UniFS: Unified Fast-to-Slow Hierarchical Architecture for Vision-Language-Action Models
Pith reviewed 2026-06-26 08:55 UTC · model grok-4.3
The pith
A single vision-language model backbone can be stratified into fast-to-slow layers to resolve the frequency dilemma in vision-language-action systems and deliver both higher task success and lower inference latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
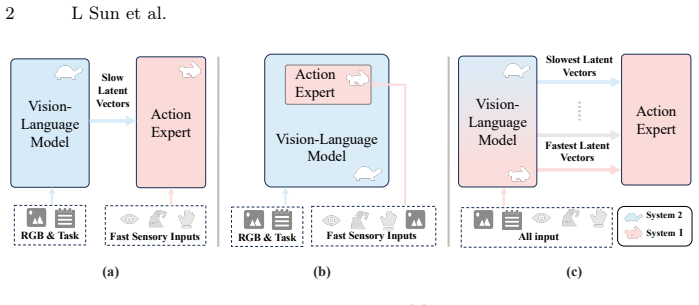
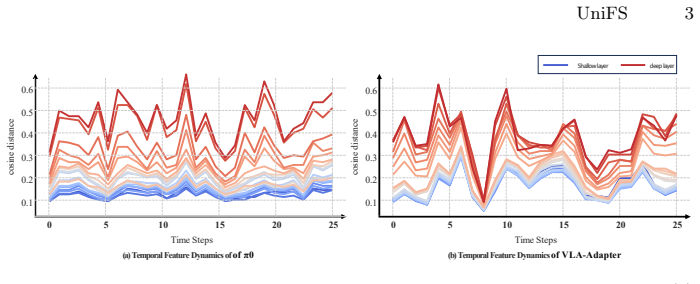
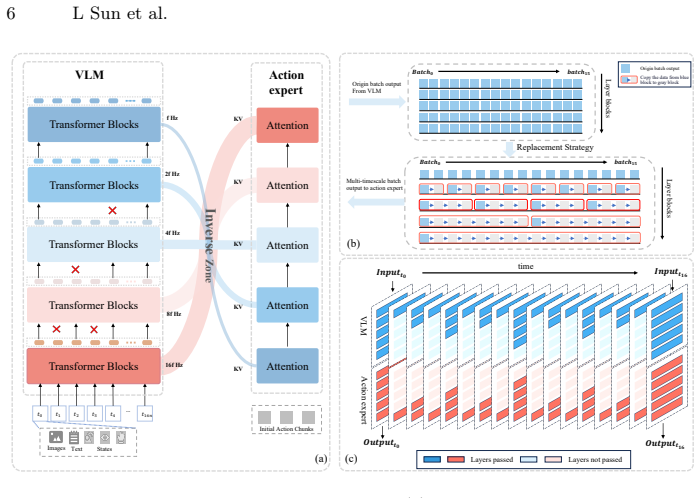
UniFS introduces a unified fast-to-slow architecture that resolves the frequency dilemma through three designs: stratifying VLM layers into groups with progressively decreasing update frequencies so shallow layers capture fast-changing dynamics and deeper layers cache stable semantics; a latent vector inversion mechanism that re-routes multi-scale VLM features to the action expert to align fast-varying representations with fine-grained decoding and slow-varying ones with coarse planning; and a multi-level supervision strategy that enforces coarse-to-fine learning across temporal scales. This enables richer cross-frequency transfer in one backbone while low-frequency paths preserve context ac
What carries the argument
The unified fast-to-slow hierarchical architecture that stratifies VLM layers by decreasing update frequency and uses latent vector inversion to align multi-scale features with action decoding.
If this is right
- Richer cross-frequency information transfer occurs inside a single backbone instead of across separate models.
- Low-frequency pathways preserve temporal context across multiple steps.
