Test-Driven, AI-Assisted Learning: Replacing Lectures with Weekly Closed-Book Tests
Pith reviewed 2026-06-26 05:53 UTC · model grok-4.3
The pith
Weekly closed-book tests paired with AI-assisted self-study can replace lectures while keeping students accountable in an upper-level theory course.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
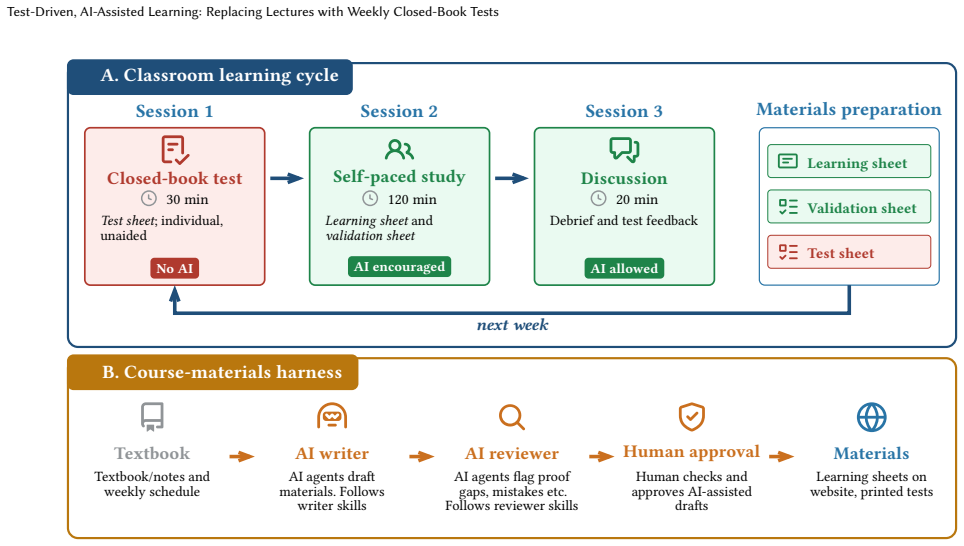
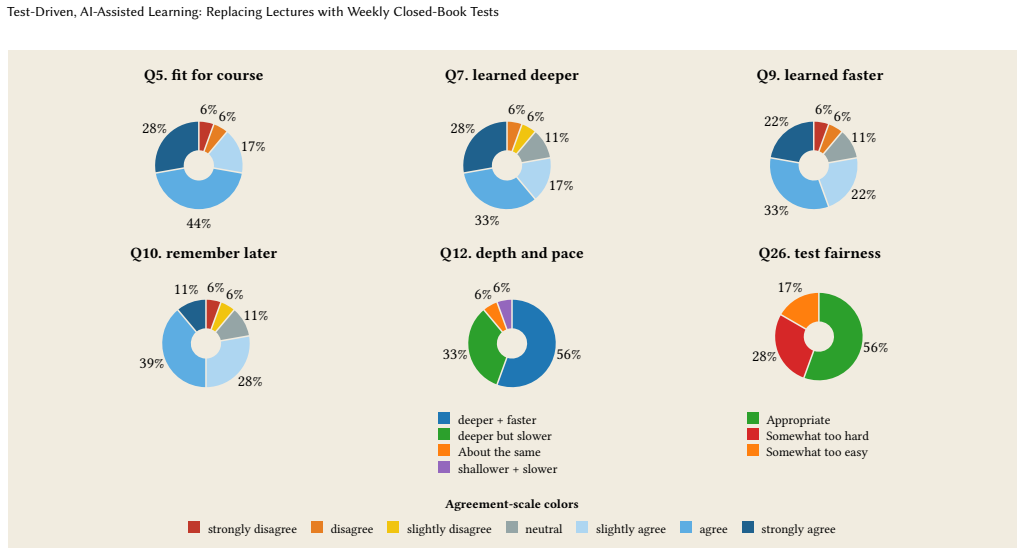
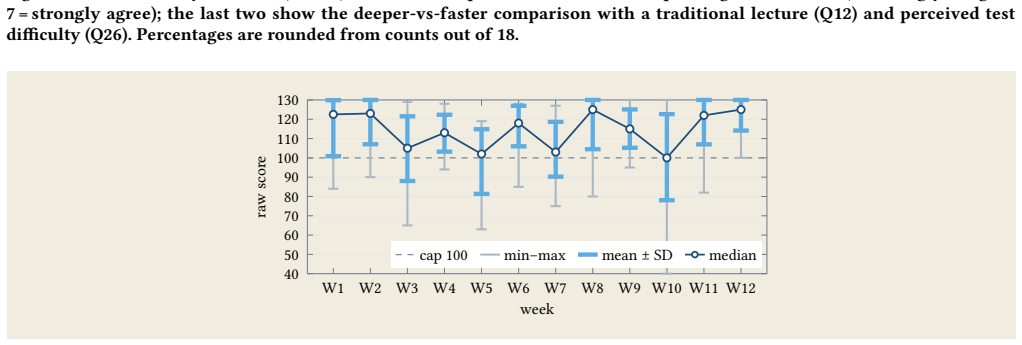
In DSAA 3071, replacing lectures with self-directed AI-assisted learning and frequent closed-book tests produced a workable high-frequency quality gate; students viewed the tests as useful accountability when given a visible preparation path, and an AI-assisted materials harness made the weekly production and grading cycle operationally feasible for the instructor.
What carries the argument
The AI-assisted materials harness, a version-controlled agent workspace that supports drafting, review, test production, and grading with human oversight.
Load-bearing premise
That results observed in one small course without a control group show the design pattern is reusable and effective for other instructors and different courses.
What would settle it
A controlled comparison in a second course where students using the TDAA pattern show no measurable gain in accountability or learning outcomes relative to a lecture-based section would undermine the reusability claim.
Figures
read the original abstract
This paper is an experience report on a 13-week Test-Driven, AI-Assisted (TDAA) redesign of DSAA 3071, Theory of Computation, an upper-level course at the Hong Kong University of Science and Technology (Guangzhou). The design is simple: the course replaces lectures with self-directed, AI-assisted learning, and frequent, independently completed tests create a high-frequency quality gate. AI agents help the instructor prepare the learning path, course website, tests, grading workflow, and repairs. Two conditions made this strict gate workable. Students needed a visible preparation path of learning sheets and aligned validation practice, so the closed-book tests felt fair rather than arbitrary. The instructor needed an AI-assisted materials harness, a version-controlled agent workspace, so that weekly drafting, review, test production, and grading could scale with human oversight. Evidence from a student survey ($N=18$), weekly scores, and the project's git history suggests that students treated the tests as useful accountability and that the harness made frequent closed-book testing operational. The evidence is limited to one small, proof-heavy course without a control group. The