Evolutionary Discovery of Developmental Reward Schedules in Deep Reinforcement Learning
Pith reviewed 2026-06-26 18:10 UTC · model grok-4.3
The pith
Evolutionary search over time-varying weights for agency, novelty, and reactivity produces reward schedules that improve deep RL on sparse-reward MiniGrid tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An evolutionary framework that optimizes time-varying weights for three biologically inspired motivational components—agency, novelty, and reactivity—yields developmental reward schedules that outperform an extrinsic-only baseline on DoorKey-6x6 and achieve competitive results on KeyCorridorS3R1, with novelty consistently emerging as the dominant early signal in the discovered schedules across both tasks.
What carries the argument
Evolutionary optimization of time-varying weights that combine the three motivational components agency, novelty, and reactivity into a single developmental reward signal.
If this is right
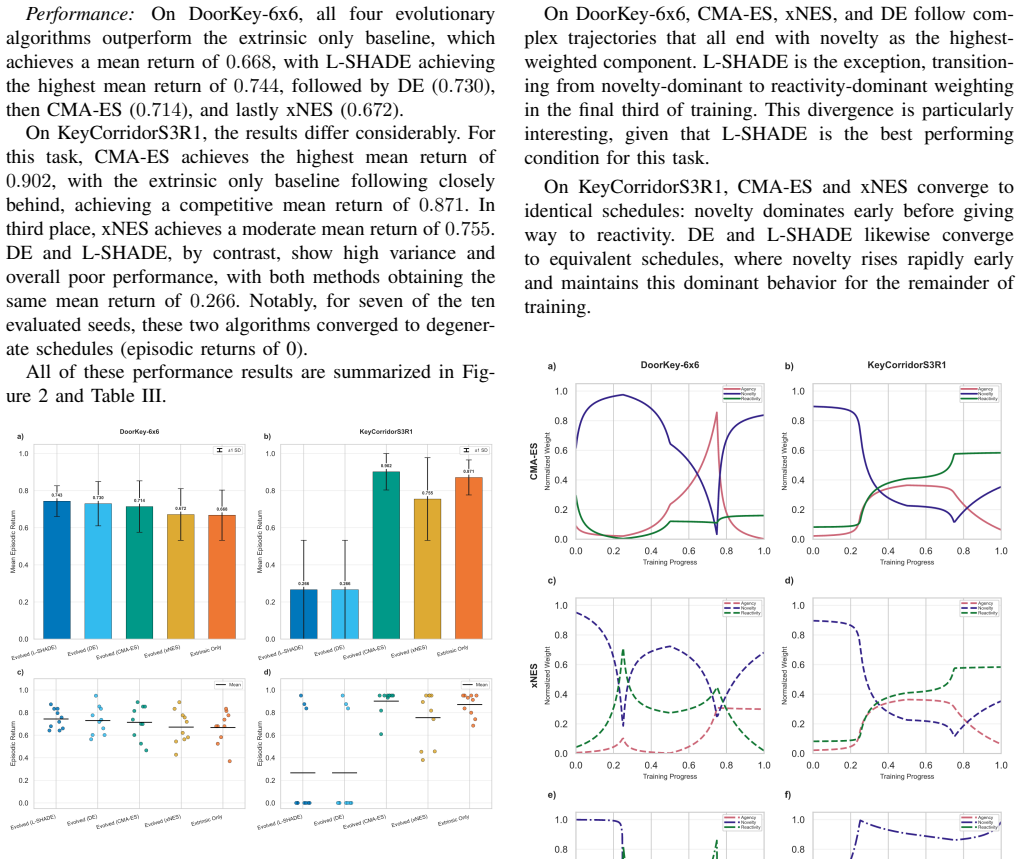
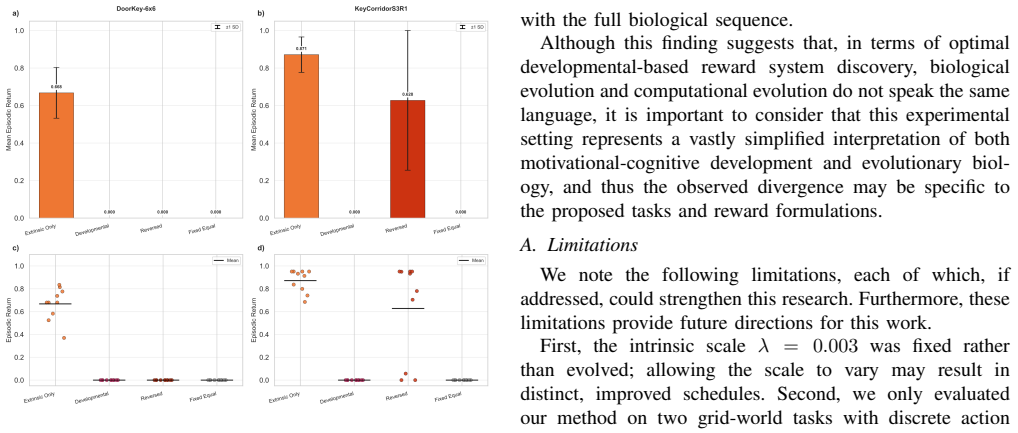
- All four evolutionary algorithms outperform the extrinsic baseline and the hand-designed schedules on DoorKey-6x6.
- L-SHADE records the largest gain, an approximate 11.4 percent relative mean improvement over the extrinsic baseline on DoorKey-6x6.
- CMA-ES records the strongest performance on KeyCorridorS3R1 while the other evolved methods show weaker generalization.
