RAVEN: Agentic RAG for Automated Vulnerability Repair
Pith reviewed 2026-06-26 09:55 UTC · model grok-4.3
The pith
RAVEN's agentic RAG framework repairs 83.13% of 160 real-world CVEs across vulnerability types and languages using only open-source local LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
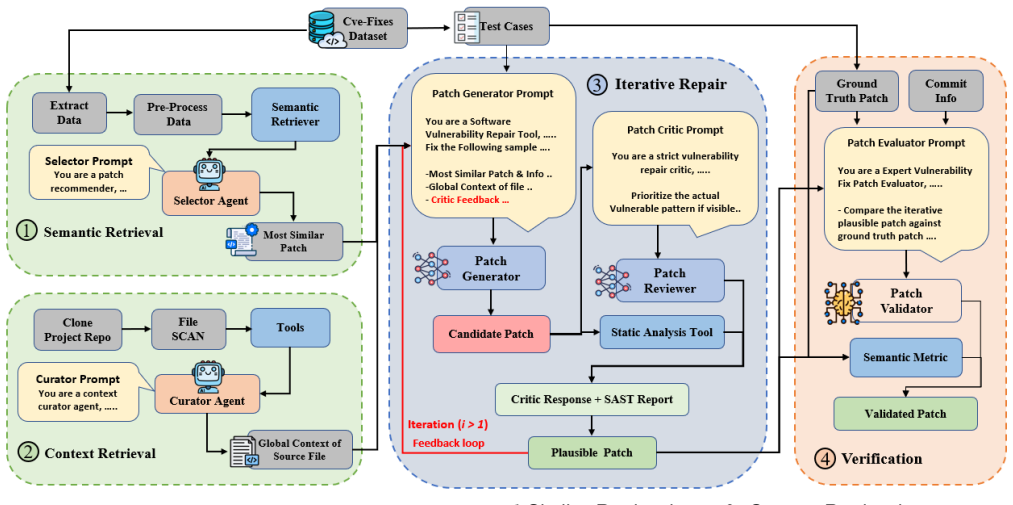
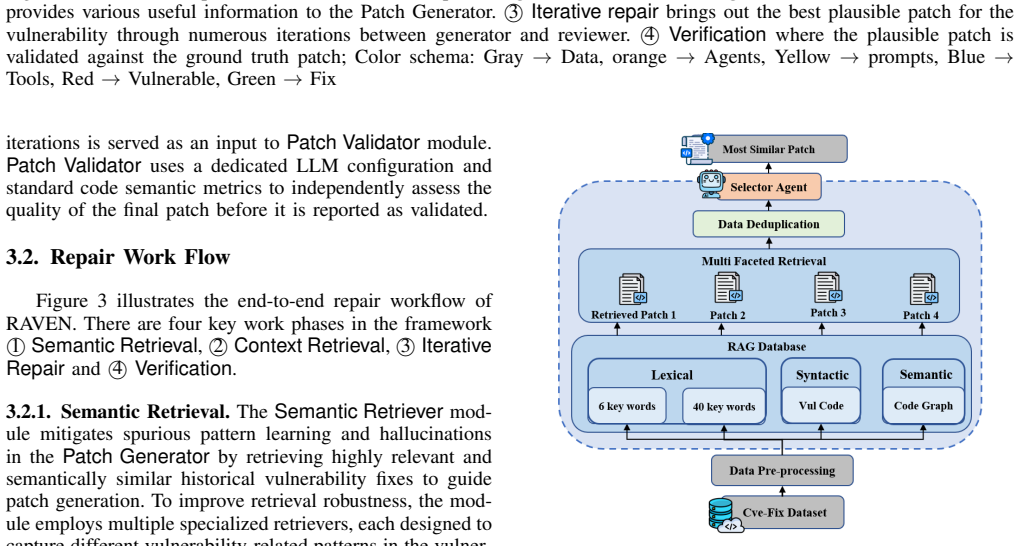
RAVEN integrates an agentic RAG pipeline with controlled iterative repair, utilizing open-source LLMs in a fully locally deployable setting with limited GPU requirements, a multi-faceted retrieval pipeline to retrieve historically relevant vulnerability fixes, and a dedicated Curator Agent that retrieves cross-file dependencies from the target repository to fix complex vulnerabilities that cannot be addressed using local vulnerable code alone. Evaluated on 160 real-world CVE vulnerabilities across diverse vulnerability types, two programming languages, unseen CWE categories, and out-of-distribution settings, RAVEN achieves an overall repair success rate of 83.13%, outperforming all existing
What carries the argument
Curator Agent that retrieves cross-file dependencies together with the multi-faceted retrieval pipeline that surfaces historical fixes to steer patch generation.
