ASCII Art Turns LLMs into VLA Controllers
Pith reviewed 2026-06-26 14:30 UTC · model grok-4.3
The pith
A text-only LLM can serve as a VLA controller when images are rendered as ASCII art.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
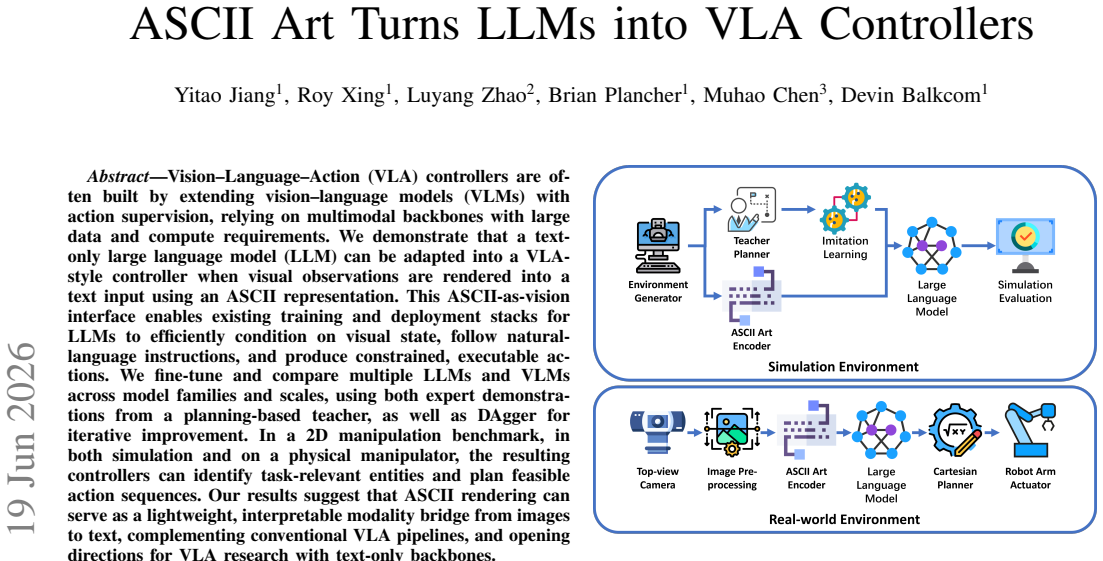
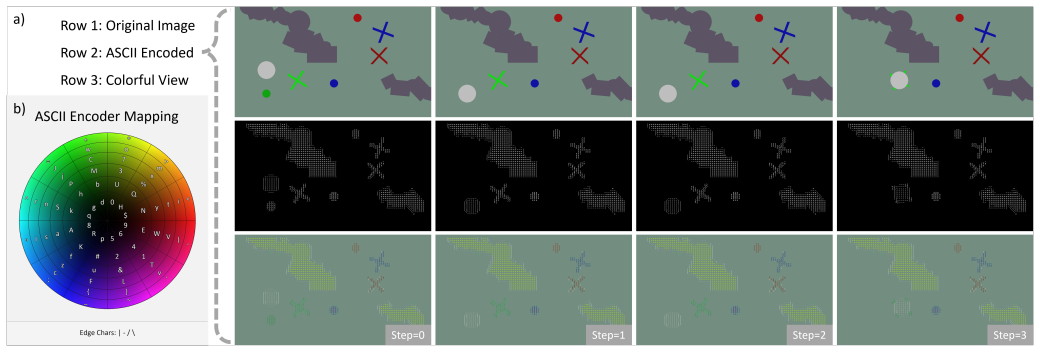
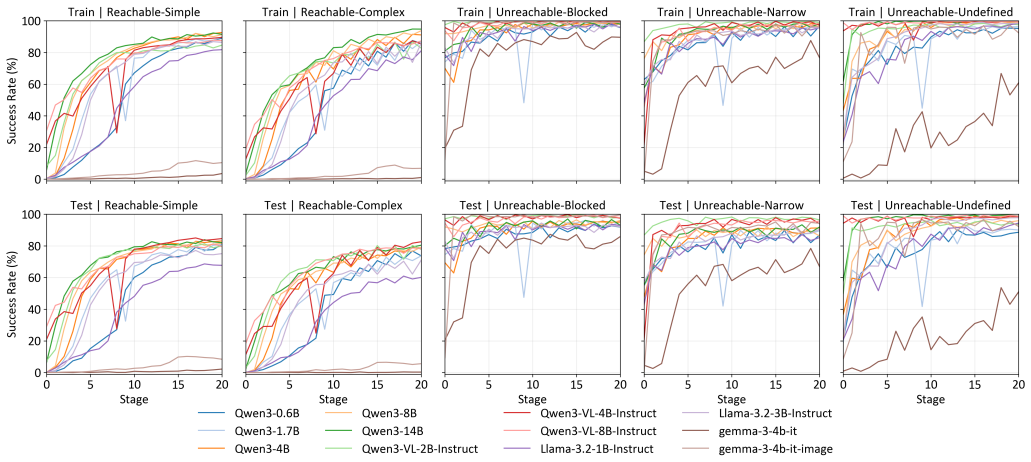
Rendering visual observations as ASCII art creates an interface that lets text-only LLMs condition on visual state, follow natural-language instructions, and produce constrained executable actions, enabling fine-tuning into VLA-style controllers without multimodal backbones.
