Text Dictates, Music Decorates: Energy-based Attention for Editable Dance Motion Generation
Pith reviewed 2026-06-26 09:13 UTC · model grok-4.3
The pith
STREAM separates text semantics and music beats in a diffusion transformer to generate dance motions that follow both without one overwriting the other.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
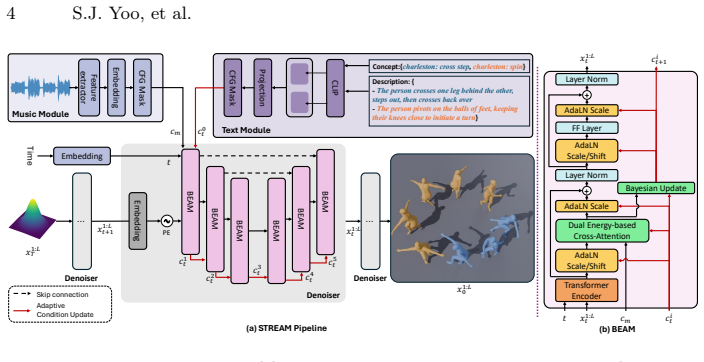
STREAM is a modality-decoupled diffusion transformer in which AdaLN injects global text semantics to control kinematic structure and the BEAM module routes the resulting features to musical beats without overwriting the semantics, resulting in state-of-the-art alignment between motion and music while perfectly preserving choreographic semantics.
What carries the argument
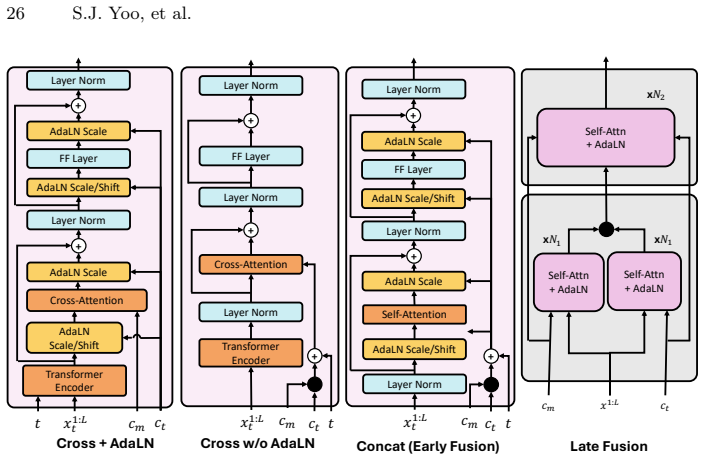
The Bimodal Energy-Based Attention Module (BEAM) which routes text-conditioned motion features to musical beats while the Adaptive Layer Normalization (AdaLN) separately handles global text semantics.
If this is right
- Models can achieve both high music synchronization and text-based editability in dance generation.
- User controllability is maintained even when strong rhythmic conditioning from music is applied.
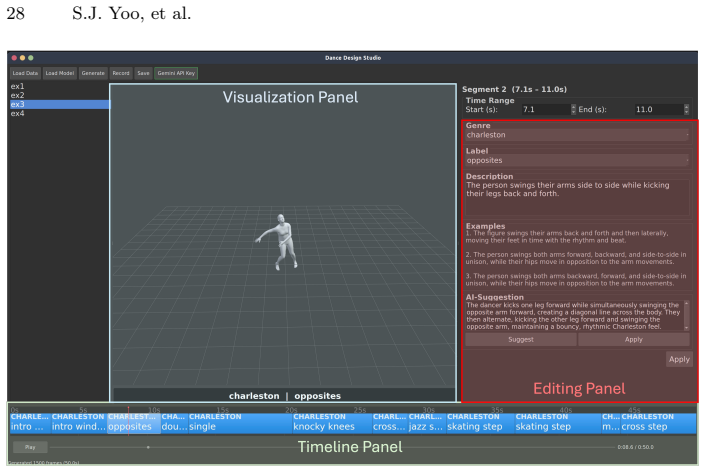
- Frame-level semantic annotations in datasets improve training for semantic preservation.