If this is right
- RAVEN generalizes to unseen CWE categories and out-of-distribution vulnerability settings.
- It delivers the reported performance using only open-source LLMs without proprietary models.
- Repair cost stays negligible across the evaluated cases.
- The approach handles vulnerabilities in two programming languages within one framework.
- Complex cases that need repository-wide context are addressed by the dedicated Curator Agent.
Where Pith is reading between the lines
- If the retrieval step continues to locate useful prior fixes for entirely new vulnerability patterns, the framework could shorten the time from disclosure to patch in production codebases.
- Local-only execution would allow deployment inside regulated or air-gapped environments where external model calls are disallowed.
- The same retrieval-plus-curator structure might transfer to non-security code repair tasks such as API migration or performance tuning with only changes to the retrieval corpus.
- Adding dynamic execution traces to the Curator Agent could further raise success on vulnerabilities whose patches depend on runtime behavior.
Load-bearing premise
The multi-faceted retrieval pipeline and Curator Agent can reliably surface historically relevant fixes and cross-file dependencies sufficient to guide patch generation for complex vulnerabilities beyond local code.
What would settle it
Evaluating the same 160 CVEs after removing all historical repair examples from the retrieval index would show whether success rate remains above 70% or collapses.
Figures

read the original abstract
Automated vulnerability repair has emerged as a promising direction to mitigate the growing number of software vulnerabilities. Recent advances in Large Language Models (LLMs) have further accelerated research in automated repair. However, existing frameworks remain largely restricted to memory-related vulnerabilities and locally repairable vulnerability settings, leaving generalization to unseen vulnerability types underexplored. Their evaluations are often limited to a single programming language, and largely rely on proprietary models. In this paper, we propose RAVEN, a scalable, efficient and autonomous framework that integrates an agentic retrieval-augmented generation (RAG) pipeline with controlled iterative repair in a unified framework. The framework utilizes open-source LLMs in a fully locally deployable setting with limited GPU requirements, while building a multi-faceted retrieval pipeline to retrieve historically relevant vulnerability fixes and guide the patch generation. In addition, RAVEN introduces a dedicated Curator Agent that retrieves cross-file dependencies from the target repository, to fix complex vulnerabilities that cannot be addressed using local vulnerable code alone. We evaluate RAVEN on 160 real-world CVE vulnerabilities across diverse vulnerability types, two programming languages, unseen CWE categories, and out-of-distribution settings. RAVEN achieves an overall repair success rate of 83.13%, outperforming all existing state-of-the-art repair frameworks, while also demonstrating strong generalization capabilities and maintaining the repair cost negligible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RAVEN, an agentic RAG framework for automated vulnerability repair that combines multi-faceted retrieval of historical fixes with a dedicated Curator Agent to handle cross-file dependencies. It evaluates the system on 160 real-world CVEs across two languages and unseen CWEs, claiming an 83.13% overall repair success rate that outperforms prior frameworks while using only open-source LLMs in a locally deployable setting with negligible repair cost.
Significance. If the performance and generalization claims are substantiated with supporting retrieval metrics and failure analysis, the work would be significant for extending automated repair beyond memory-related and locally fixable vulnerabilities to more complex, cross-file cases using accessible models.
major comments (3)
- [Evaluation] Evaluation section: the reported 83.13% success rate on 160 CVEs is presented without retrieval-precision metrics (e.g., precision@K or recall for the multi-faceted pipeline) or a breakdown of how many cases required the Curator Agent, which directly undermines assessment of whether the agentic-RAG components are responsible for the claimed generalization to unseen CWEs and complex vulnerabilities.
- [§4] §4 (Curator Agent description): no quantitative evaluation is supplied on the Curator Agent's success rate in surfacing non-local dependencies, despite this being the load-bearing mechanism for the claim that RAVEN handles vulnerabilities "that cannot be addressed using local vulnerable code alone."
- [Results] Results tables (e.g., Table 2 or equivalent): the outperformance claim over SOTA lacks per-CWE or per-language breakdowns that would allow verification of the "strong generalization capabilities" assertion, especially given the stress-test concern around cross-file retrieval reliability.
minor comments (2)
- [Abstract] The abstract states "repair cost negligible" without defining the cost metric (tokens, wall-clock time, or GPU hours); this should be clarified with explicit numbers in the evaluation.
- [§3] Notation for the multi-faceted retrieval pipeline (e.g., how the facets are combined) is introduced without a formal diagram or pseudocode, reducing reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the evaluation would be strengthened by additional metrics and breakdowns, and we will incorporate them in the revision.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported 83.13% success rate on 160 CVEs is presented without retrieval-precision metrics (e.g., precision@K or recall for the multi-faceted pipeline) or a breakdown of how many cases required the Curator Agent, which directly undermines assessment of whether the agentic-RAG components are responsible for the claimed generalization to unseen CWEs and complex vulnerabilities.
