Less is More: Lightweight Prompt Compression for Question Answering Applications on Edge Devices
Pith reviewed 2026-07-01 08:46 UTC · model grok-4.3
The pith
CORE compresses retrieval prompts for edge-device question answering using named entity recognition and semantic matching, without any auxiliary small language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
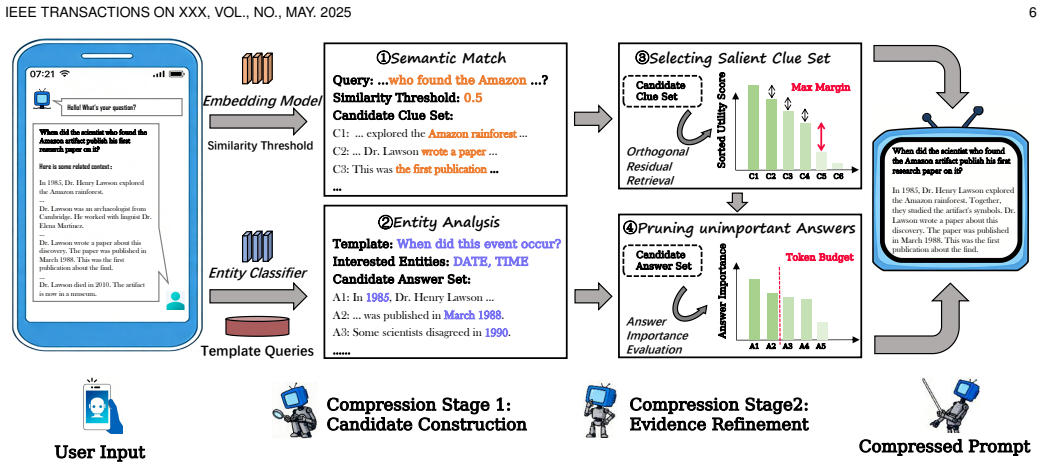
CORE is a two-stage sentence-level prompt compression method that constructs an answer set via named entity recognition and a clue set via semantic matching, refines the clue set using an orthogonal residual retrieval strategy, applies a spatial proximity metric to filter the answer set, and combines the refined sets to form the final compressed context for agent-driven QA.
What carries the argument
Two-stage compression pipeline that builds and merges an NER-derived answer set with a semantically matched clue set after orthogonal residual refinement and spatial proximity filtering.
If this is right
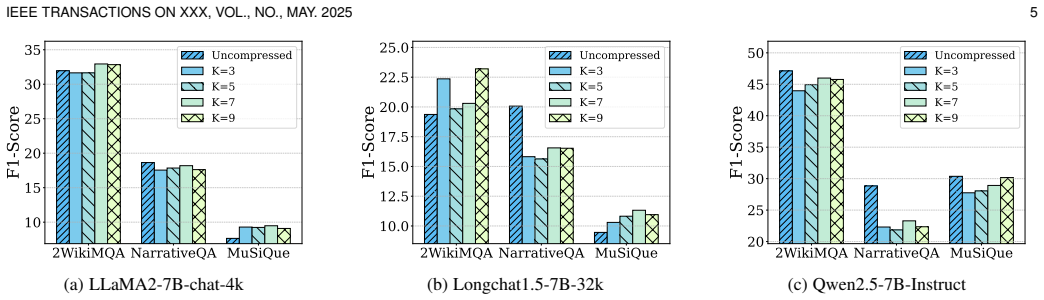
- Accuracy improves by at least 30.19 percent compared with state-of-the-art baselines inside a 2000-token budget.
- Memory usage drops by at least 50.47 percent on the tested edge device.
- Inference runs at least 1.94 times faster on the edge device.
- Energy consumption falls by 95.74 percent relative to LLMLingua2 on the tested smartphone.
Where Pith is reading between the lines
- The same extraction steps could be applied to other retrieval-augmented tasks such as summarization or dialogue on edge hardware.
- Entity-centric and proximity-based filtering may replace learned importance scoring in additional compression settings.
- The method's performance would likely degrade on questions that require long-range inference across many non-entity sentences.
Load-bearing premise
The NER answer set combined with the refined semantic clue set still contains every fact required to answer the question correctly.
