Beyond Fixed Budgets: Characterizing the Inelasticity and Limitations of Tree-of-Thought Reasoning Strategies
Pith reviewed 2026-06-30 18:36 UTC · model grok-4.3
The pith
Neither fixed exploration nor fixed pruning suffices for Tree-of-Thought reasoning across compute budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
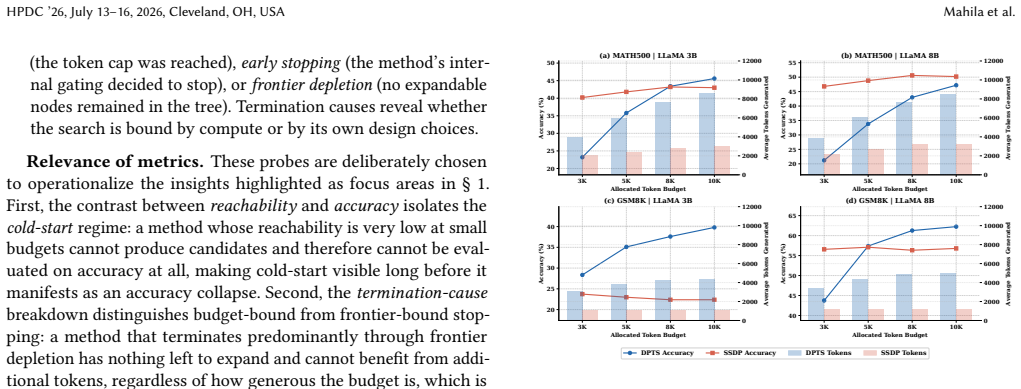
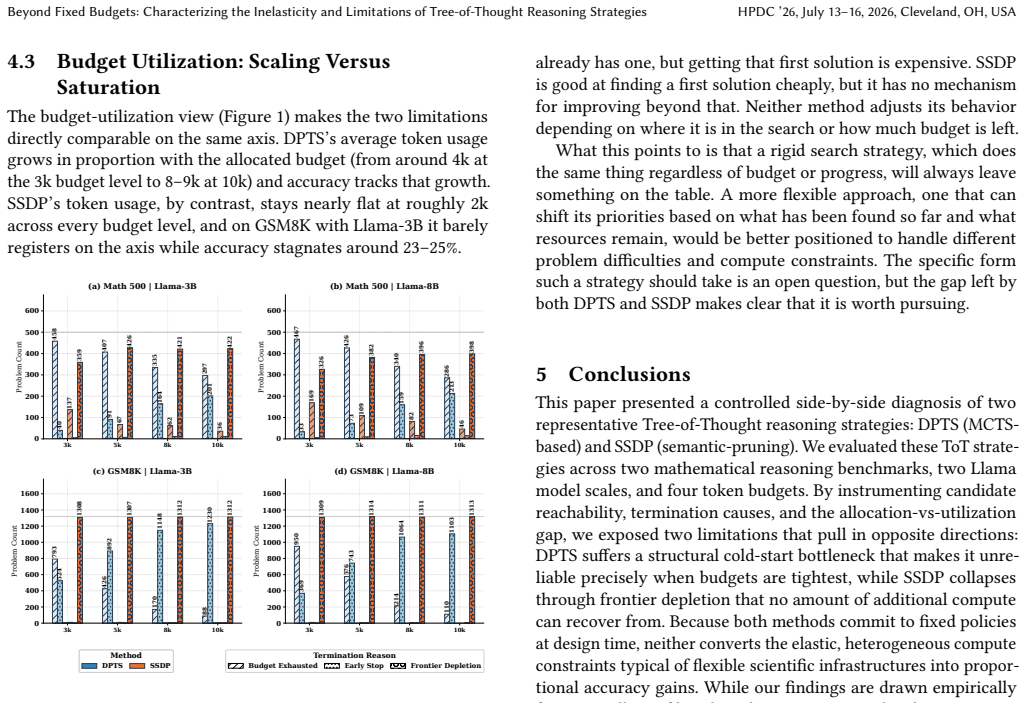
DPTS suffers from a cold-start bottleneck at low budgets: it requires sufficient exploration before its value estimates become reliable, making it a poor fit for resource-constrained settings despite strong scaling behavior at higher budgets. SSDP reaches candidate solutions efficiently but is prone to frontier depletion; its aggressive node merging permanently discards unexplored paths, leaving it unable to improve regardless of how much budget remains. Together, these findings suggest that neither a fixed exploration strategy nor a fixed pruning strategy is sufficient across the compute continuum.
