Towards CSI-Native Foundation Models: A Channel-Adaptive Roadmap for 6G
Pith reviewed 2026-06-27 04:36 UTC · model grok-4.3
The pith
Aligning foundation model pretraining with physical channel properties enables better CSI generalization and efficiency for 6G.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
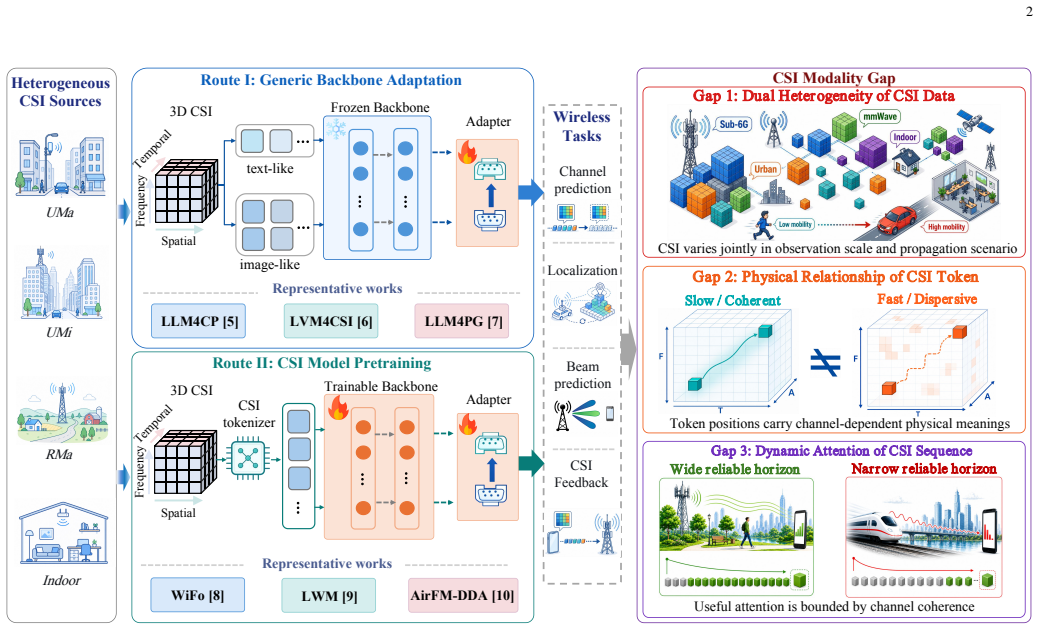
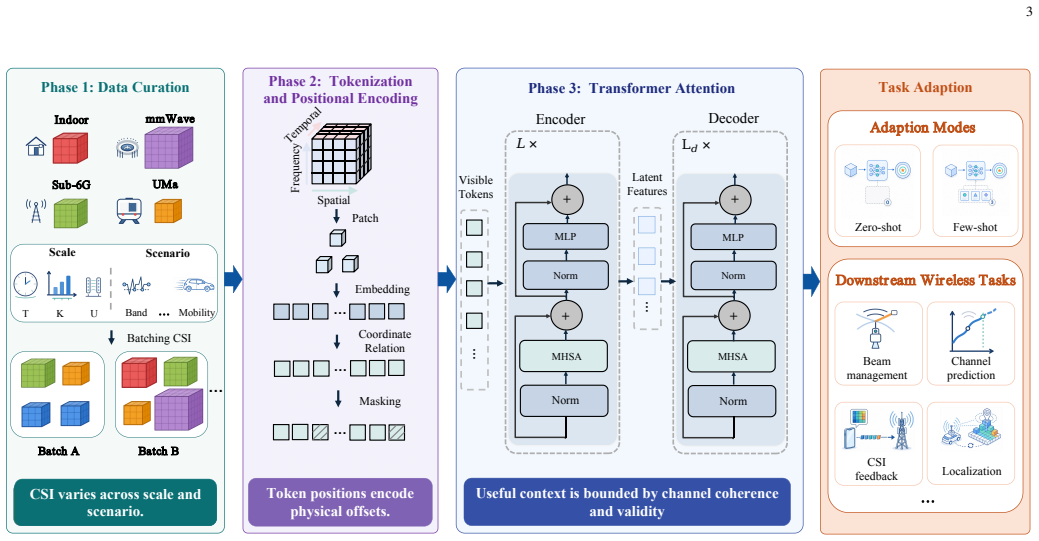
The paper claims that a channel-adaptive roadmap for CSI-native foundation models, achieved by aligning pretraining, positional modeling, and attention control with scale-aware heterogeneous exposure, physical time-frequency-antenna coordinates, and correlation-bounded token interaction, produces superior zero-shot generalization, scale extrapolation, and inference efficiency compared with generic-backbone or non-channel-aware CSI pretraining methods.
