Orthogonal Representation Editing: Decoupling Semantic Entanglement in Batch Knowledge Editing of LLMs
Pith reviewed 2026-06-26 10:10 UTC · model grok-4.3
The pith
Orthogonal constraints on edit vectors in hidden representations decouple semantic entanglement for batch LLM knowledge editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
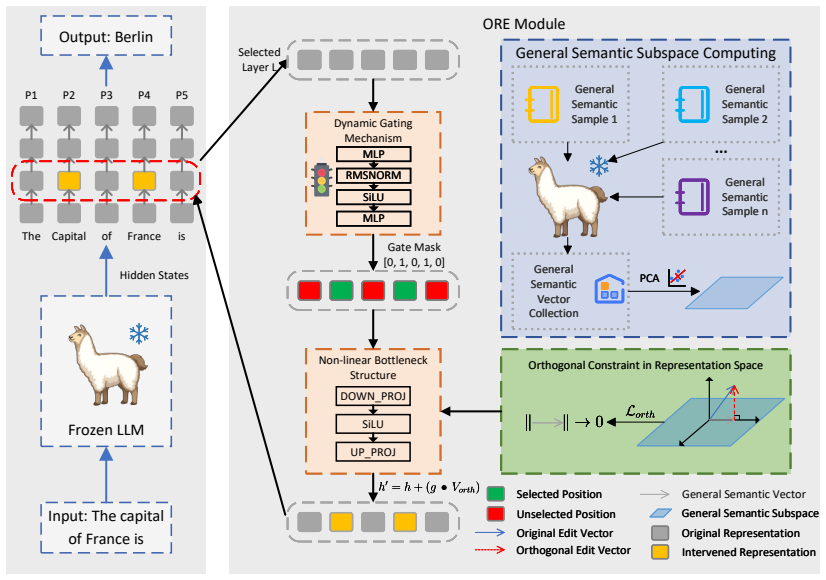
ORE performs edits in the hidden representation space of LLMs by constructing a general semantic subspace and enforcing orthogonal constraints on edit vectors, effectively decoupling semantic entanglement, and introduces a gated non-linear representation head for adaptive editing locations and precise control over knowledge injection.
What carries the argument
Orthogonal constraints on edit vectors inside a constructed general semantic subspace of the LLM hidden representations, which separate overlapping semantic signals.
If this is right
- Batch knowledge editing maintains higher precision when multiple facts are updated at once.
- Cross-lingual knowledge editing reaches stronger results than previous methods.
- Knowledge injection occurs with finer location control through the gated head.
- Overall editing success improves relative to existing batch techniques without requiring full retraining.
Where Pith is reading between the lines
- The same subspace-plus-orthogonality pattern could be tested on sequential editing pipelines to see whether it reduces cumulative drift.
- If the decoupling holds, larger batch sizes might become feasible before interference reappears.
- The gated head mechanism might transfer to other representation-level interventions such as targeted fine-tuning steps.
Load-bearing premise
Semantic representation entanglement is the main source of interference that degrades batch editing performance, and orthogonal constraints plus a gated head can separate those signals without creating fresh interference or harming unrelated model behavior.
What would settle it
A controlled comparison in which edit vectors are made orthogonal yet batch editing accuracy and interference metrics show no improvement over a non-orthogonal baseline using the same subspace and head.