What carries the argument
The opposing limitations of DPTS (Monte Carlo tree search) cold-start bottleneck and SSDP (semantic deduplication) frontier depletion, measured across Math500, GSM8K, Llama-3B/8B, and 3k-10k token budgets.
If this is right
- Search for reasoning must change its exploration or pruning intensity based on current progress and remaining resources.
- Low-budget settings require methods that produce usable estimates without large initial exploration.
- High-budget settings require methods that keep unexplored paths available instead of discarding them early.
- Scientific reasoning agents need dynamic rather than static search control.
Where Pith is reading between the lines
- Similar cold-start and depletion problems may appear in non-mathematical reasoning where path diversity matters.
- An adaptive controller could switch emphasis from exploration to preservation once value estimates stabilize.
- The same trade-off likely affects other search-based LLM methods beyond the two examined here.
Load-bearing premise
Behaviors seen on Math500 and GSM8K with Llama-3B/8B models and 3k-10k token budgets will hold for other reasoning domains, larger models, or different search implementations.
What would settle it
An experiment in which a single fixed strategy matches or exceeds adaptive performance across the full range of tested budgets and models would falsify the claim that adaptation is necessary.
Figures
read the original abstract
Tree of Thought (ToT) search has become a promising direction for improving the reasoning capabilities of large language models, but deploying these methods in practice raises a question that has received little systematic attention: how do different search strategies behave under varying compute budgets, model sizes, and problem difficulties? In this work, we evaluate two representative ToT methods; DPTS, a Monte Carlo tree search based approach, and SSDP, a semantic deduplication based approach, across two mathematical reasoning benchmarks (Math500 and GSM8K), two model scales (Llama-3B and Llama-8B), and four token budgets (3k--10k). Our analysis reveals that the two methods exhibit limitations that pull in opposite directions. DPTS suffers from a cold-start bottleneck at low budgets: it requires sufficient exploration before its value estimates become reliable, making it a poor fit for resource-constrained settings despite strong scaling behavior at higher budgets. SSDP, on the other hand, reaches candidate solutions efficiently but is prone to frontier depletion; its aggressive node merging permanently discards unexplored paths, leaving it unable to improve regardless of how much budget remains. Together, these findings suggest that neither a fixed exploration strategy nor a fixed pruning strategy is sufficient across compute continuum. We argue that effective search for scientific reasoning agents requires strategies that can adapt their behavior based on search progress and available resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates two representative Tree-of-Thought methods—DPTS (Monte Carlo tree search) and SSDP (semantic deduplication)—on Math500 and GSM8K using Llama-3B/8B models across 3k–10k token budgets. It reports that DPTS exhibits a cold-start bottleneck at low budgets while SSDP suffers from frontier depletion due to permanent merging, leading to the claim that neither fixed exploration nor fixed pruning strategies suffice across the compute continuum and that adaptive strategies are required for scientific reasoning agents.
Significance. The controlled experiments across budgets, models, and two distinct methods provide useful empirical characterization of performance differences under resource constraints. If the central generalization holds, the work would usefully motivate adaptive search; however, the limited scope of the tested strategies weakens the load-bearing inference that all fixed strategies are insufficient.
major comments (2)
- [Abstract] Abstract and conclusion sections: the claim that 'neither a fixed exploration strategy nor a fixed pruning strategy is sufficient' rests on DPTS and SSDP being representative; the observed cold-start (DPTS) and depletion (SSDP) failure modes are not shown to be inherent to the fixed-strategy categories rather than artifacts of these specific implementations (MCTS value estimation and permanent semantic merging). No ablation of alternative fixed exploration (e.g., different rollout counts or UCT variants) or milder fixed pruning rules is reported, so the necessity of adaptive behavior does not follow from the data.