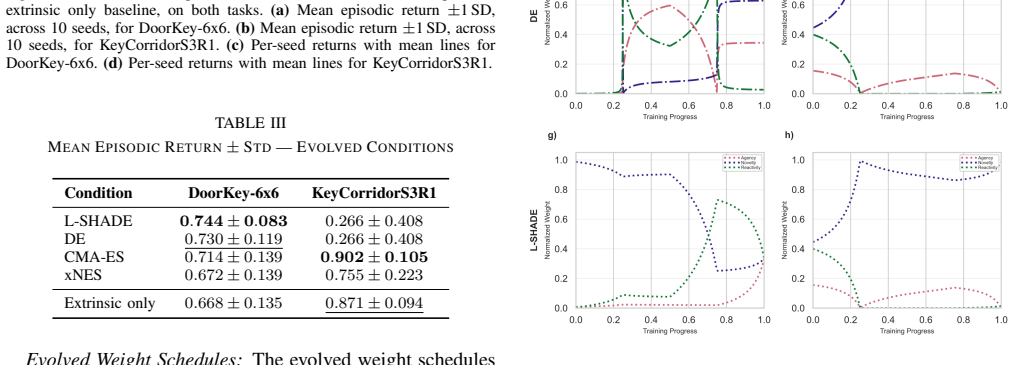
- Every high-performing schedule places novelty as the dominant early motivational signal, diverging from the authors' initial developmental ordering.
- Evolutionary search over motivational weights constitutes a viable method for discovering developmental reward schedules in deep reinforcement learning.
Where Pith is reading between the lines
- If novelty dominance proves robust, curricula that front-load novelty bonuses could be tested manually in other sparse-reward domains without re-running evolution.
- The gap between the discovered ordering and biological expectations raises the question of whether computational optimality systematically favors different early signals than natural selection does.
- Schedules evolved on one MiniGrid layout might be tested for zero-shot transfer to larger or procedurally varied layouts to measure how much re-optimization is required.
- Replacing the fixed three-component basis with additional or alternative motivational terms could be explored to see whether further gains are available.
Load-bearing premise
The three motivational components supply a sufficient basis for constructing effective schedules, and schedules found during evolutionary search will generalize beyond the specific training runs used for optimization.