Figures


read the original abstract
Knowledge editing aims to efficiently update factual information in Large Language Models (LLMs) without full retraining. However, existing methods still suffer from performance degradation in batch knowledge editing. We identify that semantic representation entanglement, such as overlapping concepts and shared syntactic patterns, accumulates interference in the representation space and reduces editing precision. To bridge this gap, in this paper, we propose Orthogonal Representation Editing (ORE), which performs edits in the hidden representation space of LLMs by constructing a general semantic subspace and enforcing orthogonal constraints on edit vectors, effectively decoupling semantic entanglement. Furthermore, we introduce a gated non-linear representation head to enable adaptive learning of editing locations and precise control over knowledge injection. Extensive experiments show that ORE outperforms existing methods and achieves superior performance in cross-lingual knowledge editing scenarios. We release our code at https://github.com/YVVH/ORE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that semantic representation entanglement (overlapping concepts and shared syntactic patterns) accumulates interference and degrades performance in batch knowledge editing of LLMs. It proposes Orthogonal Representation Editing (ORE), which performs edits in the hidden representation space by constructing a general semantic subspace, enforcing orthogonal constraints on edit vectors to decouple entanglement, and adding a gated non-linear representation head for adaptive editing locations and precise knowledge injection. The method is asserted to outperform prior approaches and achieve superior results in cross-lingual editing scenarios.
Significance. If the central claims hold with rigorous empirical support, the work could advance batch knowledge editing by offering a representation-space mechanism to reduce cross-edit interference via orthogonality, with potential benefits for maintaining unrelated capabilities. The public code release supports reproducibility.
major comments (3)
- [Abstract] Abstract: the claims of outperformance and 'superior performance in cross-lingual knowledge editing scenarios' are stated without any quantitative results, ablation studies, error bars, tables, or statistical details, so the central performance assertions cannot be evaluated from the manuscript text.
- [Introduction/Method] Introduction/Method description: the premise that semantic entanglement is the dominant cause of degradation (rather than optimization conflicts or capacity limits) is asserted but not supported by any measurement of entanglement, isolation experiment, or control that isolates the effect of the orthogonal constraints and gated head from generic regularization or capacity benefits.
- [Experiments] Experiments section (implied by abstract claims): no tables, figures, or specific results are supplied to demonstrate that the orthogonality mechanism plus gating reduces cross-edit interference while preserving unrelated capabilities, which is load-bearing for the headline claims.
minor comments (1)
- [Abstract] The code repository link is provided, which aids reproducibility; the abstract could briefly note the models and datasets used to contextualize the cross-lingual results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and support for the claims where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of outperformance and 'superior performance in cross-lingual knowledge editing scenarios' are stated without any quantitative results, ablation studies, error bars, tables, or statistical details, so the central performance assertions cannot be evaluated from the manuscript text.
Authors: We agree the abstract is high-level by design. The full manuscript's Experiments section provides the requested quantitative results, tables, figures, ablations, and error bars. We will revise the abstract to include one or two key numerical highlights (e.g., relative gains on batch editing metrics) while remaining within length limits. revision: yes
-
Referee: [Introduction/Method] Introduction/Method description: the premise that semantic entanglement is the dominant cause of degradation (rather than optimization conflicts or capacity limits) is asserted but not supported by any measurement of entanglement, isolation experiment, or control that isolates the effect of the orthogonal constraints and gated head from generic regularization or capacity benefits.
Authors: The premise is motivated by observed interference patterns in batch editing, but we acknowledge the absence of a direct entanglement metric or isolation control. The orthogonal constraints and gated head are validated via targeted ablations in the experiments. We will add a short analysis subsection with a simple entanglement proxy (e.g., cosine similarity of edit vectors) and an isolation experiment to better separate the contribution of orthogonality from generic regularization. revision: partial
-
Referee: [Experiments] Experiments section (implied by abstract claims): no tables, figures, or specific results are supplied to demonstrate that the orthogonality mechanism plus gating reduces cross-edit interference while preserving unrelated capabilities, which is load-bearing for the headline claims.
