What Does a Chemical Language Model Know About Molecules?
Pith reviewed 2026-06-26 09:22 UTC · model grok-4.3
The pith
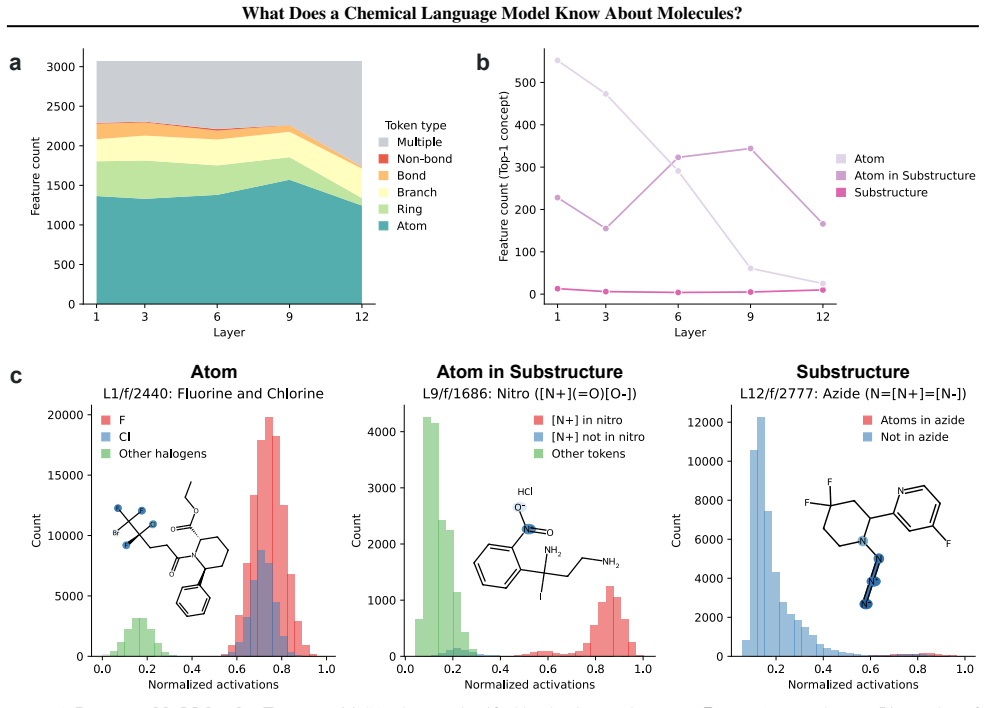
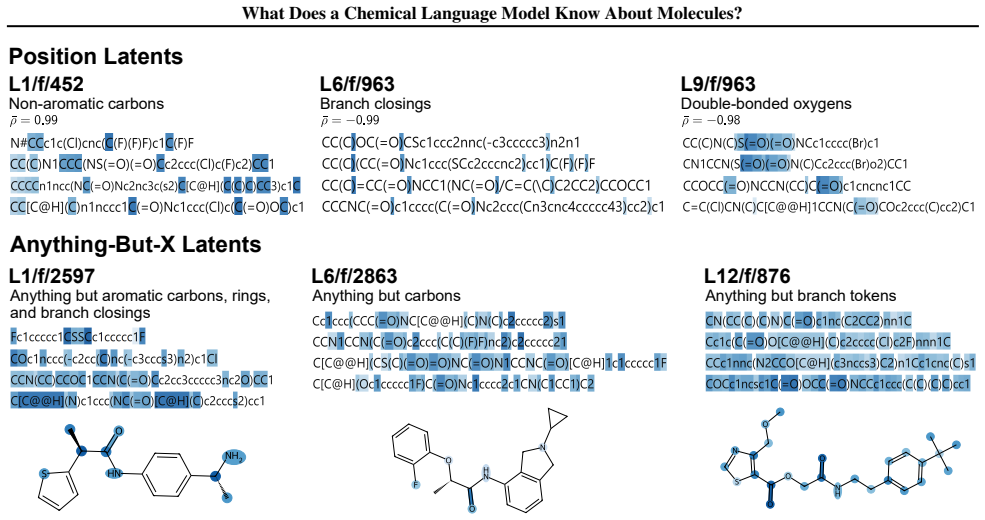
Sparse autoencoders show chemical language models parse SMILES positions in early layers and encode substructures and pharmacological features later.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