What would settle it
Measure accuracy on a QA benchmark containing questions whose correct answers depend on non-entity facts or distant context not captured by semantic matching; if accuracy falls below the baselines, the central claim is false.
Figures


read the original abstract
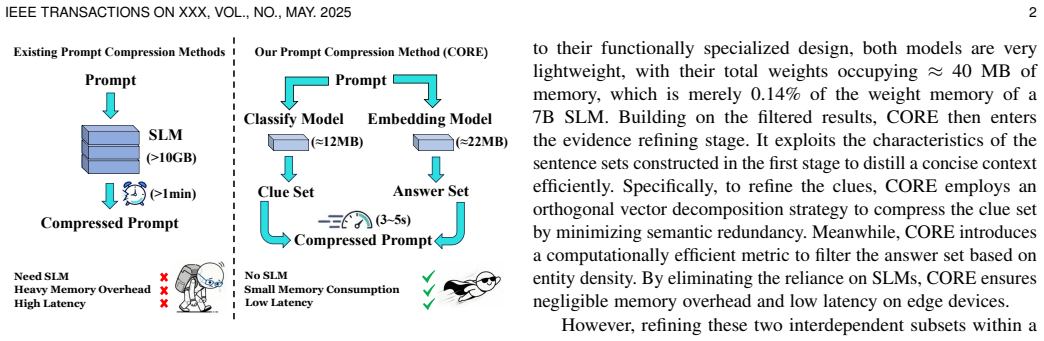
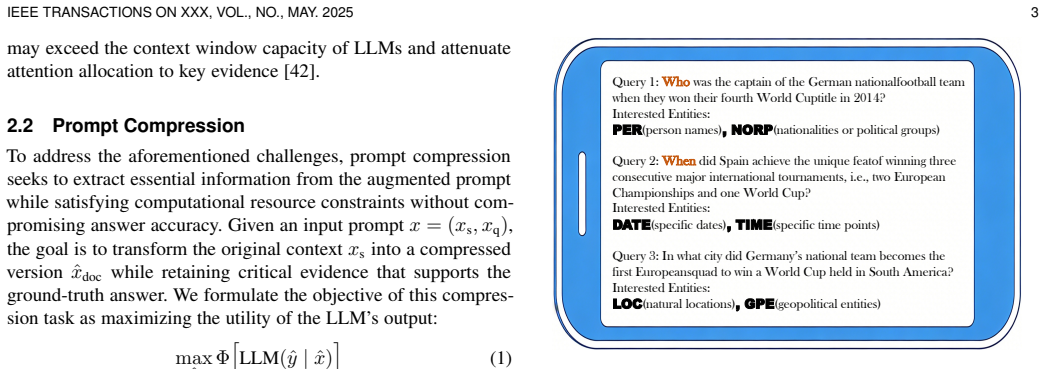
In agent-driven question answering (QA) applications, retrieval-augmented generation (RAG) is commonly introduced to enhance the response accuracy of large language models (LLMs) by providing additional context. Due to the inherent noise in retrieval results and the coarse granularity of document-level retrieval, the retrieved context often contains substantial redundant information. In this setting, the agent prompt, consisting of the user query and the associated retrieved context, leads to unnecessary computational overhead during LLM inference. Existing prompt compression methods typically rely on auxiliary small language models (SLMs) to estimate context importance. However, such approaches introduce significant memory and computational overhead, which limits their deployment on resource-constrained edge devices. In this paper, we propose CORE, a two-stage sentence-level prompt compression method that eliminates the need for SLMs. In the first stage, CORE constructs an answer set via named entity recognition (NER) and a clue set via semantic matching. In the second stage, CORE refines the clue set using an orthogonal residual retrieval strategy and designs a spatial proximity-based metric to filter the answer set. The two sets are then combined to form the final compressed context. We implement CORE on an NVIDIA Jetson AGX Orin edge device and a Huawei Nova smartphone. Experimental results demonstrate that within a 2000-token budget, CORE improves accuracy by at least 30.19% compared to state-of-the-art baselines, while reducing memory usage by at least 50.47% and achieving at least 1.94 times speedup on the edge device. Moreover, compared to the state-of-the-art LLMLingua2 method, CORE achieves a substantial energy reduction of 95.74% on the smartphone, highlighting its practicality and generalizability for mobile deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CORE, a two-stage sentence-level prompt compression method for RAG-based QA on edge devices that avoids auxiliary SLMs. Stage 1 builds an answer set via NER and a clue set via semantic matching; stage 2 refines the clue set with orthogonal residual retrieval and filters the answer set with a spatial-proximity metric before merging the sets into a compressed prompt. The authors claim that, inside a 2000-token budget on an NVIDIA Jetson AGX Orin and a Huawei Nova smartphone, CORE yields at least 30.19 % higher accuracy than SOTA baselines, at least 50.47 % lower memory, 1.94× speedup, and 95.74 % energy reduction versus LLMLingua2.