What carries the argument
The ASCII-as-vision interface that converts images into text representations for direct input to LLMs.
If this is right
- Existing LLM training stacks can be used to adapt models for visual control tasks without new multimodal infrastructure.
- Controllers can process natural language instructions and output executable actions in both simulated and physical 2D manipulation settings.
- The method complements conventional VLA pipelines by providing a lightweight modality bridge from images to text.
- Iterative improvement is possible using techniques such as DAgger on top of expert demonstrations.
Where Pith is reading between the lines
- The same ASCII bridge might allow text-only models to handle other sensor data types that can be serialized into text.
- If ASCII representations prove sufficient for 2D tasks, they could be tested on tasks with higher spatial precision to measure the resolution limit.
- Combining ASCII input with existing LLM safety or constraint mechanisms could directly constrain robot actions without additional vision modules.
Load-bearing premise
ASCII rendering preserves enough spatial and object information for manipulation tasks without critical loss that would block feasible action planning.
What would settle it
A manipulation task in which critical details such as exact object positions or shapes are lost in the ASCII rendering, causing the model to output invalid action sequences.
Figures



read the original abstract
Vision--Language--Action (VLA) controllers are often built by extending vision--language models (VLMs) with action supervision, relying on multimodal backbones with large data and compute requirements. We demonstrate that a text-only large language model (LLM) can be adapted into a VLA-style controller when visual observations are rendered into a text input using an ASCII representation. This ASCII-as-vision interface enables existing training and deployment stacks for LLMs to efficiently condition on visual state, follow natural-language instructions, and produce constrained, executable actions. We fine-tune and compare multiple LLMs and VLMs across model families and scales, using both expert demonstrations from a planning-based teacher, as well as DAgger for iterative improvement. In a 2D manipulation benchmark, in both simulation and on a physical manipulator, the resulting controllers can identify task-relevant entities and plan feasible action sequences. Our results suggest that ASCII rendering can serve as a lightweight, interpretable modality bridge from images to text, complementing conventional VLA pipelines, and opening directions for VLA research with text-only backbones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that rendering visual observations as ASCII art enables fine-tuning of text-only LLMs into VLA-style controllers capable of following language instructions, identifying task-relevant entities, and generating executable actions for 2D manipulation tasks. It reports results using expert demonstrations and DAgger on a benchmark, with evaluation in both simulation and on a physical manipulator, positioning ASCII rendering as a lightweight modality bridge that avoids the need for multimodal VLM backbones.
Significance. If substantiated, the result would demonstrate a practical, low-overhead route for adapting existing LLM infrastructure to visual control problems, potentially lowering barriers to VLA research and offering an interpretable alternative to pixel-based or VLM-based pipelines. The approach could complement rather than replace conventional methods if it scales beyond the reported 2D setting.
major comments (3)
- [Abstract] Abstract: the central empirical claim of successful fine-tuning and real-robot deployment is stated without any quantitative metrics (success rates, trajectory errors, or comparisons), error bars, ablation results, or failure-case analysis, rendering the performance claims unverifiable from the provided text.
- [Abstract] Abstract and experimental description: no information-theoretic analysis, resolution study, or ablation on ASCII rendering parameters (grid size, character set, or preprocessing) is reported, which is load-bearing because the method's viability rests on the untested assumption that the lossy ASCII representation preserves sufficient spatial layout and object identity for feasible planning.
