What Do Lorentz-Equivariant Jet Taggers Learn?
Pith reviewed 2026-06-26 14:12 UTC · model grok-4.3
The pith
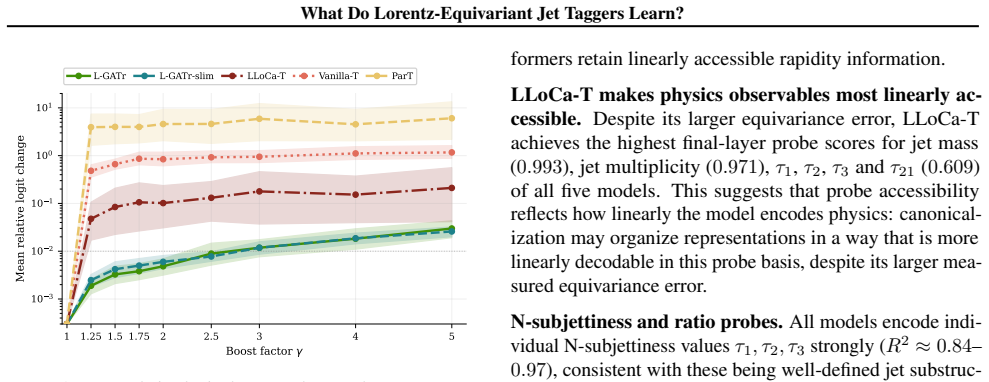
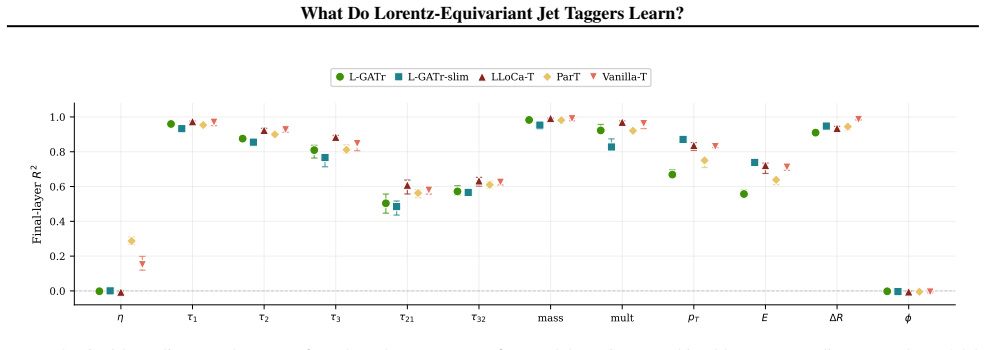
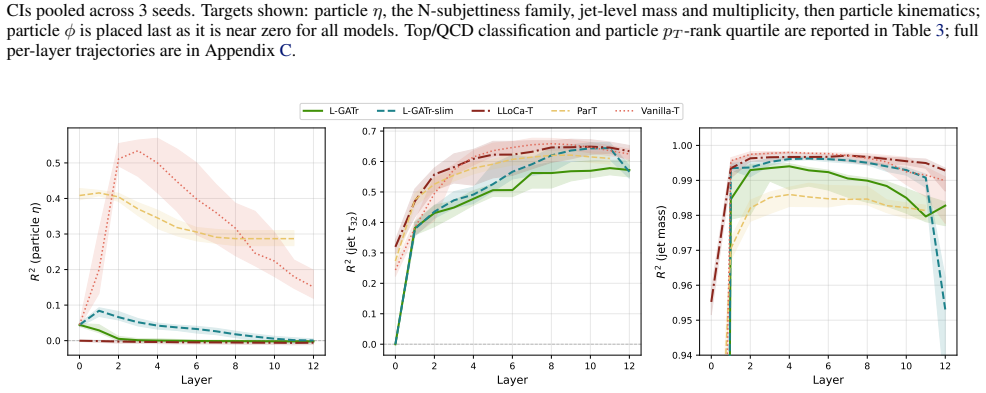
Lorentz-equivariant jet taggers suppress frame-dependent pseudorapidity while encoding jet mass and N-subjettiness strongly through vector channels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
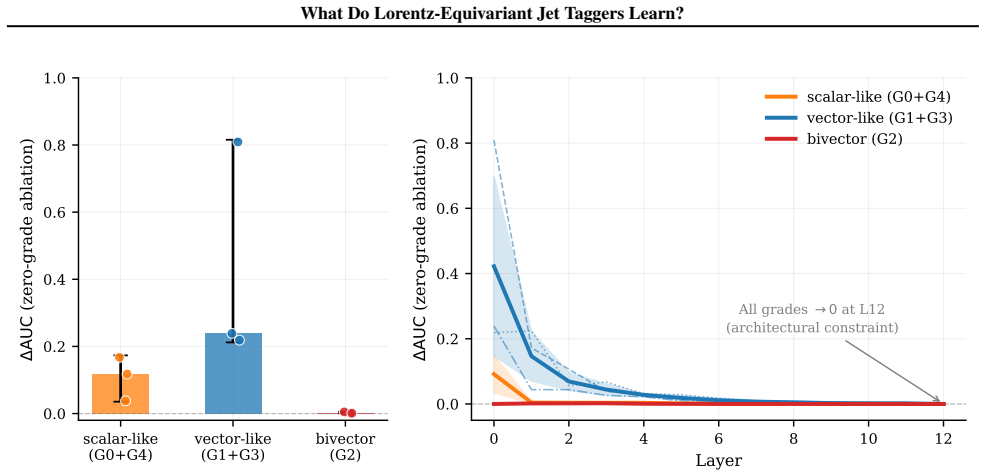
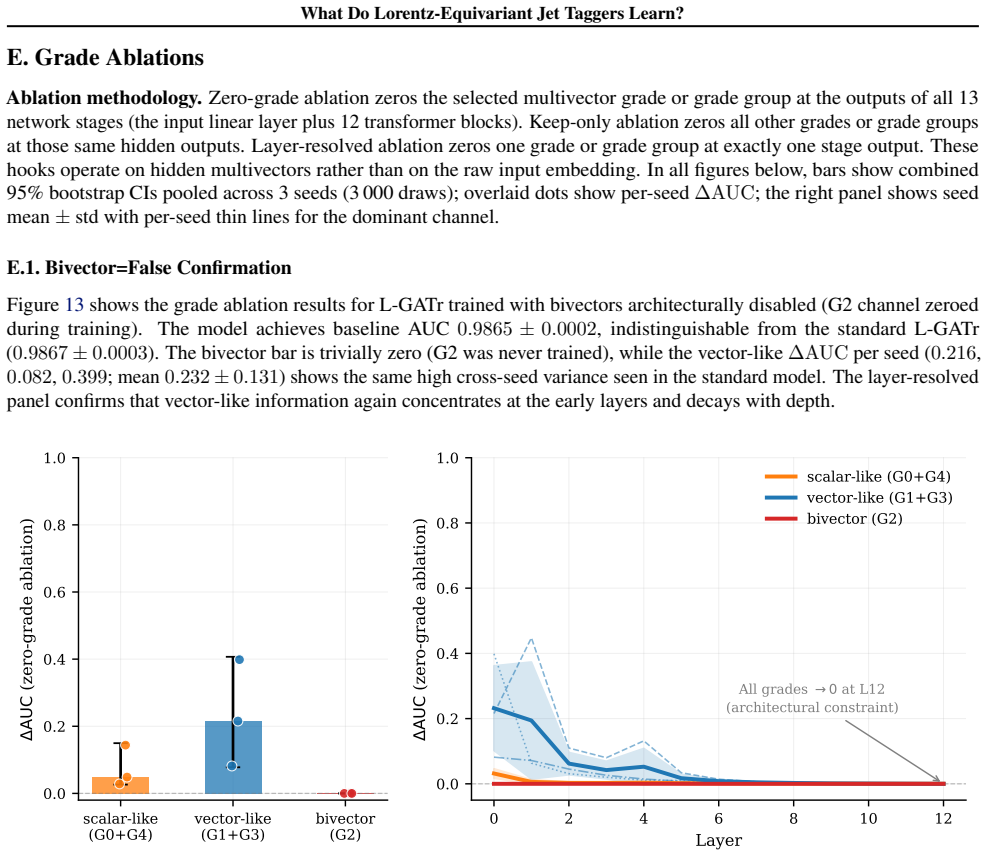
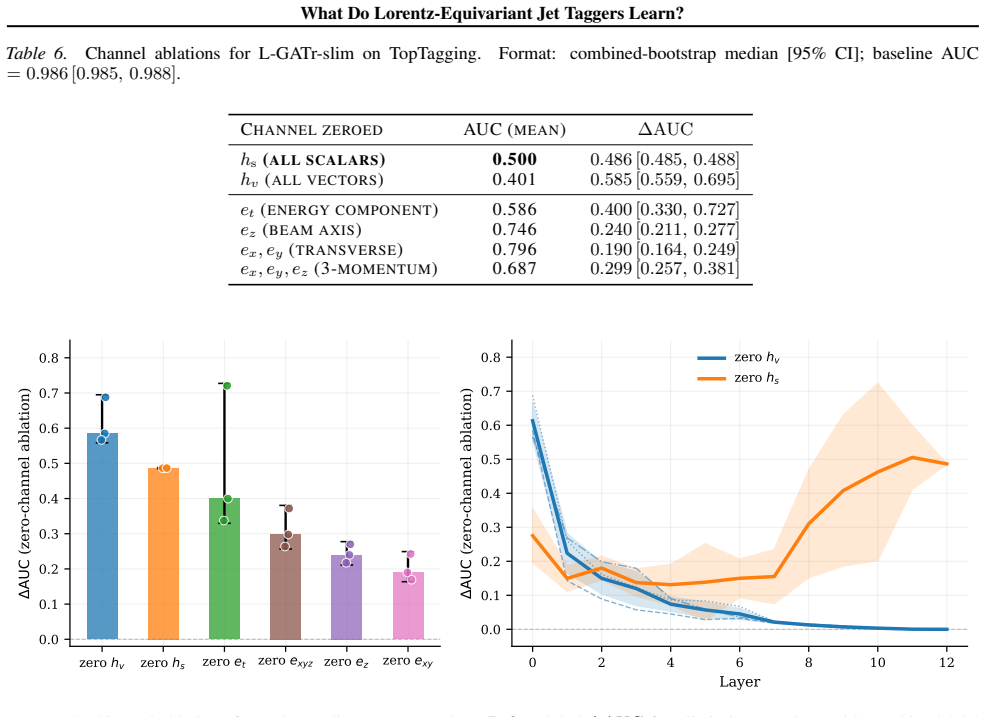
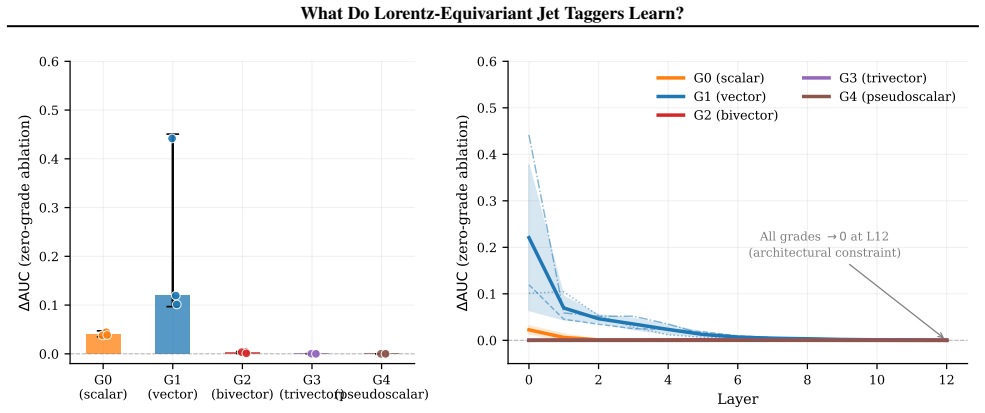
Linear probes demonstrate that equivariant models suppress frame-dependent pseudorapidity to zero while encoding jet mass and N-subjettiness strongly; grade ablations on L-GATr show bivector channels are negligible for top-quark tagging while vector-like channels are dominant but seed variable, indicating the network exploits multiple representational pathways.
What carries the argument
Linear probes and grade ablations applied to Lorentz-equivariant models such as L-GATr, L-GATr-slim and LLoCa-T.
If this is right
- Equivariant models achieve frame invariance by nulling out pseudorapidity dependence in their learned features.
- Jet mass and N-subjettiness serve as the primary physical observables carrying discriminative information for top tagging.
- Vector-like channels provide the dominant representational pathway while bivector channels add little value for this task.
- The presence of multiple pathways suggests the network maintains robustness through redundant feature extraction.
Where Pith is reading between the lines
- The observed channel selectivity could motivate simplified architectures that drop bivector components for jet-tagging tasks without loss of accuracy.