Significance. If the reported gains are substantiated by complete experimental protocols, the work would be significant for practical deployment of retrieval-augmented agents on resource-constrained hardware. The explicit device-level measurements and the elimination of SLM overhead constitute concrete engineering contributions that could broaden the reach of RAG-based QA.
major comments (2)
- [Abstract] Abstract: the central accuracy claim (≥30.19 % improvement) rests on the untested guarantee that the NER answer set plus semantically matched clue set, after orthogonal residual refinement and spatial-proximity filtering, retains every sentence required for the correct answer. No ablation, coverage statistics, or failure-case analysis is supplied to verify that critical evidence is never dropped.
- [Abstract] Abstract: the quantitative performance numbers are presented without naming the QA datasets, baseline implementations, number of runs, error bars, or statistical tests, rendering the headline claims impossible to evaluate from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract point by point below and will revise the abstract to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central accuracy claim (≥30.19 % improvement) rests on the untested guarantee that the NER answer set plus semantically matched clue set, after orthogonal residual refinement and spatial-proximity filtering, retains every sentence required for the correct answer. No ablation, coverage statistics, or failure-case analysis is supplied to verify that critical evidence is never dropped.
Authors: We agree the abstract does not explicitly demonstrate retention of critical evidence. The method design prioritizes entity capture via NER and relevance via semantic matching, with refinement steps intended to preserve necessary context; the reported accuracy gains across experiments provide indirect support. To strengthen the claim, we will revise the abstract to briefly note the coverage-oriented design and will add explicit coverage statistics plus failure-case analysis to the main text in the revision. revision: yes
-
Referee: [Abstract] Abstract: the quantitative performance numbers are presented without naming the QA datasets, baseline implementations, number of runs, error bars, or statistical tests, rendering the headline claims impossible to evaluate from the given text.
Authors: We acknowledge the abstract omits these specifics. The full manuscript details the QA datasets, baselines, run counts, error bars, and statistical tests. We will revise the abstract to concisely name the primary datasets and note that results are averaged over multiple runs with reported variance. revision: yes
Circularity Check
No circularity: empirical engineering pipeline with no derivations or self-referential reductions
full rationale
The paper describes CORE as a two-stage sentence-level prompt compression method: first constructing an answer set via NER and a clue set via semantic matching, then refining with orthogonal residual retrieval and spatial proximity filtering before combining the sets. No equations, fitted parameters, predictions, or uniqueness theorems are present. Performance numbers (accuracy, memory, speedup, energy) are reported as direct empirical measurements on specific hardware and datasets. The method is a self-contained engineering pipeline with no load-bearing steps that reduce by construction to their own inputs or prior self-citations. This is the expected non-finding for an applied systems paper without mathematical derivation chains.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Named entity recognition reliably extracts answer-relevant entities from retrieved context.
- domain assumption Semantic matching can identify sentences that provide useful clues for the query.
