Factor-Aware Mixture-of-Experts with Pretrained Encoder for Combinatorial Generalization
Pith reviewed 2026-06-26 14:29 UTC · model grok-4.3
The pith
Factor-aware mixture-of-experts with pretrained encoders allows diffusion policies to generalize to unseen combinations of environmental factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
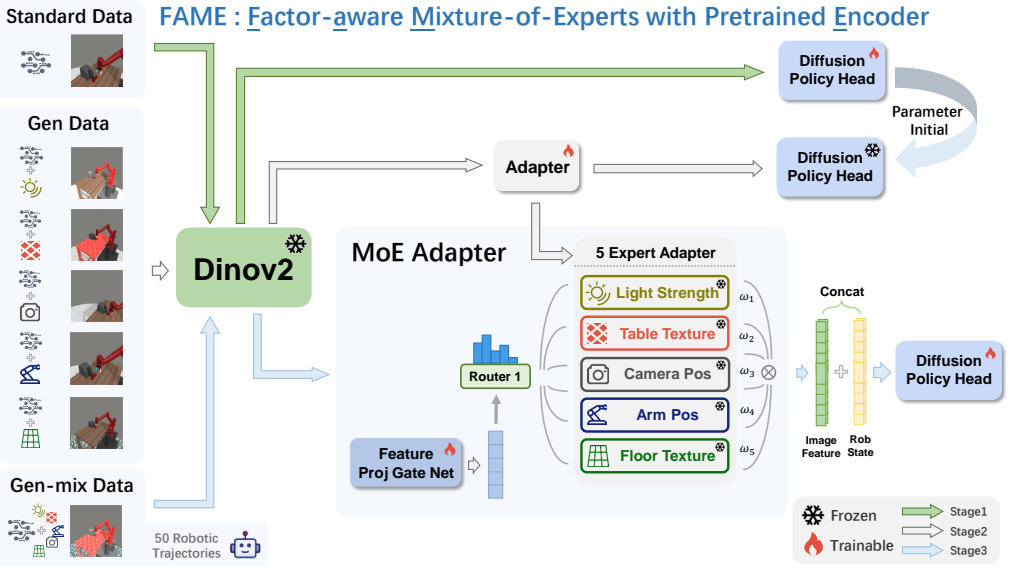
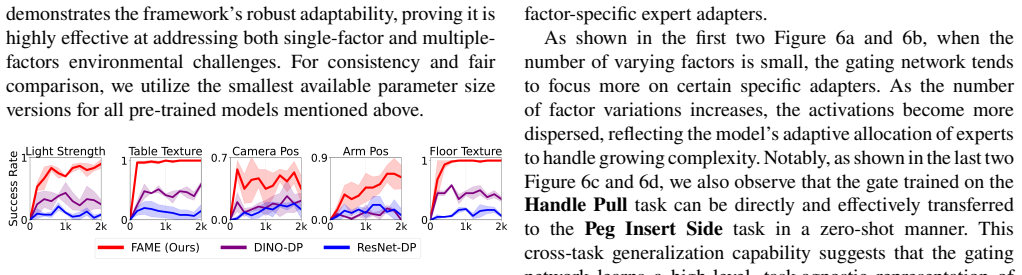
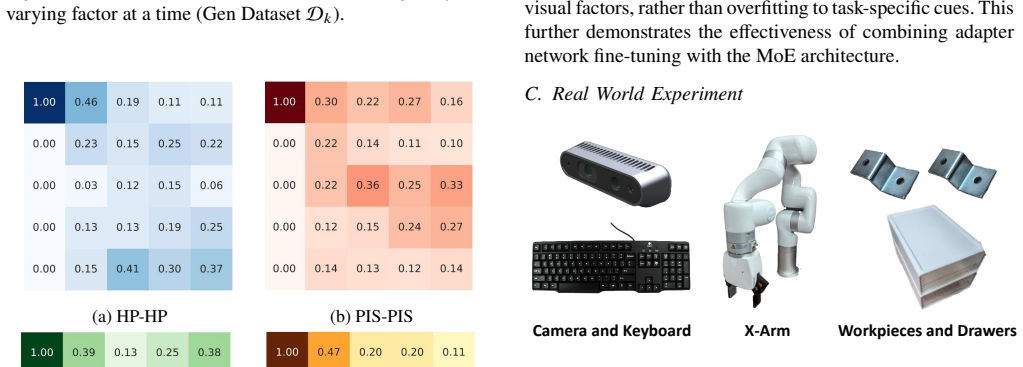
FAME integrates a factor-aware mixture-of-experts with a pretrained encoder through a three-stage process: policy warmup on standard-environment data with a frozen encoder, factor-specific adapter training on customized single-factor datasets, and joint fine-tuning where a central router and the policy learn to handle multiple factors on mixed data. The router softly weights the frozen adapters to enable effective behavior on unseen factor combinations.