- [Experimental section] Experimental section: the use of DAgger for iterative improvement and comparison across model families is described at a high level, but without details on dataset sizes, training hyperparameters, action-space constraints, or how failures in entity identification were measured, it is impossible to assess whether the reported success stems from the ASCII interface or from the simplicity of the 2D benchmark scenes.
minor comments (2)
- [Abstract] The abstract and title use the term "VLA controllers" without an explicit definition or comparison to standard VLA formulations in the literature, which could be clarified for readers unfamiliar with the subfield.
- No mention of reproducibility artifacts (code, rendering scripts, or benchmark environments) is present in the provided text, which would strengthen the contribution if added.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to improve verifiability and detail in the manuscript. We address each major comment below, indicating revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of successful fine-tuning and real-robot deployment is stated without any quantitative metrics (success rates, trajectory errors, or comparisons), error bars, ablation results, or failure-case analysis, rendering the performance claims unverifiable from the provided text.
Authors: We agree the abstract would benefit from explicit metrics. The revised abstract now includes key quantitative results from our experiments (success rates in simulation and on hardware, with comparisons to baselines), along with pointers to ablations and failure-case analysis in the main text and supplementary material. This makes the central claims verifiable without exceeding length constraints. revision: yes
-
Referee: [Abstract] Abstract and experimental description: no information-theoretic analysis, resolution study, or ablation on ASCII rendering parameters (grid size, character set, or preprocessing) is reported, which is load-bearing because the method's viability rests on the untested assumption that the lossy ASCII representation preserves sufficient spatial layout and object identity for feasible planning.
Authors: The original manuscript provides empirical validation through task performance but lacks systematic parameter ablations. We have added a dedicated subsection with resolution studies and ablations on grid size, character set, and preprocessing, demonstrating their effects on entity identification and planning success. While a formal information-theoretic analysis is not included (due to the discrete, non-probabilistic nature of ASCII rendering), the empirical results across varied parameters substantiate that sufficient spatial and identity information is preserved for the 2D tasks considered. revision: partial
-
Referee: [Experimental section] Experimental section: the use of DAgger for iterative improvement and comparison across model families is described at a high level, but without details on dataset sizes, training hyperparameters, action-space constraints, or how failures in entity identification were measured, it is impossible to assess whether the reported success stems from the ASCII interface or from the simplicity of the 2D benchmark scenes.
Authors: We have expanded the experimental section with the requested details: dataset sizes (number of expert demonstrations and DAgger iterations), full training hyperparameters, explicit action-space constraints, and the protocol for measuring entity identification failures (via per-step logging against ground-truth object positions). These additions clarify the contribution of the ASCII interface and allow readers to evaluate generalization beyond the benchmark simplicity. revision: yes
Circularity Check
No circularity; empirical demonstration rests on experiments, not derivations or self-referential fits
full rationale
The paper presents an empirical adaptation of text-only LLMs to VLA-style control via ASCII rendering of visual observations, validated through fine-tuning on expert demonstrations and DAgger, then evaluated on a 2D manipulation benchmark in simulation and on hardware. No equations, mathematical derivations, or parameter-fitting steps are described that could reduce a claimed prediction to its inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim is supported by reported experimental outcomes rather than any self-definitional or fitted-input logic, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale,
A. Brohanet al., “RT-1: Robotics Transformer for Real-World Control at Scale,” inRobotics: Science and Systems XIX. Robotics: Science and Systems Foundation, Jul 2023
2023
-
[2]
J. Chenet al., “NanoVLA: Routing Decoupled Vision-Language Un- derstanding for Nano-sized Generalist Robotic Policies,” Oct 2025, arXiv:2510.25122
-
[3]
Reducing the Barrier to Entry of Complex Robotic Software: a MoveIt! Case Study
D. Colemanet al., “Reducing the Barrier to Entry of Complex Robotic Software: a MoveIt! Case Study,” Apr 2014, arXiv:1404.3785
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[4]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
O. X.-E. Collaborationet al., “Open X-Embodiment: Robotic Learning Datasets and RT-X Models,” May 2025, arXiv:2310.08864