Reference graph
Works this paper leans on
-
[1]
Exploring autonomous agents through the lens of large language models: A review,
S. Barua, “Exploring autonomous agents through the lens of large language models: A review,”CoRR, 2024
2024
-
[2]
Large model based agents: State-of-the-art, cooperation paradigms, security and privacy, and future trends,
Y . Wang, Y . Pan, Z. Su, Y . Deng, Q. Zhao, L. Du, T. H. Luan, J. Kang, and D. Niyato, “Large model based agents: State-of-the-art, cooperation paradigms, security and privacy, and future trends,”IEEE Communications Surveys & Tutorials, 2025
2025
-
[3]
Automated resource scheduling algorithm for lightweight agent in edge computing environment,
Y . Sun, W. Wang, Z. Zhou, and M. Xu, “Automated resource scheduling algorithm for lightweight agent in edge computing environment,” in International Conference on Artificial Intelligence and Communication Technology. Springer, 2025, pp. 193–205
2025
-
[4]
Llm agents for internet of things (iot) applications,
A. Bhat, A. Mondal, and A. Tripathy, “Llm agents for internet of things (iot) applications,” 2025
2025
-
[5]
The rise of autonomous ai agents: Automating complex tasks,
A. Zuo, “The rise of autonomous ai agents: Automating complex tasks,” International Journal of Artificial Intelligence for Science (IJAI4S), vol. 1, no. 2, 2025
2025
-
[6]
Ai agents: The future of autonomous intelligence,
D. V . Virodhula, “Ai agents: The future of autonomous intelligence,” Available at SSRN 5214616, 2025
2025
-
[7]
How do large language models capture the ever-changing world knowledge? a review of recent advances,
Z. Zhang, M. Fang, L. Chen, M. Namazi-Rad, and J. Wang, “How do large language models capture the ever-changing world knowledge? a review of recent advances,” inEMNLP 2023-2023 Conference on Empirical Methods in Natural Language Processing, Proceedings. Association for Computational Linguistics (ACL), 2023, pp. 8289–8311
2023
-
[8]
Dated data: Tracing knowledge cutoffs in large language models,
J. Cheng, M. Marone, O. Weller, D. J. Lawrie, D. Khashabi, and B. Van Durme, “Dated data: Tracing knowledge cutoffs in large language models,”CoRR, 2024
2024
-
[9]
Domain specialization as the key to make large language models disruptive: A comprehensive survey,
C. Ling, X. Zhao, J. Lu, C. Deng, C. Zheng, J. Wang, T. Chowdhury, Y . Li, H. Cui, X. Zhanget al., “Domain specialization as the key to make large language models disruptive: A comprehensive survey,”ACM Computing Surveys, 2023
2023
-
[10]
Injecting domain-specific knowledge into large language models: a comprehensive survey,
Z. Song, B. Yan, Y . Liu, M. Fang, M. Li, R. Yan, and X. Chen, “Injecting domain-specific knowledge into large language models: a comprehensive survey,”arXiv preprint arXiv:2502.10708, 2025
-
[11]
A survey of hallucination in large visual language models,
W. Lan, W. Chen, Q. Chen, S. Pan, H. Zhou, and Y . Pan, “A survey of hallucination in large visual language models,”CoRR, 2024
2024
-
[12]
A comprehensive survey of hallucination mitigation techniques in large language models,
S. T. I. Tonmoy, S. M. Zaman, V . Jain, A. Rani, V . Rawte, A. Chadha, and A. Das, “A comprehensive survey of hallucination mitigation techniques in large language models,”CoRR, 2024
2024
-
[13]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qinet al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–55, 2025
2025
-
[14]
Evaluation of retrieval-augmented generation: A survey,
H. Yu, A. Gan, K. Zhang, S. Tong, Q. Liu, and Z. Liu, “Evaluation of retrieval-augmented generation: A survey,” inCCF Conference on Big Data. Springer, 2024, pp. 102–120
2024
-
[15]
Retrieval-Augmented Generation for AI-Generated Content: A Survey
P. Zhao, H. Zhang, Q. Yu, Z. Wang, Y . Geng, F. Fu, L. Yang, W. Zhang, J. Jiang, and B. Cui, “Retrieval-augmented generation for ai-generated content: A survey,”arXiv preprint arXiv:2402.19473, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
L. Zhang, K. Jijo, S. Setty, E. Chung, F. Javid, N. Vidra, and T. Clifford, “Enhancing large language model performance to answer questions and extract information more accurately,”arXiv preprint arXiv:2402.01722, 2024