What carries the argument
The unified framework that enforces three channel requirements (scale-aware heterogeneous exposure, physical time-frequency-antenna coordinates, and correlation-bounded token interaction) inside pretraining and attention mechanisms.
If this is right
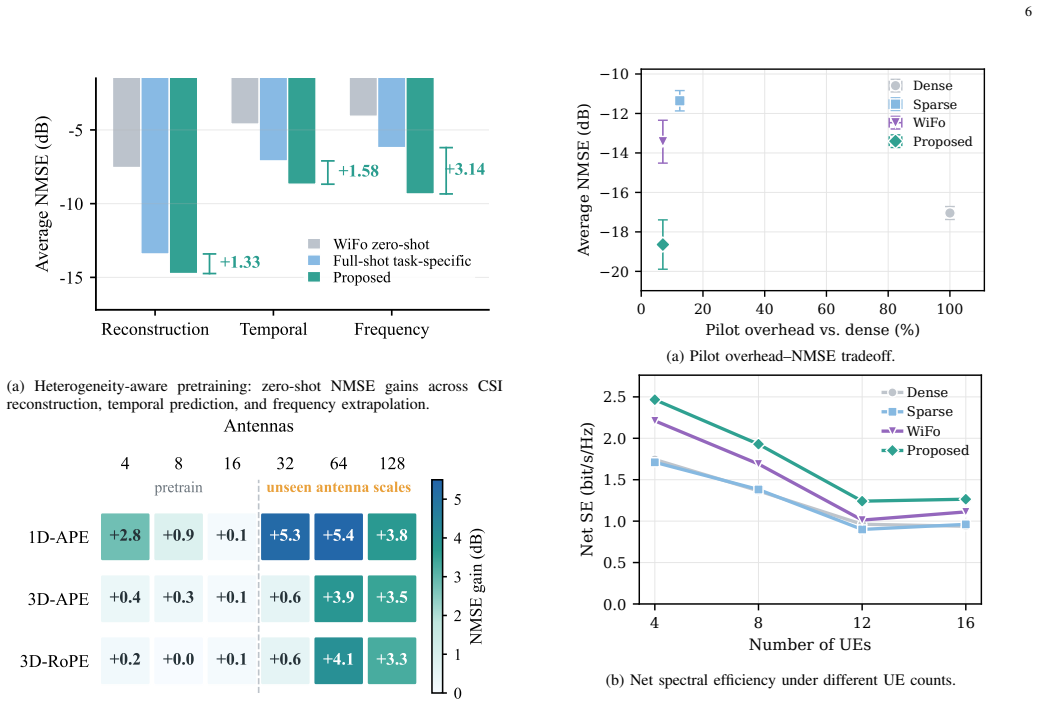
- The framework reduces normalized mean square error by more than 4 dB on spatial-temporal-frequency tasks in zero-shot settings.
- It yields up to 5.4 dB gain when the number of antennas is scaled eight times beyond what was seen during training.
- Mobility-aware processing runs up to 18.8 percent faster.
- In system-level tests it reaches -18.64 dB average NMSE while using only 7.01 percent of dense-pilot overhead and raises net spectral efficiency by 36.6 percent over dense LMMSE.
Where Pith is reading between the lines
- Domain-specific coordinate and correlation constraints may prove more effective than generic positional encodings when foundation models are applied to other physical sensing or control problems.
- If the alignment approach works, future 6G systems could rely on far fewer pilots while still supporting high-mobility users, changing how cell planning and resource allocation are designed.
- The same three-alignment pattern could be tested on non-CSI tasks such as beam prediction or interference management to check whether the benefit is specific to channel estimation or general to wireless data.
Load-bearing premise
The three alignments can be realized in pretraining and attention so that they deliver the reported gains without hidden dataset selection or extra tuning for each new scenario.
