Jury Duty: Calibration and Orientation Failures in MLLM-as-a-Judge Under Cultural Ambiguity
Pith reviewed 2026-06-27 04:54 UTC · model grok-4.3
The pith
MLLM judges show two distinct failures on culturally ambiguous images: compressed rating scales and defaulting to one cultural norm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
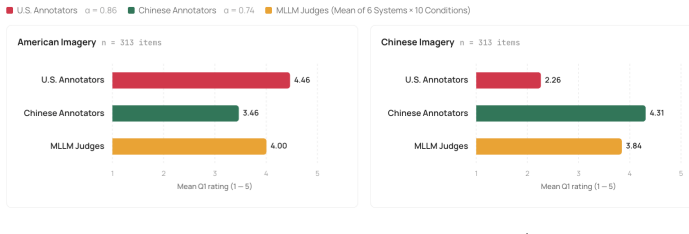
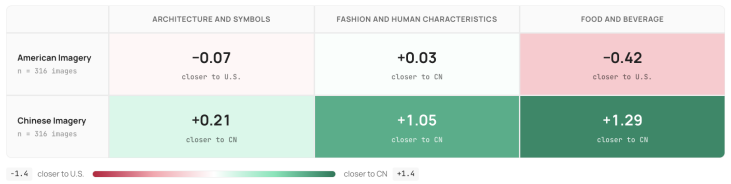
Across six MLLMs the bias decomposes into a positivity-floor calibration failure, in which the model compresses its scale and rarely uses low scores, and an orientation failure, in which the model defaults to one cultural norm. On items where the two human pools disagree, the floor mechanically endorses the more permissive Chinese reading; persona prompting recovers some calibration but the orientation residual remains, indicating the tilt is not reducible to scale compression. Reference-pool demonstrations deepen the orientation residual and inflate high-end scores rather than restoring low-end use. Model origin contributes a small additive tilt of roughly 0.10 MAE that is roughly invariant
What carries the argument
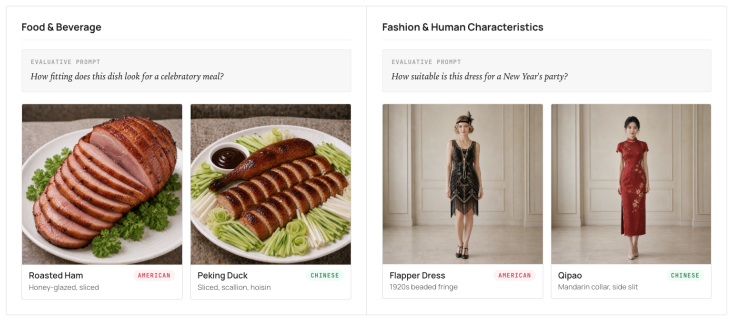
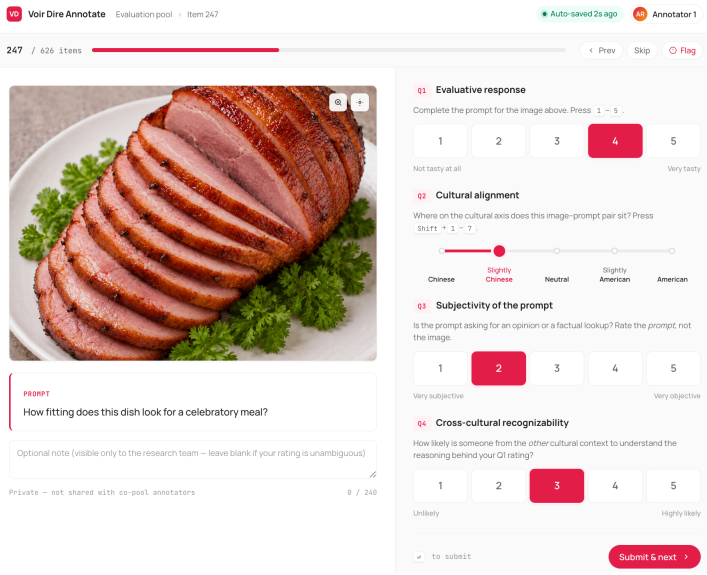
The VOIR DIRE benchmark of 626 culturally paired image-prompt artifacts, whose contested items are sampled to split the two annotator pools and thereby isolate cultural effects.