-
[17]
Advancing generative ai with rag: Enhancing relevance, creativity, and reliability in language models,
R. Mohammad, “Advancing generative ai with rag: Enhancing relevance, creativity, and reliability in language models,”International Journal of Computer Engineering and Technology (IJCET), vol. 15, no. 4, pp. 321– 329, 2024
2024
-
[18]
Long-context llms meet rag: Overcoming challenges for long inputs in rag,
B. Jin, J. Yoon, J. Han, and S. O. Arik, “Long-context llms meet rag: Overcoming challenges for long inputs in rag,” inThe Thirteenth International Conference on Learning Representations
-
[19]
Summary of a haystack: A challenge to long-context llms and rag systems,
P. Laban, A. R. Fabbri, C. Xiong, and C.-S. Wu, “Summary of a haystack: A challenge to long-context llms and rag systems,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 9885–9903
2024
-
[20]
Llmlingua: Com- pressing prompts for accelerated inference of large language models,
H. Jiang, Q. Wu, C.-Y . Lin, Y . Yang, and L. Qiu, “Llmlingua: Com- pressing prompts for accelerated inference of large language models,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 13 358–13 376
2023
-
[21]
Lost in the middle, and in-between: Enhancing language models’ ability to reason over long contexts in multi-hop qa,
G. A. Baker, A. Raut, S. Shaier, L. E. Hunter, and K. von der Wense, “Lost in the middle, and in-between: Enhancing language models’ ability to reason over long contexts in multi-hop qa,”CoRR, 2024
2024
-
[22]
Lost-in-the- middle in long-text generation: Synthetic dataset, evaluation framework, and mitigation,
J. Zhang, R. Zhang, F. Kong, Z. Miao, Y . Ye, and Y . Zheng, “Lost-in-the- middle in long-text generation: Synthetic dataset, evaluation framework, and mitigation,”CoRR, 2025
2025
-
[23]
Long context rag performance of large language models,
Q. Leng, J. Portes, S. Havens, M. Zaharia, and M. Carbin, “Long context rag performance of large language models,” inAdaptive Foundation Models: Evolving AI for Personalized and Efficient Learning
-
[24]
Long context vs. rag: Strategies for processing long documents in llms,
X. Li, Y . Bai, B. Jin, F. Zhu, L. Pan, and Y . Cao, “Long context vs. rag: Strategies for processing long documents in llms,” inProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2025, pp. 4110–4113
2025
-
[25]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Prompt compression with context-aware sentence encoding for fast and improved llm inference,
B. Liskavets, M. Ushakov, S. Roy, M. Klibanov, A. Etemad, and S. K. Luke, “Prompt compression with context-aware sentence encoding for fast and improved llm inference,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 23, 2025, pp. 24 595–24 604
2025
-
[27]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. Chaplot, D. de Las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier et al., “Mistral 7b, arxiv abs/2310.06825 (2023),”URL: https://api. semanticscholar. org/CorpusID, vol. 263830494, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression,
Z. Pan, Q. Wu, H. Jiang, M. Xia, X. Luo, J. Zhang, Q. Lin, V . R ¨uhle, Y . Yang, C.-Y . Linet al., “Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression,” inACL (Findings), 2024
2024
-
[29]
Xlm-r: Evaluating cross-lingual pre-trained models on 100 languages,
A. Conneau, G. Krikor, G. Lample, L. Barrault, C. Williams, and L. Zettlemoyer, “Xlm-r: Evaluating cross-lingual pre-trained models on 100 languages,”arXiv preprint arXiv:2001.08210, 2020
-
[30]
Y . Li, “Unlocking context constraints of llms: Enhancing context efficiency of llms with self-information-based content filtering,”arXiv preprint arXiv:2304.12102, 2023
-
[31]
A mathematical theory of communication,
C. E. Shannon, “A mathematical theory of communication,”The Bell system technical journal, vol. 27, no. 3, pp. 379–423, 1948
1948
-
[32]
Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression,
H. Jiang, Q. Wu, X. Luo, D. Li, C.-Y . Lin, Y . Yang, and L. Qiu, “Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 1658–1677
2024