- Similar linear-probe and ablation techniques could be applied to other symmetry-equivariant models to map which observables survive the symmetry constraints.
- The results raise the question of whether the same suppression of frame-dependent variables occurs in equivariant models trained on different collider observables.
- If vector dominance generalizes, training procedures might explicitly regularize toward vector representations to improve sample efficiency.
Load-bearing premise
Linear probes and grade ablations fully capture the discriminative information learned by the models without missing non-linear encodings or interactions between channels.
What would settle it
A concrete experiment would be to train a non-linear probe on the same activations and observe whether it recovers significant pseudorapidity signal or bivector contributions that linear methods missed, or to measure tagging performance after explicitly zeroing vector channels versus bivector channels.
Figures
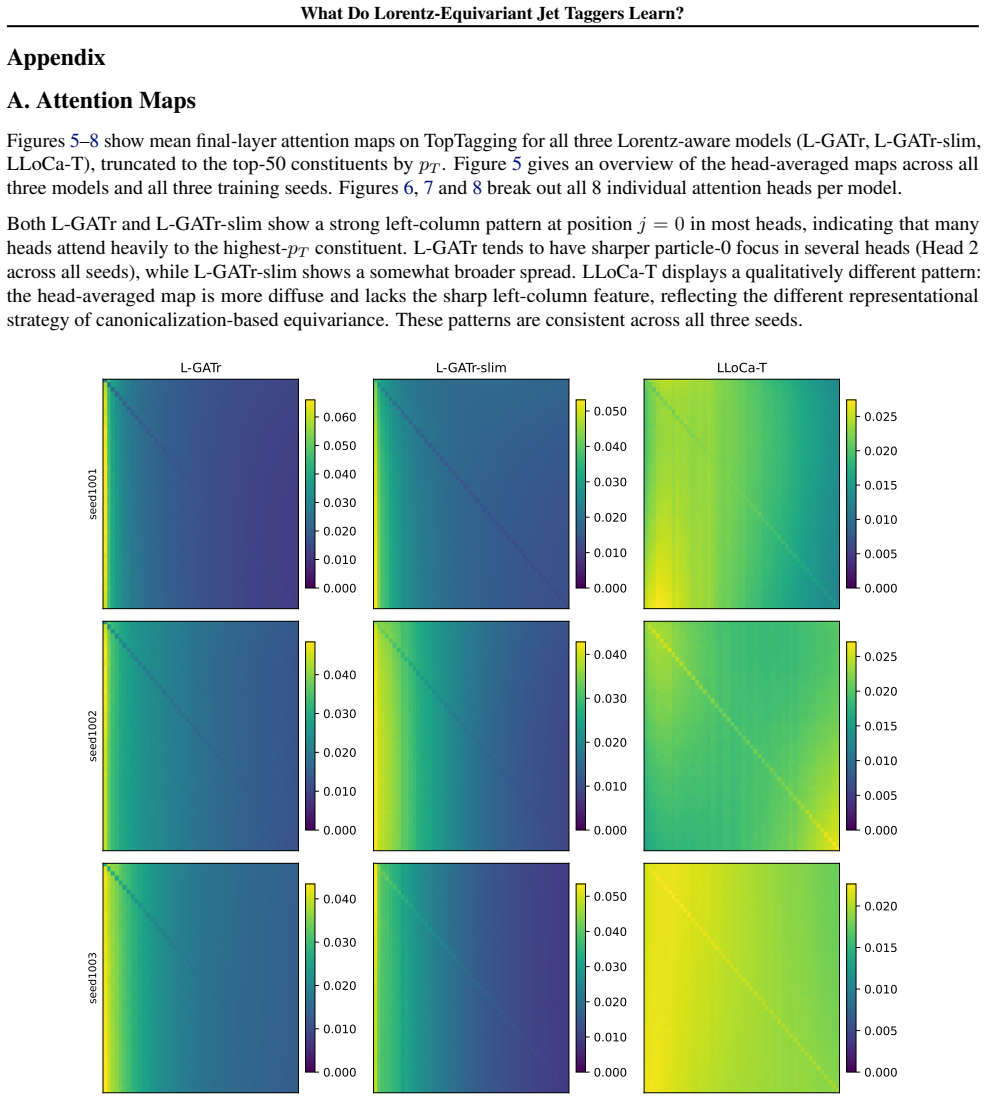
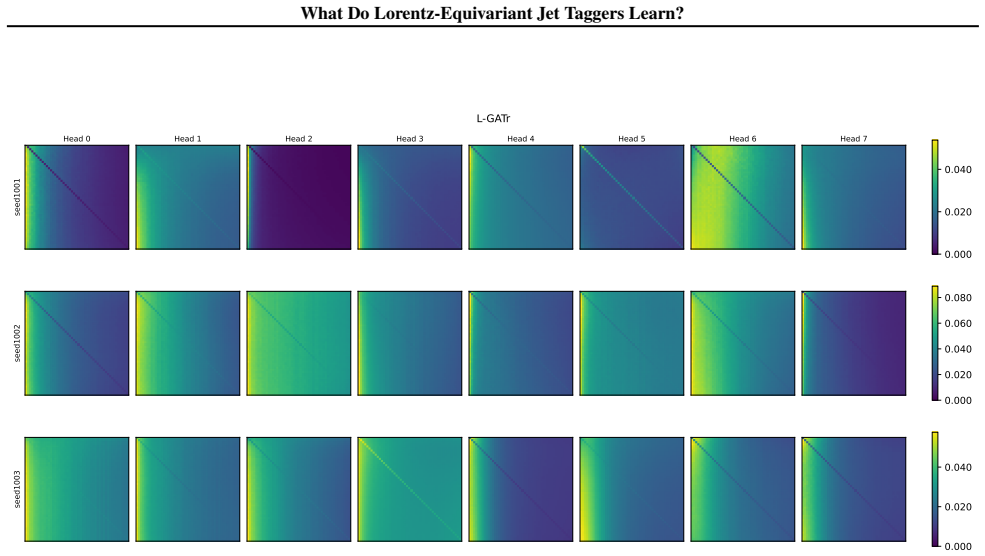