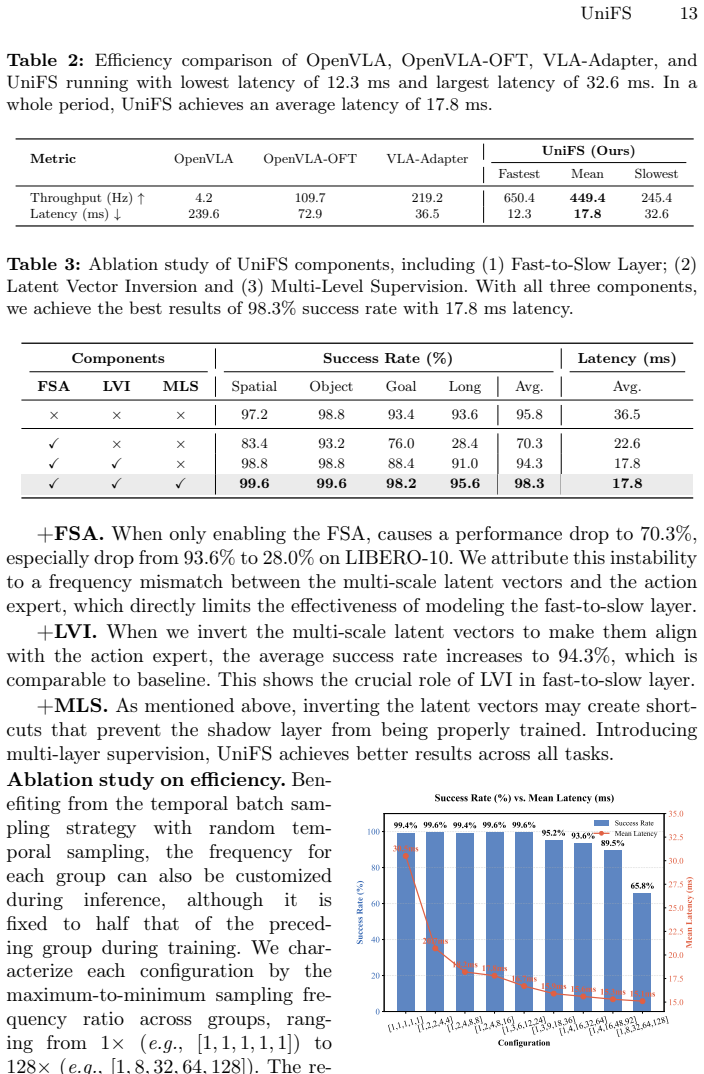
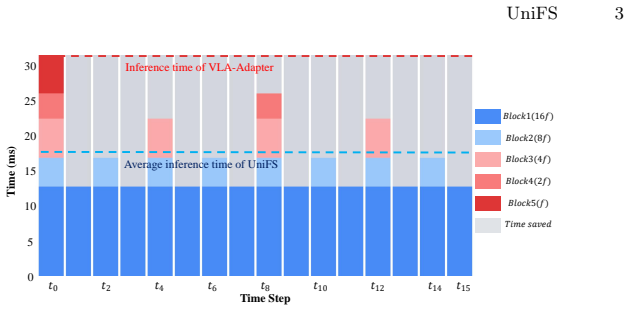
- State-of-the-art average success rate of 98.3 percent is reached on LIBERO with average inference latency cut from 36.5 ms to 17.8 ms.
- Practical applicability holds on a real Franka robot platform.
Where Pith is reading between the lines
- The same stratification idea could be tested on non-robotics tasks that require both fast reactions and slow planning, such as video prediction or real-time decision systems.
- If the multi-level supervision is the main driver of gains, then similar supervision patterns might improve other hierarchical models even without frequency changes.
- Longer-horizon tasks beyond the current benchmarks could reveal whether the preserved temporal context actually compounds over extended sequences.
Load-bearing premise
Progressively decreasing update frequencies across VLM layers will automatically align shallow fast-changing dynamics with fine-grained action decoding and deeper slow semantics with coarse planning without requiring additional cross-layer alignment losses.
What would settle it
Running the same LIBERO tasks with all layers forced to the same update frequency or with the latent vector inversion removed, and checking whether the 2.5 percent success gain and 2.1 times speedup both disappear, would directly test whether the frequency stratification and inversion are necessary.