contribution is therefore a reusable design pattern: high-frequency tests preserve individual accountability, while AI agents make material production and marking scalable. We release the harness as a public starter template so that other instructors can reproduce it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is an experience report on the 13-week redesign of DSAA 3071 (Theory of Computation) at HKUST Guangzhou. Lectures are replaced by self-directed, AI-assisted learning with weekly closed-book tests as high-frequency quality gates. An AI-assisted materials harness supports scalable preparation, test production, grading, and repairs. Evidence from an N=18 student survey, weekly scores, and git history is cited to indicate that students viewed the tests as useful accountability mechanisms and that the harness made frequent testing operational. The paper frames the contribution as a reusable design pattern and releases the harness publicly as a starter template.
Significance. If the TDAA pattern can be shown to transfer, it would provide a concrete, scalable model for preserving individual accountability in self-paced courses while using AI to manage material production and assessment workload. The explicit public release of the harness as a version-controlled starter template is a concrete strength that enables direct replication attempts and incremental refinement by other instructors.
major comments (1)
- [Abstract] Abstract: The headline claim that the TDAA approach supplies a 'reusable design pattern' that 'other instructors can adopt' is load-bearing for the contribution, yet rests exclusively on observational data from one 13-week course with N=18 students, no control group, and no second implementation. The manuscript itself notes the single-instance limitation, but the transferability assertion therefore lacks direct empirical support.
minor comments (1)
- [Abstract] Abstract: A one-sentence parenthetical gloss on the components of the 'AI-assisted materials harness' would improve immediate readability for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to calibrate the abstract's framing of transferability. We address the comment below and propose a targeted revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that the TDAA approach supplies a 'reusable design pattern' that 'other instructors can adopt' is load-bearing for the contribution, yet rests exclusively on observational data from one 13-week course with N=18 students, no control group, and no second implementation. The manuscript itself notes the single-instance limitation, but the transferability assertion therefore lacks direct empirical support.
