UnBias-Plus: Detect, Explain, and Rewrite Bias
Pith reviewed 2026-06-26 08:34 UTC · model grok-4.3
The pith
UnBias-Plus unifies segment-level bias classification, span localization, neutral rewriting, and decision reasoning in one open-source toolkit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UnBias-Plus is an open-source toolkit that unifies segment-level multi-class bias classification, biased span localization, neutral text rewriting, and reasoning for each decision, delivered through Python, CLI, REST API, and web interfaces with all components made publicly available.
What carries the argument
The UnBias-Plus toolkit, which integrates the four bias-handling tasks of classification, localization, rewriting, and explanation into a single accessible system.
If this is right
- Analysts gain segment-level multi-class labels instead of binary bias flags.
- Exact biased spans can be isolated and replaced with neutral alternatives.
- Each output includes explicit reasoning to support interpretability.
- Multiple interfaces make the capabilities available to coders, command-line users, and web visitors.
- Public release of models and datasets enables reuse and extension by others.
Where Pith is reading between the lines
- Content platforms could embed the rewriting step to flag and suggest edits for user posts before publication.
- The modular design might allow swapping in new bias classifiers for specialized domains such as legal or medical text.
- Integration with existing writing assistants could create automated bias checks during document creation.
Load-bearing premise
Existing bias detection techniques can be reliably combined into one toolkit that produces accurate, interpretable, and neutral outputs across domains without introducing new biases or losing original meaning.
What would settle it
A side-by-side human evaluation of the toolkit's neutral rewrites on held-out texts from multiple domains, checking whether meaning is preserved and bias is reduced without new biases appearing.
Figures
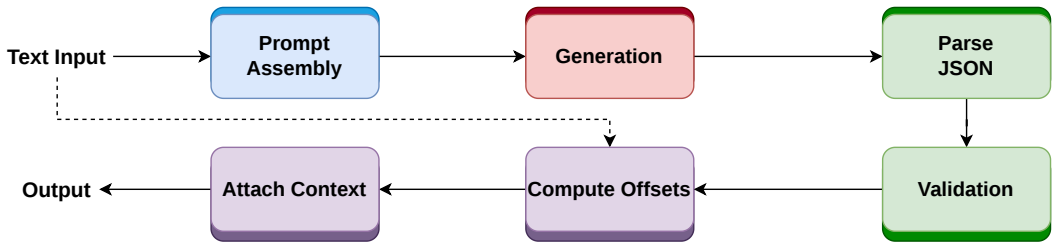
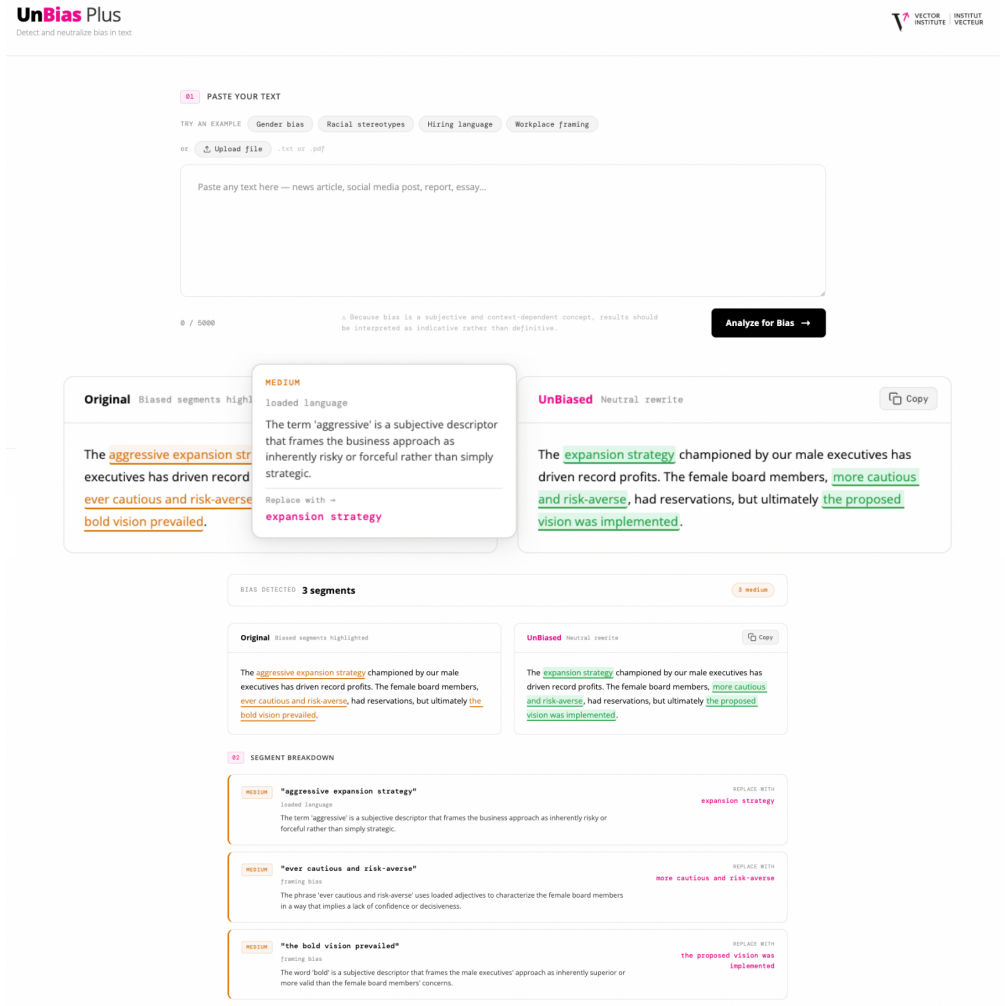
read the original abstract
Bias in natural language remains a persistent challenge in both human-written and AI-generated content, affecting domains such as journalism, education, and AI research. Most existing detection methods identify only the presence of bias, with limited support for granular detection, interpretable explanations, neutral rewriting, and openly available trained models. We present UnBias-Plus, an open-source toolkit unifying (1) segment-level multi-class bias classification, (2) biased span localization, (3) neutral text rewriting, and (4) reasoning for each decision. Available via Python, CLI, REST API, and web interfaces, UnBias-Plus supports accessible bias analysis. The toolkit, source code, models, datasets, and documentation are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents UnBias-Plus, an open-source toolkit that unifies four capabilities: (1) segment-level multi-class bias classification, (2) biased span localization, (3) neutral text rewriting, and (4) reasoning for each decision. The toolkit is made available through Python, CLI, REST API, and web interfaces, with source code, models, datasets, and documentation publicly released to support bias analysis in domains such as journalism, education, and AI research.