Authors: We agree that retrieval-precision metrics and a breakdown of Curator Agent usage are absent from the current evaluation section. These additions would allow clearer attribution of results to the agentic-RAG components. In the revised manuscript we will report precision@K and recall for the multi-faceted retrieval pipeline as well as the number and percentage of cases that invoked the Curator Agent. revision: yes
-
Referee: [§4] §4 (Curator Agent description): no quantitative evaluation is supplied on the Curator Agent's success rate in surfacing non-local dependencies, despite this being the load-bearing mechanism for the claim that RAVEN handles vulnerabilities "that cannot be addressed using local vulnerable code alone."
Authors: We acknowledge that §4 provides no quantitative success rate for the Curator Agent on non-local dependencies. We will add such an evaluation in the revision, including accuracy figures obtained via manual inspection of the 160 CVEs to quantify how often the agent correctly surfaces cross-file dependencies. revision: yes
-
Referee: [Results] Results tables (e.g., Table 2 or equivalent): the outperformance claim over SOTA lacks per-CWE or per-language breakdowns that would allow verification of the "strong generalization capabilities" assertion, especially given the stress-test concern around cross-file retrieval reliability.
Authors: The current tables report only aggregate success rates. We agree that per-CWE and per-language breakdowns would better support the generalization claims. We will expand the results tables in the revised version to include these stratified results. revision: yes
Circularity Check
No circularity: empirical framework evaluated on external CVE benchmark
full rationale
The paper describes an agentic RAG framework for vulnerability repair and reports an 83.13% success rate on 160 real-world CVEs across languages and unseen CWEs. No equations, fitted parameters, or derivation chain appear in the abstract or described claims. Performance is presented as a direct experimental outcome rather than a quantity derived from or equivalent to the framework's own inputs by construction. No self-citation load-bearing steps or ansatz smuggling are indicated. The central claim rests on retrieval and agent behavior, which the skeptic correctly flags as an assumption, but this is an empirical risk, not a circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
46 Vulnerability Statistics 2026: Key Trends in Discovery, Exploitation, and Risk,
“46 Vulnerability Statistics 2026: Key Trends in Discovery, Exploitation, and Risk,” 2026. [Online]. Available: https://security boulevard.com/2026/03/46-vulnerability-statistics-2026-key-trends-i n-discovery-exploitation-and-risk/
2026
-
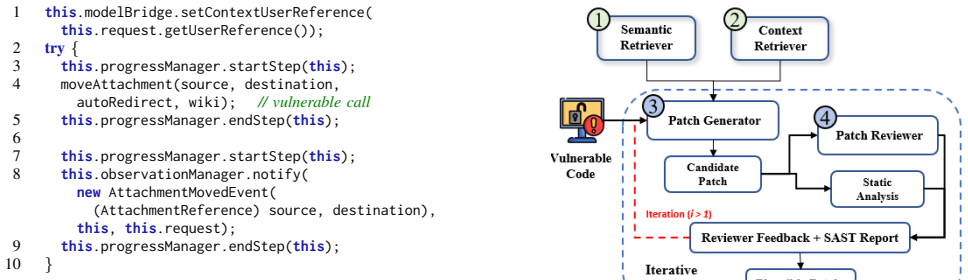
[2]
Context- aware patch generation for better automated program repair,
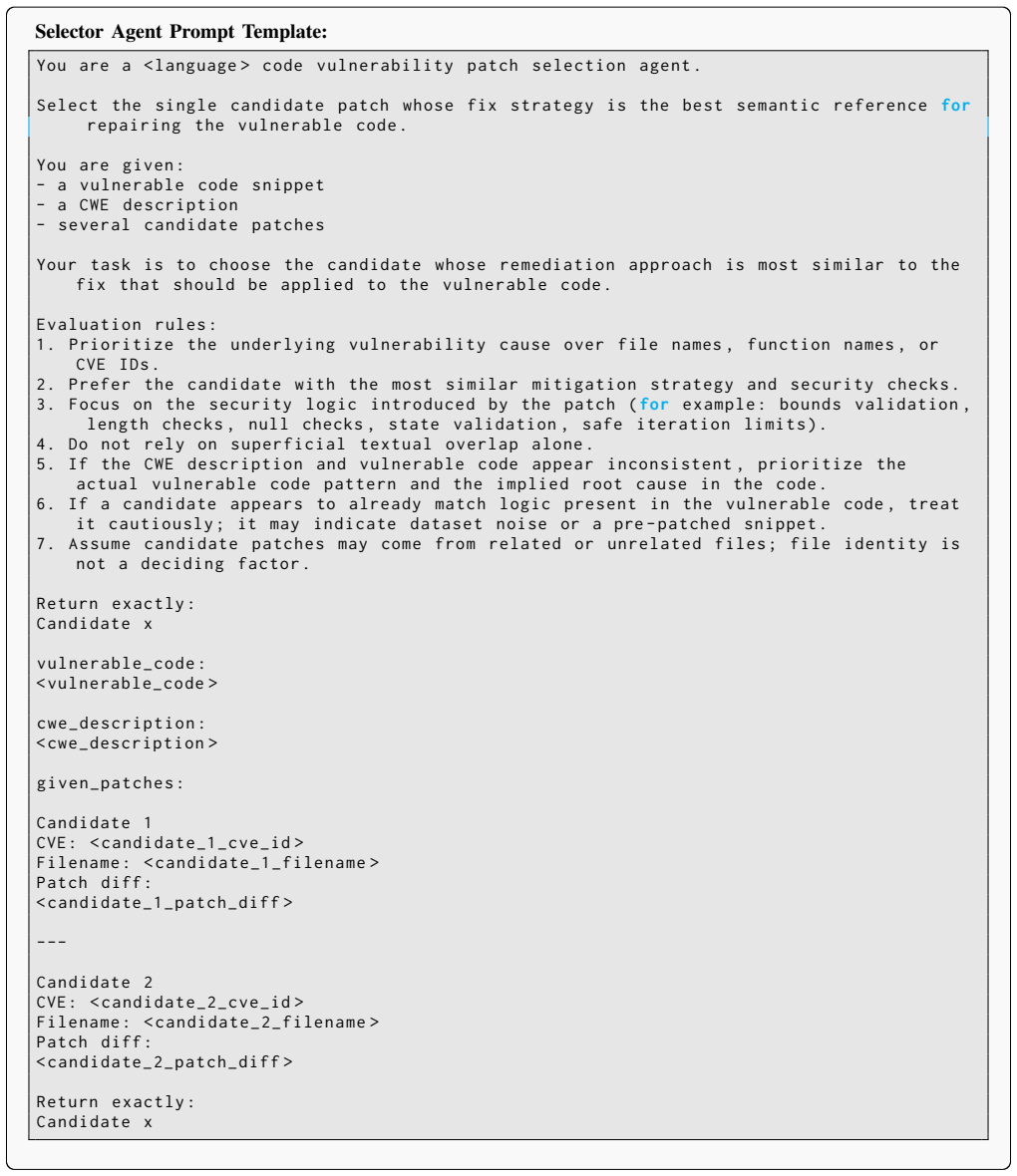
M. Wen, J. Chen, R. Wu, D. Hao, and S.-C. Cheung, “Context- aware patch generation for better automated program repair,” in Proceedings of the 40th International Conference on Software 11 Engineering, ser. ICSE ’18. New York, NY , USA: Association for Computing Machinery, 2018, p. 1–11. [Online]. Available: https://doi.org/10.1145/3180155.3180233
-
[3]
Better code search and reuse for better pro- gram repair,