What would settle it
A replication on DoorKey-6x6 in which none of the four evolutionary algorithms produce schedules whose mean return exceeds the extrinsic-only baseline by a statistically reliable margin.
Figures




read the original abstract
The temporal structure of reward composition in reinforcement learning (RL) is typically hand-designed and held fixed throughout training, leaving the progression of motivational priorities largely unexplored. In this work, we propose an evolutionary framework for discovering developmental reward schedules, in which three distinct biologically inspired motivational components -- agency, novelty, and reactivity -- are combined through time-varying weights that dynamically shift over the course of training. Evaluated on two sparse-reward MiniGrid tasks: DoorKey-6x6 and KeyCorridorS3R1, our framework compares the generalizability of four evolutionary algorithms: CMA-ES, xNES, DE, and L-SHADE against an extrinsically motivated baseline (our main comparison point), and three additional hand-designed methods. On DoorKey-6x6, all evolved methods outperform the non-evolved baselines, with L-SHADE achieving the best performance -- an approximate relative mean improvement of 11.4% over the extrinsic only baseline. On KeyCorridorS3R1, CMA-ES achieves the best overall performance, with the remaining evolved methods showing weaker and less reliable generalization capability compared to the extrinsic only baseline. Interestingly, the discovered schedules diverge from our defined developmental ordering, with novelty consistently emerging as the dominant early signal during training, across both tasks. Collectively, our results position evolutionary optimization as a promising approach for developmental reward schedule discovery in deep reinforcement learning, and suggest that what evolution finds to be optimal in computational settings may differ from what it finds to be optimal in biology. The code for this project can be found at: https://github.com/alannadels/Evolutionary_RL.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an evolutionary framework for discovering time-varying weights that combine three biologically inspired motivational components (agency, novelty, reactivity) into developmental reward schedules for deep RL. On two sparse-reward MiniGrid environments, four evolutionary algorithms (CMA-ES, xNES, DE, L-SHADE) are compared to an extrinsic-only baseline and hand-designed schedules. L-SHADE yields an approximate 11.4% relative mean improvement on DoorKey-6x6; results on KeyCorridorS3R1 are mixed, with CMA-ES strongest but other evolved methods weaker than the baseline. Evolved schedules consistently prioritize novelty early, diverging from the authors' defined developmental ordering. Code is released at a public GitHub repository.
Significance. If the empirical claims hold after proper statistical controls and generalization checks, the work would demonstrate that black-box evolutionary search can automate discovery of effective, non-stationary reward compositions in RL and that the resulting schedules can differ from both hand-designed and biologically motivated priors. The open code release supports reproducibility and follow-up work on automated motivational scheduling.
major comments (3)
- [Abstract] Abstract and experimental section: the headline 11.4% relative improvement on DoorKey-6x6 and the claim that 'all evolved methods outperform the non-evolved baselines' are reported without any indication of the number of independent runs, standard errors, or statistical significance tests. This information is load-bearing for the central empirical claim.
- [Abstract] Abstract: on KeyCorridorS3R1 the majority of evolved methods underperform the extrinsic baseline in generalization, yet the manuscript presents no evidence that the discovered weight trajectories were re-evaluated on held-out random seeds or environment instances after the evolutionary optimization phase. This leaves open the possibility that reported gains reflect overfitting to the finite set of trajectories used for fitness evaluation rather than robust schedule discovery.
- [Method] Method and experimental setup: the evolutionary search optimizes the time-varying weights directly on the target tasks; without an explicit description of how the fitness function is constructed (e.g., number of episodes per candidate, whether early-stopping or validation splits are used) it is impossible to assess whether the search is discovering transferable developmental schedules or merely exploiting idiosyncrasies of the training runs.
minor comments (2)
- [Abstract] The abstract states 'approximate relative mean improvement' without defining the exact baseline mean or the aggregation method across seeds.
