplan and S
J. Kaplan and S. McCandlish and T. Henighan and T. B. Brown and B. Chess and R. Child and S. GrayA , title =. 2020 , note =
2020
-
[14]
Transactions on Machine Learning Research , author =
The. Transactions on Machine Learning Research , author =
-
[15]
Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks , volume =. Nature Communications , author =. 2021 , note =. doi:10.1038/s41467-021-23103-1 , abstract =
-
[16]
Physical Review Research , author =
Learning curves for overparametrized deep neural networks:. Physical Review Research , author =. 2021 , note =. doi:10.1103/PhysRevResearch.3.023034 , abstract =
-
[17]
Nature Communications , author =
Separation of scales and a thermodynamic description of feature learning in some. Nature Communications , author =. 2023 , note =. doi:10.1038/s41467-023-36361-y , abstract =
-
[18]
Rubin, Noa and Fischer, Kirsten and Lindner, Javed and Dahmen, David and Seroussi, Inbar and Ringel, Zohar and Krämer, Michael and Helias, Moritz , month = may, year =. From. doi:10.48550/arXiv.2502.03210 , abstract =
-
[19]
Ringel, Zohar and Rubin, Noa and Mor, Edo and Helias, Moritz and Seroussi, Inbar , month = apr, year =. Applications of. doi:10.48550/arXiv.2502.18553 , abstract =
-
[20]
Lavie, Itay and Ringel, Zohar , month = feb, year =. Demystifying. doi:10.48550/arXiv.2406.02663 , abstract =
-
[21]
Adaptive kernel predictors from feature-learning infinite limits of neural networks , url =
Lauditi, Clarissa and Bordelon, Blake and Pehlevan, Cengiz , month = sep, year =. Adaptive kernel predictors from feature-learning infinite limits of neural networks , url =. doi:10.48550/arXiv.2502.07998 , abstract =
-
[22]
Jamming transition as a paradigm to understand the loss landscape of deep neural networks , volume =. Physical Review E , author =. doi:10.1103/PhysRevE.100.012115 , number =
-
[23]
, month = dec, year =
Hastie, Trevor and Montanari, Andrea and Rosset, Saharon and Tibshirani, Ryan J. , month = dec, year =. Surprises in
-
[24]
and Saxe, Andrew M
Advani, Madhu S. and Saxe, Andrew M. , month = oct, year =. High-dimensional dynamics of generalization error in neural networks , url =
-
[25]
Dynamics of
Bös, Siegfried and Opper, Manfred , year =. Dynamics of. Advances in
-
[26]
Statistical
Opper, Manfred and Kinzel, Wolfgang , editor =. Statistical. Models of. 1996 , doi =
1996
-
[27]
Nakkiran, Preetum and Kaplun, Gal and Bansal, Yamini and Yang, Tristan and Barak, Boaz and Sutskever, Ilya , month = sep, year =. Deep
-
[28]
Advances in neural information processing systems , author =
Implicit bias of gradient descent on linear convolutional networks , volume =. Advances in neural information processing systems , author =
-
[29]
and Simchowitz, Max and Jordan, Michael I
Lee, Jason D. and Simchowitz, Max and Jordan, Michael I. and Recht, Benjamin , year =. Gradient descent only converges to minimizers , url =. Conference on learning theory , publisher =
-
[30]
Training Compute-Optimal Large Language Models
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and Casas, Diego de Las and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Tom and Noland, Eric and Millican, Katie and Driessche, George van den and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and Simony...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.15556
-
[31]