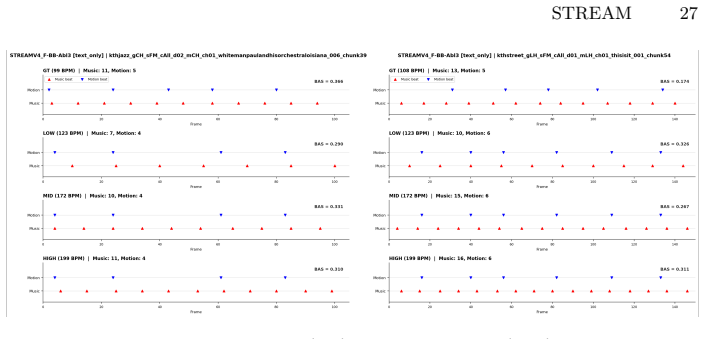
- New protocols like the Exchange Evaluation Protocol allow measurement of zero-shot editability.
Where Pith is reading between the lines
- This separation strategy may apply to other tasks where one modality risks dominating another, such as text and audio in video generation.
- Future work could test whether the same decoupling improves controllability in non-dance motion tasks.
- If the method scales, it suggests that explicit pathway separation is a general solution to modality interference in generative models.
Load-bearing premise
That using separate pathways with AdaLN for text semantics and BEAM for music beats will eliminate modality collapse and preserve controllability without any loss in motion quality or alignment.
What would settle it
An experiment in which text prompts are exchanged mid-generation and the resulting motions fail to reflect the new semantics while still matching the music would falsify the preservation of controllability.
Figures



read the original abstract
Choreographic motion generation poses unique challenges for AI, demanding precise semantic control over complex, temporally structured, and expressive full-body dynamics. While existing models can synthesize motion from music, they remain largely black boxes. Conversely, attempting to condition generation on both text and music frequently leads to modality collapse, where dense acoustic rhythms overwhelm sparse semantic text prompts, destroying user controllability. To resolve this spatial-temporal conflict, we propose STREAM (Structural-Temporal Rhythmic Energy-based Attention for Motion), a modality-decoupled diffusion transformer. STREAM strictly separates conditioning pathways: global text semantics dictate the kinematic structure via Adaptive Layer Normalization (AdaLN), while a novel Bimodal Energy-Based Attention Module (BEAM) routes these features to the musical beat without overwriting the semantics. We further introduce Motorica++, a newly curated dataset enriched with domain-specific dance vocabulary and frame-level semantic annotations from existing Motorica dataset. Additionally, to rigorously quantify zero-shot editability, we propose the Exchange Evaluation Protocol and Editable Dance Score (EDS). Through extensive experiments, STREAM achieves state-of-the-art alignment between motion and music while perfectly preserving choreographic semantics, positioning AI not merely as a reactive synthesizer, but as a controllable, collaborative partner for artistic direction. The source code and datasets are available at https://github.com/SeongJong-Yoo/STREAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces STREAM, a modality-decoupled diffusion transformer for generating editable dance motions from text and music inputs. It separates conditioning pathways by using Adaptive Layer Normalization (AdaLN) to let global text semantics dictate kinematic structure while a new Bimodal Energy-Based Attention Module (BEAM) routes features to musical beats. The work also contributes the Motorica++ dataset with frame-level semantic annotations and proposes the Exchange Evaluation Protocol together with the Editable Dance Score (EDS) metric to quantify zero-shot editability. The central claim is that this architecture achieves state-of-the-art music-motion alignment while perfectly preserving choreographic semantics, avoiding the modality collapse that typically occurs when both modalities are combined.
Significance. If the decoupling mechanism and quantitative claims are substantiated, the result would advance controllable multi-modal motion synthesis by demonstrating that text can dictate structure and music can decorate rhythm without semantic degradation. The Motorica++ dataset and EDS protocol could become useful benchmarks for editability in dance generation if externally validated.
major comments (2)
- [Abstract] Abstract: the assertion of 'state-of-the-art alignment' and 'perfectly preserving choreographic semantics' is presented without any quantitative results, ablation tables, or numerical EDS scores. This is load-bearing for the central claim because the paper's contribution rests on the superiority and zero-trade-off properties of the AdaLN+BEAM separation.
- [Abstract] Abstract: no ablation is described that compares semantic fidelity (via EDS or the Exchange Protocol) under text-only conditioning versus text+music conditioning on identical prompts. Without this comparison, it is impossible to verify that BEAM routing introduces zero semantic degradation, which directly tests the weakest assumption underlying the 'perfect preservation' claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments on the abstract below, agreeing that stronger quantitative grounding is needed for the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'state-of-the-art alignment' and 'perfectly preserving choreographic semantics' is presented without any quantitative results, ablation tables, or numerical EDS scores. This is load-bearing for the central claim because the paper's contribution rests on the superiority and zero-trade-off properties of the AdaLN+BEAM separation.