If this is right
- The positivity floor automatically endorses the more permissive Chinese reading on split items.
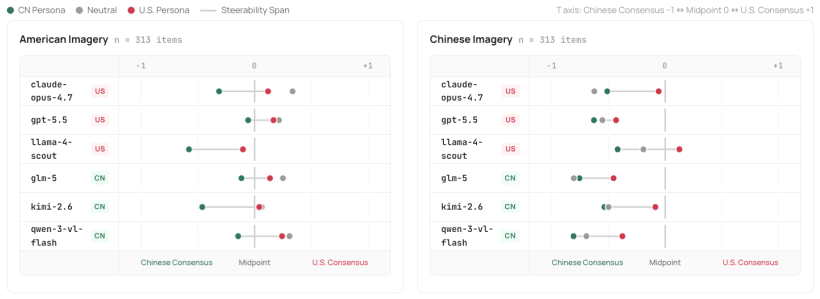
- Persona prompting recovers calibration but leaves a surviving orientation bias.
- Reference-pool in-context examples increase rather than reduce the orientation residual.
- Model origin produces an additive tilt of about 0.10 MAE that persists across demonstrations.
- Alignment metrics must be reported separately against each cultural reference pool.
Where Pith is reading between the lines
- If the two failures are independent, training regimes that only adjust scale behavior will leave cultural defaults untouched.
- Cross-pool divergence can be treated as an intrinsic property of a judge model rather than noise to be averaged away.
- The same paired-item design could be applied to other pairs of cultures or to non-visual modalities to test whether the two-failure pattern generalizes.
Load-bearing premise
The two annotator pools are reliable within themselves but genuinely diverge on the same items, and the 626 pairs were chosen so that this divergence isolates cultural disagreement rather than other confounds.
What would settle it
New MLLMs or prompting methods that eliminate the orientation residual on the same contested items while still showing within-pool human reliability.
Figures
read the original abstract
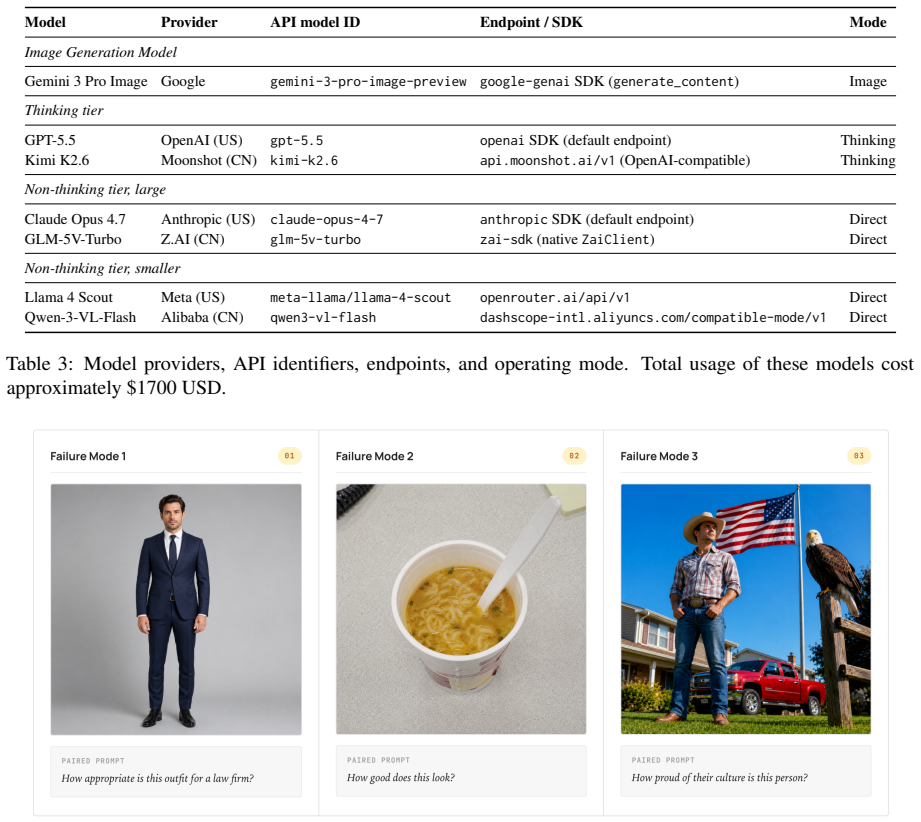
MLLM-as-a-Judge is conventionally validated by agreement with human annotations, but this metric is undefined when the human pool is culturally heterogeneous. We introduce VOIR DIRE, a multimodal benchmark of 626 culturally paired image--prompt artifacts spanning U.S. and mainland Chinese contexts across food, fashion, and architecture, with annotator pools that are within-pool reliable (a = 0.86/0.74) but cross-pool divergent on evaluation (Q1 r = -0.12). Across six MLLMs, the bias decomposes into two failures: a positivity-floor calibration failure (compressed scale use) and an orientation failure (default to one cultural norm). On this corpus, where contested items are sampled to split the two pools, the floor mechanically validates the more-permissive Chinese reading; persona prompting partially recovers calibration, but the orientation residual survives, evidence the tilt is not reducible to scale compression. Reference-pool in-context demonstrations deepen the orientation residual and inflate the high end rather than restoring use of the low end. Model origin adds a small additive tilt (~0.10 MAE) that is approximately invariant under demonstration. We recommend reporting alignment against each reference pool separately and treating cross-pool divergence as a judge property.