- [Experimental setup] Experimental setup (throughout): full methods, exact metrics, statistical details, and implementation choices for budget enforcement and node evaluation are absent, leaving open the possibility of unstated selection effects that affect the inelasticity comparisons between DPTS and SSDP.
minor comments (2)
- Add explicit definitions or pseudocode for how token budgets are allocated and measured in each method.
- Clarify whether the reported performance differences include error bars or significance tests.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, providing clarifications and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract and conclusion sections: the claim that 'neither a fixed exploration strategy nor a fixed pruning strategy is sufficient' rests on DPTS and SSDP being representative; the observed cold-start (DPTS) and depletion (SSDP) failure modes are not shown to be inherent to the fixed-strategy categories rather than artifacts of these specific implementations (MCTS value estimation and permanent semantic merging). No ablation of alternative fixed exploration (e.g., different rollout counts or UCT variants) or milder fixed pruning rules is reported, so the necessity of adaptive behavior does not follow from the data.
Authors: DPTS and SSDP were selected as representative of the two dominant fixed-strategy paradigms in recent ToT work: exploration-centric (MCTS with value estimation) and pruning-centric (aggressive semantic deduplication). The cold-start bottleneck is tied to the sample requirements of Monte Carlo value estimation, while frontier depletion follows directly from irreversible merging; both are structural features of these fixed categories rather than isolated implementation choices. We acknowledge that testing additional variants (e.g., alternative UCT formulations or softer merging thresholds) would provide further support. In revision we will temper the abstract and conclusion to state that the observed inelasticity holds for the tested representative methods and thereby motivates adaptive strategies, while explicitly noting that exhaustive coverage of all fixed variants remains future work. revision: partial
-
Referee: [Experimental setup] Experimental setup (throughout): full methods, exact metrics, statistical details, and implementation choices for budget enforcement and node evaluation are absent, leaving open the possibility of unstated selection effects that affect the inelasticity comparisons between DPTS and SSDP.
Authors: We apologize for insufficient clarity. Section 3 and Appendix A specify: token budgets are enforced by cumulative tokenizer counts; node values are obtained via a fixed LLM prompt for scalar estimation; accuracy is the primary metric with means and standard deviations reported over five random seeds. We will expand the main-text experimental setup subsection to restate these choices explicitly, including pseudocode for budget tracking and value estimation, thereby removing any ambiguity about potential selection effects. revision: yes
Circularity Check
No circularity: purely empirical characterization without derivations or self-referential reductions
full rationale
The paper conducts an empirical study evaluating DPTS (MCTS-based) and SSDP (semantic deduplication) on Math500 and GSM8K with Llama-3B/8B models across token budgets. It reports observed behaviors such as cold-start in DPTS and frontier depletion in SSDP, then concludes that neither fixed exploration nor fixed pruning suffices. No equations, fitted parameters, predictions that reduce to inputs, or load-bearing self-citations appear in the abstract or described content. The central claim follows directly from the experimental observations on the tested methods rather than any definitional or self-referential construction. This matches the default case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Math500 and GSM8K with Llama-3B/8B are representative of broader mathematical reasoning tasks and model behaviors.
