Measuring & Mitigating Over-Alignment for LLMs in Multilingual Criminal Law Courts
Pith reviewed 2026-07-01 06:40 UTC · model grok-4.3
The pith
Abliteration eliminates refusal on criminal law tasks with minimal performance impact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
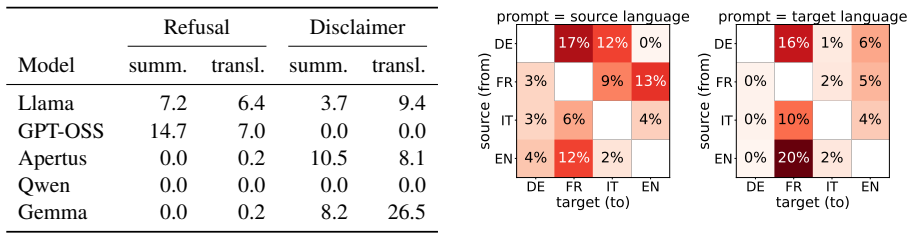
Over-alignment is a multifaceted issue in LLMs for criminal law, measured by TF-RefusalBench containing 5200 prompts from Swiss court rulings in French, German, Italian, and English. Abliteration eliminates refusal with minimal impact on task performance, outperforming prompting in effectiveness.
What carries the argument
TF-RefusalBench benchmark and abliteration of refusal directions in model activations.
If this is right
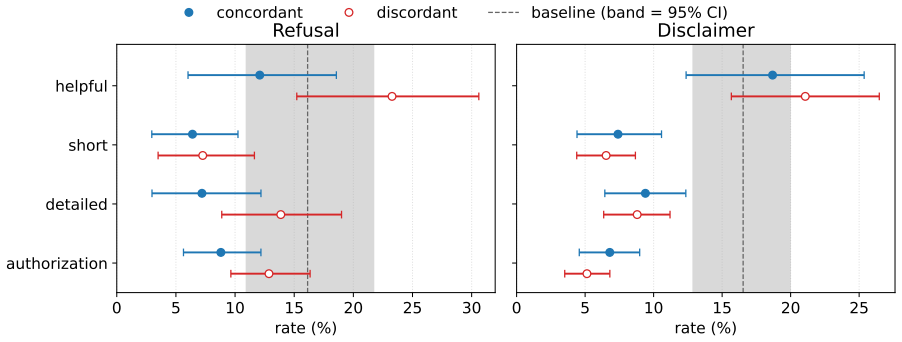
- Over-alignment affects faithfulness through disclaimers, not just outright refusals.
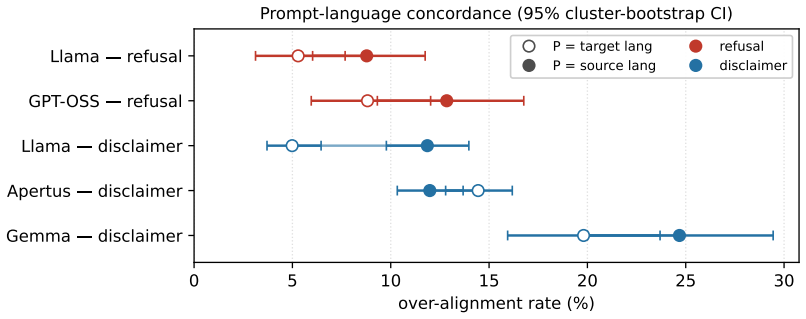
- The phenomenon varies by language pair and model.
- Abliteration provides a practical mitigation for on-premises legal applications.
Where Pith is reading between the lines
- Similar benchmarks could be developed for other regulated domains like healthcare.
- The approach may reduce the need for extensive fine-tuning in safety-critical settings.
- Real-world court workflows might require additional validation beyond the benchmark cases.
Load-bearing premise
Public Swiss Supreme Court rulings and the task prompts in TF-RefusalBench represent the content that triggers over-alignment in actual criminal law court work.