Significance. If the implementations deliver accurate, interpretable outputs without introducing new biases or altering meaning, the toolkit would address a practical gap by providing granular, multi-function bias handling in a single accessible package. The public release of all components supports reproducibility and adoption, which could be a concrete contribution to applied NLP tooling even without novel algorithmic advances.
major comments (2)
- [Abstract] Abstract: The central claim is the release of a unified toolkit addressing limitations of existing bias detection methods, yet no performance metrics, baselines, evaluation datasets, or ablation studies are mentioned. This absence makes it impossible to verify whether the four components function reliably together or outperform prior tools, which is load-bearing for any claim of practical utility.
- [Abstract] Abstract: The manuscript asserts that the toolkit supports 'accurate, interpretable, and neutral outputs across domains' implicitly through its design, but provides no description of the underlying models, training procedures, or integration method. Without these details, the unification claim cannot be assessed for internal consistency or risk of compounding errors from the combined components.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate planned revisions to the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim is the release of a unified toolkit addressing limitations of existing bias detection methods, yet no performance metrics, baselines, evaluation datasets, or ablation studies are mentioned. This absence makes it impossible to verify whether the four components function reliably together or outperform prior tools, which is load-bearing for any claim of practical utility.
Authors: The manuscript is a toolkit release paper whose primary contribution is the public unification and accessibility of the four capabilities rather than new algorithmic results. Evaluation details, including metrics on the component models, appear in the Methods and Experiments sections. We will revise the abstract to reference key performance figures and direct readers to those sections. revision: yes
-
Referee: [Abstract] Abstract: The manuscript asserts that the toolkit supports 'accurate, interpretable, and neutral outputs across domains' implicitly through its design, but provides no description of the underlying models, training procedures, or integration method. Without these details, the unification claim cannot be assessed for internal consistency or risk of compounding errors from the combined components.