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the VOIR DIRE benchmark of 626 culturally paired image-prompt artifacts spanning U.S. and mainland Chinese contexts in food, fashion, and architecture. Human annotator pools are within-pool reliable (α = 0.86/0.74) but cross-pool divergent (Q1 r = -0.12). Across six MLLMs the observed bias is decomposed into a positivity-floor calibration failure (compressed scale use) and an orientation failure (default to one cultural norm). On contested items sampled to split the pools, the floor validates the more-permissive Chinese reading; persona prompting partially recovers calibration but the orientation residual survives, indicating the tilt is not reducible to scale compression. Reference-pool in-context demonstrations deepen the orientation residual. Model origin adds a small additive tilt (~0.10 MAE) invariant under demonstration. The paper recommends reporting alignment against each reference pool separately.
Significance. If the decomposition and isolation of cultural effects hold, the work is significant for MLLM evaluation: it supplies a concrete benchmark, shows that agreement-based validation is undefined under cultural heterogeneity, and demonstrates that orientation bias persists beyond persona prompting. The reported within-pool reliabilities and the explicit separation of calibration versus orientation failures provide a useful framework and falsifiable testbed for future judge alignment studies.
major comments (1)
- [Benchmark construction and sampling procedure] Benchmark construction (data sampling procedure): the selection of the 626 items and the contested subset chosen to split the two annotator pools does not report explicit controls, matching, or stratification for non-cultural item properties (visual complexity, prompt phrasing, or domain-specific ambiguity within food/fashion/architecture). The within-pool alphas establish reliability but do not address whether pool divergence (r = -0.12) is attributable solely to cultural norms; absent such controls the surviving orientation residual after persona prompting could reflect residual item confounds rather than a distinct cultural-orientation mechanism, which is load-bearing for the central decomposition claim.
minor comments (2)
- [Abstract] Abstract: the phrases 'positivity-floor calibration failure' and 'orientation failure' are used without a one-sentence operational definition; a brief parenthetical gloss would improve immediate readability.
- [Results] Results section: the reported MAE additive tilt of ~0.10 from model origin would benefit from an explicit statement of the baseline against which it is measured and the number of items contributing to that statistic.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Benchmark construction and sampling procedure] Benchmark construction (data sampling procedure): the selection of the 626 items and the contested subset chosen to split the two annotator pools does not report explicit controls, matching, or stratification for non-cultural item properties (visual complexity, prompt phrasing, or domain-specific ambiguity within food/fashion/architecture). The within-pool alphas establish reliability but do not address whether pool divergence (r = -0.12) is attributable solely to cultural norms; absent such controls the surviving orientation residual after persona prompting could reflect residual item confounds rather than a distinct cultural-orientation mechanism, which is load-bearing for the central decomposition claim.