Authors: We agree that the abstract presents the claims at a high level without numerical support. The body of the manuscript (Section 4 and Table 2) contains the EDS scores, music-alignment metrics, and ablations demonstrating SOTA performance and semantic preservation. To make the abstract self-contained and directly responsive to this concern, we will revise it to include the key quantitative results (e.g., EDS values and alignment deltas) from the experiments. revision: yes
-
Referee: [Abstract] Abstract: no ablation is described that compares semantic fidelity (via EDS or the Exchange Protocol) under text-only conditioning versus text+music conditioning on identical prompts. Without this comparison, it is impossible to verify that BEAM routing introduces zero semantic degradation, which directly tests the weakest assumption underlying the 'perfect preservation' claim.
Authors: The manuscript reports that adding BEAM does not degrade EDS relative to text-only baselines, but we acknowledge that an explicit side-by-side ablation on identical prompts (text-only vs. text+music) is not described in the abstract and is only summarized rather than isolated in the main text. We will add this targeted comparison (new table or subsection) in the revision to directly substantiate the zero-degradation claim. revision: yes
Circularity Check
No significant circularity; claims rest on new empirical components
full rationale
The paper introduces a novel architecture (STREAM using AdaLN for text and BEAM for music routing), a new dataset (Motorica++ with added annotations), and new metrics/protocols (Exchange Evaluation Protocol and EDS). All central claims of SOTA alignment and semantic preservation are presented as outcomes of experiments on these new elements rather than any derivation that reduces to fitted inputs, self-citations, or renamed known results. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the provided text; the work is self-contained against external benchmarks with no evidence of predictions equaling inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion transformers can be conditioned on text and audio modalities
invented entities (1)
-
Bimodal Energy-Based Attention Module (BEAM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alexanderson, S., Nagy, R., Beskow, J., Henter, G.E.: Listen, Denoise, Action! Audio-Driven Motion Synthesis with Diffusion Models. ACM Trans. Graph.42(4), 44:1–44:20 (2023).https://doi.org/10.1145/3592458 , https://dl.acm.org/ doi/10.1145/3592458
-
[2]
Routledge, London (Aug 2023).https://doi.org/10.4324/9781003009764
Angelov, V.: You, the Choreographer: Creating and Crafting Dance. Routledge, London (Aug 2023).https://doi.org/10.4324/9781003009764
-
[3]
Athanasiou, N., Ceske, A., Diomataris, M., Black, M.J., Varol, G.: MotionFix: Text-Driven 3D Human Motion Editing (Sep 2024).https://doi.org/10.48550/ arXiv.2408.00712,http://arxiv.org/abs/2408.00712
arXiv 2024
-
[4]
Frontiers in Human Neuroscience14, 584312 (Jan 2021)
Basso, J.C., Satyal, M.K., Rugh, R.: Dance on the Brain: Enhancing Intra- and Inter-Brain Synchrony. Frontiers in Human Neuroscience14, 584312 (Jan 2021). https://doi.org/10.3389/fnhum.2020.584312 , https://pmc.ncbi.nlm.nih. gov/articles/PMC7832346/
-
[5]
Frontiers in Psychology6(Apr 2015)
Cameron, D.J., Bentley, J., Grahn, J.A.: Cross-cultural influences on rhythm process- ing: Reproduction, discrimination, and beat tapping. Frontiers in Psychology6(Apr 2015). https://doi.org/10.3389/fpsyg.2015.00366, https://www.frontiersin. org/journals/psychology/articles/10.3389/fpsyg.2015.00366/full
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, X., Jiang, B., Liu, W., Huang, Z., Fu, B., Chen, T., Yu, G.: Executing Your Commands via Motion Diffusion in Latent Space. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18000–18010 (2023), https://openaccess.thecvf.com/content/CVPR2023/html/Chen_Executing_ Your_Commands_via_Motion_Diffusion_in_Latent_Spac...
