Chains That See, Answers That Don't: A Multi-Aspect Evaluation Recipe for Forced Chain-of-Thought on Video-MME
Pith reviewed 2026-06-26 09:25 UTC · model grok-4.3
The pith
Forced chain-of-thought produces video-conditioned reasoning chains on Video-MME yet leaves multiple-choice accuracy unchanged or slightly lower.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
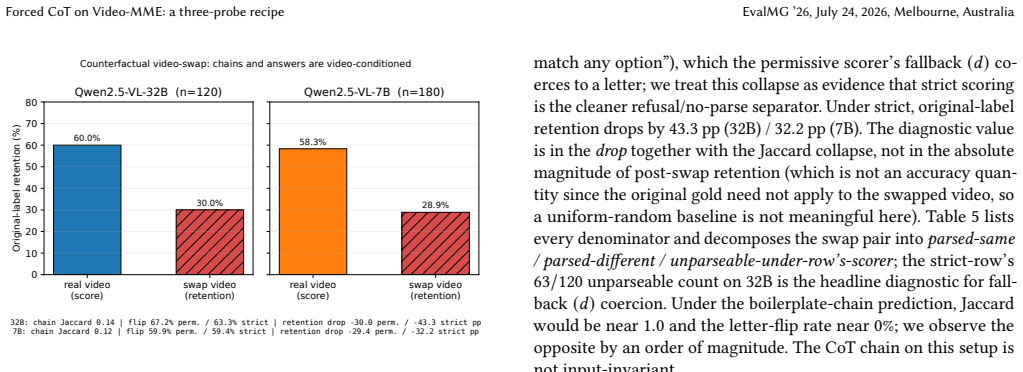
On the Video-MME benchmark the CoT chains generated by Qwen2.5-VL are demonstrably video-conditioned, since swapping the video collapses chain overlap and changes most final answer letters, yet the same forced-CoT regime produces no increase in multiple-choice accuracy and a statistically supported decrease on the 7B model under the manuscript's primary scorer.
What carries the argument
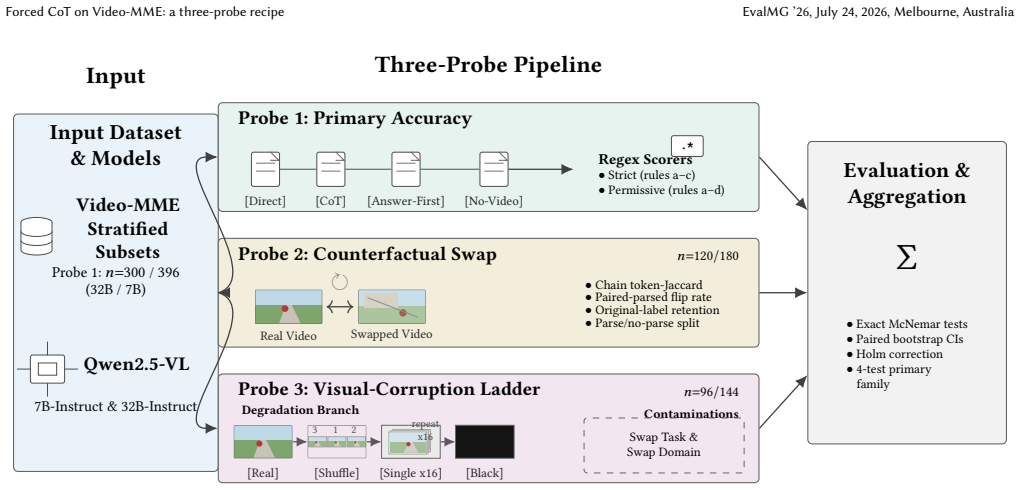
Three-probe evaluation recipe consisting of paired accuracy across direct/CoT/answer-first/no-video conditions, a counterfactual video-swap diagnostic on the generated chains, and a four-rung visual-degradation ladder, each reported under strict and permissive regex scorers with multiplicity correction.
If this is right
- CoT chains are not boilerplate text but respond to the specific video content.
- Forcing explicit reasoning steps does not raise MCQ accuracy on this benchmark and model family.
- Accuracy measurements can differ by a few points depending on whether a strict or permissive answer extractor is used.
- The three-probe recipe can be applied to other video QA datasets and models without requiring new annotations.