Authors: The Experiments section does contain tables and figures with batch and cross-lingual results plus ablations. If the reviewed version omitted these, we will ensure the next version clearly presents all tables/figures with error bars, statistical tests, and explicit discussion of interference reduction (via before/after edit vector orthogonality metrics) and capability preservation. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description contain no equations, quantitative derivations, or self-citations that could reduce claims to inputs by construction. The paper identifies semantic entanglement as an issue and proposes ORE (general semantic subspace + orthogonal constraints + gated head) as a solution, with performance claims resting on experimental results rather than any self-referential math or fitted-parameter renaming. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Knowledge Decoupling via Orthogonal Projection for Lifelong Editing of Large Language Models
Xu, Haoyu and Lan, Pengxiang and Yang, Enneng and Guo, Guibing and Zhao, Jianzhe and Jiang, Linying and Wang, Xingwei. Knowledge Decoupling via Orthogonal Projection for Lifelong Editing of Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.646
-
[2]
The Thirteenth International Conference on Learning Representations , year=
AlphaEdit: Null-Space Constrained Model Editing for Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[3]
Mitigating Negative Interference in Multilingual Knowledge Editing through Null-Space Constraints
Sun, Wei and Qu, Tingyu and Li, Mingxiao and Davis, Jesse and Moens, Marie-Francine. Mitigating Negative Interference in Multilingual Knowledge Editing through Null-Space Constraints. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.460
-
[4]
Context-Robust Knowledge Editing for Language Models
Park, Haewon and Choi, Gyubin and Kim, Minjun and Jo, Yohan. Context-Robust Knowledge Editing for Language Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.540
-
[5]
URL https: //aclanthology.org/2025.acl-long.208/
Li, Qi and Chu, Xiaowen. A da E dit: Advancing Continuous Knowledge Editing For Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.208
-
[6]
One for All: Update Parameterized Knowledge Across Multiple Models with Once Edit
Ma, Weitao and Du, Xiyuan and Feng, Xiaocheng and Huang, Lei and Huang, Yichong and Zhang, Huiyi and Yang, Xiaoliang and Li, Baohang and Feng, Xiachong and Liu, Ting and Qin, Bing. One for All: Update Parameterized Knowledge Across Multiple Models with Once Edit. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volu...
-
[7]
Zhengxuan Wu and Aryaman Arora and Zheng Wang and Atticus Geiger and Dan Jurafsky and Christopher D Manning and Christopher Potts , booktitle=. Re. 2024 , url=
2024
-
[8]
Neuron-Level Sequential Editing for Large Language Models
Jiang, Houcheng and Fang, Junfeng and Zhang, Tianyu and Bi, Baolong and Zhang, An and Wang, Ruipeng and Liang, Tao and Wang, Xiang. Neuron-Level Sequential Editing for Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.815
-
[9]
The Eleventh International Conference on Learning Representations , year=
Mass-Editing Memory in a Transformer , author=. The Eleventh International Conference on Learning Representations , year=
-
[10]
Aging with
Thomas Hartvigsen and Swami Sankaranarayanan and Hamid Palangi and Yoon Kim and Marzyeh Ghassemi , booktitle=. Aging with. 2023 , url=
2023
-
[11]
Serial Lifelong Editing via Mixture of Knowledge Experts
Cheng, YuJu and Yu, Yu-Chu and Chang, Kai-Po and Wang, Yu-Chiang Frank. Serial Lifelong Editing via Mixture of Knowledge Experts. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1492
-
[12]
The Thirteenth International Conference on Learning Representations , year=
Unlocking Efficient, Scalable, and Continual Knowledge Editing with Basis-Level Representation Fine-Tuning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
2024 , url=
Peng Wang and Zexi Li and Ningyu Zhang and Ziwen Xu and Yunzhi Yao and Yong Jiang and Pengjun Xie and Fei Huang and Huajun Chen , booktitle=. 2024 , url=
2024
-
[14]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex J Andonian and Yonatan Belinkov , booktitle=. Locating and Editing Factual Associations in. 2022 , url=
2022
-
[15]
Advances in neural information processing systems , volume=
Experience replay for continual learning , author=. Advances in neural information processing systems , volume=
-