Figures



read the original abstract
Mainstream Fast-Slow dual system vision-language-action models decouple a high-frequency action expert from a low-frequency vision-language model for efficiency, yet they face a fundamental frequency dilemma: large update gaps cause semantic drift from stale context, while small gaps erode the intended computational savings. Moreover, because the action expert receives only the VLM's final-layer representation at a single fixed frequency, rich intermediate features are discarded, limiting both information coupling and manipulation precision. Inspired by multi-timescale neural processing in the human brain, we introduce UniFS, a unified fast-to-slow architecture that resolves these challenges through three key designs. First, we stratify the VLM layers into groups with progressively decreasing update frequencies, enabling shallow layers to capture fast-changing dynamics while deeper layers cache stable semantic context. Second, a latent vector inversion mechanism re-routes the interaction order between multi-scale VLM features and the action expert, aligning fast-varying representations with fine-grained action decoding and slow-varying ones with coarse planning. Third, a multi-level supervision strategy enforces a coarse-to-fine learning hierarchy across temporal scales. Together, these designs enable richer cross-frequency information transfer within a single backbone, while the low-frequency pathways additionally preserve temporal context across steps. Experiments on LIBERO show that UniFS achieves state-of-the-art performance (98.3\% average success rate, a 2.5\% gain over VLA-Adapter baseline) while reducing average inference latency from 36.5~ms to 17.8~ms (2.1$\times$ speedup). Real-robot experiments on a Franka platform further validate its practical applicability. Code is opensourced at https://github.com/linsun449/UniFS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents UniFS, a unified fast-to-slow hierarchical architecture for vision-language-action (VLA) models. It addresses the frequency dilemma in fast-slow dual-system VLA models by stratifying VLM layers into groups with progressively decreasing update frequencies, introducing a latent vector inversion mechanism to re-route multi-scale features, and applying multi-level supervision for coarse-to-fine learning. Experiments on the LIBERO benchmark report state-of-the-art performance with 98.3% average success rate (2.5% improvement over VLA-Adapter) and a 2.1× reduction in inference latency from 36.5 ms to 17.8 ms, with additional validation on a real Franka robot platform. The code is open-sourced.
Significance. If the performance and efficiency gains prove robust, UniFS offers a promising direction for unifying fast and slow processing within a single VLM backbone, enabling richer cross-frequency information transfer while preserving temporal context. The open-sourced code at the provided GitHub link is a clear strength that supports reproducibility.
major comments (2)
- [Experiments on LIBERO] Experiments section: The reported 98.3% average success rate and 2.1× speedup (from 36.5 ms to 17.8 ms) are presented without information on experimental controls, statistical significance, baseline implementation details, or robustness across random seeds and environment variations. This makes it impossible to determine whether the gains are attributable to the three proposed designs rather than other factors.
- [Latent vector inversion mechanism] Method section on latent vector inversion: The description states that inversion re-routes interaction to align fast-varying representations with fine-grained action decoding and slow-varying ones with coarse planning, yet no derivation, intermediate feature analysis, or ablation demonstrates that the chosen frequencies plus inversion enforce this mapping (rather than merely reordering access) in the absence of additional cross-layer alignment losses beyond the stated multi-level supervision.
minor comments (2)
- [Abstract] The abstract refers to 'rich intermediate features' being discarded in prior work but does not quantify or reference which specific layers or representations are involved.
- [Method] Notation for the progressively decreasing update frequencies across layer groups would benefit from an explicit equation or table defining the frequency schedule per group.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we respond point-by-point to the major comments, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Experiments on LIBERO] Experiments section: The reported 98.3% average success rate and 2.1× speedup (from 36.5 ms to 17.8 ms) are presented without information on experimental controls, statistical significance, baseline implementation details, or robustness across random seeds and environment variations. This makes it impossible to determine whether the gains are attributable to the three proposed designs rather than other factors.