Authors: We agree that the paper is a single-instance experience report and provides no direct empirical evidence of transfer to other courses or instructors. The abstract already states the limitation explicitly ('The evidence is limited to one small, proof-heavy course without a control group'). We will revise the abstract to describe the TDAA approach as a proposed design pattern derived from this implementation, with the public harness release intended to enable other instructors to test and refine it, rather than asserting that reusability has been empirically demonstrated. revision: yes
Circularity Check
No circularity: experience report with direct empirical artifacts, no derivations or self-referential reductions
full rationale
The paper is a qualitative experience report on a single course redesign. It presents student survey responses (N=18), weekly scores, and git history as direct evidence. No equations, fitted parameters, model predictions, or mathematical derivations appear. No self-citations are invoked as load-bearing premises, and the contribution is framed explicitly as a reusable pattern supported by the reported single-instance data rather than reduced to prior author work or definitional equivalence. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Students can effectively learn theory of computation content through self-directed study supported by AI assistance and aligned validation practice without traditional lectures.
invented entities (1)
-
AI-assisted materials harness
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Olusola O. Adesope, Dominic A. Trevisan, and Narayankripa Sundararajan. 2017. Rethinking the Use of Tests: A Meta-Analysis of Practice Testing.Review of Educational Research87, 3 (2017), 659–701. doi:10.3102/0034654316689306
-
[2]
Anthropic. 2026. Claude Code overview. https://code.claude.com/docs/en/ overview Accessed 2026-05-08
2026
-
[3]
John Biggs. 1996. Enhancing Teaching through Constructive Alignment.Higher Education32, 3 (1996), 347–364. doi:10.1007/BF00138871
-
[4]
Jacob L. Bishop and Matthew A. Verleger. 2013. The Flipped Classroom: A Survey of the Research. In2013 ASEE Annual Conference & Exposition. ASEE Conferences, Atlanta, Georgia, 23.1200.1–23.1200.18. doi:10.18260/1-2--22585
-
[5]
Benjamin S. Bloom. 1984. The 2 Sigma Problem: The Search for Methods of Group Instruction as Effective as One-to-One Tutoring.Educational Researcher 13, 6 (1984), 4–16. doi:10.3102/0013189X013006004
-
[6]
Jennifer Campbell, Andrew Petersen, and Jacqueline Smith. 2019. Self-Paced Mastery Learning CS1. InProceedings of the 50th ACM Technical Symposium on Computer Science Education. Association for Computing Machinery, 955–961. doi:10.1145/3287324.3287481
-
[7]
Debby R. E. Cotton, Peter A. Cotton, and J. Reuben Shipway. 2024. Chatting and cheating: Ensuring academic integrity in the era of ChatGPT.Innovations in Education and Teaching International61, 2 (2024), 228–239. doi:10.1080/14703297. 2023.2190148
-
[8]
Crouch and Eric Mazur
Catherine H. Crouch and Eric Mazur. 2001. Peer Instruction: Ten years of experience and results.American Journal of Physics69, 9 (2001), 970–977. doi:10. 1119/1.1374249
2001
-
[9]
Cursor. 2026. Cursor Docs. https://cursor.com/docs Accessed 2026-05-09
2026
-
[10]
Seth DeVore, Emily Marshman, and Chandralekha Singh. 2017. Challenge of Engaging All Students via Self-Paced Interactive Electronic Learning Tutorials for Introductory Physics.Physical Review Physics Education Research13, 1 (2017), 010127. doi:10.1103/PhysRevPhysEducRes.13.010127
-
[11]
Scott Freeman, Sarah L. Eddy, Miles McDonough, Michelle K. Smith, Nnadozie Okoroafor, Hannah Jordt, and Mary Pat Wenderoth. 2014. Active learn- ing increases student performance in science, engineering, and mathemat- ics.Proceedings of the National Academy of Sciences111, 23 (2014), 8410–8415. doi:10.1073/pnas.1319030111
-
[12]
Git Project. 2026. Git. https://git-scm.com/ Accessed 2026-05-09
2026
-
[13]
ChatGPT for good? On opportunities and challenges of large language models for education,
Enkelejda Kasneci, Kathrin Sessler, Stefan Kuechemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan Guennemann, and 2Reusable harness and companion artifact: https://github.com/GiggleLiu/TDAA-Go. Test-Driven, AI-Assisted Learning: Replacing Lectures with Weekly Closed-Book Tests Eyke Huellermeier. 2023. ChatGPT for good...