Q. Xin and S. Reiss, “Better code search and reuse for better pro- gram repair,” in2019 IEEE/ACM International Workshop on Genetic Improvement (GI), 2019, pp. 10–17
2019
-
[4]
Sosrepair: Expressive semantic search for real-world program re- pair,
A. Afzal, M. Motwani, K. T. Stolee, Y . Brun, and C. Le Goues, “Sosrepair: Expressive semantic search for real-world program re- pair,”IEEE Transactions on Software Engineering, vol. 47, no. 10, pp. 2162–2181, 2021
2021
-
[5]
Automatic program repair using formal verification and expression templates,
T.-T. Nguyen, Q.-T. Ta, and W.-N. Chin, “Automatic program repair using formal verification and expression templates,” inVerification, Model Checking, and Abstract Interpretation, C. Enea and R. Piskac, Eds. Cham: Springer International Publishing, 2019, pp. 70–91
2019
-
[6]
Automatic patch generation learned from human-written patches,
D. Kim, J. Nam, J. Song, and S. Kim, “Automatic patch generation learned from human-written patches,” in2013 35th International Conference on Software Engineering (ICSE), 2013, pp. 802–811
2013
-
[7]
You cannot fix what you cannot find! an investiga- tion of fault localization bias in benchmarking automated program repair systems,
K. Liu, A. Koyuncu, T. F. Bissyand ´e, D. Kim, J. Klein, and Y . Le Traon, “You cannot fix what you cannot find! an investiga- tion of fault localization bias in benchmarking automated program repair systems,” in2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST), 2019, pp. 102–113
2019
-
[8]
Avatar: Fixing semantic bugs with fix patterns of static analysis violations,
K. Liu, A. Koyuncu, D. Kim, and T. F. Bissyand ´e, “Avatar: Fixing semantic bugs with fix patterns of static analysis violations,”2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER), pp. 1–12, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:201043038
2019
-
[9]
Sequencer: Sequence-to-sequence learning for end-to-end program repair,
Z. Chen, S. Kommrusch, M. Tufano, L.-N. Pouchet, D. Poshyvanyk, and M. Monperrus, “Sequencer: Sequence-to-sequence learning for end-to-end program repair,”IEEE Transactions on Software Engi- neering, vol. 47, no. 9, pp. 1943–1959, 2021
1943
-
[10]
Sorting and transforming program repair ingredients via deep learning code similarities,
M. White, M. Tufano, M. Mart ´ınez, M. Monperrus, and D. Poshy- vanyk, “Sorting and transforming program repair ingredients via deep learning code similarities,” in2019 IEEE 26th International Confer- ence on Software Analysis, Evolution and Reengineering (SANER), 2019, pp. 479–490
2019
-
[11]
Coconut: combining context-aware neural translation models using ensemble for program repair,
T. Lutellier, H. V . Pham, L. Pang, Y . Li, M. Wei, and L. Tan, “Coconut: combining context-aware neural translation models using ensemble for program repair,” ser. ISSTA 2020. New York, NY , USA: Association for Computing Machinery, 2020, p. 101–114. [Online]. Available: https://doi.org/10.1145/3395363.3397369
-
[12]
Neural transfer learning for repairing security vulnerabilities in c code,
Z. Chen, S. Kommrusch, and M. Monperrus, “Neural transfer learning for repairing security vulnerabilities in c code,”IEEE Transactions on Software Engineering, vol. 49, no. 1, pp. 147–165, 2023
2023
-
[13]
Seqtrans: Automatic vulnerability fix via sequence to sequence learning,