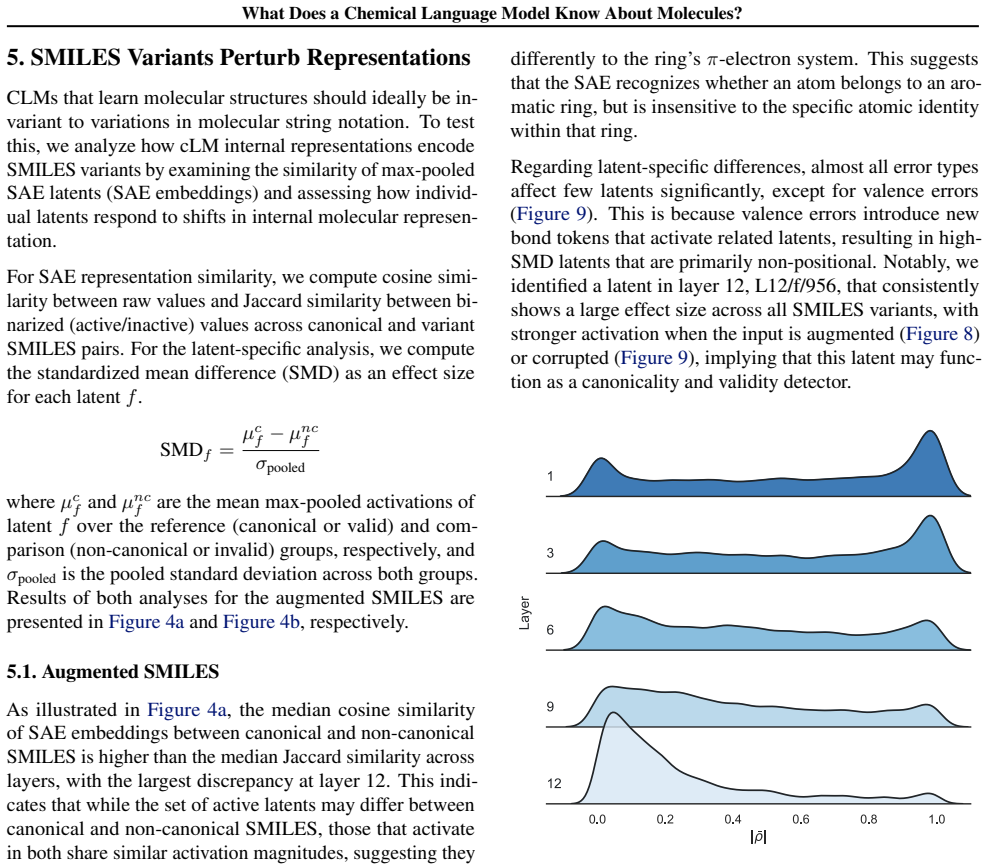
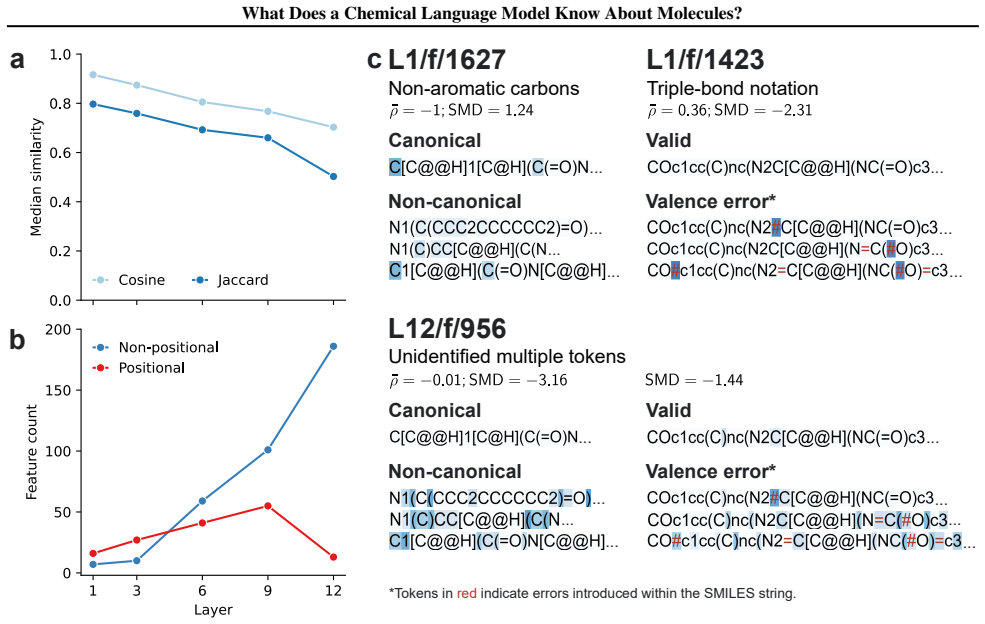
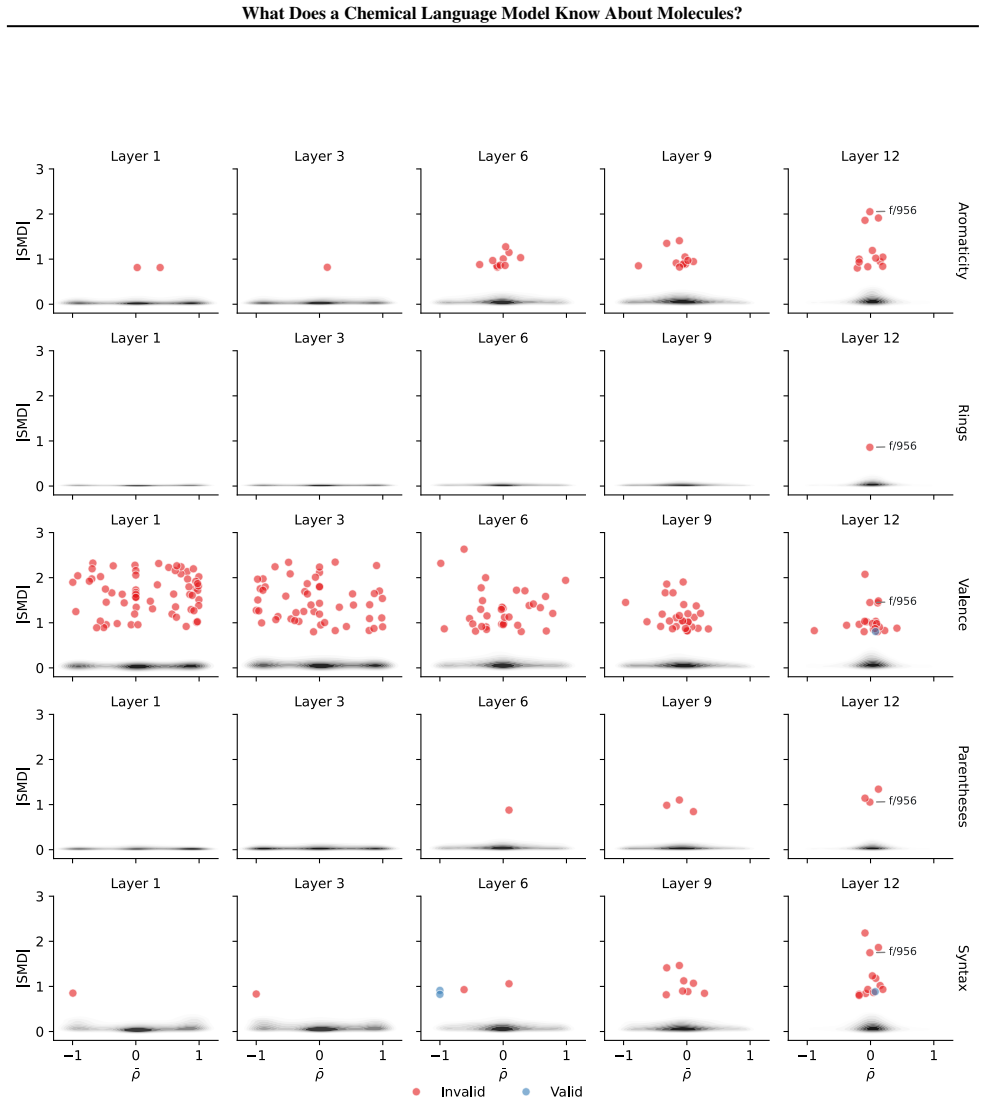
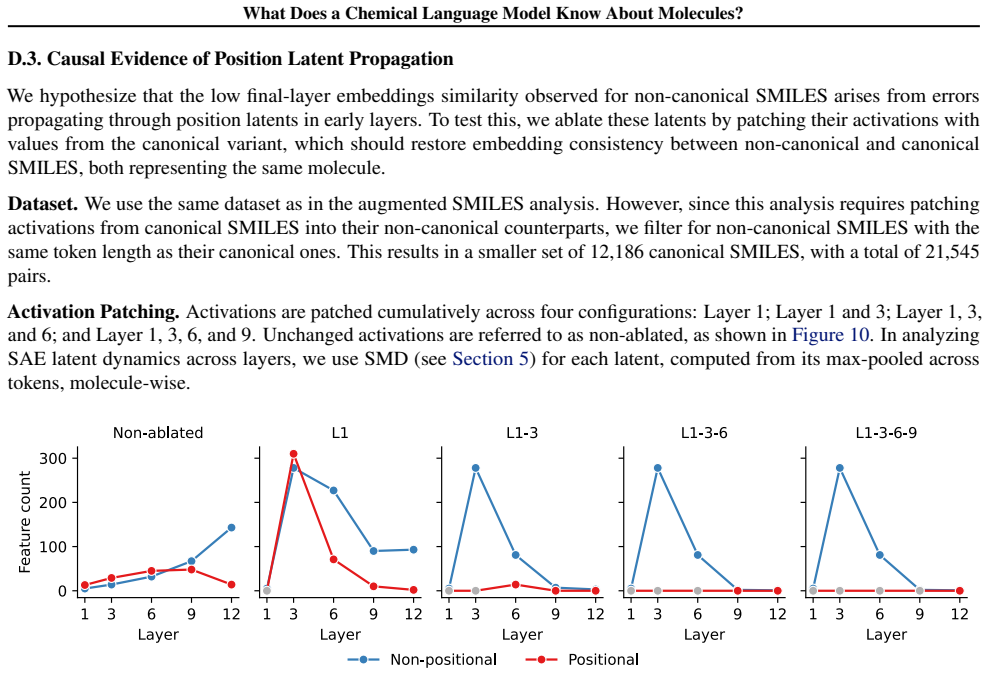
Early layers in MolFormer rely on position-tracking latents to parse molecular grammar in SMILES, while later layers encode atom-in-substructure and pharmacologically relevant features; non-canonical SMILES produce more disruptive representation shifts than invalid SMILES because position-latent disruption propagates across layers.
What carries the argument
Sparse autoencoders applied across layers of MolFormer to recover and interpret position-tracking and semantic latents from molecular string representations.
If this is right
- Representation building in chemical language models proceeds from syntactic position tracking to semantic substructure encoding.
- Non-canonical SMILES strings disrupt internal processing more than invalid ones due to position-latent effects.
- Pharmacologically relevant features emerge in deeper layers rather than being present from the start.
- Interactive visualization of SAE activations can reveal how specific molecular strings are processed internally.