What would settle it
A test on a fresh channel dataset or antenna configuration where the framework shows no NMSE reduction or no spectral-efficiency improvement over a standard LMMSE baseline using the same pilot count.
Figures


read the original abstract
Wireless foundation models offer a path toward reusable channel state information (CSI) intelligence for sixth-generation (6G) systems. However, existing generic-backbone adaptation and CSI pretraining methods often treat CSI as task tensors rather than propagation-conditioned channel responses, thereby failing to capture the intrinsic time-frequency-spatial geometry of wireless environments. This paper presents a channel-adaptive roadmap toward CSI-native foundation models, proposing a unified framework that aligns pretraining, positional modeling, and attention control with three channel requirements: scale-aware heterogeneous exposure, physical time-frequency-antenna coordinates, and correlation-bounded token interaction. Extensive experiments demonstrate the superiority of the proposed framework across three dimensions: zero-shot generalization, reducing NMSE by more than 4 dB across spatial-temporal-frequency tasks; scale extrapolation, yielding up to a 5.4 dB gain under 8 times unseen antenna scaling; and inference efficiency, accelerating mobility-aware processing by up to 18.8%. A system-level evaluation with Sionna SYS further shows that the proposed framework uses only 7.01% of dense-pilot overhead, reaches -18.64 dB average NMSE, and improves average net spectral efficiency by 36.6% over dense LMMSE and 15.5% over WiFo, indicating that CSI-native representation learning can support pilot-efficient radio access.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a channel-adaptive framework for CSI-native foundation models in 6G that aligns pretraining, positional modeling, and attention with three requirements (scale-aware heterogeneous exposure, physical time-frequency-antenna coordinates, and correlation-bounded token interaction). It reports empirical results showing >4 dB NMSE reduction in zero-shot generalization across spatial-temporal-frequency tasks, up to 5.4 dB gain under 8x unseen antenna scaling, up to 18.8% acceleration in mobility-aware processing, and system-level Sionna SYS results with 7.01% of dense-pilot overhead achieving -18.64 dB average NMSE and 36.6% net spectral efficiency improvement over dense LMMSE (15.5% over WiFo).
Significance. If the claimed gains and attributions hold under controlled evaluation, the work would be significant for the field by offering a principled route to embed wireless propagation geometry into foundation-model design, potentially enabling reusable, pilot-efficient CSI intelligence for 6G rather than generic backbone adaptation.
major comments (1)
- [Abstract] Abstract: the central claims consist of specific numerical performance gains (NMSE reductions, scale-extrapolation dB values, efficiency percentages, and Sionna SYS metrics) with no accompanying methodological details on architecture realizations, training procedures, baseline definitions, datasets, or controls for selection effects; this absence makes the support for the claims impossible to assess and is load-bearing for the paper's empirical contribution.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for clear support of the empirical claims. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims consist of specific numerical performance gains (NMSE reductions, scale-extrapolation dB values, efficiency percentages, and Sionna SYS metrics) with no accompanying methodological details on architecture realizations, training procedures, baseline definitions, datasets, or controls for selection effects; this absence makes the support for the claims impossible to assess and is load-bearing for the paper's empirical contribution.