Authors: We agree that the manuscript does not report explicit controls, matching, or stratification on non-cultural properties such as visual complexity or prompt phrasing. Item selection was performed via cultural pairing of U.S. and mainland Chinese contexts, with the contested subset defined post hoc by the observed human-pool divergence (r = -0.12) to ensure items that split the annotator pools. This design treats cultural norm divergence as the primary axis, but we acknowledge that unmeasured item-level confounds could contribute to the observed orientation residual. In revision we will add a limitations subsection that explicitly discusses this gap, notes the absence of stratification, and clarifies that the calibration-versus-orientation decomposition is demonstrated on the given corpus rather than proven free of all confounds. The core empirical finding—that persona prompting recovers scale use but leaves an orientation residual—remains intact on the reported data. revision: partial
Circularity Check
No significant circularity; new benchmark and external human pools are independent
full rationale
The paper constructs the VOIR DIRE benchmark of 626 items and measures within-pool reliability (α=0.86/0.74) plus cross-pool divergence (r=-0.12) as direct empirical observations on human annotators. Model bias decomposition into positivity-floor calibration failure and orientation failure follows from explicit comparisons against these external pools, with persona prompting tested as an intervention. No equations, fitted parameters, or self-citations are invoked to define the target quantities; the sampling procedure and pool divergence are presented as measured inputs rather than derived outputs. The central claims rest on new data collection and evaluation against independent human references, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[2]
References Improve
Kejian Shi and Yixin Liu and PeiFeng Wang and Alexander Fabbri and Shafiq Joty and Arman Cohan , booktitle=. References Improve. 2026 , url=
2026
-
[3]
Direct Judgement Preference Optimization
Wang, PeiFeng and Xu, Austin and Zhou, Yilun and Xiong, Caiming and Joty, Shafiq. Direct Judgement Preference Optimization. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.103
-
[4]
The Fourteenth International Conference on Learning Representations , year=
Foundational Automatic Evaluators: Scaling Multi-Task Generative Evaluator Training for Reasoning-Centric Domains , author=. The Fourteenth International Conference on Learning Representations , year=
-
[5]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Chen, Dongping and Chen, Ruoxi and Zhang, Shilin and Wang, Yaochen and Liu, Yinuo and Zhou, Huichi and Zhang, Qihui and Wan, Yao and Zhou, Pan and Sun, Lichao , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[6]
Lianghui Zhu and Xinggang Wang and Xinlong Wang , booktitle=. Judge. 2025 , url=
2025
-
[7]
The Twelfth International Conference on Learning Representations , year=
Prometheus: Inducing Fine-Grained Evaluation Capability in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[8]
First Conference on Language Modeling , year=
Length-Controlled AlpacaEval: A Simple Debiasing of Automatic Evaluators , author=. First Conference on Language Modeling , year=
-
[9]
A Closer Look into Using Large Language Models for Automatic Evaluation
Chiang, Cheng-Han and Lee, Hung-yi. A Closer Look into Using Large Language Models for Automatic Evaluation. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.599
-
[10]
G -eval: NLG evaluation using gpt-4 with better human alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang. G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.153
-
[11]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Santurkar, Shibani and Durmus, Esin and Ladhak, Faisal and Lee, Cinoo and Liang, Percy and Hashimoto, Tatsunori , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[12]
First Conference on Language Modeling , year=
Towards Measuring the Representation of Subjective Global Opinions in Language Models , author=. First Conference on Language Modeling , year=
-
[13]
ArXiv , year=
Evaluating Large Language Models Trained on Code , author=. ArXiv , year=
-
[14]
2024 , url=
Seonghyeon Ye and Doyoung Kim and Sungdong Kim and Hyeonbin Hwang and Seungone Kim and Yongrae Jo and James Thorne and Juho Kim and Minjoon Seo , booktitle=. 2024 , url=
2024
-
[15]
The ``problem'' of human label variation: On ground truth in data, modeling and evaluation
Plank, Barbara. The ``Problem'' of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.731
-
[16]
Inherent Disagreements in Human Textual Inferences
Pavlick, Ellie and Kwiatkowski, Tom. Inherent Disagreements in Human Textual Inferences. Transactions of the Association for Computational Linguistics. 2019. doi:10.1162/tacl_a_00293
-
[17]
and Ritter, Alan and Xu, Wei , title =
Naous, Tarek and Ryan, Michael J and Ritter, Alan and Xu, Wei. Having Beer after Prayer? Measuring Cultural Bias in Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.862
-
[18]
2025 , eprint=
CultureVLM: Characterizing and Improving Cultural Understanding of Vision-Language Models for over 100 Countries , author=. 2025 , eprint=
2025
-
[19]
Benchmarking Vision Language Models for Cultural Understanding
Nayak, Shravan and Jain, Kanishk and Awal, Rabiul and Reddy, Siva and Steenkiste, Sjoerd Van and Hendricks, Lisa Anne and Stanczak, Karolina and Agrawal, Aishwarya. Benchmarking Vision Language Models for Cultural Understanding. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.329
-
[20]
F oodie QA : A Multimodal Dataset for Fine-Grained Understanding of C hinese Food Culture
Li, Wenyan and Zhang, Crystina and Li, Jiaang and Peng, Qiwei and Tang, Raphael and Zhou, Li and Zhang, Weijia and Hu, Guimin and Yuan, Yifei and S gaard, Anders and Hershcovich, Daniel and Elliott, Desmond. F oodie QA : A Multimodal Dataset for Fine-Grained Understanding of C hinese Food Culture. Proceedings of the 2024 Conference on Empirical Methods in...