-
[33]
Efficient prompt compression with evaluator heads for long-context transformer inference,
W. Fei, X. Niu, G. Xie, Y . Liu, B. Bai, and W. Han, “Efficient prompt compression with evaluator heads for long-context transformer inference,” arXiv preprint arXiv:2501.12959, 2025
-
[34]
Llama-3.1-foundationAI-securityLLM- base-8b technical report.arXiv preprint arXiv:2504.21039,
P. Kassianik, B. Saglam, A. Chen, B. Nelson, A. Vellore, M. Aufiero, F. Burch, D. Kedia, A. Zohary, S. Weerawardhenaet al., “Llama- 3.1-foundationai-securityllm-base-8b technical report,”arXiv preprint arXiv:2504.21039, 2025
-
[35]
Nvidia jetson orin nx series data sheet,
NVIDIA Corporation, “Nvidia jetson orin nx series data sheet,” https: //developer.nvidia.com/downloads/jetson-orin-nx-series-data-sheet, 2022, describes Jetson Orin NX 8 GB and 16 GB LPDDR5 edge/automotive modules
2022
-
[36]
Edge-llm: Enabling efficient large language model adaptation on edge devices via layerwise unified compression and adaptive layer tuning & voting,
H. You, Y . Sun, H.-J. Kuan, J. Lin, Y . Wang, B. Chen, R. Baraniuk, and Y . Zhang, “Edge-llm: Enabling efficient large language model adaptation on edge devices via layerwise unified compression and adaptive layer tuning & voting,” inProceedings of the 61st ACM/IEEE Design Automation Conference (DAC), 2024, pp. 1–6
2024
-
[37]
Edgellm: Fast on-device llm inference with speculative decoding,
D. Xu, W. Yin, H. Zhang, X. Jin, Y . Zhang, S. Wei, M. Xu, and X. Liu, “Edgellm: Fast on-device llm inference with speculative decoding,”IEEE Transactions on Mobile Computing, vol. 24, no. 1, pp. 1–18, 2025
2025
-
[38]
Flexgen: High-throughput generative inference of large language models with a single gpu,
Y . Sheng, L. Zheng, B. Yuan, Z. Li, M. Ryabinin, B. Chen, P. Liang, C. R ´e, I. Stoica, and C. Zhang, “Flexgen: High-throughput generative inference of large language models with a single gpu,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 31 094–31 116
2023
-
[39]
Empowering 1000 tokens/second on-device LLM prefilling with mllm- NPU,
D. Xu, H. Zhang, L. Yang, R. Liu, G. Huang, M. Xu, and X. Liu, “Empowering 1000 tokens/second on-device LLM prefilling with mllm- NPU,”arXiv preprint arXiv:2407.05858, 2024
-
[40]
Message understanding conference-6: A brief history,
R. Grishman and B. M. Sundheim, “Message understanding conference-6: A brief history,” inCOLING 1996 volume 1: The 16th international conference on computational linguistics, 1996
1996
-
[41]
Making retrieval-augmented language models robust to irrelevant context,
O. Yoran, T. Wolfson, O. Ram, and J. Berant, “Making retrieval-augmented language models robust to irrelevant context,” inProceedings of the Twelfth International Conference on Learning Representations (ICLR),
-
[42]
Available: https://openreview.net/forum?id=ZS4m74kZpH
[Online]. Available: https://openreview.net/forum?id=ZS4m74kZpH
-
[43]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,”Transactions of the Association for Computational Linguistics (TACL), vol. 12, pp. 157–173, 2024. [Online]. Available: https://aclanthology.org/2024.tacl-1.9/
2024
-
[44]
Neural question generation using interrogative phrases,
Y . Sasazawa, S. Takase, and N. Okazaki, “Neural question generation using interrogative phrases,” inProceedings of the 12th international conference on natural language generation, 2019, pp. 106–111
2019
-
[45]
Industrial-strength natural language processing in python,
SpaCy, “Industrial-strength natural language processing in python,” 2015
2015
-
[46]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained IEEE TRANSACTIONS ON XXX, VOL., NO., MAY . 2025 14 transformers,
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou, “Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained IEEE TRANSACTIONS ON XXX, VOL., NO., MAY . 2025 14 transformers,”Advances in neural information processing systems, vol. 33, pp. 5776–5788, 2020
2025
-
[47]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019, pp. 3982– 3992
2019
-
[48]
Longbench: A bilingual, multitask benchmark for long context understanding,