What carries the argument
The central router that softly weights frozen factor-specific adapters as a dense mixture-of-experts to enable combinatorial generalization.
If this is right
- The policy handles multiple environmental factors jointly after the joint fine-tuning stage.
- Performance reaches 34 percent above diffusion policy baselines on the Meta-World benchmark.
- Generalization improves by 35 percent under real-world variations in a pick-and-place task.
- Independent single-factor adapters can be reused across different combinations via the router.
Where Pith is reading between the lines
- Adding more adapters for additional factors could extend the framework without retraining the entire policy from scratch.
- The router mechanism might reduce the volume of mixed-factor data needed compared with training a monolithic policy on all combinations.
- Similar modular adapter-plus-router designs could apply to other pretrained models facing combinatorial shifts in object properties or task parameters.
Load-bearing premise
Adapters trained independently on single-factor datasets can be softly combined by a router on mixed data to produce effective behavior on unseen factor combinations without significant interference or negative transfer.
What would settle it
If the router-weighted model shows no higher success rate than a single-adapter or non-MoE baseline on a held-out test set containing novel combinations of two or more factors, the combinatorial generalization claim would not hold.
Figures

read the original abstract
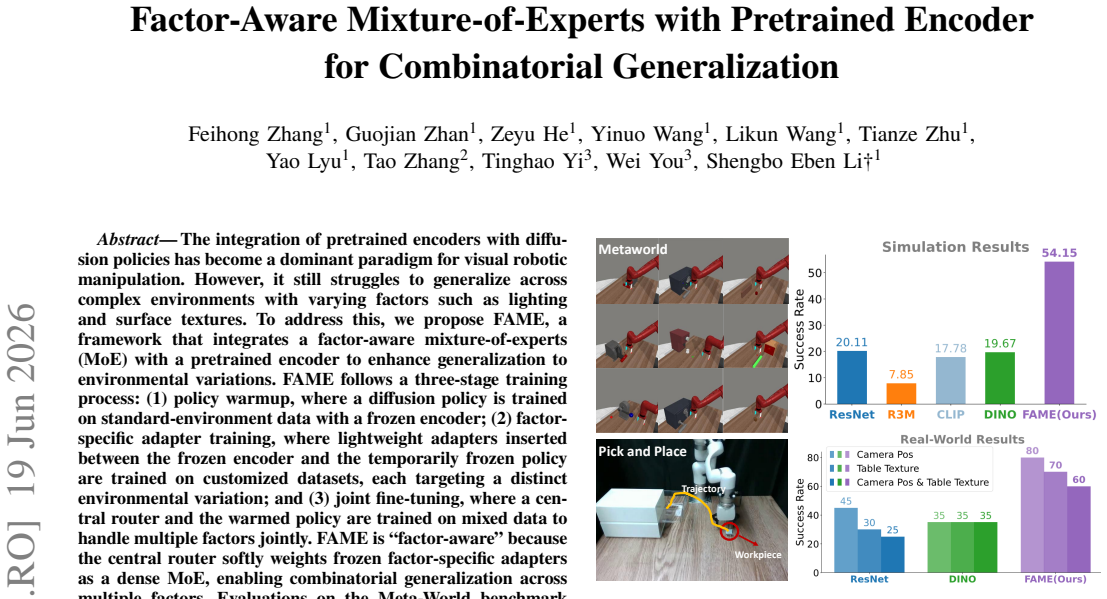
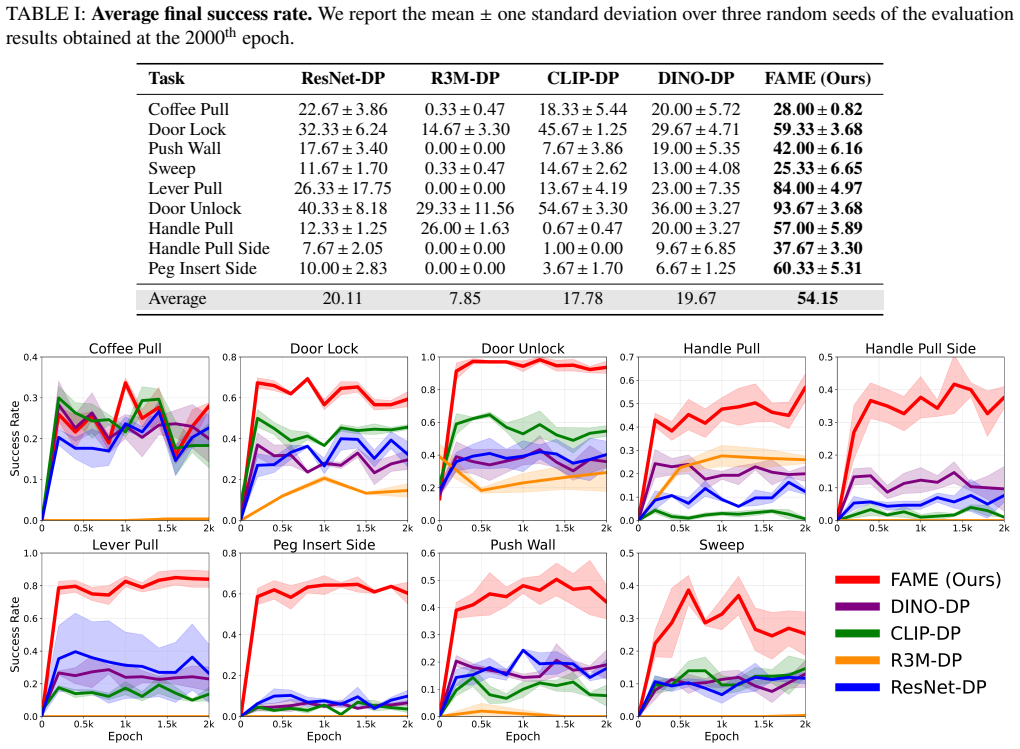
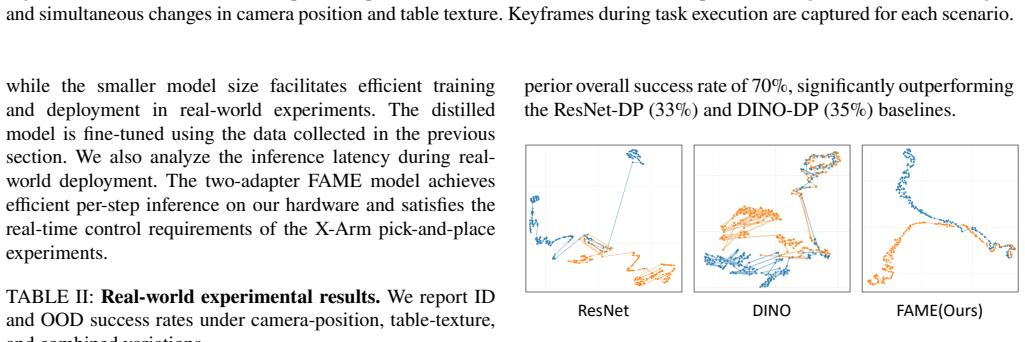