Where Pith is reading between the lines
- This layer-wise progression suggests that interventions on early position latents could improve robustness to SMILES variations.
- The findings may generalize to other string-based molecular encoders if similar position-tracking mechanisms are recovered.
- Pharmacological feature emergence in later layers could guide targeted fine-tuning for drug-related tasks.
Load-bearing premise
The latents extracted by the sparse autoencoders reflect actual features used by the model rather than being artifacts of the autoencoder training process.
What would settle it
A controlled intervention that disables the position-tracking latents in early layers and measures whether SMILES parsing accuracy drops specifically for canonical versus non-canonical strings.
Figures
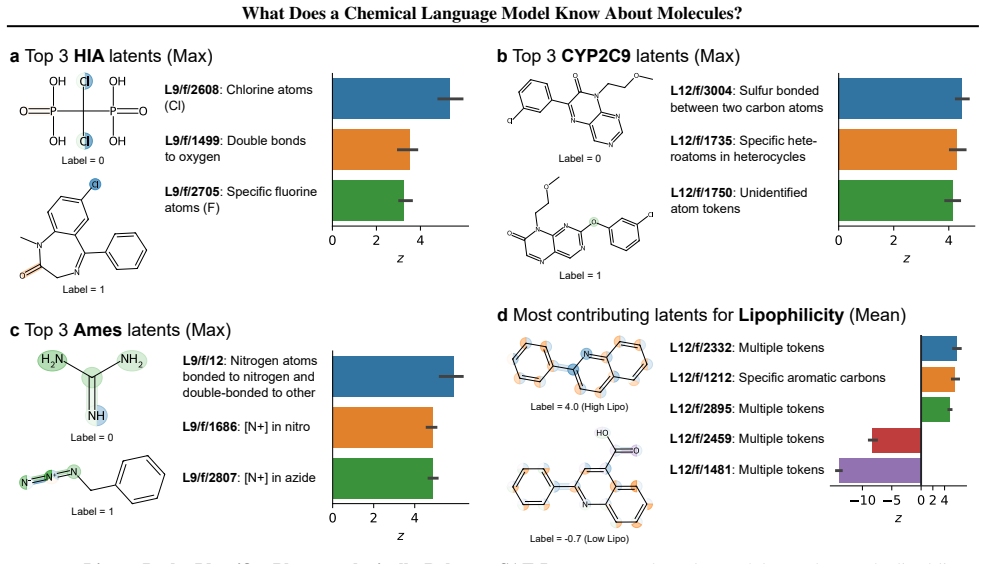
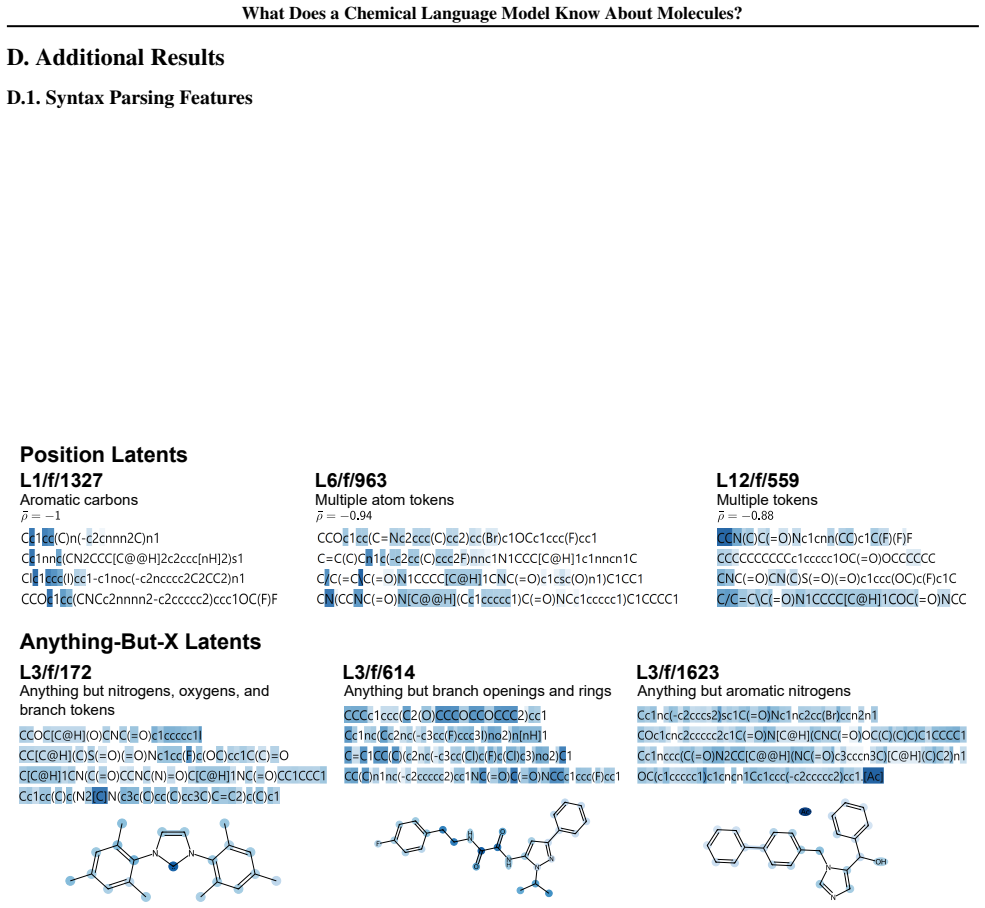
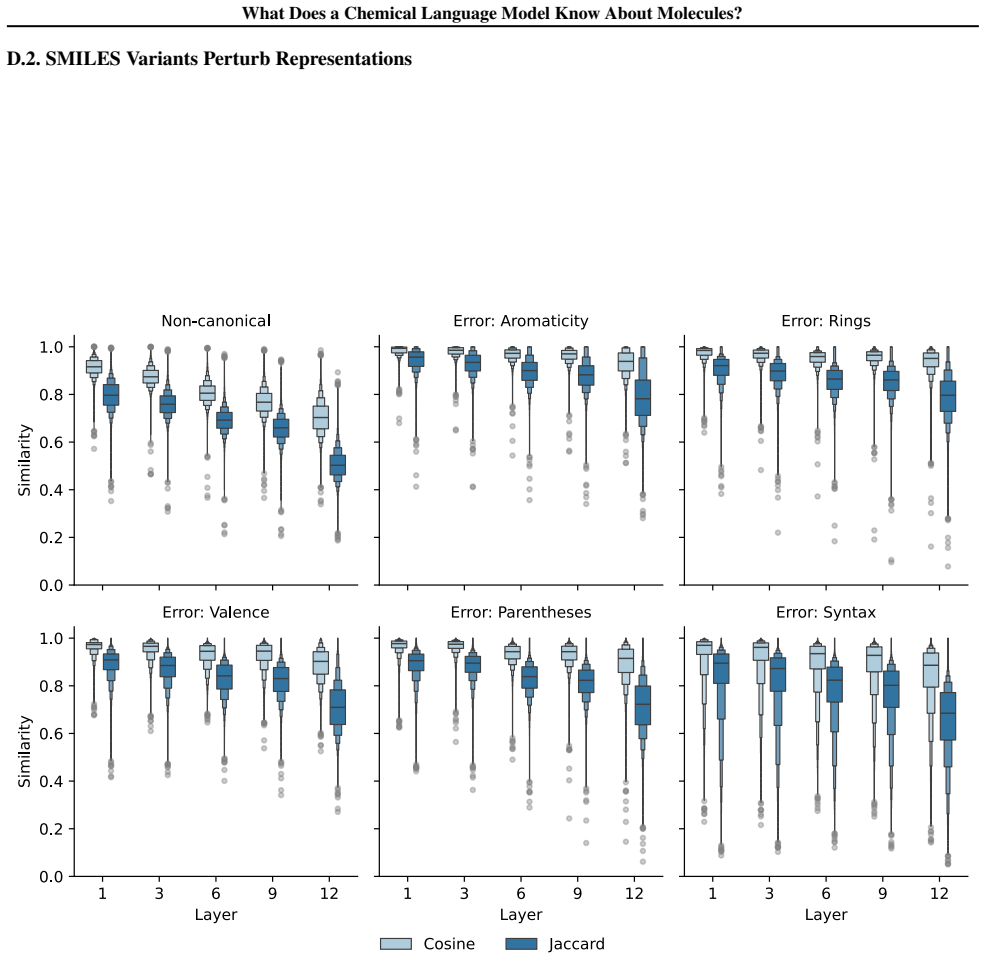
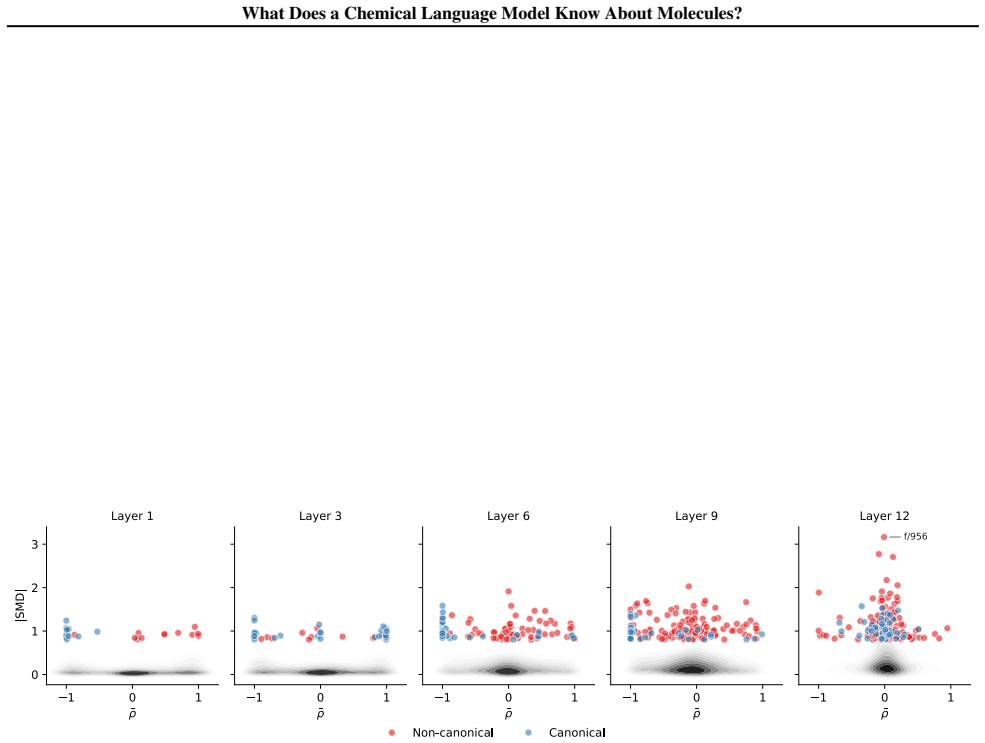
read the original abstract
Chemical language models (cLMs) are widely assumed to learn surface-level syntactic patterns rather than learning meaningful molecular semantics. Here, we apply sparse autoencoders (SAEs) to MolFormer, an encoder-only cLM, to mechanistically examine how molecular representations are built across layers. We discover that early layers rely on position-tracking latents to parse molecular grammar, while later layers encode atom-in-substructure and pharmacologically relevant features. Additionally, we show that non-canonical SMILES produce more disruptive representation shifts than invalid SMILES, driven by position-latent disruption propagating across layers. To support further exploration, we develop InterMol, an interactive visualizer for SAE activations on molecular strings and structures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper applies sparse autoencoders (SAEs) to MolFormer, an encoder-only chemical language model, to examine layer-wise construction of molecular representations from SMILES strings. It claims that early layers rely on position-tracking latents to parse molecular grammar, later layers encode atom-in-substructure and pharmacologically relevant features, and that non-canonical SMILES induce larger representation shifts than invalid SMILES via propagation of position-latent disruptions. An interactive visualizer called InterMol is introduced to support exploration of SAE activations.