Where Pith is reading between the lines
- If the video-swap diagnostic holds on other models, it would indicate that current VLMs do use visual input inside their reasoning traces even when accuracy does not improve.
- A natural next measurement would be whether allowing the model to choose when to produce CoT (rather than forcing it) changes the accuracy outcome.
- The released raw responses allow direct comparison of chain quality against human-written reasoning on the same questions.
Load-bearing premise
The strict and permissive regex scorers together with the declared primary family for correction capture model answers without introducing parsing bias that affects the reported accuracy drop.
What would settle it
Recompute the accuracy tables on the released raw responses using an independent string-matching procedure that does not rely on the original regex patterns; if the small drop on the 7B model disappears, the central negative finding is falsified.
Figures



read the original abstract
Forced chain-of-thought (CoT) is widely assumed to make vision-language models more reliable on video question answering. We propose a small three-probe evaluation recipe to test that assumption: paired accuracy across direct, CoT, answer-first, and no-video conditions; a counterfactual video-swap diagnostic over the CoT chains; and a four-rung visual-degradation ladder. Each probe is reported under both a strict and a permissive regex scorer, with multiplicity correction over a manuscript-declared primary family. Applied to Qwen2.5-VL on Video-MME subsets, the recipe returns a two-part finding. The CoT chains are strongly video-conditioned: swapping the input video collapses chain overlap and flips most final letters, the opposite of what a "boilerplate-chain" null would predict. Yet on the same data, forced CoT does not improve MCQ accuracy, and on the smaller 7B model it produces a small but statistically supported drop under a post-hoc primary scorer choice. We do not claim this generalizes beyond the Qwen2.5-VL / Video-MME instantiation; the raw responses and a single recomputation script will be released with the supplementary material so every number can be re-derived.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a three-probe evaluation recipe (paired accuracy across direct/CoT/answer-first/no-video conditions, counterfactual video-swap diagnostic, and visual-degradation ladder) applied to Qwen2.5-VL on Video-MME subsets. It reports that forced CoT chains are strongly video-conditioned (swaps collapse overlap and flip answers), yet forced CoT yields no MCQ accuracy gain and a small statistically supported drop on the 7B model under a post-hoc primary scorer choice, with all measurements using strict/permissive regex scorers plus multiplicity correction; raw responses and a recomputation script are to be released.
Significance. If the empirical findings hold, the work challenges the assumption that forced CoT improves reliability for video QA in VLMs and supplies a compact, reusable diagnostic recipe. The explicit release of raw responses and a single recomputation script is a clear strength, allowing every reported number to be independently re-derived from the same data.
major comments (1)
- [Abstract] Abstract: The headline negative claim—that forced CoT produces no accuracy improvement and a small but statistically supported drop on the 7B model—is explicitly qualified as holding 'under a post-hoc primary scorer choice.' Because the primary family for multiplicity correction was selected after inspecting results, the statistical support for the accuracy drop may be sensitive to this analysis choice rather than reflecting a pre-specified procedure; this directly bears on the central claim that forced CoT does not help (and may hurt) accuracy on the same data where the video-swap diagnostic succeeds.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the implications of our post-hoc analysis choice. We address the single major comment below and are prepared to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline negative claim—that forced CoT produces no accuracy improvement and a small but statistically supported drop on the 7B model—is explicitly qualified as holding 'under a post-hoc primary scorer choice.' Because the primary family for multiplicity correction was selected after inspecting results, the statistical support for the accuracy drop may be sensitive to this analysis choice rather than reflecting a pre-specified procedure; this directly bears on the central claim that forced CoT does not help (and may hurt) accuracy on the same data where the video-swap diagnostic succeeds.
Authors: We agree that the primary scorer family was selected after inspecting the results, as already signaled by the explicit 'post-hoc' qualifier in the abstract. The manuscript declares the primary family (strict/permissive scorers across the four conditions) and applies multiplicity correction within it, but we did not pre-register the choice. This does limit the strength of any claim to statistical support for the accuracy drop. The video-swap diagnostic itself does not rely on this correction and remains unaffected. We will revise the abstract and the results section to (a) restate the post-hoc nature more prominently, (b) present the accuracy comparison both with and without multiplicity correction, and (c) frame the drop as an observed pattern under the chosen analysis rather than a pre-specified statistical finding. The released recomputation script already permits readers to test alternative families. revision: yes
Circularity Check
No significant circularity; purely empirical evaluation with direct measurements.