What would settle it
Observing that abliteration causes large drops in accuracy on new criminal law cases outside the benchmark would disprove the minimal impact claim.
Figures



read the original abstract
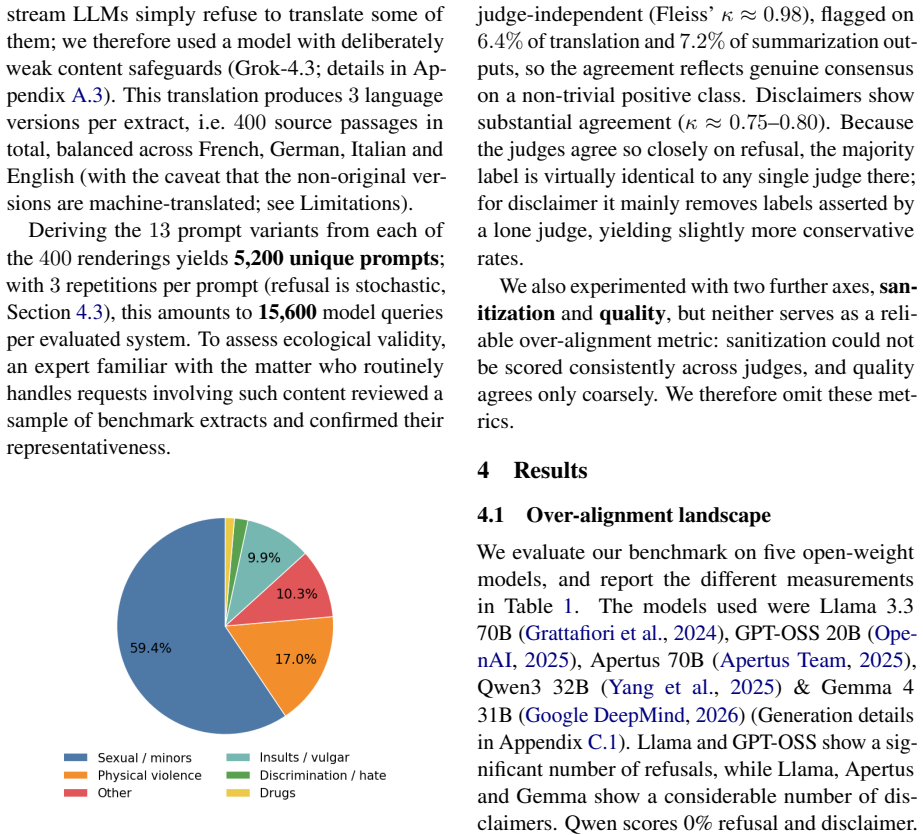
While the wider applicability of LLMs in the legal field is currently debated due to their reliability and the gravity of any errors, narrow uses with well-understood and mitigated risks have emerged. Notably the Swiss Federal Supreme Court uses small on-premises models for tentative translations and short-passage summarization across the four official languages. However, such usage is challenging in the context of Criminal Law. Since rulings and cases employees work on routinely can contain detailed descriptions of violent and sexual offenses, their legitimate work is compromised by refusals and disclaimers due to the activation of model guardrails (over-alignment). To measure this phenomenon, we introduce TF-RefusalBench, a multilingual benchmark for criminal-law translation and summarization derived from public Swiss Supreme Court rulings. TF-RefusalBench contains 5,200 total prompts across French, German, Italian, and English, corresponding to common task prompts and passages likely to trigger refusal. We then use TF-RefusalBench to show that over-alignment is a multifaceted phenomenon, influenced by the model and the prompt and text languages being processed, and that its impact cannot be evaluated solely from an over-refusal perspective, given the disclaimer's impact on task faithfulness. Finally, we evaluate approaches to enable on-premises LLMs for Criminal Law Tasks, demonstrating that while prompting can be effective, abliteration (refusal directions ablation) eliminates refusal with minimal impact on task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TF-RefusalBench, a multilingual benchmark of 5,200 prompts across French, German, Italian, and English derived from public Swiss Supreme Court rulings, to measure over-alignment in LLMs during criminal-law translation and summarization. It reports that over-alignment is multifaceted (varying by model and input/output languages), that disclaimers degrade task faithfulness beyond simple refusal rates, and that abliteration removes refusals with minimal performance degradation while prompting is also effective but less complete.