Authors: The body of the manuscript describes the models, training procedures, and integration pipeline. To make this information visible from the abstract, we will add a concise summary of the model choices and integration approach. revision: yes
Circularity Check
No circularity: descriptive system announcement with no derivations or fitted claims
full rationale
The paper presents an open-source toolkit implementing four listed capabilities (segment-level classification, span localization, neutral rewriting, reasoning). No equations, predictions, fitted parameters, or derivation chains appear in the provided text. The central claim is simply the construction and public release of the toolkit, which is a factual descriptive statement rather than a result derived from inputs. No self-citations, uniqueness theorems, or ansatzes are invoked. This matches the default expectation of no significant circularity for system-description papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bellamy, Rachel K. E. and Dey, Kuntal and Hind, Michael and Hoffman, Samuel C. and Houde, Stephanie and Kannan, Kalapriya and Lohia, Pranay and Martino, Jacquelyn and Mehta, Sameep and Mojsilovic, Aleksandra and Nagar, Seema and Ramamurthy, Karthikeyan Natesan and Richards, John T. and Saha, Diptikalyan and Sattigeri, Prasanna and Singh, Moninder and Vars...
-
[2]
arXiv preprint arXiv:2601.21666 , year=
SONIC-O1: A Real-World Benchmark for Evaluating Multimodal Large Language Models on Audio-Video Understanding , author=. arXiv preprint arXiv:2601.21666 , year=
-
[3]
arXiv preprint arXiv:2505.11454 , year=
Humanibench: A human-centric framework for large multimodal models evaluation , author=. arXiv preprint arXiv:2505.11454 , year=
-
[5]
Neural Media Bias Detection Using Distant Supervision With BABE - Bias Annotations By Experts
Spinde, Timo and Plank, Manuel and Krieger, Jan-David and Ruas, Terry and Gipp, Bela and Aizawa, Akiko. Neural Media Bias Detection Using Distant Supervision With BABE - Bias Annotations By Experts. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.101
-
[6]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
NeuTral Rewriter: A rule-based and neural approach to automatic rewriting into gender neutral alternatives , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[7]
Expert Systems with Applications , volume=
Nbias: A natural language processing framework for BIAS identification in text , author=. Expert Systems with Applications , volume=. 2024 , publisher=
2024
-
[8]
Biaslyze API Documentation , year =
-
[9]
Sunipa Dev, Masoud Monajatipoor, Anaelia Ovalle, Arjun Subramonian, Jeff Phillips, and Kai-Wei Chang
Blodgett, Su Lin and Barocas, Solon and Daum. Language (Technology) Is Power: A Critical Survey of ``Bias'' in. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =. doi:10.18653/v1/2020.acl-main.485 , url =
-
[10]
and Saligrama, Venkatesh and Kalai, Adam T
Bolukbasi, Tolga and Chang, Kai-Wei and Zou, James Y. and Saligrama, Venkatesh and Kalai, Adam T. , title =. Advances in Neural Information Processing Systems (. 2016 , volume =
2016
-
[11]
Journal of Open Source Software , year =
Bouchard, Dylan and Chauhan, Mohit Singh and Skarbrevik, David and Bajaj, Viren and Ahmad, Zeya , title =. Journal of Open Source Software , year =. doi:10.21105/joss.07570 , url =
-
[12]
Castillo-Campos, Miguel and Becerra-Alonso, David and Boomgaarden, Hajo G. , title =. Social Science Computer Review , year =. doi:10.1177/08944393251331510 , url =
-
[13]
Nikita Nangia, Clara Vania, Rasika Bhalerao, and Samuel R
Gallegos, Isabel O. and Rossi, Ryan A. and Barrow, Joe and Tanjim, Md Mehrab and Kim, Sungchul and Dernoncourt, Franck and Yu, Tong and Chang, Ruiyi and Ahmed, Nesreen K. , title =. Computational Linguistics , year =. doi:10.1162/coli_a_00524 , url =
-
[14]
and Aponte, Rogelio and Rossi, Ryan A
Gallegos, Isabel O. and Aponte, Rogelio and Rossi, Ryan A. and Barrow, Joe and Tanjim, Md Mehrab and Yu, Tong and Deilamsalehy, Hanieh and Zhang, Ruiyi and Kim, Sungchul and Dernoncourt, Franck and Lipka, Nedim and Owens, Daniel and Gu, Jiuxiang , title =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com...