Authors: We agree that the current experimental reporting lacks sufficient controls and statistical details. In the revised manuscript we will add: (i) results across 5 random seeds with mean and standard deviation, (ii) explicit baseline re-implementation details including training hyperparameters and hardware, (iii) additional environment variation tests, and (iv) statistical significance measures (e.g., paired t-tests or confidence intervals). These additions will allow readers to better attribute performance gains to the proposed designs. revision: yes
-
Referee: [Latent vector inversion mechanism] Method section on latent vector inversion: The description states that inversion re-routes interaction to align fast-varying representations with fine-grained action decoding and slow-varying ones with coarse planning, yet no derivation, intermediate feature analysis, or ablation demonstrates that the chosen frequencies plus inversion enforce this mapping (rather than merely reordering access) in the absence of additional cross-layer alignment losses beyond the stated multi-level supervision.
Authors: The inversion is motivated by matching temporal scales to action granularity, with effectiveness shown via end-to-end performance and existing architecture ablations. We acknowledge the value of more direct evidence. In revision we will add an ablation isolating the inversion component and intermediate feature visualizations (e.g., cosine similarity or activation maps before/after inversion) to demonstrate the enforced alignment beyond simple reordering. revision: yes
Circularity Check
No circularity: empirical results from architectural proposal
full rationale
The paper introduces three architectural modifications (layer stratification by update frequency, latent vector inversion, multi-level supervision) to address frequency dilemmas in VLA models and reports empirical gains on LIBERO (98.3% success, 2.1× speedup). No equations, parameter fits, or self-citations appear in the abstract or described claims that would reduce the performance numbers to inputs by construction. The outcome is presented as an experimental consequence of the designs rather than a derived quantity equivalent to the inputs; the central claim remains an independent empirical observation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023) 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2512.24695 (2025) 2
Behrouz,A.,Razaviyayn,M.,Zhong,P.,Mirrokni,V.:Nestedlearning:Theillusion of deep learning architectures. arXiv preprint arXiv:2512.24695 (2025) 2
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025) 2, 4, 6, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024) 2, 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
arXiv preprint arXiv:2410.08001 (2024) 4, 6
Bu, Q., Li, H., Chen, L., Cai, J., Zeng, J., Cui, H., Yao, M., Qiao, Y.: Towards synergistic, generalized, and efficient dual-system for robotic manipulation. arXiv preprint arXiv:2410.08001 (2024) 4, 6
-
[6]
WorldVLA: Towards Autoregressive Action World Model
Cen, J., Yu, C., Yuan, H., Jiang, Y., Huang, S., Guo, J., Li, X., Song, Y., Luo, H., Wang, F., et al.: Worldvla: Towards autoregressive action world model. arXiv preprint arXiv:2506.21539 (2025) 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2506.01953 (2025) 2
Chen, H., Liu, J., Gu, C., Liu, Z., Zhang, R., Li, X., He, X., Guo, Y., Fu, C.W., Zhang, S., et al.: Fast-in-slow: A dual-system foundation model unifying fast ma- nipulation within slow reasoning. arXiv preprint arXiv:2506.01953 (2025) 2
-
[8]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In: European Conference on Computer Vision. pp. 19–35. Springer (2024) 2
2024
-
[9]
The International Journal of Robotics Research44(10-11), 1684–1704 (2025) 12
Chi,C.,Xu,Z.,Feng,S.,Cousineau,E.,Du,Y.,Burchfiel,B.,Tedrake,R.,Song,S.: Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research44(10-11), 1684–1704 (2025) 12