Y . Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Houet al., “Longbench: A bilingual, multitask benchmark for long context understanding,” inACL (1), 2024
2024
-
[49]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Weiet al., “Qwen2. 5 technical report,”arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
The NarrativeQA reading comprehension challenge,
T. Koˇcisk´y, J. Schwarz, P. Blunsom, C. Dyer, K. M. Hermann, G. Melis, and E. Grefenstette, “The NarrativeQA reading comprehension challenge,” Transactions of the Association for Computational Linguistics, vol. 6, pp. 317–328, 2018. [Online]. Available: https://aclanthology.org/Q18-1023
2018
-
[51]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,
S. Sugawara, X. Ho, A.-K. D. Nguyen, and A. Aizawa, “Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,” inProceedings of the 28th International Conference on Computational Linguistics. International Committee on Computational Linguistics, 2020
2020
-
[52]
Hierarchical pattern-based complex query of temporal knowledge graph,
L. Zhu, H. Zhang, and L. Bai, “Hierarchical pattern-based complex query of temporal knowledge graph,”Knowledge-Based Systems, vol. 284, p. 111301, 2024. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S0950705123010493
2024
-
[53]
Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition,
Y . C. Pati, R. Rezaiifar, and P. S. Krishnaprasad, “Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition,” inProceedings of the 27th Asilomar Conference on Signals, Systems and Computers. IEEE, 1993, pp. 40–44
1993
-
[54]
Ebk-means: A clustering technique based on elbow method and k-means in wsn,
P. Bholowalia and A. Kumar, “Ebk-means: A clustering technique based on elbow method and k-means in wsn,”International Journal of Computer Applications, vol. 105, no. 9, 2014
2014
-
[55]
Textrank: Bringing order into texts,
R. Mihalcea and P. Tarau, “Textrank: Bringing order into texts,” in Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2004, pp. 404–411
2004
-
[56]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,” inAdvances in neural information processing systems, 2019, pp. 8026–8037
2019
-
[57]
Transformers: State-of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowiczet al., “Transformers: State-of-the-art natural language processing,” inProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, 2020, pp. 38–45
2020
-
[58]
vllm: An efficient inference engine for large language models,
W. Kwon, “vllm: An efficient inference engine for large language models,” Ph.D. dissertation, UC Berkeley, 2025
2025
-
[59]
Docker: lightweight linux containers for consistent development and deployment,
D. Merkelet al., “Docker: lightweight linux containers for consistent development and deployment,”Linux j, vol. 239, no. 2, p. 2, 2014
2014
-
[60]
Musique: Multihop questions via single-hop question composition,
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Musique: Multihop questions via single-hop question composition,”Transactions of the Association for Computational Linguistics, vol. 10, pp. 539–554, 2022
2022
-
[61]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning, “Hotpotqa: A dataset for diverse, explainable multi-hop question answering,”arXiv preprint arXiv:1809.09600, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[62]
A dataset of information-seeking questions and answers anchored in research papers,
P. Dasigi, K. Lo, I. Beltagy, A. Cohan, N. A. Smith, and M. Gardner, “A dataset of information-seeking questions and answers anchored in research papers,”arXiv preprint arXiv:2105.03011, 2021
-
[63]
Natural questions: a benchmark for question answering research,
T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Leeet al., “Natural questions: a benchmark for question answering research,”Transactions of the Association for Computational Linguistics, vol. 7, pp. 453–466, 2019
2019
-
[64]
Beautiful soup documentation,
L. Richardson, “Beautiful soup documentation,” https://www.crummy. com/software/BeautifulSoup/, 2024, python library version 4.12.3
2024
-
[65]
How long can context length of open-source llms truly promise?