2025
-
[15]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =. Proceedings of the 10th International Conference on Learning Representations (. 2022 , url =
2022
-
[16]
Proceedings of the 31st International Conference on Computational Linguistics (
Lin, Luyang and Wang, Lingzhi and Guo, Jinsong and Wong, Kam-Fai , title =. Proceedings of the 31st International Conference on Computational Linguistics (. 2025 , pages =
2025
-
[17]
arXiv preprint arXiv:2508.03677 , year =
Marchiori Manerba, Marta and Navigli, Roberto and Ruggeri, Federico and Bernardi, Debora , title =. arXiv preprint arXiv:2508.03677 , year =
-
[18]
Nallapati, R., Zhou, B., Gulcehre, C., and Xiang, B
Nadeem, Moin and Bethke, Anna and Reddy, Siva , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics , year =. doi:10.18653/v1/2021.acl-long.416 , url =
-
[19]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
2022
-
[20]
Jwala Dhamala, Tony Sun, et al
Parrish, Alicia and Chen, Angelica and Nangia, Nikita and Padmakumar, Vishakh and Phang, Jason and Thompson, Jana and Htut, Phu Mon and Bowman, Samuel R. , title =. Findings of the Association for Computational Linguistics:. 2022 , pages =. doi:10.18653/v1/2022.findings-acl.165 , url =
-
[21]
arXiv preprint arXiv:2505.09388 , year =
-
[22]
International Journal of Data Science and Analytics , year =
Raza, Shaina and Reji, Deepak John and Ding, Chen , title =. International Journal of Data Science and Analytics , year =. doi:10.1007/s41060-022-00359-4 , url =
-
[23]
arXiv preprint arXiv:2312.00168 , year =
Raza, Shaina , title =. arXiv preprint arXiv:2312.00168 , year =
-
[24]
Raza, Shaina and Vayani, Arshia and Jain, Ankita and Narayanan, Ananya and Khazaie, Vahid Reza and Bashir, Syed Raza and Dolatabadi, Elham and Uddin, Gias and Emmanouilidis, Christos and Qureshi, Rizwan and others , title =. Information Fusion , year =. doi:10.1016/j.inffus.2025.104092 , url =
-
[25]
Proceedings of the 4th Workshop on Gender Bias in Natural Language Processing (
Tokpo, Ewoenam Kwaku and Calders, Toon , title =. Proceedings of the 4th Workshop on Gender Bias in Natural Language Processing (. 2022 , pages =
2022
-
[26]
2025 , url =
Neutralizing Bias in. 2025 , url =
2025
-
[27]
2026 , url =
unbias-plus Demo Notebook , howpublished =. 2026 , url =
2026
-
[28]
Fairlearn: Assessing and Improving Fairness of
Weerts, Hilde and Dud. Fairlearn: Assessing and Improving Fairness of. Journal of Machine Learning Research , year =
-
[29]
Proceedings of the 5th Workshop on Trustworthy
Xu, Xin and Xu, Wei and Zhang, Ningyu and McAuley, Julian , title =. Proceedings of the 5th Workshop on Trustworthy. 2025 , pages =
2025
-
[30]
Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods
Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Ordonez, Vicente and Chang, Kai-Wei , title =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year =. doi:10.18653/v1/N18-2003 , url =
-
[31]
Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
WIKIBIAS: Detecting multi-span subjective biases in language , author=. Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
2021
-
[32]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Language (technology) is power: A critical survey of “bias” in NLP , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[33]
arXiv preprint arXiv:2312.06674 , year=
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
-
[34]
and Wallach, Hanna and Cotterell, Ryan
Zmigrod, Ran and Mielke, Sabrina J. and Wallach, Hanna and Cotterell, Ryan , title =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year =. doi:10.18653/v1/P19-1161 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.