The integration of pretrained encoders with diffusion policies has become a dominant paradigm for visual robotic manipulation. However, it still struggles to generalize across complex environments with varying factors such as lighting and surface textures. To address this, we propose FAME, a framework that integrates a factor-aware mixture-of-experts (MoE) with a pretrained encoder to enhance generalization to environmental variations. FAME follows a three-stage training process: (1) policy warmup, where a diffusion policy is trained on standard-environment data with a frozen encoder; (2) factor-specific adapter training, where lightweight adapters inserted between the frozen encoder and the temporarily frozen policy are trained on customized datasets, each targeting a distinct environmental variation; and (3) joint fine-tuning, where a central router and the warmed policy are trained on mixed data to handle multiple factors jointly. FAME is ``factor-aware'' because the central router softly weights frozen factor-specific adapters as a dense MoE, enabling combinatorial generalization across multiple factors. Evaluations on the Meta-World benchmark show that FAME outperforms diffusion policy baselines by 34%. We further validate FAME in a real-world pick-and-place task using a compact model trained on newly collected data, where FAME achieves a 35% improvement in generalization under real-world variations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FAME, a factor-aware mixture-of-experts (MoE) framework that augments a pretrained encoder with a diffusion policy for robotic manipulation. It employs a three-stage training procedure—policy warmup on standard data with frozen encoder, training of lightweight factor-specific adapters on single-factor customized datasets, and joint fine-tuning of a router plus warmed policy on mixed multi-factor data—to enable soft composition of adapters for combinatorial generalization to unseen environmental variations (e.g., lighting, textures). The central empirical claims are a 34% outperformance versus diffusion policy baselines on Meta-World and a 35% generalization improvement in a real-world pick-and-place task.