Reference graph
Works this paper leans on
-
[1]
Argonne Leadership Computing Facility. 2026. Polaris. https://www.alcf.anl.gov/ polaris. Accessed: May 1, 2026
2026
-
[2]
Moiz Arif, Avinash Maurya, Bogdan Nicolae, and Sudharshan Vazhkudai. 2026. Understanding Inference Scaling for LLMs: Bottlenecks, Trade-offs, and Perfor- mance Principles. InISCA’26: The International Symposium on Computer Architec- ture. IEEE/ACM, Raleigh, NC, USA
2026
-
[3]
Maarten Bosma, Ed Chi, Brian Ichter, Quoc V Le, Dale Schuurmans, et al. 2022. Chain-Of-Thought Prompting Elicits Reasoning in Large Language Models. In NeurIPS: Advances in Neural Information Processing Systems. 24824–24837. doi:10. 52202/068431-1800
2022
-
[4]
Browne, Edward Powley, Daniel Whitehouse, Simon M
Cameron B. Browne, Edward Powley, Daniel Whitehouse, Simon M. Lucas, Peter I. Cowling, et al . 2012. A Survey of Monte Carlo Tree Search Methods.IEEE: Transactions on Computational Intelligence and AI in Games(2012). doi:10.1109/ tciaig.2012.2186810
-
[5]
Weipeng Cao, Jiongjiong Gu, Zhong Ming, Zhiyuan Cai, Yuzhao Wang, et al
-
[6]
Flexible Computing: A New Framework for Improving Resource Allocation and Scheduling in Elastic Computing.IEEE Transactions on Services Computing1 (2025). doi:10.1109/tsc.2024.3489433
-
[8]
Yifu Ding, Wentao Jiang, Shunyu Liu, Yongcheng Jing, Jinyang Guo, et al. 2025. Dynamic parallel tree search for efficient llm reasoning. InACL: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. doi:10. 18653/v1/2025.acl-long.550
2025
-
[9]
John Duchi, Elad Hazan, and Yoram Singer. 2021. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization.JMLR: Journal of Machine Learning Research(2021). http://jmlr.org/papers/v12/duchi11a.html
2021
- [10]
-
[11]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, et al
-
[12]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring Mathematical Problem Solving With the MATH Dataset. In Advances in Neural Information Processing Systems (NeurIPS ’21 Datasets and Benchmarks Track). doi:10.48550/ARXIV.2103.03874
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.03874
-
[13]
Nathan Herr, Tim Rocktäschel, and Roberta Raileanu. 2025. LLM-First Search: Self-Guided Exploration of the Solution Space. doi:10.48550/ARXIV.2506.05213
-
[14]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, et al. 2022. Training compute-optimal large language models. In NeurIPS: The International Conference on Neural Information Processing Systems. doi:10.48550/arXiv.2203.15556
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.15556 2022
-
[15]
Jinhao Jiang, Zhipeng Chen, Yingqian Min, Jie Chen, Xiaoxue Cheng, et al. 2024. Technical Report: Enhancing LLM Reasoning with Reward-guided Tree Search. CoRR(2024). https://doi.org/10.48550/arXiv.2411.11694
-
[16]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, et al. 2020. Scaling Laws for Neural Language Models. doi:10.48550/ARXIV.2001. 08361
-
[17]
Joongho Kim, Xirui Huang, Zarreen Reza, Gabriel Grand, Kevin Zhu, and Ryan Lagasse. 2025. Chopping Trees: Semantic Similarity Based Dynamic Pruning for Tree-of-Thought Reasoning. InNeurIPS 2025 Workshop on Efficient Reasoning. https://openreview.net/forum?id=6xrbjd86dF
2025
- [18]
-
[19]
Qingyao Li, Wei Xia, Xinyi Dai, Kounianhua Du, Weiwen Liu, et al. 2025. Re- thinkmcts: Refining erroneous thoughts in monte carlo tree search for code generation. InEMNLP: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. doi:10.18653/v1/2025.emnlp-main.410
-
[20]
Qingwen Lin, Boyan Xu, Guimin Hu, Zijian Li, Zhifeng Hao, et al. 2025. CMCTS: A Constrained Monte Carlo Tree Search framework for mathematical reasoning in large language model.Applied Intelligence56 (2025). doi:10.1007/s10489-025- 07044-6
-
[21]
Sora Miyamoto, Daisuke Oba, and Naoaki Okazaki. 2026. Aligning Tree-Search Policies with Fixed Token Budgets in Test-Time Scaling of LLMs. doi:10.48550/ ARXIV.2602.09574