- [Method] Notation for the three motivational components and their time-varying weights is introduced but never formalized with equations; readers must infer the representation from the evolutionary-algorithm descriptions.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below. We agree that additional statistical reporting and methodological details are needed to strengthen the empirical claims, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental section: the headline 11.4% relative improvement on DoorKey-6x6 and the claim that 'all evolved methods outperform the non-evolved baselines' are reported without any indication of the number of independent runs, standard errors, or statistical significance tests. This information is load-bearing for the central empirical claim.
Authors: We agree that the absence of run counts, error bars, and significance tests weakens the central claims. In the revision we will report the exact number of independent runs performed, include standard errors (or confidence intervals), and add statistical tests comparing evolved schedules to the extrinsic baseline. These details will be inserted into both the abstract and the experimental results section. revision: yes
-
Referee: [Abstract] Abstract: on KeyCorridorS3R1 the majority of evolved methods underperform the extrinsic baseline in generalization, yet the manuscript presents no evidence that the discovered weight trajectories were re-evaluated on held-out random seeds or environment instances after the evolutionary optimization phase. This leaves open the possibility that reported gains reflect overfitting to the finite set of trajectories used for fitness evaluation rather than robust schedule discovery.
Authors: We acknowledge the concern about possible overfitting. The current manuscript reports generalization performance on held-out evaluation episodes with varied random seeds, but the protocol is not stated explicitly. We will add a dedicated paragraph describing the post-evolution evaluation procedure, including the number of held-out seeds and environment instances used for final reporting. If further held-out testing is required, we can conduct it during revision. revision: partial
-
Referee: [Method] Method and experimental setup: the evolutionary search optimizes the time-varying weights directly on the target tasks; without an explicit description of how the fitness function is constructed (e.g., number of episodes per candidate, whether early-stopping or validation splits are used) it is impossible to assess whether the search is discovering transferable developmental schedules or merely exploiting idiosyncrasies of the training runs.
Authors: We agree that the fitness evaluation details are insufficiently specified. The revised Methods section will explicitly state the number of episodes (or steps) used to evaluate each candidate, the total training horizon, any early-stopping rules, and whether validation splits or multiple environment instances were employed during search. This will allow readers to judge the transferability of the discovered schedules. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical evolutionary optimization procedure (CMA-ES, xNES, DE, L-SHADE) that searches for time-varying weights on three motivational components and evaluates the resulting schedules on two MiniGrid environments against fixed baselines. No equations, first-principles derivations, or parameter-fitting steps are described that would reduce the reported performance deltas to quantities defined by the same data or by self-referential definitions. The search itself constitutes the method; measured improvements are external empirical outcomes rather than algebraic identities or fitted-input predictions. No load-bearing self-citations or uniqueness theorems appear in the provided text. The work is therefore self-contained against its external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- time-varying weights for agency, novelty, reactivity
axioms (1)
- domain assumption The three components (agency, novelty, reactivity) are appropriate and sufficient building blocks for developmental reward schedules in these environments.