2023
-
[7]
arXiv preprint arXiv:2005.00341 (2020),https: //assets.pubpub.org/2gnzbcnd/11608661311181.pdf
Dhariwal, P., Jun, H., Payne, C., Kim, J.W., Radford, A., Sutskever, I.: Jukebox: A generative model for music. arXiv preprint arXiv:2005.00341 (2020),https: //assets.pubpub.org/2gnzbcnd/11608661311181.pdf
Pith/arXiv arXiv 2005
-
[8]
Du, Y., Durkan, C., Strudel, R., Tenenbaum, J.B., Dieleman, S., Fergus, R., Sohl- Dickstein, J., Doucet, A., Grathwohl, W.: Reduce, Reuse, Recycle: Compositional Generation with Energy-Based Diffusion Models and MCMC (Sep 2024).https: //doi.org/10.48550/arXiv.2302.11552,http://arxiv.org/abs/2302.11552
-
[9]
In: Advances in Neural Information Processing Systems
Du, Y., Li, S., Mordatch, I.: Compositional Visual Generation with Energy Based Models. In: Advances in Neural Information Processing Systems. vol. 33, pp. 6637–
-
[10]
(2020),https://proceedings.neurips.cc/paper/ 2020/hash/49856ed476ad01fcff881d57e161d73f-Abstract.html
Curran Associates, Inc. (2020),https://proceedings.neurips.cc/paper/ 2020/hash/49856ed476ad01fcff881d57e161d73f-Abstract.html
2020
-
[11]
https://doi.org/10.48550/arXiv.2406.11179 , http:// arxiv.org/abs/2406.11179
Du, Y., Mao, J., Tenenbaum, J.B.: Learning Iterative Reasoning through Energy Diffusion (Jun 2024). https://doi.org/10.48550/arXiv.2406.11179 , http:// arxiv.org/abs/2406.11179
-
[12]
arXiv preprint arXiv:2503.17340 (2025) 16 S.J
Fan, C., Guan, J., Zhao, X., Xu, D., Lin, Y., Ye, T., Feng, P., Pan, H.: Align your rhythm: Generating highly aligned dance poses with gating-enhanced rhythm-aware feature representation. arXiv preprint arXiv:2503.17340 (2025) 16 S.J. Yoo, et al
arXiv 2025
-
[13]
In: Proceedings of the Seventh ACM International Conference on Multimedia (Part 1)
Foote, J.: Visualizing music and audio using self-similarity. In: Proceedings of the Seventh ACM International Conference on Multimedia (Part 1). pp. 77–80. MULTIMEDIA ’99, Association for Computing Machinery, New York, NY, USA (Oct 1999). https://doi.org/10.1145/319463.319472 , https://dl.acm.org/ doi/10.1145/319463.319472
-
[14]
Gladstone, A., Nanduru, G., Islam, M.M., Han, P., Ha, H., Chadha, A., Du, Y., Ji, H., Li, J., Iqbal, T.: Energy-Based Transformers are Scalable Learners and Thinkers (Jul 2025).https://doi.org/10.48550/arXiv.2507.02092, http: //arxiv.org/abs/2507.02092
-
[15]
In: ACM SIGGRAPH 2024 Conference Papers
Goel, P., Wang, K.C., Liu, C.K., Fatahalian, K.: Iterative Motion Editing with Natural Language. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–9. SIG- GRAPH ’24, Association for Computing Machinery, New York, NY, USA (Jul 2024). https://doi.org/10.1145/3641519.3657447, https://dl.acm.org/doi/ 10.1145/3641519.3657447
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vi- sion
Gong, K., Lian, D., Chang, H., Guo, C., Jiang, Z., Zuo, X., Mi, M.B., Wang, X.: TM2D: Bimodality Driven 3D Dance Generation via Music-Text Integration. In: Proceedings of the IEEE/CVF International Conference on Computer Vi- sion. pp. 9942–9952 (2023),https://openaccess.thecvf.com/content/ICCV2023/ html/Gong_TM2D_Bimodality_Driven_3D_Dance_Generation_via_...
2023
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gong, K., Lian, D., Chang, H., Guo, C., Jiang, Z., Zuo, X., Mi, M.B., Wang, X.: Tm2d: Bimodality driven 3d dance generation via music-text integration. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9942–9952 (2023)
2023
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.: Generating Diverse and Natural 3D Human Motions From Text. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5152–5161 (2022), https://openaccess.thecvf.com/content/CVPR2022/html/Guo_Generating_ Diverse_and_Natural_3D_Human_Motions_From_Text_CVPR_2022_...