full rationale
The paper reports empirical accuracy comparisons across CoT conditions on Video-MME using regex-based scorers and multiplicity correction. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the derivation chain. All claims rest on observable model outputs under controlled conditions rather than any reduction to inputs by construction. The post-hoc qualifier on the primary scorer is a methodological note but does not create circularity under the defined patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying statistical significance testing and multiplicity correction for the reported accuracy drop
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
Pith/arXiv arXiv 2025
-
[2]
Chengkun Cai, Xu Zhao, Haoliang Liu, Zhongyu Jiang, Tianfang Zhang, Zongkai Wu, Jenq-Neng Hwang, and Lei Li. 2025. The Role of Deductive and Inductive Reasoning in Large Language Models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 16780–16790....
-
[3]
Yihang Chen, Pin Qian, Su Wang, Sipeng Zhang, Huan Xu, Shuhuai Lin, and Xinpeng Wei. 2026. Does RAG Know When Retrieval Is Wrong? Diagnosing Context Compliance under Knowledge Conflict. arXiv:2605.14473 [cs.CL] https: //arxiv.org/abs/2605.14473
Pith/arXiv arXiv 2026
-
[4]
Tibshirani
Bradley Efron and Robert J. Tibshirani. 1993.An Introduction to the Bootstrap. Number 57 in Monographs on Statistics and Applied Probability. Chapman & Hall/CRC
1993
-
[5]
Fagerland, Stian Lydersen, and Petter Laake
Morten W. Fagerland, Stian Lydersen, and Petter Laake. 2013. The McNemar Test for Binary Matched-Pairs Data: Mid-𝑝 and Asymptotic Are Better Than Exact Conditional.BMC Medical Research Methodology13 (2013), 91. doi:10.1186/1471- 2288-13-91
-
[6]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. 2025. Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysi...
-
[7]
Sture Holm. 1979. A Simple Sequentially Rejective Multiple Test Procedure. Scandinavian Journal of Statistics6, 2 (1979), 65–70
1979
-
[8]
Yuelyu Ji, Wuwei Lan, and Patrick Ng. 2025. MRAG-Suite: A Diagnostic Eval- uation Platform for Visual Retrieval-Augmented Generation.arXiv preprint arXiv:2509.24253(2025). https://arxiv.org/abs/2509.24253
arXiv 2025
-
[9]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large Language Models are Zero-Shot Reasoners. InAdvances in Neural Information Processing Systems 35 (NeurIPS 2022). https://arxiv.org/abs/ 2205.11916
Pith/arXiv arXiv 2022
-
[10]
Daniël Lakens. 2017. Equivalence Tests: A Practical Primer for 𝑡 Tests, Correla- tions, and Meta-Analyses.Social Psychological and Personality Science8, 4 (2017), 355–362. doi:10.1177/1948550617697177 EvalMG ’26, July 24, 2026, Melbourne, Australia Fan, Li, and Zhuang
-
[11]
Tian Lan, Jinyuan Xu, Xue He, Jenq-Neng Hwang, and Lei Li. 2025. Attention Consistency for LLMs Explanation. InFindings of the Association for Compu- tational Linguistics: EMNLP 2025. Association for Computational Linguistics, Suzhou, China, 1736–1750. doi:10.18653/v1/2025.findings-emnlp.91
-
[12]
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamile Lukosiute, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy Maxwel...
Pith/arXiv arXiv 2023
-
[13]
Lei Li. 2024. CPSeg: Finer-Grained Image Semantic Segmentation via Chain-of-Thought Language Prompting. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). 513–522. https://openaccess.thecvf.com/content/WACV2024/html/Li_CPSeg_Finer- Grained_Image_Semantic_Segmentation_via_Chain-of-Thought_Language_ Prompting_WACV_20...