2025
-
[10]
In: 2020 IEEE-RAS 20th International Conference on Humanoid Robots (Humanoids)
Chignoli, M., Kim, D., Stanger-Jones, E., Kim, S.: The mit humanoid robot: De- sign, motion planning, and control for acrobatic behaviors. In: 2020 IEEE-RAS 20th International Conference on Humanoid Robots (Humanoids). pp. 1–8. IEEE (2021) 2
2020
-
[11]
arXiv preprint arXiv:2505.03912 (2025) 2, 4 16 L Sun et al
Cui, C., Ding, P., Song, W., Bai, S., Tong, X., Ge, Z., Suo, R., Zhou, W., Liu, Y., Jia, B., et al.: Openhelix: A short survey, empirical analysis, and open-source dual-system vla model for robotic manipulation. arXiv preprint arXiv:2505.03912 (2025) 2, 4 16 L Sun et al
-
[12]
GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
Deng, S., Yan, M., Wei, S., Ma, H., Yang, Y., Chen, J., Zhang, Z., Yang, T., Zhang, X., Zhang, W., et al.: Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data. arXiv preprint arXiv:2505.03233 (2025) 2, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Himoe-vla: Hierarchical mixture-of- experts for generalist vision-language-action policies,
Du, Z., Liu, B., Liang, Y., Shen, Y., Cao, H., Zheng, X., Feng, Z., Wu, Z., Yang, J., Jiang, Y.G.: Himoe-vla: Hierarchical mixture-of-experts for generalist vision- language-action policies. arXiv preprint arXiv:2512.05693 (2025) 6
-
[14]
arXiv preprint arXiv:2410.15549 (2024) 2, 6
Han, B., Kim, J., Jang, J.: A dual process vla: Efficient robotic manipulation leveraging vlm. arXiv preprint arXiv:2410.15549 (2024) 2, 6
-
[15]
arXiv preprint arXiv:2312.08782 (2023) 2
Hu, Y., Xie, Q., Jain, V., Francis, J., Patrikar, J., Keetha, N., Kim, S., Xie, Y., Zhang,T.,Fang,H.S.,etal.:Towardgeneral-purposerobotsviafoundationmodels: A survey and meta-analysis. arXiv preprint arXiv:2312.08782 (2023) 2
-
[16]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.:π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054 (2025) 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Fron- tiers in human neuroscience13, 426 (2019) 5
Jerath, R., Beveridge, C., Jensen, M.: On the hierarchical organization of oscilla- tory assemblies: layered superimposition and a global bioelectric framework. Fron- tiers in human neuroscience13, 426 (2019) 5
2019
-
[18]
arXiv preprint arXiv:2509.12594 (2025) 2
Jiang, T., Jiang, X., Ma, Y., Wen, X., Li, B., Zhan, K., Jia, P., Liu, Y., Sun, S., Lang, X.: The better you learn, the smarter you prune: Towards efficient vision-language-action models via differentiable token pruning. arXiv preprint arXiv:2509.12594 (2025) 2
-
[19]
macmillan (2011) 2, 4
Kahneman, D.: Thinking, fast and slow. macmillan (2011) 2, 4
2011
-
[20]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success. arXiv preprint arXiv:2502.19645 (2025) 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024) 2, 4, 7, 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Li, W., Zhang, R., Shao, R., He, J., Nie, L.: Cogvla: Cognition-aligned vision- language-action model via instruction-driven routing & sparsification. arXiv preprint arXiv:2508.21046 (2025) 2, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
arXiv preprint arXiv:2506.12723 (2025) 2, 12
Li, Y., Meng, Y., Sun, Z., Ji, K., Tang, C., Fan, J., Ma, X., Xia, S., Wang, Z., Zhu, W.: Sp-vla: A joint model scheduling and token pruning approach for vla model acceleration. arXiv preprint arXiv:2506.12723 (2025) 2, 12
-
[24]
arXiv preprint arXiv:2502.05485 (2025) 6
Li, Y., Deng, Y., Zhang, J., Jang, J., Memmel, M., Yu, R., Garrett, C.R., Ramos, F., Fox, D., Li, A., et al.: Hamster: Hierarchical action models for open-world robot manipulation. arXiv preprint arXiv:2502.05485 (2025) 6
-
[25]
Li, Z., Hu, B., Shao, R., Chen, G., Jiang, D., Xie, P., Hao, J., Nie, L.: Global prior meets local consistency: Dual-memory augmented vision-language-action model for efficient robotic manipulation. arXiv preprint arXiv:2602.20200 (2026) 6