2022
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
Gupta, P., Fotso-Puepi, J.A., Li, Z., Mehta, J., Bera, A.: Mdd: A dataset for text- and-music conditioned duet dance generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
2025
-
[20]
In: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics
Gutmann, M., Hyvärinen, A.: Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. pp. 297–304. JMLR Workshop and Conference Proceedings (Mar 2010),https://proceedings.mlr. press/v9/gutmann10a.html
2010
-
[21]
arXiv preprint arXiv:2312.15946 (2023)
Han, B., Ren, Y., Peng, H., Zhang, T., Ling, Z., Yin, X., Han, F.: Enchant- dance: Unveiling the potential of music-driven dance movement. arXiv preprint arXiv:2312.15946 (2023)
Pith/arXiv arXiv 2023
-
[22]
In: Advances in Neural Information Processing Systems
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilib- rium. In: Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc. (2017), https://proceedings.neurips.cc/paper/2017/hash/ 8a1d694707eb0fefe65871369074926d-Abstract.html
2017
-
[23]
Neural Computation14(8), 1771–1800 (Aug 2002).https://doi.org/10
Hinton, G.E.: Training Products of Experts by Minimizing Contrastive Diver- gence. Neural Computation14(8), 1771–1800 (Aug 2002).https://doi.org/10. 1162/089976602760128018, https://ieeexplore.ieee.org/abstract/document/ 6789337 STREAM 17
2002
-
[24]
In: Ad- vances in Neural Information Processing Systems
Ho, J., Jain, A., Abbeel, P.: Denoising Diffusion Probabilistic Models. In: Ad- vances in Neural Information Processing Systems. vol. 33, pp. 6840–6851. Curran Associates, Inc. (2020), https://proceedings.neurips.cc/paper/2020/hash/ 4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html
2020
-
[25]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-Free Diffusion Guidance (Jul 2022).https://doi. org/10.48550/arXiv.2207.12598,http://arxiv.org/abs/2207.12598
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.12598 2022
-
[26]
https://doi.org/10.48550/arXiv.2006.06119 , http://arxiv.org/abs/2006
Huang, R., Hu, H., Wu, W., Sawada, K., Zhang, M., Jiang, D.: Dance Revolution: Long-Term Dance Generation with Music via Curriculum Learning (Sep 2023). https://doi.org/10.48550/arXiv.2006.06119 , http://arxiv.org/abs/2006. 06119
-
[27]
In: European Conference on Computer Vision (ECCV) (2024)
Huang, Y., Wan, W., Yang, Y., Callison-Burch, C., Yatskar, M., Liu, L.: Como: Controllable motion generation through language guided pose code editing. In: European Conference on Computer Vision (ECCV) (2024)
2024
-
[28]
In: European Conference on Computer Vision
Huang, Z., Xu, X., Xu, C., Zhang, H., Zheng, C., Qin, J., He, S.: Beat-it: Beat- synchronized multi-condition 3d dance generation. In: European Conference on Computer Vision. pp. 273–290. Springer (2024)
2024
-
[29]
Journal of Machine Learning Research6(4) (2005),https://www.jmlr
Hyvärinen, A., Dayan, P.: Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research6(4) (2005),https://www.jmlr. org/papers/volume6/hyvarinen05a/hyvarinen05a.pdf
2005
-
[30]
Dance Research Journal32(1), 116–125 (2000).https://doi.org/10.2307/1478285, https://www
Kaeppler, A.L.: Dance Ethnology and the Anthropology of Dance. Dance Research Journal32(1), 116–125 (2000).https://doi.org/10.2307/1478285, https://www. jstor.org/stable/1478285
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition
Kulkarni,N.,Rempe,D.,Genova,K.,Kundu,A.,Johnson,J.,Fouhey,D.,Guibas,L.: NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition. pp. 947–957 (2024),https://openaccess.thecvf.com/content/CVPR2024/ html/Kulkarni_NIFTY_Neural_Object_Interaction_Fields_f...
2024
-
[32]
05897,http://arxiv.org/abs/2212.05897
Lee, T., Moon, G., Lee, K.M.: MultiAct: Long-Term 3D Human Motion Generation from Multiple Action Labels (Feb 2023).https://doi.org/10.48550/arXiv.2212. 05897,http://arxiv.org/abs/2212.05897
-
[33]
Li, J., Yin, Y., Chu, H., Zhou, Y., Wang, T., Fidler, S., Li, H.: Learning to Generate Diverse Dance Motions with Transformer (Aug 2020).https://doi.org/10.48550/ arXiv.2008.08171,http://arxiv.org/abs/2008.08171
arXiv 2020
-
[34]
Li, J., Cao, J., Zhang, H., Rempe, D., Kautz, J., Iqbal, U., Yuan, Y.: GENMO: A GENeralist Model for Human MOtion (May 2025).https://doi.org/10.48550/ arXiv.2505.01425,http://arxiv.org/abs/2505.01425
arXiv 2025
-
[35]
Chemberta-2: Towards chemical foundation models.CoRR, abs/2209.01712, 2022
Li, R., Zhang, Y., Zhang, Y., Zhang, H., Guo, J., Zhang, Y., Liu, Y., Li, X.: Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives (Apr 2024).https://doi.org/10.48550/arXiv. 2403.10518,http://arxiv.org/abs/2403.10518
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[36]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision
Li, R., Zhao, J., Zhang, Y., Su, M., Ren, Z., Zhang, H., Tang, Y., Li, X.: FineDance: A Fine-grained Choreography Dataset for 3D Full Body Dance Generation. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10234– 10243 (2023), https://openaccess.thecvf.com/content/ICCV2023/html/Li_ FineDance_A_Fine-grained_Choreography_Da...