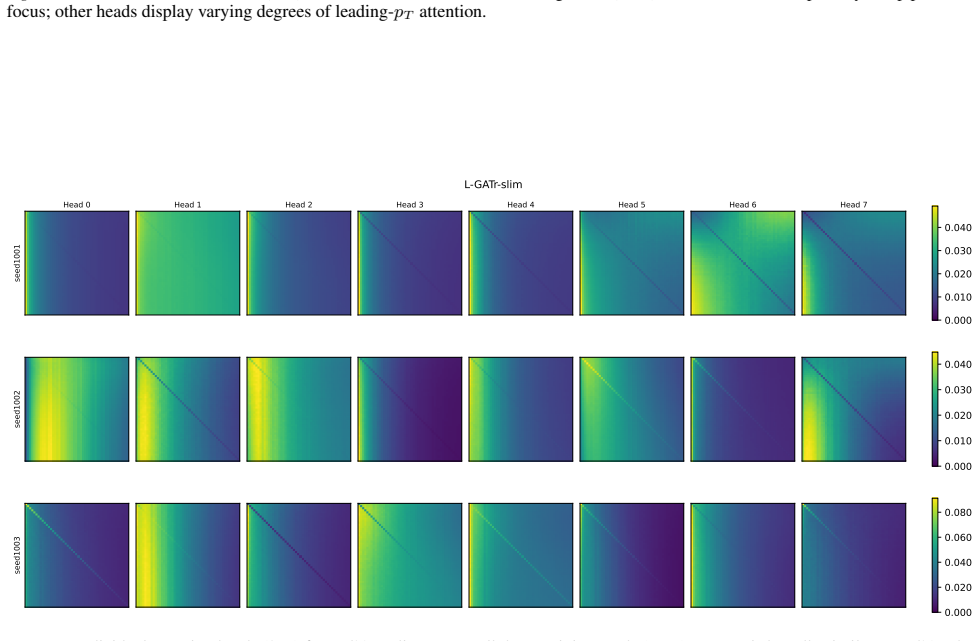
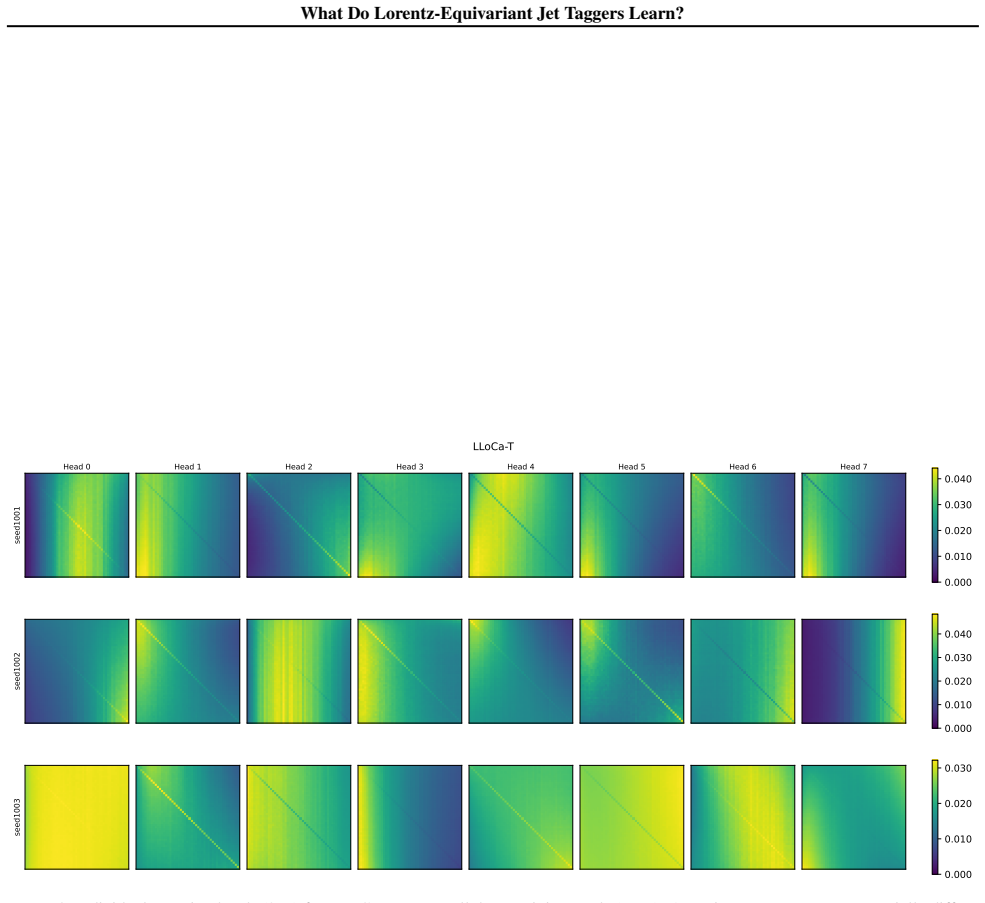
read the original abstract
We study what Lorentz-equivariant jet taggers learn internally, using equivariance tests, linear probes and grade ablations across five models including L-GATr, L-GATr-slim and LLoCa-T. Linear probes show that equivariant models suppress frame-dependent pseudorapidity to zero while encoding jet mass and N-subjettiness strongly. Grade ablations on L-GATr reveal that bivector channels are negligible for top-quark tagging while vector-like channels are dominant but seed variable, consistent with the network exploiting multiple representational pathways. These results characterize which physical features and algebraic grade structures carry discriminative information in equivariant taggers and may inform future development of such models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies the internal representations learned by Lorentz-equivariant jet taggers (L-GATr, L-GATr-slim, LLoCa-T and two others) via equivariance tests, linear probes and grade ablations. It reports that equivariant models suppress frame-dependent pseudorapidity to zero while strongly encoding jet mass and N-subjettiness, and that grade ablations on L-GATr show bivector channels to be negligible for top-quark tagging while vector-like channels dominate but are seed-variable, consistent with multiple representational pathways.
Significance. If the empirical measurements are robust, the work would usefully characterize which physical observables and algebraic grades carry discriminative information in equivariant jet taggers and could guide future architecture choices. The study performs direct empirical measurements on already-trained models using standard tools, which is a methodological strength.
major comments (2)
- [linear probes section] The linear-probe results (suppression of pseudorapidity, strong encoding of mass and N-subjettiness) are presented without details on training procedure, data splits, statistical controls, error estimation or hyperparameter selection; this information is required to establish that the reported quantities are not sensitive to post-hoc analysis choices.