J. Chi, Y . Qu, T. Liu, Q. Zheng, and H. Yin, “Seqtrans: Automatic vulnerability fix via sequence to sequence learning,”IEEE Transac- tions on Software Engineering, vol. 49, no. 2, pp. 564–585, 2023
2023
-
[14]
Vulrepair: a t5-based automated software vulnerability repair,
M. Fu, C. Tantithamthavorn, T. Le, V . Nguyen, and D. Phung, “Vulrepair: a t5-based automated software vulnerability repair,” ser. ESEC/FSE 2022. New York, NY , USA: Association for Computing Machinery, 2022, p. 935–947. [Online]. Available: https://doi.org/10.1145/3540250.3549098
-
[15]
X. Zhou, K. Kim, B. Xu, D. Han, and D. Lo, “Out of sight, out of mind: Better automatic vulnerability repair by broadening input ranges and sources,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ser. ICSE ’24. New York, NY , USA: Association for Computing Machinery, 2024. [Online]. Available: https://doi.org/10.1145...
-
[16]
Ex- amining zero-shot vulnerability repair with large language models,
H. Pearce, B. Tan, B. Ahmad, R. Karri, and B. Dolan-Gavitt, “Ex- amining zero-shot vulnerability repair with large language models,” in2023 IEEE Symposium on Security and Privacy (SP), 2023, pp. 2339–2356
2023
-
[17]
Rap-gen: Retrieval- augmented patch generation with codet5 for automatic program repair,
W. Wang, Y . Wang, S. Joty, and S. C. Hoi, “Rap-gen: Retrieval- augmented patch generation with codet5 for automatic program repair,” ser. ESEC/FSE 2023. New York, NY , USA: Association for Computing Machinery, 2023, p. 146–158. [Online]. Available: https://doi.org/10.1145/3611643.3616256
-
[18]
Y . Kim, S. Shin, H. Kim, and J. Yoon,Logs in, patches out: auto- mated vulnerability repair via tree-of-thought LLM analysis. USA: USENIX Association, 2025
2025
-
[19]
Patchagent: a practical program repair agent mimicking human ex- pertise,
Z. Yu, Z. Guo, Y . Wu, J. Yu, M. Xu, D. Mu, Y . Chen, and X. Xing, “Patchagent: a practical program repair agent mimicking human ex- pertise,” inProceedings of the 34th USENIX Conference on Security Symposium, ser. SEC ’25. USA: USENIX Association, 2025
2025
-
[20]
Appatch: au- tomated adaptive prompting large language models for real-world software vulnerability patching,
Y . Nong, H. Yang, L. Cheng, H. Hu, and H. Cai, “Appatch: au- tomated adaptive prompting large language models for real-world software vulnerability patching,” inProceedings of the 34th USENIX Conference on Security Symposium, ser. SEC ’25. USA: USENIX Association, 2025
2025
-
[21]
Beyond tests: Program vulnerability repair via crash constraint extraction,
X. Gao, B. Wang, G. J. Duck, R. Ji, Y . Xiong, and A. Roychoudhury, “Beyond tests: Program vulnerability repair via crash constraint extraction,”ACM Trans. Softw. Eng. Methodol., vol. 30, no. 2, Feb
-
[22]
Available: https://doi.org/10.1145/3418461
[Online]. Available: https://doi.org/10.1145/3418461
-
[23]
Gemma 4,
Google DeepMind, “Gemma 4,” 2026. [Online]. Available: https: //deepmind.google/models/gemma/gemma-4/
2026
-
[24]
Nemotron-3-30b,
NVIDIA Corporation, “Nemotron-3-30b,” 2025. [Online]. Available: https://build.nvidia.com/nvidia/nemotron-3-nano-30b-a3b/modelcard
2025
-
[25]
CVE-2023-37910,
“CVE-2023-37910,” 2023. [Online]. Available: https://www.cve.org/ CVERecord?id=CVE-2023-37910
2023
-
[26]
XWiki Platform: An Open-Source Enterprise Wiki Framework
“XWiki Platform: An Open-Source Enterprise Wiki Framework.”