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, et al
-
[23]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open Foundation and Fine-Tuned Chat Models. doi:10.48550/ ARXIV.2307.09288
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Ziyu Wan, Xidong Feng, Muning Wen, Stephen Marcus McAleer, Ying Wen, et al. 2024. AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training. InICML: International Conference on Machine Learning. doi:10.48550/arXiv.2309.17179
-
[25]
Ante Wang, Linfeng Song, Ye Tian, Baolin Peng, Dian Yu, et al. 2025. Litesearch: Efficient tree search with dynamic exploration budget for math reasoning. In AAAI: Proceedings of the AAAI Conference on Artificial Intelligence. doi:10.1609/ aaai.v39i24.34719
2025
-
[26]
Ante Wang, Linfeng Song, Ye Tian, Dian Yu, Haitao Mi, Xiangyu Duan, et al
-
[27]
InACL: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics
Don’t get lost in the trees: Streamlining llm reasoning by overcoming tree search exploration pitfalls. InACL: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. doi:10.48550/arXiv.2502.11183
-
[28]
Teng Wang, Wing-Yin Yu, Zhenqi He, Zehua Liu, HaileiGong HaileiGong, et al
-
[29]
InACL: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics
Bpp-search: Enhancing tree of thought reasoning for mathematical mod- eling problem solving. InACL: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. doi:10.48550/arXiv.2411.17404
-
[30]
Xuezhi Wang, Jason Wei, Dale Schuurmans, V Le Quoc, Ed Chi, et al. 2022. Self- consistency improves chain of thought reasoning in language models. InICLR: International Conference on Learning Representations. doi:10.48550/arXiv.2203. 11171
-
[31]
arXiv preprint arXiv:2405.00451 , year=
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, et al. 2024. Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning. doi:10.48550/ARXIV.2405.00451
-
[32]
Guanming Xiong, Haochen Li, and Wen Zhao. 2025. MCTS-KBQA: Monte Carlo Tree Search for Knowledge Base Question Answering. doi:10.48550/ARXIV.2502. 13428
-
[33]
Huanjin Yao, Jiaxing Huang, Wenhao Wu, Jingyi Zhang, Yibo Wang, et al. 2026. Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Col- lective Monte Carlo Tree Search. InNeurIPS: Advances in Neural Information Processing Systems. https://openreview.net/forum?id=lwOV2ACEK9
2026
-
[34]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shih, Liane Levin, et al . 2023. Tree of thoughts: Deliberate problem solving with large language models.NeurIPS: Advances in Neural Information Processing Systems36 (2023). doi:10.48550/arXiv. 2305.10601
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[35]
Jie Ye, Jaime Cernuda, Avinash Maurya, Xian-He Sun, Anthony Kougkas, and Bogdan Nicolae. 2025. Characterizing the Behavior and Impact of KV Caching on Transformer Inferences Under Concurrency. InIPDPS’25: International Parallel and Distributed Processing Symposium. doi:10.1109/IPDPS64566.2025.00108
-
[36]
Chung-Wei Victor Yuan. 2026. ECR: Manifold-Guided Semantic Cues for Compact Language Models. doi:10.48550/arXiv.2601.00543
-
[37]
Marvin Zhang, Henrik Marklund, Nikita Dhawan, Abhishek Gupta, Sergey Levine, and Chelsea Finn. 2021. Adaptive risk minimization: learning to adapt to domain shift. InNeurIPS: The International Conference on Neural Information Processing Systems. doi:10.48550/arXiv.2007.02931
-
[38]
Maciej Świechowski, Konrad Godlewski, Bartosz Sawicki, and Jacek Mańdziuk
-
[39]
Monte Carlo Tree Search: a review of recent modifications and applications. Artificial Intelligence Review56 (2022). doi:10.1007/s10462-022-10228-y
-
[40]
Domagoj Ševerdija, Tomislav Prusina, Antonio Jovanović, Luka Borozan, Jurica Maltar, and Domagoj Matijević. 2023. Compressing Sentence Representation with Maximum Coding Rate Reduction. In46th MIPRO ICT and Electronics Convention. doi:10.23919/MIPRO57284.2023.10159709
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.