Authors: The abstract is a concise summary of contributions and headline results, as is conventional. Full methodological details—including the channel-adaptive pretraining objective, scale-aware positional encoding with physical (t,f,a) coordinates, correlation-bounded attention mask, training datasets and splits, baseline implementations (dense LMMSE, WiFo), and controls for selection bias—are provided in Sections 3 (Framework), 4 (Experimental Setup and Datasets), and 5 (Results). The abstract does not repeat these sections; readers are expected to consult the body for reproducibility. If the referee finds any specific detail still missing from the body, we will gladly expand it. revision: no
Circularity Check
No significant circularity identified
full rationale
The paper advances a unified framework for CSI-native foundation models by aligning pretraining, positional modeling, and attention with three channel requirements, then validates it solely via empirical results on NMSE, scale extrapolation, inference speed, and system-level spectral efficiency. No equations, closed-form predictions, fitted parameters renamed as forecasts, or load-bearing self-citations appear in the abstract or claim structure. All performance numbers are reported as experimental outcomes from controlled comparisons, leaving the derivation chain self-contained and independent of its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
6G AI-driven air interface—Hexa-X-II view,
H. Farhadi, B. Banerjee, R. Berkvenset al., “6G AI-driven air interface—Hexa-X-II view,”IEEE Communications Magazine, vol. 63, no. 10, pp. 118–125, Oct. 2025
2025
-
[2]
Overview of AI and communication for 6G network: Fundamentals, challenges, and future research opportu- nities,
Q. Cui, X. You, N. Weiet al., “Overview of AI and communication for 6G network: Fundamentals, challenges, and future research opportu- nities,”Science China Information Sciences, vol. 68, no. 7, p. 171301, 2025
2025
-
[3]
Large language models in 6G from standard to on-device networks,
H. Zou, Q. Zhao, S. Lasaulceet al., “Large language models in 6G from standard to on-device networks,”Nature Reviews Electrical Engineering, vol. 3, pp. 123–134, 2026
2026
-
[4]
Applying AI to CSI for high efficiency wireless communication,
Y . Li, Y . Hu, K. Minet al., “Applying AI to CSI for high efficiency wireless communication,”IEEE Wireless Communications, vol. 30, no. 1, pp. 104–110, 2023
2023
-
[5]
LLM4CP: Adapting large language models for channel prediction,
B. Liu, X. Liu, S. Gaoet al., “LLM4CP: Adapting large language models for channel prediction,”Journal of Communications and Information Networks, vol. 9, no. 2, pp. 113–125, 2024
2024
-
[6]
J. Guo, P. Jiang, C.-K. Wenet al., “LVM4CSI: Enabling direct applica- tion of pre-trained large vision models for wireless channel tasks,”arXiv preprint arXiv:2507.05121, 2025
arXiv 2025
-
[7]
LLM4PG: Adapting large language model for pathloss map generation via synesthesia of machines,
M. Sun, L. Bai, X. Chenget al., “LLM4PG: Adapting large language model for pathloss map generation via synesthesia of machines,”arXiv preprint arXiv:2511.02423, 2025
arXiv 2025
-
[8]
WiFo: Wireless foundation model for channel prediction,
B. Liu, S. Gao, X. Liuet al., “WiFo: Wireless foundation model for channel prediction,”Science China Information Sciences, vol. 68, no. 6, p. 162302, 2025
2025
-
[9]
Large wireless model (LWM): A foundation model for wireless channels,
S. Alikhani, G. Charan, and A. Alkhateeb, “Large wireless model (LWM): A foundation model for wireless channels,”arXiv preprint arXiv:2411.08872, 2024
arXiv 2024
-
[10]
AirFM-DDA: Air-Interface Foundation Model in the Delay-Doppler-Angle Domain for AI-Native 6G,
K. Bian, M. Tao, J. Moet al., “AirFM-DDA: Air-Interface Foundation Model in the Delay-Doppler-Angle Domain for AI-Native 6G,”arXiv preprint arXiv:2605.00020, 2026
Pith/arXiv arXiv 2026
-
[11]
Scalable pre-trained masked channel model of wireless communications,
J. Guo, Z. Deng, Z. Qiaoet al., “Scalable pre-trained masked channel model of wireless communications,”IEEE Transactions on Communi- cations, vol. 74, pp. 6197–6212, 2026
2026
-
[12]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmaret al., “Attention is all you need,” inProc. Advances in Neural Information Processing Systems, 2017
2017
-
[13]
WiFo-2: A generalist foundation model unifies heterogeneous wireless system design,
B. Liu, X. Liu, S. Gaoet al., “WiFo-2: A generalist foundation model unifies heterogeneous wireless system design,”arXiv preprint arXiv:2511.22222, 2025
Pith/arXiv arXiv 2025
-
[14]
C. Zhang, X. Lyu, C. Renet al., “HeterCSI: Channel-adaptive hetero- geneous CSI pretraining framework for generalized wireless foundation models,”arXiv preprint arXiv:2601.18200, 2026
arXiv 2026
-
[15]
Adaptive 3D-RoPE: Physics-aligned ro- tary positional encoding for wireless foundation models,
C. Zhang, X. Lyu, C. Renet al., “Adaptive 3D-RoPE: Physics-aligned ro- tary positional encoding for wireless foundation models,”arXiv preprint arXiv:2605.00968, 2026
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.