- [grade ablations on L-GATr] Grade ablations on L-GATr conclude that bivector channels are negligible while vector channels dominate; because the paper itself remarks on 'multiple representational pathways,' the ablations (performed linearly and in isolation) may miss non-linear cross-grade interactions that could alter the interpretation of channel dominance.
minor comments (1)
- The abstract should explicitly list all five models examined and state the precise tagging task (top-quark vs. QCD).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript to incorporate additional details and clarifications where appropriate.
read point-by-point responses
-
Referee: [linear probes section] The linear-probe results (suppression of pseudorapidity, strong encoding of mass and N-subjettiness) are presented without details on training procedure, data splits, statistical controls, error estimation or hyperparameter selection; this information is required to establish that the reported quantities are not sensitive to post-hoc analysis choices.
Authors: We agree that the linear-probe results require more detailed documentation to ensure robustness and reproducibility. In the revised manuscript, we will add a new subsection in the methods or results detailing: the probe training procedure (including optimizer, learning rate, epochs, and regularization), data splits (using the standard jet tagging train/validation/test partitions with probes trained on training data and evaluated on test data), statistical controls (averaging over multiple random seeds for probe training), error estimation (reporting mean and standard deviation across seeds), and hyperparameter selection (e.g., via validation set). These additions will confirm that the observed suppression of pseudorapidity and strong encoding of mass and N-subjettiness are stable and insensitive to post-hoc choices. revision: yes
-
Referee: [grade ablations on L-GATr] Grade ablations on L-GATr conclude that bivector channels are negligible while vector channels dominate; because the paper itself remarks on 'multiple representational pathways,' the ablations (performed linearly and in isolation) may miss non-linear cross-grade interactions that could alter the interpretation of channel dominance.
Authors: We acknowledge the referee's observation that our remark on multiple representational pathways (evidenced by seed-variable vector channel importance) raises the possibility of non-linear cross-grade interactions not captured by linear, isolated ablations. However, the linear ablations provide a direct and standard measure of each grade's isolated contribution, and the negligible bivector role is consistent across seeds. Exploring non-linear interactions would require more advanced methods (e.g., non-linear probes on grade combinations) beyond the scope of this empirical characterization study. In the revision, we will add a discussion paragraph noting this limitation while maintaining that the linear results still validly indicate grade dominance for top tagging. revision: partial
Circularity Check
No circularity: empirical measurements on trained models
full rationale
The paper reports results from equivariance tests, linear probes, and grade ablations applied to already-trained Lorentz-equivariant jet taggers (L-GATr, LLoCa-T, etc.). These are standard post-training diagnostic tools with no derivations, equations, or fitted parameters that reduce reported findings (e.g., pseudorapidity suppression or channel dominance) to quantities defined or optimized within the same analysis. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The analysis is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes attached to model layers extract the primary discriminative features learned during training
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume =
Brehmer, Johann and de Haan, Pim and Behrends, S. Advances in Neural Information Processing Systems , volume =. 2023 , note =
2023
-
[2]
Advances in Neural Information Processing Systems , volume =
Spinner, Jonas and Bres. Advances in Neural Information Processing Systems , volume =. 2024 , note =
2024
-
[4]
, booktitle =
Spinner, Jonas and Favaro, Luigi and Lippmann, Peter and Pitz, Sebastian and Gerhartz, Gerrit and Plehn, Tilman and Hamprecht, Fred A. , booktitle =. 2025 , note =
2025
-
[5]
2022 , note =