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
PaLM-E: An Embodied Multimodal Language Model,
D. Driesset al., “PaLM-E: An Embodied Multimodal Language Model,” inProceedings of the 40th International Conference on Machine Learn- ing. PMLR, Jul 2023, pp. 8469–8488, ISSN: 2640-3498
2023
-
[6]
Octo: An Open-Source Generalist Robot Policy,
D. Ghoshet al., “Octo: An Open-Source Generalist Robot Policy,” in Robotics: Science and Systems XX. Robotics: Science and Systems Foundation, Jul 2024
2024
-
[7]
Good old-fashioned engineering can close the 100,000- year “data gap
K. Goldberg, “Good old-fashioned engineering can close the 100,000- year “data gap” in robotics,”Science Robotics, vol. 10, no. 105, p. eaea7390, Aug 2025, publisher: American Association for the Advance- ment of Science
2025
-
[8]
A formal basis for the heuristic determination of minimum cost paths,
P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,”IEEE Transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968
1968
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Huet al., “LoRA: Low-Rank Adaptation of Large Language Models,” Oct 2021, arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huanget al., “V oxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models,” Nov 2023, arXiv:2307.05973
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
ASCIIEval: Benchmarking Models’ Visual Perception in Text Strings via ASCII Art,
Q. Jiaet al., “ASCIIEval: Benchmarking Models’ Visual Perception in Text Strings via ASCII Art,” Sep 2025, arXiv:2410.01733 [cs]
-
[12]
Exploring Spontaneous Social Interaction Swarm Robotics Powered by Large Language Models,
Y . Jianget al., “Exploring Spontaneous Social Interaction Swarm Robotics Powered by Large Language Models,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct 2025, pp. 10 198–10 205, ISSN: 2153-0866
2025
-
[13]
VIMA: Robot Manipulation with Multimodal Prompts,
——, “VIMA: Robot Manipulation with Multimodal Prompts,” inPro- ceedings of the 40th International Conference on Machine Learning. PMLR, Jul 2023, pp. 14 975–15 022, ISSN: 2640-3498
2023
-
[14]
Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications,
K. Kawaharazukaet al., “Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications,”IEEE Access, vol. 13, pp. 162 467–162 504, 2025, arXiv:2510.07077
-
[15]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kimet al., “OpenVLA: An Open-Source Vision-Language-Action Model,” Sep 2024, arXiv:2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Optimization-based locomotion planning, esti- mation, and control design for the atlas humanoid robot,
S. Kuindersmaet al., “Optimization-based locomotion planning, esti- mation, and control design for the atlas humanoid robot,”Autonomous Robots, vol. 40, no. 3, pp. 429–455, Mar 2016
2016
-
[17]
Code as Policies: Language Model Programs for Embodied Control
J. Lianget al., “Code as Policies: Language Model Programs for Embodied Control,” May 2023, arXiv:2209.07753
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
ASCIIBench: Evaluating Language-Model-Based Under- standing of Visually-Oriented Text,
K. Luoet al., “ASCIIBench: Evaluating Language-Model-Based Under- standing of Visually-Oriented Text,” Dec 2025, arXiv:2512.04125 [cs]
-
[19]
GRID: Scene-Graph-based Instruction-driven Robotic Task Planning,
Z. Niet al., “GRID: Scene-Graph-based Instruction-driven Robotic Task Planning,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct 2024, pp. 13 765–13 772, ISSN: 2153- 0866
2024
-
[20]
SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning,
K. Ranaet al., “SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning,” Sep 2023, arXiv:2307.06135
-
[21]
Flower: Democratizing generalist robot policies with efficient vision-language-action flow policies,
M. Reusset al., “FLOWER: Democratizing Generalist Robot Poli- cies with Efficient Vision-Language-Action Flow Policies,” Sep 2025, arXiv:2509.04996
-
[22]
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning,
S. Ross, G. Gordon, and D. Bagnell, “A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning,” inProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Jun 2011, pp. 627–635, ISSN: 1938-7228. [Online]. Available: https://proceedings.mlr.pr...
2011
-
[23]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukoret al., “SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics,” Jun 2025, arXiv:2506.01844
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
CERBERUS in the DARPA Subterranean Chal- lenge,
M. Tranzattoet al., “CERBERUS in the DARPA Subterranean Chal- lenge,”Science Robotics, vol. 7, no. 66, p. eabp9742, May 2022, publisher: American Association for the Advancement of Science
2022
-
[25]
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Q. Zhaoet al., “CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models,” Mar 2025, arXiv:2503.22020
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control,
B. Zitkovichet al., “RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control,” inProceedings of The 7th Con- ference on Robot Learning. PMLR, Dec 2023, pp. 2165–2183, ISSN: 2640-3498
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.