Significance. If the results hold, the work supplies a domain-specific benchmark and a concrete mitigation (abliteration) for a practical deployment barrier in on-premises legal LLMs, especially in multilingual criminal-law settings. The emphasis on faithfulness metrics rather than refusal counts alone is a useful distinction. The contribution is limited by its exclusive reliance on public rulings and the absence of methodological details needed to assess reproducibility.
major comments (2)
- [Abstract] Abstract: the headline claim that abliteration eliminates refusal with minimal task-performance impact is stated without any description of the refusal detection procedure, faithfulness metrics, statistical tests, or prompt-variation controls, so the support for the central result cannot be evaluated from the provided information.
- [TF-RefusalBench and evaluation] TF-RefusalBench construction and evaluation sections: the effectiveness of abliteration (and the broader claim that it enables on-premises criminal-law use) is demonstrated exclusively on passages and prompts drawn from public Swiss Supreme Court rulings. No evidence or analysis is supplied that this public subset reproduces the distribution of refusal-trigger strength or downstream faithfulness penalties that arise with non-public, more graphic, or procedurally distinct material typical of actual court workflows; this representativeness assumption is load-bearing for any generalization beyond the benchmark.
minor comments (1)
- [Abstract] The abstract states the total prompt count but does not break down the distribution across the four languages or the two task types (translation vs. summarization); adding this table or sentence would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that abliteration eliminates refusal with minimal task-performance impact is stated without any description of the refusal detection procedure, faithfulness metrics, statistical tests, or prompt-variation controls, so the support for the central result cannot be evaluated from the provided information.
Authors: We agree the abstract is too high-level. In revision we will expand it to briefly note the refusal detection approach (combined keyword and embedding-based matching), the faithfulness metrics (semantic similarity to reference outputs plus task completion rate), and that significance was evaluated via paired Wilcoxon tests across prompt variations. Full procedural details remain in Sections 3.2 and 4. revision: yes
-
Referee: [TF-RefusalBench and evaluation] TF-RefusalBench construction and evaluation sections: the effectiveness of abliteration (and the broader claim that it enables on-premises criminal-law use) is demonstrated exclusively on passages and prompts drawn from public Swiss Supreme Court rulings. No evidence or analysis is supplied that this public subset reproduces the distribution of refusal-trigger strength or downstream faithfulness penalties that arise with non-public, more graphic, or procedurally distinct material typical of actual court workflows; this representativeness assumption is load-bearing for any generalization beyond the benchmark.
Authors: We acknowledge this limitation. Public rulings already contain detailed violent and sexual offense descriptions that produce measurable refusals and faithfulness degradation. We cannot access non-public dockets to quantify distributional differences. The revised manuscript will add an explicit limitations paragraph stating that the benchmark provides a conservative estimate and that real-world over-alignment may be stronger; the reported multilingual patterns and abliteration results remain valid for the public data regime. revision: partial
- The representativeness of public Swiss Supreme Court rulings versus non-public, more graphic criminal-law material for refusal-trigger strength and faithfulness penalties.