Reference graph
Works this paper leans on
-
[1]
M. Luciana, D. Wahlstrom, J. N. Porter, and P. F. Collins, “Dopamin- ergic modulation of incentive motivation in adolescence: age-related changes in signaling, individual differences, and implications for the development of self-regulation,”Dev. Psychol., vol. 48, no. 3, pp. 844– 861, May 2012, doi: 10.1037/a0027432
-
[2]
A motivational theory of life-span development,
J. Heckhausen, C. Wrosch, and R. Schulz, “A motivational theory of life-span development,”Psychol. Rev., vol. 117, no. 1, pp. 32–60, Jan. 2010, doi: 10.1037/a0017668
-
[3]
C. Kidd, S. T. Piantadosi, and R. N. Aslin, “The Goldilocks effect: Human infants allocate attention to visual sequences that are neither too simple nor too complex,”PLOS One, vol. 7, no. 5, e36399, May 2012, doi: 10.1371/journal.pone.0036399
-
[4]
Adolescent development of the reward system,
A. Galvan, “Adolescent development of the reward system,” Front. Hum. Neurosci., vol. 4, art. 6, Feb. 2010, doi: 10.3389/neuro.09.006.2010
-
[5]
A unique adolescent response to reward prediction errors,
J. R. Cohen, R. F. Asarnow, F. W. Sabb, R. M. Bilder, S. Y . Bookheimer, B. J. Knowlton, and R. A. Poldrack, “A unique adolescent response to reward prediction errors,”Nat. Neurosci., vol. 13, no. 6, pp. 669–671, Jun. 2010, doi: 10.1038/nn.2558
-
[6]
B. J. Casey, R. M. Jones, and T. A. Hare, “The adolescent brain,”Ann. N.Y. Acad. Sci., vol. 1124, pp. 111–126, Mar. 2008, doi: 10.1196/an- nals.1440.010
work page doi:10.1196/an- 2008
-
[7]
Develop- ment of corticostriatal connectivity constrains goal-directed behavior during adolescence,
C. Insel, E. K. Kastman, C. R. Glenn, and L. H. Somerville, “Develop- ment of corticostriatal connectivity constrains goal-directed behavior during adolescence,”Nat. Commun., vol. 8, no. 1, art. 1605, Nov. 2017, doi: 10.1038/s41467-017-01369-8
-
[8]
Motivation reconsidered: The concept of compe- tence,
R. W. White, “Motivation reconsidered: The concept of compe- tence,”Psychol. Rev., vol. 66, no. 5, pp. 297–333, Sep. 1959, doi: 10.1037/h0040934
-
[9]
C. Kidd and B. Y . Hayden, “The psychology and neuroscience of curiosity,”Neuron, vol. 88, no. 3, pp. 449–460, Nov. 2015, doi: 10.1016/j.neuron.2015.09.010
-
[10]
Proximal Policy Optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization algorithms,”arXiv, Jul. 2017, arXiv:1707.06347
Pith/arXiv arXiv 2017
-
[11]
Minigrid & Miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks,
M. Chevalier-Boisvert, B. Dai, M. Towers, R. de Lazcano, L. Willems, S. Lahlou, S. Pal, P. S. Castro, and J. Terry, “Minigrid & Miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks,” inProc. 37th Conf. on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, pp. 73383–73394, Dec. 2023
2023
-
[12]
The CMA Evolution Strategy: A tutorial,
N. Hansen, “The CMA Evolution Strategy: A tutorial,”arXiv, Mar. 2023, arXiv:1604.00772
Pith/arXiv arXiv 2023
-
[13]
Exponential Natural Evolution Strategies,
T. Glasmachers, T. Schaul, S. Yi, D. Wierstra, and J. Schmidhuber, “Exponential Natural Evolution Strategies,” inProc. 12th Annual Conf. on Genetic and Evolutionary Computation (GECCO), pp. 393–400, Jul. 2010, doi: 10.1145/1830483.1830557
-
[14]
Journal of global optimization11(4), 341–359 (1997) https://doi.org/10.1023/A:1008202821328
R. Storn and K. Price, “Differential Evolution – A simple and efficient heuristic for global optimization over continuous spaces,” J. Global Optim., vol. 11, no. 4, pp. 341–359, Dec. 1997, doi: 10.1023/A:1008202821328
-
[15]
Improving the search performance of SHADE using linear population size reduction,