2023
-
[37]
Li, R., Yang, S., Ross, D.A., Kanazawa, A.: Ai choreographer: Music conditioned 3d dance generation with aist++ (2021)
2021
-
[38]
Yoo, et al
Li, R., Yang, S., Ross, D.A., Kanazawa, A.: Learn to dance with aist++: Music conditioned 3d dance generation (2021) 18 S.J. Yoo, et al
2021
-
[39]
Advances in Neural Information Processing Systems36, 25268– 25280 (Dec 2023), https : / / proceedings
Lin, J., Zeng, A., Lu, S., Cai, Y., Zhang, R., Wang, H., Zhang, L.: Motion-X: A Large-scale 3D Expressive Whole-body Human Motion Dataset. Advances in Neural Information Processing Systems36, 25268– 25280 (Dec 2023), https : / / proceedings . neurips . cc / paper _ files / paper / 2023 / hash / 4f8e27f6036c1d8b4a66b5b3a947dd7b - Abstract - Datasets _ and ...
2023
-
[40]
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinned multi-person linear model. ACM Transactions on Graphics34(6), 248:1–248:16 (2015). https://doi.org/10.1145/2816795.2818013, https://dl.acm.org/doi/ 10.1145/2816795.2818013
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Luo, Z., Ren, M., Hu, X., Huang, Y., Yao, L.: POPDG: Popular 3D Dance Genera- tion with PopDanceSet. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26984–26993 (2024)
2024
-
[42]
https://doi.org/10.48550/arXiv.2505.19377 , http://arxiv.org/abs/2505.19377
Meng, Z., Han, Z., Peng, X., Xie, Y., Jiang, H.: Absolute Coordinates Make Motion Generation Easy (May 2025). https://doi.org/10.48550/arXiv.2505.19377 , http://arxiv.org/abs/2505.19377
-
[43]
Müller, M., Röder, T., Clausen, M.: Efficient content-based retrieval of motion cap- ture data. In: ACM SIGGRAPH 2005 Papers. pp. 677–685. SIGGRAPH ’05, Associ- ation for Computing Machinery, New York, NY, USA (Jul 2005).https://doi.org/ 10.1145/1186822.1073247, https://dl.acm.org/doi/10.1145/1186822.1073247
-
[44]
In: Handbook of Markov Chain Monte Carlo
Neal, R.M.: MCMC Using Hamiltonian Dynamics. In: Handbook of Markov Chain Monte Carlo. Chapman and Hall/CRC (2011)
2011
-
[45]
Eurographics (Short Papers)7(10) (2008), http://reports-archive.adm.cs.cmu.edu/anon/2007/CMU-CS-07-164.pdf
Onuma, K., Faloutsos, C., Hodgins, J.K.: FMDistance: A Fast and Effective Distance Function for Motion Capture Data. Eurographics (Short Papers)7(10) (2008), http://reports-archive.adm.cs.cmu.edu/anon/2007/CMU-CS-07-164.pdf
2008
-
[46]
Advances in Neural Information Processing Systems36, 76382–76408 (Dec 2023), https : / / proceedings
Park, G.Y., Kim, J., Kim, B., Lee, S.W., Ye, J.C.: Energy-Based Cross Attention for Bayesian Context Update in Text-to-Image Diffusion Models. Advances in Neural Information Processing Systems36, 76382–76408 (Dec 2023), https : / / proceedings . neurips . cc / paper _ files / paper / 2023 / hash / f0878b7efa656b3bbd407c9248d13751-Abstract-Conference.html
2023
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Peebles, W., Xie, S.: Scalable Diffusion Models with Transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4195–4205 (2023), https://openaccess.thecvf.com/content/ICCV2023/html/Peebles_Scalable_ Diffusion_Models_with_Transformers_ICCV_2023_paper.html