-
[27]
CWE-862: Missing Authorization
“CWE-862: Missing Authorization.” [Online]. Available: https: //cwe.mitre.org/data/definitions/862.html
-
[28]
CVEfixes: Automated Collection of Vulnerabilities and Their Fixes from Open-Source Software,
G. Bhandari, A. Naseer, and L. Moonen, “Cvefixes: automated collection of vulnerabilities and their fixes from open-source software,” inProceedings of the 17th International Conference on Predictive Models and Data Analytics in Software Engineering, ser. PROMISE 2021. New York, NY , USA: Association for Computing Machinery, 2021, p. 30–39. [Online]. Avail...
-
[29]
Joern: A tool for parsing and analyzing source code,
J. Developers, “Joern: A tool for parsing and analyzing source code,” 2017. [Online]. Available: https://joern.io
2017
-
[30]
The probabilistic relevance frame- work: Bm25 and beyond,
S. Robertson and H. Zaragoza, “The probabilistic relevance frame- work: Bm25 and beyond,”Foundations and Trends in Information Retrieval, vol. 3, pp. 333–389, 09 2009
2009
-
[31]
Semgrep: Lightweight static analysis for many lan- guages,
Semgrep, Inc., “Semgrep: Lightweight static analysis for many lan- guages,” https://github.com/semgrep/semgrep
-
[32]
Codebleu: a method for automatic evaluation of code synthesis,
S. Ren, D. Guo, S. Lu, L. Zhou, S. Liu, D. Tang, N. Sundaresan, M. Zhou, A. Blanco, and S. Ma, “Codebleu: a method for automatic evaluation of code synthesis,” 2020. [Online]. Available: https://arxiv.org/abs/2009.10297
Pith/arXiv arXiv 2020
-
[33]
CWE-787: Out-of-bounds Write
“CWE-787: Out-of-bounds Write.” [Online]. Available: https: //cwe.mitre.org/data/definitions/787.html
-
[34]
CWE-125: Out-of-bounds Read
“CWE-125: Out-of-bounds Read.” [Online]. Available: https: //cwe.mitre.org/data/definitions/125.html
-
[35]
CWE-79: Improper Neutralization of Input During Web Page Generation (’Cross-site Scripting’)
“CWE-79: Improper Neutralization of Input During Web Page Generation (’Cross-site Scripting’).” [Online]. Available: https: //cwe.mitre.org/data/definitions/79.html
-
[36]
CWE-89: Improper Neutralization of Special Elements used in an SQL Command (’SQL Injection’)
“CWE-89: Improper Neutralization of Special Elements used in an SQL Command (’SQL Injection’).” [Online]. Available: https://cwe.mitre.org/data/definitions/89.html
-
[37]
CWE-94: Improper Control of Generation of Code (’Code Injection’)
“CWE-94: Improper Control of Generation of Code (’Code Injection’).” [Online]. Available: https://cwe.mitre.org/data/definitio ns/94.html
-
[38]
CWE-22: Improper Limitation of a Pathname to a Restricted Directory (’Path Traversal’)
“CWE-22: Improper Limitation of a Pathname to a Restricted Directory (’Path Traversal’).” [Online]. Available: https://cwe.mitre. org/data/definitions/22.html
-
[39]
CWE-502: Deserialization of Untrusted Data
“CWE-502: Deserialization of Untrusted Data.” [Online]. Available: https://cwe.mitre.org/data/definitions/502.html 12
-
[40]
CWE-352: Cross-Site Request Forgery (CSRF)
“CWE-352: Cross-Site Request Forgery (CSRF).” [Online]. Available: https://cwe.mitre.org/data/definitions/352.html
-
[41]
CWE-863: Incorrect Authorization
“CWE-863: Incorrect Authorization.” [Online]. Available: https: //cwe.mitre.org/data/definitions/863.html
-
[42]
Vul4j: A dataset of reproducible java vulnerabilities geared towards the study of program repair techniques,
Q.-C. Bui, R. Scandariato, and N. E. D. Ferreyra, “Vul4j: A dataset of reproducible java vulnerabilities geared towards the study of program repair techniques,” in2022 IEEE/ACM 19th International Conference on Mining Software Repositories (MSR), 2022, pp. 464–468
2022
-
[43]
CWE-835: Loop with Unreachable Exit Condition (’Infinite Loop’)
“CWE-835: Loop with Unreachable Exit Condition (’Infinite Loop’).” [Online]. Available: https://cwe.mitre.org/data/definitions/835.html
-
[44]
CWE-828: Signal Handler with Functionality that is not Asynchronous-Safe
“ CWE-828: Signal Handler with Functionality that is not Asynchronous-Safe.” [Online]. Available: https://cwe.mitre.org/data /definitions/828.html
-
[45]
CWE-770: Allocation of Resources Without Limits or Throttling
“ CWE-770: Allocation of Resources Without Limits or Throttling.” [Online]. Available: https://cwe.mitre.org/data/definitions/770.html
-
[46]
CWE-476: NULL Pointer Dereference