Significance. If the held-out combinatorial generalization claim is substantiated with proper experimental controls, the approach could offer a practical route to factor-robust policies without full retraining, leveraging frozen pretrained encoders and lightweight adapters. The three-stage MoE design is a reasonable engineering response to the problem. However, the manuscript supplies no information on baseline re-implementations, random seeds, statistical tests, or dataset construction, so the magnitude of the reported gains cannot be assessed and the significance remains provisional.
major comments (2)
- [Abstract] Abstract: the performance claims (34% on Meta-World, 35% real-world) are stated without any information on baseline implementations, number of seeds, statistical tests, or construction of the customized factor datasets. This information is load-bearing for evaluating the central empirical claim.
- [Three-stage training process] Three-stage training process (abstract description of stages 2–3): there is no statement confirming that the multi-factor combinations used for evaluation are absent from the mixed training data in stage 3. Without explicit held-out status, observed gains may reflect interpolation within the training distribution rather than extrapolation to novel factor combinations, directly undermining the combinatorial generalization claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that clarify the experimental protocol and training procedure.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims (34% on Meta-World, 35% real-world) are stated without any information on baseline implementations, number of seeds, statistical tests, or construction of the customized factor datasets. This information is load-bearing for evaluating the central empirical claim.
Authors: We agree that the current manuscript does not supply these details in the abstract or elsewhere. In the revised version we will expand both the abstract and the Experiments section to describe baseline re-implementations, report results across multiple random seeds with statistical tests, and detail the construction of the single-factor customized datasets. revision: yes
-
Referee: [Three-stage training process] Three-stage training process (abstract description of stages 2–3): there is no statement confirming that the multi-factor combinations used for evaluation are absent from the mixed training data in stage 3. Without explicit held-out status, observed gains may reflect interpolation within the training distribution rather than extrapolation to novel factor combinations, directly undermining the combinatorial generalization claim.
Authors: We agree that an explicit statement is required. Stage 3 trains the router and policy only on mixtures of the single-factor datasets; the multi-factor test combinations are constructed to be absent from this training data. We will add a clear statement in the Method and Experiments sections confirming the held-out status of these combinations. revision: yes
Circularity Check
No circularity: empirical training procedure with external benchmark validation
full rationale
The paper presents FAME as a three-stage empirical training process (policy warmup, factor-specific adapter training, joint fine-tuning with router) evaluated on Meta-World and real-world tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Claims rest on performance deltas against baselines on external benchmarks, satisfying the self-contained criterion with no load-bearing reductions to internal definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y. Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”Proceedings of Robotics: Science and Systems (RSS), 2023. [Online]. Available: https://arxiv.org/abs/2303.04115
-
[2]
X-distill: Cross-architecture vision distillation for visuomotor learning,
M. Shao, F. Zhang, G. Zhang, B. Cheng, Z. Xue, and H. Xu, “X-distill: Cross-architecture vision distillation for visuomotor learning,”arXiv preprint arXiv:2601.11269, 2026
-
[3]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, R. Howes, P.-Y. Huang, H. Xu, V. Sharma, S.-W. Li, W. Galuba, M. Rabbat, M. Assran, N. Ballas, G. Synnaeve, I. Misra, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “Dinov2: Learning robust visual features without supervis...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark,et al., “Learning transferable visual models from natural language supervision,”arXiv preprint arXiv:2103.00020, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
R3M: A Universal Visual Representation for Robot Manipulation
S. Nair, A. Rajeswaran, V. Kumar, C. Finn, and A. Gupta, “R3m: A universal visual representation for robot manipulation,”arXiv preprint arXiv:2203.12601, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Denoising Diffusion Probabilistic Models
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in Neural Information Processing Systems, vol. 33, pp. 6840–6851, 2020. [Online]. Available: https://arxiv.org/abs/2006.11239
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Generative Modeling by Estimating Gradients of the Data Distribution
Y. Song and S. Ermon, “Generative modeling by estimating gradients of the data distribution,”Advances in Neural Information Processing Systems, vol. 33, pp. 10 878–10 889, 2020. [Online]. Available: https://arxiv.org/abs/1907.05600