2023
-
[48]
arXiv preprint arXiv:2404.00054 (2024)
Peng, S., Ladenheim, K., Shrestha, S., Fermüller, C.: Choreographing the digi- tal canvas: A machine learning approach to artistic performance. arXiv preprint arXiv:2404.00054 (2024)
arXiv 2024
-
[49]
In: Proceedings of the 9th International Conference on Movement and Computing
Peng, S., Ladenheim, K., Shrestha, S., Fermüller, C.: Generation of novel fall animation with configurable attributes. In: Proceedings of the 9th International Conference on Movement and Computing. MOCO ’24, Association for Computing Machinery, New York, NY, USA (2024). https://doi.org/10.1145/3658852. 3659087,https://doi.org/10.1145/3658852.3659087
-
[50]
In: International Conference on Computer Vision (ICCV) (2023)
Petrovich, M., Black, M.J., Varol, G.: TMR: Text-to-motion retrieval using con- trastive 3D human motion synthesis. In: International Conference on Computer Vision (ICCV) (2023)
2023
-
[51]
Plappert, M., Mandery, C., Asfour, T.: The KIT Motion-Language Dataset. Big Data4(4), 236–252 (Dec 2016).https://doi.org/10.1089/big.2016.0028, https: //www.liebertpub.com/doi/abs/10.1089/big.2016.0028
-
[52]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning Transferable STREAM 19 Visual Models From Natural Language Supervision (Feb 2021).https://doi.org/ 10.48550/arXiv.2103.00020,http://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.00020 2021
-
[53]
Hopfield Networks is All You Need
Ramsauer, H., Schäfl, B., Lehner, J., Seidl, P., Widrich, M., Adler, T., Gruber, L., Holzleitner, M., Pavlović, M., Sandve, G.K., Greiff, V., Kreil, D., Kopp, M., Klambauer, G., Brandstetter, J., Hochreiter, S.: Hopfield Networks is All You Need (Apr 2021). https://doi.org/10.48550/arXiv.2008.02217, http://arxiv.org/ abs/2008.02217
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2008.02217 2021
-
[54]
In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional Networks for Biomed- ical Image Segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. pp. 234–241. Springer International Publishing, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
-
[55]
arXiv preprint arXiv:2504.04634 (2025)
Shah, F.N., Shah, P., Saleem, M.U., Pinyoanuntapong, E., Wang, P., Xue, H., Helmy, A.: Dancemosaic: High-fidelity dance generation with multimodal editability. arXiv preprint arXiv:2504.04634 (2025)
arXiv 2025
-
[56]
Sievers, B., Polansky, L., Casey, M., Wheatley, T.: Music and movement share a dynamic structure that supports universal expressions of emotion. Proceedings of the National Academy of Sciences of the United States of America110(1), 70– 75 (Jan 2013).https://doi.org/10.1073/pnas.1209023110, https://pmc.ncbi. nlm.nih.gov/articles/PMC3538264/
-
[57]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Siyao, L., Yu, W., Gu, T., Lin, C., Wang, Q., Qian, C., Loy, C.C., Liu, Z.: Bai- lando: 3D Dance Generation by Actor-Critic GPT With Choreographic Memory. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11050–11059 (2022),https://openaccess.thecvf.com/content/ CVPR2022/html/Siyao_Bailando_3D_Dance_Generation_by_A...