2024
-
[14]
Lei Li, Sen Jia, Jianhao Wang, Zhongyu Jiang, Feng Zhou, Ju Dai, Tianfang Zhang, Zongkai Wu, and Jenq-Neng Hwang. 2025. Human Motion Instruction Tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). https://arxiv.org/abs/2411.16805
arXiv 2025
-
[15]
Yanhang Li, Zhichao Fan, and Zexin Zhuang. 2026. Auditing Reasoning-Trace Memorization Claims after Unlearning with Head-Conditioned Canaries.arXiv preprint arXiv:2605.18891(2026). https://arxiv.org/abs/2605.18891
Pith/arXiv arXiv 2026
-
[16]
Yanhang Li, Zhichao Fan, and Zexin Zhuang. 2026. SafetyRepro: Configuration- Conditional Rank Instability on Alignment Benchmarks.arXiv preprint arXiv:2605.25492(2026). https://arxiv.org/abs/2605.25492
Pith/arXiv arXiv 2026
-
[17]
Hanjun Luo, Ziye Deng, Ruizhe Chen, and Zuozhu Liu. 2024. FAIntbench: A Holistic and Precise Benchmark for Bias Evaluation in Text-to-Image Models. arXiv preprint arXiv:2405.17814(2024). https://arxiv.org/abs/2405.17814 Accepted by ICML DMLR 2024
arXiv 2024
-
[18]
Hanjun Luo, Haoyu Huang, Ziye Deng, Xinfeng Li, Hewei Wang, Yingbin Jin, Yang Liu, Wenyuan Xu, and Zuozhu Liu. 2024. BIGbench: A Unified Benchmark for Evaluating Multi-Dimensional Social Biases in Text-to-Image Models.arXiv preprint arXiv:2407.15240(2024). https://arxiv.org/abs/2407.15240
arXiv 2024
-
[19]
Hanjun Luo, Zhimu Huang, Haoyu Huang, Ziye Deng, Ruizhe Chen, Xinfeng Li, Zuozhu Liu, and Hanan Salam. 2026. BiasIG: Benchmarking Multi-Dimensional Social Biases in Text-to-Image Models.arXiv preprint arXiv:2604.11934(2026). https://arxiv.org/abs/2604.11934 Accepted by IJCNN 2026
Pith/arXiv arXiv 2026
-
[20]
Aman Madaan and Amir Yazdanbakhsh. 2022. Text and Patterns: For Effective Chain of Thought, It Takes Two to Tango.arXiv preprint arXiv:2209.07686(2022). https://arxiv.org/abs/2209.07686
arXiv 2022
-
[21]
Quinn McNemar. 1947. Note on the Sampling Error of the Difference Between Correlated Proportions or Percentages.Psychometrika12, 2 (1947), 153–157. doi:10.1007/BF02295996
-
[22]
Pin Qian, Su Wang, Xiaoyuan Wang, Yihang Chen, Wenxuan Xu, Qiaolin Yu, Shuhuai Lin, Sipeng Zhang, Junxian You, and Xinpeng Wei. 2026. Relevant Is Not Warranted: Evidence-Force Calibration for Cited RAG. arXiv:2605.28044 [cs.AI] https://arxiv.org/abs/2605.28044
Pith/arXiv arXiv 2026
-
[23]
Qwen Team. 2025. Qwen2.5-VL-32B: Smarter and Lighter. Qwen blog, March 24,
2025
-
[24]
https://qwenlm.github.io/blog/qwen2.5-vl-32b/
-
[25]
Schuirmann
Donald J. Schuirmann. 1987. A Comparison of the Two One-Sided Tests Procedure and the Power Approach for Assessing the Equivalence of Average Bioavailability. Journal of Pharmacokinetics and Biopharmaceutics15, 6 (1987), 657–680. doi:10. 1007/BF01068419
1987
-
[26]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. Lan- guage Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023). https://arxiv.org/abs/2305.04388
Pith/arXiv arXiv 2023
-
[27]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems 35 (NeurIPS 2022). https://arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2022
-
[28]
Ziyu Yao, Xuxin Cheng, Zhiqi Huang, and Lei Li. 2025. CountLLM: Towards Gen- eralizable Repetitive Action Counting via Large Language Model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). https://arxiv.org/abs/2503.17690
arXiv 2025
-
[29]
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. 2024. Multimodal Chain-of-Thought Reasoning in Language Models. Transactions on Machine Learning Research(2024). https://arxiv.org/abs/2302. 00923
2024
-
[30]
Zexin Zhuang, Yanhang Li, and Zhichao Fan. 2026. Pre-Registering the Detectable Effect: A Paired-MDE Budget for 4-Bit Quantization Benchmarks, with a Pilot Audit.arXiv preprint arXiv:2605.28873(2026). https://arxiv.org/abs/2605.28873 A Subtitle ablation (32B only) When video subtitles (SRT) are available, we can inject them as a prompt prefix. Of the 300 ...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.