Levi, Noam Itzhak and Oz, Yaron , month = oct, year =. The. Proceedings of the 42nd
-
[32]
Yang, Ge and Hu, Edward and Babuschkin, Igor and Sidor, Szymon and Liu, Xiaodong and Farhi, David and Ryder, Nick and Pachocki, Jakub and Chen, Weizhu and Gao, Jianfeng , year =. Tuning. Advances in
-
[33]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Bronstein, Michael M. and Bruna, Joan and Cohen, Taco and Veličković, Petar , month = may, year =. Geometric. doi:10.48550/arXiv.2104.13478 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2104.13478
-
[34]
Depthwise
Bordelon, Blake and Noci, Lorenzo and Li, Mufan Bill and Hanin, Boris and Pehlevan, Cengiz , month = oct, year =. Depthwise
-
[35]
Yang, Greg and Yu, Dingli and Zhu, Chen and Hayou, Soufiane , month = oct, year =. Tensor
-
[36]
Blake, Charlie and Eichenberg, Constantin and Dean, Josef and Balles, Lukas and Prince, Luke Yuri and Deiseroth, Björn and Cruz-Salinas, Andres Felipe and Luschi, Carlo and Weinbach, Samuel and Orr, Douglas , month = oct, year =. u-\
-
[37]
Haas, Moritz and Xu, Jin and Cevher, Volkan and Vankadara, Leena Chennuru , month = nov, year =. \
-
[38]
Dey, Nolan and Zhang, Bin Claire and Noci, Lorenzo and Li, Mufan and Bordelon, Blake and Bergsma, Shane and Pehlevan, Cengiz and Hanin, Boris and Hestness, Joel , month = oct, year =. Don't be lazy:. doi:10.48550/arXiv.2505.01618 , abstract =
-
[39]
Qiu, Shikai and Xiao, Lechao and Wilson, Andrew Gordon and Pennington, Jeffrey and Agarwala, Atish , month = jun, year =. Scaling
-
[40]
, month = jul, year =
Yang, Greg and Hu, Edward J. , month = jul, year =. Tensor. Proceedings of the 38th
-
[41]
and Novak, Roman and Liu, Peter J
Everett, Katie and Xiao, Lechao and Wortsman, Mitchell and Alemi, Alexander A. and Novak, Roman and Liu, Peter J. and Gur, Izzeddin and Sohl-Dickstein, Jascha and Kaelbling, Leslie Pack and Lee, Jaehoon and Pennington, Jeffrey , month = jul, year =. Scaling. doi:10.48550/arXiv.2407.05872 , abstract =
-
[42]
Ishikawa, Satoki and Karakida, Ryo , month = oct, year =. On the
-
[43]
Infinite
Bordelon, Blake and Chaudhry, Hamza Tahir and Pehlevan, Cengiz , month = nov, year =. Infinite
-
[44]
Lingle, Lucas , month = feb, year =. An. doi:10.48550/arXiv.2404.05728 , abstract =
-
[45]
Transactions on Machine Learning Research , author =
A thorough reproduction and evaluation of \. Transactions on Machine Learning Research , author =
-
[46]
Dey, Nolan and Gosal, Gurpreet and Zhiming and Chen and Khachane, Hemant and Marshall, William and Pathria, Ribhu and Tom, Marvin and Hestness, Joel , month = apr, year =. Cerebras-. doi:10.48550/arXiv.2304.03208 , abstract =
-
[47]
Decoupled
Loshchilov, Ilya and Hutter, Frank , month = sep, year =. Decoupled
-
[48]
Sharpness-aware
Foret, Pierre and Kleiner, Ariel and Mobahi, Hossein and Neyshabur, Behnam , month = oct, year =. Sharpness-aware
-
[49]
Shampoo: Preconditioned Stochastic Tensor Optimization
Gupta, Vineet and Koren, Tomer and Singer, Yoram , month = mar, year =. Shampoo:. doi:10.48550/arXiv.1802.09568 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.09568
-
[50]
Proceedings of the 33rd
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and Desmaison, Alban and Köpf, Andreas and Yang, Edward and DeVito, Zach and Raison, Martin and Tejani, Alykhan and Chilamkurthy, Sasank and Steiner, Benoit and Fang, Lu and B...