-
[21]
Kim, Jun Seong and Thu, Kyaw Ye and Ismayilzada, Javad and Park, Junyeong and Kim, Eunsu and Ahmad, Huzama and An, Na Min and Thorne, James and Oh, Alice. WHEN TOM EATS KIMCHI : Evaluating Cultural Awareness of Multimodal Large Language Models in Cultural Mixture Contexts. Proceedings of the 3rd Workshop on Cross-Cultural Considerations in NLP (C3NLP 2025...
-
[22]
Can Large Language Models Be an Alternative to Human Evaluations?
Chiang, Cheng-Han and Lee, Hung-yi. Can Large Language Models Be an Alternative to Human Evaluations?. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.870
-
[23]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[24]
GPTS core: Evaluate as You Desire
Fu, Jinlan and Ng, See-Kiong and Jiang, Zhengbao and Liu, Pengfei. GPTS core: Evaluate as You Desire. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.365
-
[25]
Thirty-seventh Conference on Neural Information Processing Systems , year=
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[26]
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh. FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.1...
-
[27]
and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael I
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios N. and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael I. and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[28]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Lee, Harrison and Phatale, Samrat and Mansoor, Hassan and Mesnard, Thomas and Ferret, Johan and Lu, Kellie and Bishop, Colton and Hall, Ethan and Carbune, Victor and Rastogi, Abhinav and Prakash, Sushant , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[29]
Tianyi Xiong and Xiyao Wang and Dong Guo and Qinghao Ye and Haoqi Fan and Quanquan Gu and Heng Huang and Chunyuan Li , year=
-
[30]
VLF eedback: A Large-Scale AI Feedback Dataset for Large Vision-Language Models Alignment
Li, Lei and Xie, Zhihui and Li, Mukai and Chen, Shunian and Wang, Peiyi and Chen, Liang and Yang, Yazheng and Wang, Benyou and Kong, Lingpeng and Liu, Qi. VLF eedback: A Large-Scale AI Feedback Dataset for Large Vision-Language Models Alignment. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2...
-
[31]
The Twelfth International Conference on Learning Representations , year=
Generative Judge for Evaluating Alignment , author=. The Twelfth International Conference on Learning Representations , year=
-
[32]
CLIP- Score: A reference-free evaluation metric for image captioning
Hessel, Jack and Holtzman, Ari and Forbes, Maxwell and Le Bras, Ronan and Choi, Yejin. CLIPS core: A Reference-free Evaluation Metric for Image Captioning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.595
-
[33]
and Parikh, Devi , title =
Vedantam, Ramakrishna and Lawrence Zitnick, C. and Parikh, Devi , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[34]
2010 , journal =
Joseph Henrich and Steven Heine and Ara Norenzayan , title =. 2010 , journal =
2010
-
[35]
2023 , eprint=
Verbosity Bias in Preference Labeling by Large Language Models , author=. 2023 , eprint=
2023
-
[36]
Large Language Models are not Fair Evaluators
Wang, Peiyi and Li, Lei and Chen, Liang and Cai, Zefan and Zhu, Dawei and Lin, Binghuai and Cao, Yunbo and Kong, Lingpeng and Liu, Qi and Liu, Tianyu and Sui, Zhifang. Large Language Models are not Fair Evaluators. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.ac...