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Diffusion actor-critic with entropy regulator,
Y. Wang, L. Wang, Y. Jiang, W. Zou, T. Liu, X. Song, W. Wang, L. Xiao, J. Wu, J. Duan,et al., “Diffusion actor-critic with entropy regulator,”Advances in Neural Information Processing Systems, vol. 37, pp. 54 183–54 204, 2024
2024
-
[9]
A hybrid framework using diffusion policy and residual rl for force-sensitive robotic manip- ulation,
Y. Li, Q. Lyu, J. Yang, Y. Salam, and W. Wang, “A hybrid framework using diffusion policy and residual rl for force-sensitive robotic manip- ulation,”IEEE Robotics and Automation Letters, 2025
2025
-
[10]
Mp1: Meanflow tames policy learning in 1-step for robotic manipulation,
J. Sheng, Z. Wang, P. Li, and M. Liu, “Mp1: Meanflow tames policy learning in 1-step for robotic manipulation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 22, 2026, pp. 18 532– 18 539
2026
-
[11]
Memory-gated diffusion policy: Advancing robotic behaviour learning with memory- oriented architectures,
X. Huang, J. Hu, Q. Liu, G. Zhao, W. Deng, and W. Liu, “Memory-gated diffusion policy: Advancing robotic behaviour learning with memory- oriented architectures,”Knowledge-Based Systems, vol. 325, p. 113738, 2025
2025
-
[12]
Et-seed: Efficient trajectory-level se (3) equivariant diffusion policy,
C. Tie, Y. Chen, R. Wu, B. Dong, Z. Li, C. Gao, and H. Dong, “Et-seed: Efficient trajectory-level se (3) equivariant diffusion policy,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 60 114–60 132
2025
-
[13]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Un- terthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
2021
-
[14]
Masked visual pre-training for motor control.arXiv preprint arXiv:2203.06173, 2022
T. Xiao, I. Radosavovic, T. Darrell, and J. Malik, “Masked visual pre- training for motor control,”arXiv preprint arXiv:2203.06173, 2022
-
[15]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Y. J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V. Kumar, and A. Zhang, “Vip: Towards universal visual reward and representation via value- implicit pre-training,”arXiv preprint arXiv:2210.00030, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Where are we in the search for an artificial visual cortex for embodied intelligence?
A. Majumdar, K. Yadav, S. Arnaud, J. Ma, C. Chen, S. Silwal, A. Jain, V.-P. Berges, T. Wu, J. Vakil,et al., “Where are we in the search for an artificial visual cortex for embodied intelligence?”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[17]
Parameter-efficient transfer learning for NLP,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for NLP,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 2790–2799
2019
-
[18]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,”arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
The power of scale for parameter-efficient prompt tuning,
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” inProceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing, 2021, pp. 3045–3059
2021
-
[20]
Prefix-tuning: Optimizing continuous prompts for generation,
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics, 2021, pp. 4582–4597
2021
-
[21]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and Z. Chen, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”arXiv preprint arXiv:2101.03961, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bam- ford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressand,et al., “Mixtral of experts,”arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Generalizing motion planners with mixture of experts for autonomous driving,
Q. Sun, H. Wang, J. Zhan, F. Nie, X. Wen, L. Xu, K. Zhan, P. Jia, X. Lang, and H. Zhao, “Generalizing motion planners with mixture of experts for autonomous driving,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 6033–6039
2025
-
[25]
Drivemoe: Mixture-of-experts for vision-language-action model in end-to-end autonomous driving,
Z. Yang, Y. Chai, X. Jia, Q. Li, Y. Shao, X. Zhu, H. Su, and J. Yan, “Drivemoe: Mixture-of-experts for vision-language-action model in end-to-end autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 10 678–10 688
2026
-
[26]
Germ: A generalist robotic model with mixture-of-experts for quadruped robot,
W. Song, H. Zhao, P. Ding, C. Cui, S. Lyu, Y. Fan, and D. Wang, “Germ: A generalist robotic model with mixture-of-experts for quadruped robot,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 11 879–11 886
2024
-
[27]
B. Cheng, T. Liang, S. Huang, M. Shao, F. Zhang, B. Xu, Z. Xue, and H. Xu, “Moe-dp: An moe-enhanced diffusion policy for robust long-horizon robotic manipulation with skill decomposition and failure recovery,” 2025. [Online]. Available: https://arxiv.org/abs/2511.05007
-
[28]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine, “Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,” inConference on Robot Learning (CoRL). PMLR, 2020, pp. 1094–1100
2020
-
[29]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[30]
Visualizing data using t-sne,
L. v. d. Maaten and G. Hinton, “Visualizing data using t-sne,”Journal of machine learning research, vol. 9, no. Nov, pp. 2579–2605, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.