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Advances in Neural Information Processing Systems36, 44776–44791 (2023) 10
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Benchmark- ing knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems36, 44776–44791 (2023) 10
2023
-
[27]
arXiv preprint arXiv:2505.07634 (2025) 5
Liu, J., Shi, X., Nguyen, T.D., Zhang, H., Zhang, T., Sun, W., Li, Y., Vasilakos, A.V.,Iacca,G.,Khan,A.A.,etal.:Neuralbrain:aneuroscience-inspiredframework for embodied agents. arXiv preprint arXiv:2505.07634 (2025) 5
-
[28]
A Survey on Vision-Language-Action Models for Embodied AI
Ma, Y., Song, Z., Zhuang, Y., Hao, J., King, I.: A survey on vision-language-action models for embodied ai. arXiv preprint arXiv:2405.14093 (2024) 2 UniFS 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Pertsch, K., Stachowicz, K., Ichter, B., Driess, D., Nair, S., Vuong, Q., Mees, O., Finn, C., Levine, S.: Fast: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv:2501.09747 (2025) 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
arXiv preprint arXiv:2508.21112 (2025) 12
Qu, D., Song, H., Chen, Q., Chen, Z., Gao, X., Ye, X., Lv, Q., Shi, M., Ren, G., Ruan, C., et al.: Eo-1: Interleaved vision-text-action pretraining for general robot control. arXiv preprint arXiv:2508.21112 (2025) 12
-
[32]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Qu, D., Song, H., Chen, Q., Yao, Y., Ye, X., Ding, Y., Wang, Z., Gu, J., Zhao, B., Wang, D., et al.: Spatialvla: Exploring spatial representations for visual-language- action model. arXiv preprint arXiv:2501.15830 (2025) 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Vision-language-action (vla) models: Concepts, progress, applications and challenges,
Sapkota, R., Cao, Y., Roumeliotis, K.I., Karkee, M.: Vision-language-action (vla) models: Concepts, progress, applications and challenges. arXiv preprint arXiv:2505.04769 (2025) 5
-
[34]
Nature Reviews Neuroscience25(9), 625–642 (2024) 5
Senkowski, D., Engel, A.K.: Multi-timescale neural dynamics for multisensory in- tegration. Nature Reviews Neuroscience25(9), 625–642 (2024) 5
2024
-
[35]
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Shi, H., Xie, B., Liu, Y., Sun, L., Liu, F., Wang, T., Zhou, E., Fan, H., Zhang, X., Huang, G.: Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. arXiv preprint arXiv:2508.19236 (2025) 2, 4, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Trends in cognitive sciences23(7), 572–583 (2019) 5
Shine, J.M.: Neuromodulatory influences on integration and segregation in the brain. Trends in cognitive sciences23(7), 572–583 (2019) 5
2019
-
[37]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Shukor, M., Aubakirova, D., Capuano, F., Kooijmans, P., Palma, S., Zoui- tine, A., Aractingi, M., Pascal, C., Russi, M., Marafioti, A., et al.: Smolvla: A vision-language-action model for affordable and efficient robotics. arXiv preprint arXiv:2506.01844 (2025) 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Frontiers in Psychology17, 1704370 (2026) 5
Snyder, A.C.: Resonant hierarchies: a multiscale framework for oscillatory dynam- ics in the brain. Frontiers in Psychology17, 1704370 (2026) 5
2026
-
[39]
arXiv preprint arXiv:2505.21432 (2025) 2
Song, H., Qu, D., Yao, Y., Chen, Q., Lv, Q., Tang, Y., Shi, M., Ren, G., Yao, M., Zhao, B., et al.: Hume: Introducing system-2 thinking in visual-language-action model. arXiv preprint arXiv:2505.21432 (2025) 2
-
[40]
In: 2025 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS)
Song, W., Chen, J., Ding, P., Zhao, H., Zhao, W., Zhong, Z., Ge, Z., Li, Z., Wang, D., Wang, L., et al.: Pd-vla: Accelerating vision-language-action model integrated with action chunking via parallel decoding. In: 2025 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS). pp. 13162–13169. IEEE (2025) 12
2025
-
[41]