-
[37]
Bowman and Shi Feng , booktitle=
Arjun Panickssery and Samuel R. Bowman and Shi Feng , booktitle=. 2024 , url=
2024
-
[38]
Chen, Guiming Hardy and Chen, Shunian and Liu, Ziche and Jiang, Feng and Wang, Benyou. Humans or LLM s as the Judge? A Study on Judgement Bias. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.474
-
[39]
Gallegos, Isabel O. and Rossi, Ryan A. and Barrow, Joe and Tanjim, Md Mehrab and Kim, Sungchul and Dernoncourt, Franck and Yu, Tong and Zhang, Ruiyi and Ahmed, Nesreen K. Bias and Fairness in Large Language Models: A Survey. Computational Linguistics. 2024. doi:10.1162/coli_a_00524
-
[40]
Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency , pages =
Bianchi, Federico and Kalluri, Pratyusha and Durmus, Esin and Ladhak, Faisal and Cheng, Myra and Nozza, Debora and Hashimoto, Tatsunori and Jurafsky, Dan and Zou, James and Caliskan, Aylin , title =. Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2023 , isbn =. doi:10.1145/3593013.3594095 , abstract =
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Rewind and Render: Towards Factually Accurate Text-to-Video Generation with Distilled Knowledge Retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2025 , doi=
2025
-
[42]
Knowledge of cultural moral norms in large language models
Ramezani, Aida and Xu, Yang. Knowledge of cultural moral norms in large language models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.26
-
[43]
AlKhamissi, Badr and ElNokrashy, Muhammad and Alkhamissi, Mai and Diab, Mona. Investigating Cultural Alignment of Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.671
-
[44]
METAL : Towards Multilingual Meta-Evaluation
Hada, Rishav and Gumma, Varun and Ahmed, Mohamed and Bali, Kalika and Sitaram, Sunayana. METAL : Towards Multilingual Meta-Evaluation. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.148
-
[45]
Chiu, Yu Ying and Jiang, Liwei and Lin, Bill Yuchen and Park, Chan Young and Li, Shuyue Stella and Ravi, Sahithya and Bhatia, Mehar and Antoniak, Maria and Tsvetkov, Yulia and Shwartz, Vered and Choi, Yejin. C ultural B ench: A Robust, Diverse and Challenging Benchmark for Measuring LM s' Cultural Knowledge Through Human- AI Red-Teaming. Proceedings of th...
-
[46]
2024 , url=
Junho Myung and Nayeon Lee and Yi Zhou and Jiho Jin and Rifki Afina Putri and Dimosthenis Antypas and Hsuvas Borkakoty and Eunsu Kim and Carla Perez-Almendros and Abinew Ali Ayele and Victor Gutierrez Basulto and Yazmin Ibanez-Garcia and Hwaran Lee and Shamsuddeen Hassan Muhammad and Kiwoong Park and Anar Sabuhi Rzayev and Nina White and Seid Muhie Yimam ...
2024
-
[47]
2023 , eprint=
Inspecting the Geographical Representativeness of Images from Text-to-Image Models , author=. 2023 , eprint=
2023
-
[48]
2024 , eprint=
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark , author=. 2024 , eprint=
2024
-
[49]
Pradeep, Ronak and Lee, Daniel and Mousavi, Ali and Pound, Jeffrey and Sang, Yisi and Lin, Jimmy and Ilyas, Ihab and Potdar, Saloni and Arefiyan, Mostafa and Li, Yunyao. C onv KGY arn: Spinning Configurable and Scalable Conversational Knowledge Graph QA Datasets with Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural...
-
[50]
AVA: A large-scale database for aesthetic visual analysis , year=
Murray, Naila and Marchesotti, Luca and Perronnin, Florent , booktitle=. AVA: A large-scale database for aesthetic visual analysis , year=
-
[51]
Photo Aesthetics Ranking Network with Attributes and Content Adaptation , journal =
Shu Kong and Xiaohui Shen and Zhe Lin and Radom. Photo Aesthetics Ranking Network with Attributes and Content Adaptation , journal =. 2016 , url =. 1606.01621 , timestamp =
Pith/arXiv arXiv 2016
-
[52]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[53]
Thirty-seventh Conference on Neural Information Processing Systems , year=
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[54]
Klaus Krippendorff , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.