“CWE-476: NULL Pointer Dereference.” [Online]. Available: https://cwe.mitre.org/data/definitions/476.html
-
[47]
CWE-416: Use After Free
“CWE-416: Use After Free.” [Online]. Available: https://cwe.mitre. org/data/definitions/416.html
-
[48]
CWE-281: Improper Preservation of Permissions
“CWE-281: Improper Preservation of Permissions.” [Online]. Available: https://cwe.mitre.org/data/definitions/281.html
-
[49]
CWE-96: Improper Neutralization of Directives in Statically Saved Code (’Static Code Injection’)
“CWE-96: Improper Neutralization of Directives in Statically Saved Code (’Static Code Injection’).” [Online]. Available: https: //cwe.mitre.org/data/definitions/96.html
-
[50]
Program vulnerability repair via inductive inference,
Y . Zhang, X. Gao, G. J. Duck, and A. Roychoudhury, “Program vulnerability repair via inductive inference,” inProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2022. New York, NY , USA: Association for Computing Machinery, 2022, p. 691–702. [Online]. Available: https://doi.org/10.1145/3533767.3534387
-
[51]
Varfix: balancing edit expressiveness and search effectiveness in automated program repair,
C.-P. Wong, P. Santiesteban, C. K ¨astner, and C. Le Goues, “Varfix: balancing edit expressiveness and search effectiveness in automated program repair,” inProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ser. ESEC/FSE 2021. New York, NY , USA: Association for C...
-
[52]
An analysis of the search spaces for generate and validate patch generation systems,
F. Long and M. Rinard, “An analysis of the search spaces for generate and validate patch generation systems,” inProceedings of the 38th International Conference on Software Engineering, ser. ICSE ’16. New York, NY , USA: Association for Computing Machinery, 2016, p. 702–713. [Online]. Available: https://doi.org/10 .1145/2884781.2884872
arXiv 2016
-
[53]
A survey of symbolic execution techniques,
R. Baldoni, E. Coppa, D. C. D’elia, C. Demetrescu, and I. Finocchi, “A survey of symbolic execution techniques,” vol. 51, no. 3, May
-
[54]
Available: https://doi.org/10.1145/3182657
[Online]. Available: https://doi.org/10.1145/3182657
-
[55]
relifix: automated repair of software regressions,
S. H. Tan and A. Roychoudhury, “relifix: automated repair of software regressions,” inProceedings of the 37th International Conference on Software Engineering - Volume 1, ser. ICSE ’15. IEEE Press, 2015, p. 471–482
2015
-
[56]
Automatic inference of code transforms for patch generation,
F. Long, P. Amidon, and M. Rinard, “Automatic inference of code transforms for patch generation,” inProceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, ser. ESEC/FSE 2017. New York, NY , USA: Association for Computing Machinery, 2017, p. 727–739. [Online]. Available: https://doi.org/10.1145/3106237.3106253
-
[57]
Tbar: revisiting template-based automated program repair,
K. Liu, A. Koyuncu, D. Kim, and T. F. Bissyand ´e, “Tbar: revisiting template-based automated program repair,” inProceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2019. New York, NY , USA: Association for Computing Machinery, 2019, p. 31–42. [Online]. Available: https://doi.org/10.1145/3293882.3330577
-
[58]
Dlfix: context-based code transformation learning for automated program repair,
Y . Li, S. Wang, and T. N. Nguyen, “Dlfix: context-based code transformation learning for automated program repair,” in Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, ser. ICSE ’20. New York, NY , USA: Association for Computing Machinery, 2020, p. 602–614. [Online]. Available: https://doi.org/10.1145/3377811.3380345
-
[59]
Review4repair: Code review aided automatic program repairing,
F. Huq, M. Hasan, M. M. A. Haque, S. Mahbub, A. Iqbal, and T. Ahmed, “Review4repair: Code review aided automatic program repairing,”Inf. Softw. Technol., vol. 143, no. C, Mar. 2022. [Online]. Available: https://doi.org/10.1016/j.infsof.2021.106765
-
[60]
How effective are neural networks for fixing security vulnerabilities,
Y . Wu, N. Jiang, H. V . Pham, T. Lutellier, J. Davis, L. Tan, P. Babkin, and S. Shah, “How effective are neural networks for fixing security vulnerabilities,” inProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2023. New York, NY , USA: Association for Computing Machinery, 2023, p. 1282–1294. [Online...