R. Tanabe and A. S. Fukunaga, “Improving the search performance of SHADE using linear population size reduction,” inProc. IEEE Congress on Evol. Computation (CEC), pp. 1658–1665, Jul. 2014, doi: 10.1109/CEC.2014.6900380
-
[16]
Reinforcement learning across development: What insights can we draw from a decade of re- search?,
K. Nussenbaum and C. A. Hartley, “Reinforcement learning across development: What insights can we draw from a decade of re- search?,”Dev. Cogn. Neurosci., vol. 40, art. 100733, Dec. 2019, doi: 10.1016/j.dcn.2019.100733
-
[17]
Emulating perceptual development in deep reinforcement learning,
E. Arditi, Y . Nagai, E. Ugur, M. Asada, and E. Oztop, “Emulating perceptual development in deep reinforcement learning,” inProc. IEEE Int. Conf. on Development and Learning (ICDL), Sep. 2025, doi: 10.1109/ICDL63968.2025.11204434
-
[18]
Curriculum learning for reinforcement learning domains: A framework and survey,
S. Narvekar, B. Peng, M. Leonetti, J. Sinapov, M. E. Taylor, and P. Stone, “Curriculum learning for reinforcement learning domains: A framework and survey,”J. Mach. Learn. Res., vol. 21, no. 1, art. 181, Jan. 2020
2020
-
[19]
#Exploration: A study of count-based exploration for deep reinforcement learning,
H. Tang, R. Houthooft, D. Foote, A. Stooke, X. Chen, Y . Duan, J. Schulman, F. De Turck, and P. Abbeel, “#Exploration: A study of count-based exploration for deep reinforcement learning,” inProc. 31st Conf. on Neural Information Processing Systems (NeurIPS), pp. 2750– 2759, Dec. 2017
2017
-
[20]
Intrinsic mo- tivation exploration via self-supervised prediction in reinforce- ment learning,
Z. Yang, H. Du, Y . Wu, Z. Jiang, and H. Qu, “Intrinsic mo- tivation exploration via self-supervised prediction in reinforce- ment learning,” inProc. 6th Int. Conf. on Data-driven Op- tim. of Complex Systems (DOCS), pp. 79–84, Aug. 2024, doi: 10.1109/DOCS63458.2024.10704242
-
[21]
Rethinking exploration in rein- forcement learning with effective metric-based exploration bonus,
Y . Wang, K. Zhao, F. Liu, and L. H. U, “Rethinking exploration in rein- forcement learning with effective metric-based exploration bonus,” in Proc. 38th Conf. on Neural Information Processing Systems (NeurIPS), pp. 57765–57792, Dec. 2024
2024
-
[22]
Self-attention-based temporary cu- riosity in reinforcement learning exploration,
H. Hu, S. Song, and G. Huang, “Self-attention-based temporary cu- riosity in reinforcement learning exploration,”IEEE Trans. on Systems, Man, and Cybernetics: Systems, vol. 51, no. 9, pp. 5773–5784, Sep. 2021, doi: 10.1109/TSMC.2019.2957051
-
[23]
H. Okada, “A comparative study of DE, GA and ES for evo- lutionary reinforcement learning of neural networks in pendulum task,” inProc. Congress in Comp. Science, Comp. Engineer- ing, & Applied Computing (CSCE), pp. 426–428, Jul. 2023, doi: 10.1109/CSCE60160.2023.00076
-
[24]
Adaptive combination of a Genetic Algorithm and Novelty Search for deep neuroevolution,
E. Segal and M. Sipper, “Adaptive combination of a Genetic Algorithm and Novelty Search for deep neuroevolution,” inProc. 14th Int. Joint Conf. on Computational Intelligence (IJCCI), pp. 143–150, Oct. 2022, doi: 10.5220/0011550200003332
-
[25]
Y . Peng, G. Chen, M. Zhang, and B. Xue, “Proximal Evolutionary Strategy: Improving deep reinforcement learning through evolutionary policy optimization,”Memetic Computing, vol. 16, no. 3, pp. 445–466, Sep. 2024, doi: 10.1007/s12293-024-00419-1
-
[26]
Discovering state-of-the-art reinforcement learning algorithms,
J. Oh, G. Farquhar, I. Kemaev, D. A. Calian, M. Hessel, L. Zintgraf, S. Singh, H. van Hasselt, and D. Silver, “Discovering state-of-the-art reinforcement learning algorithms,”Nature, vol. 648, no. 8093, pp. 312–319, Dec. 2025, doi: 10.1038/s41586-025-09761-x
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.