Tan, X., Yang, Y., Ye, P., Zheng, J., Bai, B., Wang, X., Hao, J., Chen, T.: Think twice, act once: Token-aware compression and action reuse for efficient inference in vision-language-action models. arXiv preprint arXiv:2505.21200 (2025) 2
-
[42]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
arXiv preprint arXiv:2509.09372 (2025) 7, 12
Wang, Y., Ding, P., Li, L., Cui, C., Ge, Z., Tong, X., Song, W., Zhao, H., Zhao, W., Hou, P., et al.: Vla-adapter: An effective paradigm for tiny-scale vision-language- action model. arXiv preprint arXiv:2509.09372 (2025) 7, 12
-
[44]
arXiv preprint arXiv:2412.03293 (2024) 4
Wen, J., Zhu, M., Zhu, Y., Tang, Z., Li, J., Zhou, Z., Li, C., Liu, X., Peng, Y., Shen, C., et al.: Diffusion-vla: Generalizable and interpretable robot foundation model via self-generated reasoning. arXiv preprint arXiv:2412.03293 (2024) 4
-
[45]
IEEE Robotics and Automation Letters (2025) 2 18 L Sun et al
Wen, J., Zhu, Y., Li, J., Zhu, M., Tang, Z., Wu, K., Xu, Z., Liu, N., Cheng, R., Shen, C., et al.: Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation. IEEE Robotics and Automation Letters (2025) 2 18 L Sun et al
2025
-
[46]
arXiv e-prints pp
Xu, S., Wang, Y., Xia, C., Zhu, D., Huang, T., Xu, C.: Vla-cache: Towards efficient vision-language-action model via adaptive token caching in robotic manipulation. arXiv e-prints pp. arXiv–2502 (2025) 12
2025
-
[47]
arXiv preprint arXiv:2510.24795 (2025) 5
Yu, Z., Wang, B., Zeng, P., Zhang, H., Zhang, J., Gao, L., Song, J., Sebe, N., Shen, H.T.: A survey on efficient vision-language-action models. arXiv preprint arXiv:2510.24795 (2025) 5
-
[48]
Advances in Neural Information Processing Systems37, 56619–56643 (2024) 2
Yue, Y., Wang, Y., Kang, B., Han, Y., Wang, S., Song, S., Feng, J., Huang, G.: Deer-vla:Dynamicinferenceofmultimodallargelanguagemodelsforefficientrobot execution. Advances in Neural Information Processing Systems37, 56619–56643 (2024) 2
2024
-
[49]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023) 7
2023
-
[50]
Pure vision language action (vla) models: A comprehensive survey,
Zhang, D., Sun, J., Hu, C., Wu, X., Yuan, Z., Zhou, R., Shen, F., Zhou, Q.: Pure vision language action (vla) models: A comprehensive survey. arXiv preprint arXiv:2509.19012 (2025) 5
-
[51]
arXiv preprint arXiv:2410.05273 (2024) 4
Zhang, J., Guo, Y., Chen, X., Wang, Y.J., Hu, Y., Shi, C., Chen, J.: Hirt: Enhancing robotic control with hierarchical robot transformers. arXiv preprint arXiv:2410.05273 (2024) 4
-
[52]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhao, Q., Lu, Y., Kim, M.J., Fu, Z., Zhang, Z., Wu, Y., Li, Z., Ma, Q., Han, S., Finn, C., et al.: Cot-vla: Visual chain-of-thought reasoning for vision-language- action models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1702–1713 (2025) 2, 12
2025
-
[53]
Zheng, J., Li, J., Liu, D., Zheng, Y., Wang, Z., Ou, Z., Liu, Y., Liu, J., Zhang, Y.Q., Zhan,X.:Universalactionsforenhancedembodiedfoundationmodels.In:Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 22508–22519 (2025) 12
2025
-
[54]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Zheng, J., Li, J., Wang, Z., Liu, D., Kang, X., Feng, Y., Zheng, Y., Zou, J., Chen, Y., Zeng, J., et al.: X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274 (2025) 2, 4, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Zhu, Y., Wong, J., Mandlekar, A., Martín-Martín, R., Joshi, A., Lin, K., Mad- dukuri, A., Nasiriany, S., Zhu, Y.: robosuite: A modular simulation framework and benchmark for robot learning. arXiv preprint arXiv:2009.12293 (2020) 11
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[56]
In: Conference on Robot Learning
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183. PMLR (2023) 2, 4 UniFS 1 A Detailed Architecture As shown in Table 4, in our implementation, we find that the vision e...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.