Qu, Huilin and Li, Congqiao and Qian, Sitian , booktitle =. 2022 , note =
2022
-
[6]
and Hammad, A
Esmail, W. and Hammad, A. and Nojiri, M. , journal =. 2026 , note =
2026
-
[7]
and Duarte, Javier , booktitle =
Wang, Aaron and Gandrakota, Abhijith and Ngadiuba, Jennifer and Sahu, Vivekanand and Bhatnagar, Priyansh and Khoda, Elham E. and Duarte, Javier , booktitle =. 2024 , note =
2024
-
[8]
and Ngadiuba, Jennifer and Duarte, Javier and Cavanaugh, Richard , booktitle =
Legge, Timothy and Wang, Aaron and Ortiz, Jacob and Limouzi, Victor and Zhao, Zihan and Gandrakota, Abhijith and Khoda, Elham E. and Ngadiuba, Jennifer and Duarte, Javier and Cavanaugh, Richard , booktitle =. 2025 , note =
2025
-
[9]
and Plehn, T
Kasieczka, G. and Plehn, T. and Butter, A. and Cranmer, K. and Debnath, D. and Dillon, B. M. and others , journal =. 2019 , note =
2019
-
[10]
2018 , note =
Butter, Anja and Kasieczka, Gregor and Plehn, Tilman and Russell, Michael , journal =. 2018 , note =
2018
-
[11]
2011 , note =
Thaler, Jesse and Van Tilburg, Ken , journal =. 2011 , note =
2011
-
[12]
2019 , note =
Cheng, Taoli , booktitle =. 2019 , note =
2019
-
[13]
2019 , note =
Kornblith, Simon and Norouzi, Mohammad and Lee, Honglak and Hinton, Geoffrey , booktitle =. 2019 , note =
2019
-
[14]
Brehmer, J., de Haan, P., Behrends, S., and Cohen, T. Geometric Algebra Transformer . In Advances in Neural Information Processing Systems, volume 36, 2023. arXiv:2305.18415
arXiv 2023
-
[15]
Deep-learned Top Tagging with a Lorentz Layer
Butter, A., Kasieczka, G., Plehn, T., and Russell, M. Deep-learned Top Tagging with a Lorentz Layer . SciPost Physics, 5: 0 028, 2018. arXiv:1707.08966
Pith/arXiv arXiv 2018
-
[16]
Interpretability Study on Deep Learning for Jet Physics at the Large Hadron Collider
Cheng, T. Interpretability Study on Deep Learning for Jet Physics at the Large Hadron Collider . In Machine Learning and the Physical Sciences Workshop, NeurIPS, 2019. arXiv:1911.01872
arXiv 2019
-
[17]
IAFormer: Interaction-Aware Transformer network for collider data analysis
Esmail, W., Hammad, A., and Nojiri, M. IAFormer: Interaction-Aware Transformer network for collider data analysis . SciPost Physics, 20: 0 108, 2026. arXiv:2505.03258
Pith/arXiv arXiv 2026
- [18]
-
[19]
Similarity of Neural Network Representations Revisited
Kornblith, S., Norouzi, M., Lee, H., and Hinton, G. Similarity of Neural Network Representations Revisited . In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp.\ 3519--3529, 2019. arXiv:1905.00414
Pith/arXiv arXiv 2019
-
[20]
E., Ngadiuba, J., Duarte, J., and Cavanaugh, R
Legge, T., Wang, A., Ortiz, J., Limouzi, V., Zhao, Z., Gandrakota, A., Khoda, E. E., Ngadiuba, J., Duarte, J., and Cavanaugh, R. Why Is Attention Sparse In Particle Transformer? In Machine Learning and the Physical Sciences Workshop, NeurIPS, 2025. arXiv:2512.00210
arXiv 2025
-
[21]
Economical Jet Taggers -- Equivariant, Slim, and Quantized
Petitjean, A., Plehn, T., Spinner, J., and K \"o the, U. Economical Jet Taggers -- Equivariant, Slim, and Quantized . arXiv preprint arXiv:2512.17011, 2025. arXiv:2512.17011
arXiv 2025
-
[22]
Particle Transformer for Jet Tagging
Qu, H., Li, C., and Qian, S. Particle Transformer for Jet Tagging . In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pp.\ 18281--18292, 2022. arXiv:2202.03772
arXiv 2022
-
[23]
Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics
Spinner, J., Bres \'o , V., de Haan, P., Plehn, T., Thaler, J., and Brehmer, J. Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics . In Advances in Neural Information Processing Systems, volume 38, 2024. arXiv:2405.14806
arXiv 2024
-
[24]
Spinner, J., Favaro, L., Lippmann, P., Pitz, S., Gerhartz, G., Plehn, T., and Hamprecht, F. A. Lorentz Local Canonicalization: How to Make Any Network Lorentz-Equivariant . In Advances in Neural Information Processing Systems, 2025. arXiv:2505.20280
arXiv 2025
-
[25]
Thaler, J. and Van Tilburg, K. Identifying Boosted Objects with N-subjettiness . Journal of High Energy Physics, 2011: 0 015, 2011. arXiv:1011.2268
Pith/arXiv arXiv 2011
-
[26]
Wang, A., Gandrakota, A., Ngadiuba, J., Sahu, V., Bhatnagar, P., Khoda, E. E., and Duarte, J. Interpreting Transformers for Jet Tagging . In Machine Learning and the Physical Sciences Workshop, NeurIPS, 2024. arXiv:2412.03673
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.