-
[51]
Developers, TensorFlow , month = aug, year =
-
[52]
2026 , eprint=
On the origin of neural scaling laws: from random graphs to natural language , author=. 2026 , eprint=
2026
-
[53]
2023 , eprint=
Depthwise Hyperparameter Transfer in Residual Networks: Dynamics and Scaling Limit , author=. 2023 , eprint=
2023
-
[54]
2022 , eprint=
Meta-Principled Family of Hyperparameter Scaling Strategies , author=. 2022 , eprint=
2022
-
[55]
2023 , eprint=
Effective Theory of Transformers at Initialization , author=. 2023 , eprint=
2023
-
[56]
Scaling laws for amplitude surrogates
Bahl, Henning and Bres \'o -Pla, Victor and Butter, Anja and Ramirez, Joaqu \' n Iturriza. Scaling laws for amplitude surrogates. 2026. arXiv:2601.13308
arXiv 2026
-
[57]
Advances in Neural Information Processing Systems , year =
Identifying and Attacking the Saddle Point Problem in High-Dimensional Non-Convex Optimization , author =. Advances in Neural Information Processing Systems , year =. 1406.2572 , archiveprefix=
-
[58]
Advances in Neural Information Processing Systems , year =
Deep Learning without Poor Local Minima , author =. Advances in Neural Information Processing Systems , year =. 1605.07110 , archiveprefix=
-
[59]
Proceedings of the 34th International Conference on Machine Learning , year =
How to Escape Saddle Points Efficiently , author =. Proceedings of the 34th International Conference on Machine Learning , year =. 1703.00887 , archiveprefix=
-
[60]
USSR Computational Mathematics and Mathematical Physics , volume =
Some Methods of Speeding Up the Convergence of Iteration Methods , author =. USSR Computational Mathematics and Mathematical Physics , volume =
-
[61]
Introductory Lectures on Convex Optimization: A Basic Course , author =
-
[62]
Proceedings of the 30th International Conference on Machine Learning , year =
On the Importance of Initialization and Momentum in Deep Learning , author =. Proceedings of the 30th International Conference on Machine Learning , year =. 1309.1019 , archiveprefix =
-
[63]
Advances in Neural Information Processing Systems , year =
Loss Surfaces, Mode Connectivity, and Fast Ensembling of Deep Neural Networks , author =. Advances in Neural Information Processing Systems , year =. 1802.10026 , archiveprefix =
-
[64]
2014 , eprint =
Adam: A Method for Stochastic Optimization , author =. 2014 , eprint =
2014
-
[65]
2016 , eprint =
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima , author =. 2016 , eprint =
2016
-
[66]
2017 , eprint =
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour , author =. 2017 , eprint =
2017
-
[67]
2018 , eprint =
Don't Decay the Learning Rate, Increase the Batch Size , author =. 2018 , eprint =
2018
-
[68]
Proceedings of the 33rd International Conference on Machine Learning , year =
Train Faster, Generalize Better: Stability of Stochastic Gradient Descent , author =. Proceedings of the 33rd International Conference on Machine Learning , year =. 1509.01240 , archiveprefix =
-
[69]
Journal of Machine Learning Research , volume =
Stochastic Gradient Descent as Approximate Bayesian Inference , author =. Journal of Machine Learning Research , volume =. 2017 , url =
2017
-
[70]
2017 , eprint =
SGDR: Stochastic Gradient Descent with Warm Restarts , author =. 2017 , eprint =
2017
-
[71]
2017 IEEE Winter Conference on Applications of Computer Vision (WACV) , year =
Cyclical Learning Rates for Training Neural Networks , author =. 2017 IEEE Winter Conference on Applications of Computer Vision (WACV) , year =
2017
-
[72]
Proceedings of the 33rd International Conference on Machine Learning , year =
Group Equivariant Convolutional Networks , author =. Proceedings of the 33rd International Conference on Machine Learning , year =. 1602.07576 , archiveprefix=
-
[73]
Advances in Neural Information Processing Systems , year =
Deep Sets , author =. Advances in Neural Information Processing Systems , year =. 1703.06114 , archiveprefix=
-
[74]
Journal of High Energy Physics , year =
Energy Flow Networks: Deep Sets for Particle Jets , author =. Journal of High Energy Physics , year =. doi:10.1007/JHEP01(2019)121 , eprint =
-
[75]
ParticleNet: Jet Tagging via Particle Clouds , author =. Physical Review D , year =. doi:10.1103/PhysRevD.101.056019 , eprint =
-
[76]
Gaussian Processes for Machine Learning , author =
-
[77]
Active Learning Literature Survey , author =
-
[78]
Advances in Neural Information Processing Systems , year =
Learning both Weights and Connections for Efficient Neural Network , author =. Advances in Neural Information Processing Systems , year =. 1506.02626 , archiveprefix=
-
[79]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =. 1712.05877 , archiveprefix=
-
[80]
2015 , eprint =
Distilling the Knowledge in a Neural Network , author =. 2015 , eprint =
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.