2022
-
[58]
In: Proceedings of the 32nd International Conference on Machine Learning
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep Unsupervised Learning using Nonequilibrium Thermodynamics. In: Proceedings of the 32nd International Conference on Machine Learning. pp. 2256–2265. PMLR (Jun 2015), https://proceedings.mlr.press/v37/sohl-dickstein15.html
2015
-
[59]
Song, Y., Kingma, D.P.: How to Train Your Energy-Based Models (Feb 2021).https: //doi.org/10.48550/arXiv.2101.03288,http://arxiv.org/abs/2101.03288
-
[60]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-Based Generative Modeling through Stochastic Differential Equations (Feb 2021). https://doi.org/10.48550/arXiv.2011.13456 , http://arxiv.org/abs/ 2011.13456
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2011.13456 2021
-
[61]
Sun, J., Wang, C., Hu, H., Lai, H., Jin, Z., Hu, J.F.: You Never Stop Dancing: Non-freezing Dance Generation via Bank-constrained Manifold Pro- jection. Advances in Neural Information Processing Systems35, 9995–10007 (Dec 2022), https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 40bfe6177e8aed33c982264cf9e6e62c-Abstract-Conference.html
2022
-
[62]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human Motion Diffusion Model (Oct 2022). https://doi.org/10.48550/arXiv.2209. 14916,http://arxiv.org/abs/2209.14916
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209 2022
-
[63]
Tripathi, S., Taheri, O., Lassner, C., Black, M.J., Holden, D., Stoll, C.: HUMOS: Human Motion Model Conditioned on Body Shape (Sep 2024).https://doi.org/ 10.48550/arXiv.2409.03944,http://arxiv.org/abs/2409.03944
-
[64]
In: Proceedings of the Asian Conference on Computer Vision
Truong-Thuy, T.V., Bui-Le, G.C., Nguyen, H.D., Le, T.N.: Rethinking Sampling for Music-Driven Long-Term Dance Generation. In: Proceedings of the Asian Conference on Computer Vision. pp. 2667–2683 (2024),https://openaccess. 20 S.J. Yoo, et al. thecvf.com/content/ACCV2024/html/Truong-Thuy_Rethinking_Sampling_for_ Music-Driven_Long-Term_Dance_Generation_ACCV...
2024
-
[65]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tseng, J., Castellon, R., Liu, K.: Edge: Editable dance generation from music. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 448–458 (2023)
2023
-
[66]
arXiv preprint arXiv:2406.07871 (2024)
Wang, H., Zhu, Y., Geng, X.: Flexible music-conditioned dance generation with style description prompts. arXiv preprint arXiv:2406.07871 (2024)
arXiv 2024
-
[67]
Proceedings of the AAAI Conference on Artificial Intelligence39(24), 25615–25623 (Apr 2025)
Yang, H., Su, K., Zhang, Y., Chen, J., Qian, K., Liu, G., Gan, C.: UniMuMo: Unified Text, Music, and Motion Generation. Proceedings of the AAAI Conference on Artificial Intelligence39(24), 25615–25623 (Apr 2025). https://doi.org/ 10.1609/aaai.v39i24.34752, https://ojs.aaai.org/index.php/AAAI/article/ view/34752
-
[68]
In: Advances in Neural Information Processing Systems
Yuille, A.L., Rangarajan, A.: The Concave-Convex Procedure (CCCP). In: Advances in Neural Information Processing Systems. vol. 14. MIT Press (2001), https : / / proceedings . neurips . cc / paper / 2001 / hash / a012869311d64a44b5a0d567cd20de04-Abstract.html
2001
-
[69]
https://doi.org/10.48550/arXiv.2508.17342, http: //arxiv.org/abs/2508.17342
Zhang, H., Li, Z., Qi, X., Li, M., Sun, M., Zhang, M., Han, S.: DanceEditor: Towards Iterative Editable Music-driven Dance Generation with Open-Vocabulary Descriptions (Aug 2025). https://doi.org/10.48550/arXiv.2508.17342, http: //arxiv.org/abs/2508.17342
-
[70]
Zhang, J., Fan, H., Yang, Y.: EnergyMoGen: Compositional Human Motion Gen- eration with Energy-Based Diffusion Model in Latent Space (Dec 2024).https: //doi.org/10.48550/arXiv.2412.14706,http://arxiv.org/abs/2412.14706
-
[71]
48550/arXiv.2304.01116,http://arxiv.org/abs/2304.01116
Zhang, M., Guo, X., Pan, L., Cai, Z., Hong, F., Li, H., Yang, L., Liu, Z.: ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model (Apr 2023).https://doi.org/10. 48550/arXiv.2304.01116,http://arxiv.org/abs/2304.01116
arXiv 2023
-
[72]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the Continuity of Rotation Representations in Neural Networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5745–5753 (2019),https:// openaccess.thecvf.com/content_CVPR_2019/html/Zhou_On_the_Continuity_ of_Rotation_Representations_in_Neural_Networks_CVPR_2019_...
2019
-
[73]
Zhuang, W., Wang, C., Chai, J., Wang, Y., Shao, M., Xia, S.: Music2dance: Dancenet for music-driven dance generation. ACM Trans. Multimedia Comput. Commun. Appl.18(2) (Feb 2022). https://doi.org/10.1145/3485664 , https: //doi.org/10.1145/3485664 STREAM 21 Supplementary Material: Text Dictates, Music Decorates: Energy- based Attention for Editable Dance Mo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.