-
[14]
Maureen J. Lage, Glenn J. Platt, and Michael Treglia. 2000. Inverting the Class- room: A Gateway to Creating an Inclusive Learning Environment.The Journal of Economic Education31, 1 (2000), 30–43. doi:10.1080/00220480009596759
-
[15]
Jin-Guo Liu. 2026. Agentic Production Harnesses for Technical Document Gen- eration. Manuscript in preparation
2026
-
[16]
Ethan R. Mollick and Lilach Mollick. 2024. Instructors as Innovators: A Future- Focused Approach to New AI Learning Opportunities, with Prompts.SSRN preprint(2024). doi:10.2139/ssrn.4802463
-
[17]
OpenAI. 2026. Codex: AI Coding Partner from OpenAI. https://openai.com/ codex/ Accessed 2026-05-09
2026
-
[18]
Seth Poulsen, Yael Gertner, Benjamin Cosman, Matthew West, and Geoffrey L. Herman. 2023. Efficiency of Learning from Proof Blocks Versus Writing Proofs. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education. Association for Computing Machinery, 156–162. doi:10.1145/3545945.3569797
-
[19]
Henry L. Roediger and Jeffrey D. Karpicke. 2006. Test-Enhanced Learning: Taking Memory Tests Improves Long-Term Retention.Psychological Science17, 3 (2006), 249–255. doi:10.1111/j.1467-9280.2006.01693.x
-
[20]
2013.Introduction to the Theory of Computation(3 ed.)
Michael Sipser. 2013.Introduction to the Theory of Computation(3 ed.). Cen- gage Learning. https://www.cengage.com/c/introduction-to-the-theory-of- computation-3e-sipser/9781133187790/
arXiv 2013
-
[21]
Ziqi Tan, Yingbin Zhang, and Su Mu. 2024. Error Tolerance in Automatic Short Answer Grading with Large Language Models: The Case of Handwriting Recog- nition Errors. In2024 IEEE International Conference on Consumer Electronics. doi:10.58459/icce.2024.4870
-
[22]
Typst Project. 2026. Typst. https://typst.app Accessed 2026-05-08
2026
-
[23]
Tamara van Gog, Fred Paas, and John Sweller. 2010. Cognitive Load Theory: Advances in Research on Worked Examples, Animations, and Cognitive Load Measurement.Educational Psychology Review22, 4 (2010), 375–378. doi:10.1007/ s10648-010-9145-4
2010
-
[24]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. 2024. A Survey on Large Language Model Based Autonomous Agents.Frontiers of Computer Science18, 6 (2024), 186345. doi:10.1007/s11704- 024-40231-1
-
[25]
Xiaojing Weng, Qian Xia, Meixun Gu, Kumaran Rajaram, and Thomas K. F. Chiu
-
[26]
Assessment and Learning Outcomes for Generative AI in Higher Education: A Scoping Review on Current Research Status and Trends.Australasian Journal of Educational Technology40, 6 (2024), 37–55. doi:10.14742/ajet.9540
-
[27]
Da-Wei Zhang, Melissa Boey, Yan Yu Tan, and Alexis Hoh Sheng Jia. 2024. Evaluating Large Language Models for Criterion-Based Grading from Agreement to Consistency.npj Science of Learning9 (2024), 79. doi:10.1038/s41539-024- 00291-1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.