-
[61]
Retrieval-augmented generation for knowledge- intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Kuttler, M. Lewis, W.-t. Yih, T. Rocktaschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge- intensive nlp tasks,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474. [Online]. Available: https://proceedings.neurips.cc/paper/2020/...
2020
-
[62]
Retrieval-augmented generation for large language models: A survey,
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, M. Wang, and H. Wang, “Retrieval-augmented generation for large language models: A survey,”arXiv preprint arXiv:2312.10997, 2023. [Online]. Available: https://arxiv.org/abs/2312.10997 Appendix This appendix provides background on Retrieval Aug- mented Generation, prompt templates and rep...
Pith/arXiv arXiv 2023
-
[63]
Retrieval Augmented Generation Retrieval Augmented Generation (RAG) incorporates external knowledge at inference time by combining the internal knowledge of an LLM with external sources such as vector databases, knowledge bases, and code reposito- ries [59], [60]. This is particularly beneficial for knowledge- intensive tasks where information changes dyn...
2015
-
[64]
Performance of RA VEN on C based CWEs The results in table 7 further demonstrate the effective- ness of RA VEN on C-based vulnerabilities across memory- safety and access-control categories. Formemory-based vul- nerabilities(CWE-125), RA VEN successfully repairs17out of20instances, achieving a repair success rate of85.00%, which shows its ability to mitig...
-
[65]
Select the single candidate patch whose fix strategy is the best semantic referencefor repairing the vulnerable code
Prompt Templates 14 Selector Agent Prompt Template: You are a < language > code vulnerability patch selection agent . Select the single candidate patch whose fix strategy is the best semantic referencefor repairing the vulnerable code . You are given : - a vulnerable code snippet - a CWE description - several candidate patches Your task is to choose the c...
-
[66]
Prioritize the underlying vulnerability cause over file names , function names , or CVE IDs
-
[67]
Prefer the candidate with the most similar mitigation strategy and security checks
-
[68]
Focus on the security logic introduced by the patch (forexample : bounds validation , length checks , null checks , state validation , safe iteration limits )
-
[69]
Do not rely on superficial textual overlap alone
-
[70]
If the CWE description and vulnerable code appear inconsistent , prioritize the actual vulnerable code pattern and the implied root cause in the code
-
[71]
If a candidate appears to already match logic present in the vulnerable code , treat it cautiously ; it may indicate dataset noise or a pre - patched snippet
-
[72]
Assume candidate patches may come from related or unrelated files ; file identity is not a deciding factor . Return exactly : Candidate x vulnerable_code : < vulnerable_code > cwe_description : < cwe_description > given_patches : Candidate 1 CVE : < candidate_1_cve_id > Filename : < candidate_1_filename > Patch diff : < candidate_1_patch_diff > --- Candid...
-
[73]
{ r ef e re n c e_ g u id a n ce }
Prioritize the concrete root cause visible in the target code . { r ef e re n c e_ g u id a n ce }
-
[74]
Apply the smallest targeted fix that prevents the unsafe behaviorwhilepreserving existing logic
-
[75]
Do not refactor , rename symbols , change formatting unnecessarily , or modify unrelated behavior
-
[76]
Do not introduce new helper functions , macros , types , or dependencies unless clearly implied by the provided code context
-
[77]
Reuse existing validation style , control flow , and error handling patterns when possible
-
[78]
Output rules : - Return only one```{ code_fence }```code block and no other text
Ensure the result is syntactically valid and consistent with the surrounding code . Output rules : - Return only one```{ code_fence }```code block and no other text . - Inside the code block , provide only the minimal fixed code snippet ( s )forthe target file . - Do not output a unified diff unless explicitly requested . { r e f e r e n c e _ o u t p u t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.