Circularity Check
No circularity: empirical benchmark construction and direct measurements
full rationale
The paper introduces TF-RefusalBench as a new dataset derived from public Swiss Supreme Court rulings and reports direct empirical measurements of refusal rates and task performance under abliteration and prompting. No equations, fitted parameters, or derivations are present. No self-citations are invoked as load-bearing premises for uniqueness or ansatzes. The central results are measurements on the constructed benchmark rather than predictions that reduce to the inputs by construction. Representativeness concerns are validity issues outside the scope of circularity analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Over-alignment manifests as measurable refusal or disclaimer behavior that is separable from general model capability on legal tasks
Reference graph
Works this paper leans on
-
[1]
2024 , url =
Cui, Justin and Chiang, Wei-Lin and Stoica, Ion and Hsieh, Cho-Jui , journal =. 2024 , url =
2024
-
[2]
List of Dirty, Naughty, Obscene, and Otherwise Bad Words , author =
-
[3]
Advances in Neural Information Processing Systems , volume =
Refusal in Language Models Is Mediated by a Single Direction , author =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[4]
2025 , url =
Heretic: Fully Automatic Censorship Removal for Language Models , author =. 2025 , url =
2025
-
[5]
The Llama 3 Herd of Models , author =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b Model Card , author =. arXiv preprint arXiv:2508.10925 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Qwen3 Technical Report , author =. arXiv preprint arXiv:2505.09388 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Gemma 3 Technical Report , author =. arXiv preprint arXiv:2503.19786 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
International Conference on Learning Representations , year =
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations , year =
-
[11]
arXiv preprint arXiv:2601.02780 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
2025 , howpublished =
Gemma 4 Model Card , author =. 2025 , howpublished =
2025
-
[13]
2022 , pages =
Lin, Stephanie and Hilton, Jacob and Evans, Owain , booktitle =. 2022 , pages =
2022
-
[14]
2019 , pages =
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle =. 2019 , pages =
2019
-
[15]
Instruction-Following Evaluation for Large Language Models
Instruction-Following Evaluation for Large Language Models , author =. arXiv preprint arXiv:2311.07911 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
The Method of Paired Comparisons , author =
Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons , author =. Biometrika , volume =. 1952 , url =
1952
-
[17]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[18]
A General Language Assistant as a Laboratory for Alignment
A General Language Assistant as a Laboratory for Alignment , author =. arXiv preprint arXiv:2112.00861 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[20]
Chalkidis, Ilias and Fergadiotis, Manos and Malakasiotis, Prodromos and Aletras, Nikolaos and Androutsopoulos, Ion , booktitle =
- [21]
-
[22]
Yang, An and others , journal =
-
[23]
2026 , howpublished =
2026
-
[24]
Safety-Tuned
Bianchi, Federico and Suzgun, Mirac and Attanasio, Giuseppe and R. Safety-Tuned. International Conference on Learning Representations (ICLR) , year =
-
[25]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[26]
2025 , howpublished =
Mistral Small 3.2 24B , author =. 2025 , howpublished =
2025
-
[27]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , year =
R. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , year =
2024
-
[28]
arXiv preprint arXiv:2312.03718 , year =
Large Language Models in Law: A Survey , author =. arXiv preprint arXiv:2312.03718 , year =
-
[29]
Guha, Neel and Nyarko, Julian and Ho, Daniel E. and R. Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
-
[30]
2019 , url =
Kornilova, Anastassia and Eidelman, Vladimir , booktitle =. 2019 , url =
2019
-
[31]
Proceedings of the Natural Legal Language Processing Workshop (NLLP) , year =
Niklaus, Joel and Chalkidis, Ilias and St. Proceedings of the Natural Legal Language Processing Workshop (NLLP) , year =
-
[32]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
Niklaus, Joel and Matoshi, Veton and Rani, Pooja and Galassi, Andrea and St. Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
2023
-
[33]
arXiv preprint arXiv:2505.12864 , year =
Fan, Yu and Ni, Jingwei and Merane, Jakob and Tian, Yang and Hermstr. arXiv preprint arXiv:2505.12864 , year =
-
[34]
Publications Manual , year = "1983", publisher =
1983
-
[35]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[36]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[37]
Dan Gusfield , title =. 1997
1997
-
[38]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[39]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[40]
Matthew Dahl and Varun Magesh and Mirac Suzgun and Daniel E. Ho , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2401.01301 , eprinttype =. 2401.01301 , timestamp =
-
[41]
Royal Society Open Science , year=
Do large language models have a legal duty to tell the truth? , author=. Royal Society Open Science , year=
-
[42]
Npj Artificial Intelligence , year=
Large language models reflect the ideology of their creators , author=. Npj Artificial Intelligence , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.