D. Li, R. Shao, A. Xie, Y . Sheng, L. Zheng, J. Gonzalez, I. Stoica, X. Ma, and H. Zhang, “How long can context length of open-source llms truly promise?” inNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023
2023
-
[66]
Chatgpt: Jack of all trades, master of none,
J. Koco´n, I. Cichecki, O. Kaszyca, M. Kochanek, D. Szydło, J. Baran, J. Bielaniewicz, M. Gruza, A. Janz, K. Kanclerzet al., “Chatgpt: Jack of all trades, master of none,”Information Fusion, vol. 99, p. 101861, 2023
2023
-
[67]
A review on large language models: Architectures, applications, taxonomies, open issues and challenges,
M. A. K. Raiaan, M. S. H. Mukta, K. Fatema, N. M. Fahad, S. Sakib, M. M. J. Mim, J. Ahmad, M. E. Ali, and S. Azam, “A review on large language models: Architectures, applications, taxonomies, open issues and challenges,”IEEE access, vol. 12, pp. 26 839–26 874, 2024
2024
-
[68]
A comprehensive survey on long context language modeling.arXiv preprint arXiv:2503.17407, 2025
J. Liu, D. Zhu, Z. Bai, Y . He, H. Liao, H. Que, Z. Wang, C. Zhang, G. Zhang, J. Zhanget al., “A comprehensive survey on long context language modeling,”arXiv preprint arXiv:2503.17407, 2025
-
[69]
Flashattention-3: Fast and accurate attention with asynchrony and low- precision,
J. Shah, G. Bikshandi, Y . Zhang, V . Thakkar, P. Ramani, and T. Dao, “Flashattention-3: Fast and accurate attention with asynchrony and low- precision,”Advances in Neural Information Processing Systems, vol. 37, pp. 68 658–68 685, 2024
2024
-
[70]
Spargeattn: Accurate sparse attention accelerating any model inference,
J. Zhang, C. Xiang, H. Huang, J. Wei, H. Xi, J. Zhu, and J. Chen, “Spargeattn: Accurate sparse attention accelerating any model inference,” arXiv preprint arXiv:2502.18137, 2025
-
[71]
Extending llms’ context window with 100 samples,
Y . Zhang, J. Li, and P. Liu, “Extending llms’ context window with 100 samples,”arXiv preprint arXiv:2401.07004, 2024
-
[72]
S. Pawar, S. Tonmoy, S. Zaman, V . Jain, A. Chadha, and A. Das, “The what, why, and how of context length extension techniques in large language models–a detailed survey,”arXiv preprint arXiv:2401.07872, 2024
-
[73]
Found in the middle: How language models use long contexts better via plug-and-play positional encoding,
Z. Zhang, R. Chen, S. Liu, Z. Yao, O. Ruwase, B. Chen, X. Wu, Z. Wang et al., “Found in the middle: How language models use long contexts better via plug-and-play positional encoding,”Advances in Neural Information Processing Systems, vol. 37, pp. 60 755–60 775, 2024
2024
-
[74]
Positional encoding in transformer-based time series models: A survey,
H. Irani and V . Metsis, “Positional encoding in transformer-based time series models: A survey,”dynamics, vol. 4, p. 24, 2025
2025
-
[75]
Prompt compression for large language models: A survey.arXiv preprint arXiv:2410.12388,
Z. Li, Y . Liu, Y . Su, and N. Collier, “Prompt compression for large language models: A survey,”arXiv preprint arXiv:2410.12388, 2024
-
[76]
Adapting language models to compress contexts,
A. Chevalier, A. Wettig, A. Ajith, T. Chen, D. Zhang, D. Jordan, Z. Yao, D. Jurafsky, D. Chenet al., “Adapting language models to compress contexts,”arXiv preprint arXiv:2305.14788, 2023
-
[77]
Learning to compress prompts with gist tokens,
J. Mu and J. Andreas, “Learning to compress prompts with gist tokens,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[78]
Leveraging attention to effectively compress prompts for long-context llms,
Y . Zhao, H. Wu, and B. Xu, “Leveraging attention to effectively compress prompts for long-context llms,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 24, 2025, pp. 26 048–26 056
2025
-
[79]
A survey on recent advances in named entity recognition,
I. Keraghel, S. Morbieu, and M. Nadif, “A survey on recent advances in named entity recognition,”arXiv preprint arXiv:2401.10825, 2024
-
[80]
Named entity recognition and relation extraction: State-of-the-art,
Z. Nasar, S. W. Jaffry, and M. K. Malik, “Named entity recognition and relation extraction: State-of-the-art,”ACM Computing Surveys (CSUR), vol. 54, no. 1, pp. 1–39, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.