[16]
arXiv preprint arXiv:2005.14165 , volume=
Language models are few-shot learners , author=. arXiv preprint arXiv:2005.14165 , volume=
Pith/arXiv arXiv 2005
-
[17]
arXiv preprint arXiv:1701.06538 , year=
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
-
[18]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[19]
ACM Computing Surveys , volume=
Knowledge editing for large language models: A survey , author=. ACM Computing Surveys , volume=. 2024 , publisher=
2024
-
[20]
arXiv preprint arXiv:2305.13172 , year=
Editing large language models: Problems, methods, and opportunities , author=. arXiv preprint arXiv:2305.13172 , year=
-
[21]
arXiv preprint arXiv:2401.07453 , year=
Model editing at scale leads to gradual and catastrophic forgetting , author=. arXiv preprint arXiv:2401.07453 , year=
-
[22]
arXiv preprint arXiv:2304.00740 , year=
Inspecting and editing knowledge representations in language models , author=. arXiv preprint arXiv:2304.00740 , year=
-
[23]
arXiv preprint arXiv:2301.09785 , year=
Transformer-patcher: One mistake worth one neuron , author=. arXiv preprint arXiv:2301.09785 , year=
-
[24]
arXiv preprint arXiv:2502.05628 , year=
Anyedit: Edit any knowledge encoded in language models , author=. arXiv preprint arXiv:2502.05628 , year=
-
[25]
Findings of the Association for Computational Linguistics: EACL 2024 , pages=
Cross-lingual editing in multilingual language models , author=. Findings of the Association for Computational Linguistics: EACL 2024 , pages=
2024
-
[26]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Cross-lingual knowledge editing in large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[27]
arXiv preprint arXiv:2505.18774 , year=
Disentangling Knowledge Representations for Large Language Model Editing , author=. arXiv preprint arXiv:2505.18774 , year=
-
[28]
arXiv preprint arXiv:2410.11469 , year=
O-edit: Orthogonal subspace editing for language model sequential editing , author=. arXiv preprint arXiv:2410.11469 , year=
-
[29]
arXiv preprint arXiv:2506.00536 , year=
Decoupling Reasoning and Knowledge Injection for In-Context Knowledge Editing , author=. arXiv preprint arXiv:2506.00536 , year=
-
[30]
arXiv preprint arXiv:1706.04115 , year=
Zero-shot relation extraction via reading comprehension , author=. arXiv preprint arXiv:1706.04115 , year=
-
[31]
The Thirteenth International Conference on Learning Representations , year=
Perturbation-Restrained Sequential Model Editing , author=. The Thirteenth International Conference on Learning Representations , year=
-
[32]
Model editing harms general abilities of large language models: Regularization to the rescue
Gu, Jia-Chen and Xu, Hao-Xiang and Ma, Jun-Yu and Lu, Pan and Ling, Zhen-Hua and Chang, Kai-Wei and Peng, Nanyun. Model Editing Harms General Abilities of Large Language Models: Regularization to the Rescue. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.934
-
[33]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[34]
International Conference on Machine Learning , pages=
Memory-based model editing at scale , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[35]
arXiv preprint arXiv:2012.00363 , year=
Modifying memories in transformer models , author=. arXiv preprint arXiv:2012.00363 , year=
arXiv 2012
-
[36]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[37]
arXiv preprint arXiv:2407.10671 , volume=
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , volume=
-
[38]
Wiley interdisciplinary reviews: computational statistics , volume=
Principal component analysis , author=. Wiley interdisciplinary reviews: computational statistics , volume=. 2010 , publisher=
2010
-
[39]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
1948
-
[40]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[41]
SAKE : Steering activations for knowledge editing
Scialanga, Marco and Laugel, Thibault and Grari, Vincent and Detyniecki, Marcin. SAKE : Steering Activations for Knowledge Editing. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.777
-
[42]
Decoding by Contrasting Knowledge: Enhancing Large Language Model Confidence on Edited Facts
Bi, Baolong and Liu, Shenghua and Mei, Lingrui and Wang, Yiwei and Fang, Junfeng and Ji, Pengliang and Cheng, Xueqi. Decoding by Contrasting Knowledge: Enhancing Large Language Model Confidence on Edited Facts. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.841
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.