Significance. If the recovered latents are shown to be causally relevant to MolFormer's computations, the work would provide a mechanistic account of how cLMs move from syntactic to semantic processing of molecules, directly addressing a common assumption in the field. The release of InterMol constitutes a concrete contribution for reproducibility and further interpretability studies.
major comments (2)
- [Abstract and §4] Abstract and §4 (results on layer-wise latents): the central claims that early layers use position-tracking latents while later layers encode pharmacologically relevant features rest on the assumption that SAE directions correspond to genuine model features; no quantitative metrics, labeling criteria, or validation controls (e.g., ablation or causal patching) are supplied to support this mapping.
- [§5] §5 (non-canonical vs. invalid SMILES experiments): the claim that non-canonical SMILES produce more disruptive shifts via position-latent propagation requires evidence that the observed activation changes are driven by the identified position latents rather than other factors; the manuscript provides no feature-ablation or intervention results to establish this causal link.
minor comments (2)
- [§3] Figure captions and §3 (SAE training details): sparsity and dictionary-size hyperparameters are not stated explicitly, making it difficult to assess reproducibility of the reported latents.
- [§6] The InterMol tool description would benefit from a brief statement of its input/output format and any limitations on the molecules it can visualize.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We address each major comment below, clarifying our methodological approach while acknowledging areas where additional discussion or qualification is warranted.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results on layer-wise latents): the central claims that early layers use position-tracking latents while later layers encode pharmacologically relevant features rest on the assumption that SAE directions correspond to genuine model features; no quantitative metrics, labeling criteria, or validation controls (e.g., ablation or causal patching) are supplied to support this mapping.
Authors: The interpretations in §4 are derived from consistent activation patterns of SAE latents on targeted molecular inputs, visualized and categorized via the InterMol tool. Labeling was performed by inspecting high-activating examples for syntactic (position) versus semantic (substructure/pharmacophore) properties. We agree that explicit labeling criteria and a clearer statement of the monosemanticity assumption would strengthen the presentation. We will revise §4 and the abstract to include these criteria and add a limitations paragraph noting the absence of quantitative metrics or causal interventions such as ablation or patching. revision: partial
-
Referee: [§5] §5 (non-canonical vs. invalid SMILES experiments): the claim that non-canonical SMILES produce more disruptive shifts via position-latent propagation requires evidence that the observed activation changes are driven by the identified position latents rather than other factors; the manuscript provides no feature-ablation or intervention results to establish this causal link.
Authors: Section 5 reports larger activation shifts for non-canonical SMILES that align with early-layer position-latent disruptions propagating forward, based on layer-wise comparison of SAE activations. We concur that this constitutes correlational evidence rather than a direct causal demonstration via ablation or intervention. We will revise the text in §5 to frame the position-latent propagation as a supported hypothesis from the observed patterns, while explicitly noting the lack of feature-ablation results as a limitation. revision: partial
Circularity Check
No circularity: purely empirical SAE analysis with no derivations or self-referential predictions
full rationale
The paper is an empirical interpretability study applying sparse autoencoders to MolFormer activations on SMILES strings. Claims about layer-wise latents (position-tracking in early layers, atom-in-substructure and pharmacological features in later layers) and representation shifts under non-canonical vs. invalid SMILES are presented as observations from activation patterns and visualizations, not as quantities derived from equations or fitted parameters that reduce to the inputs by construction. No self-citations load-bearing the central claims, no uniqueness theorems, no ansatzes smuggled in, and no renaming of known results as new derivations. The work is self-contained against external benchmarks in the sense that its findings rest on direct measurement rather than any internal definition that equates result to input.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://www.biorxiv.org/content/ early/2025/06/18/2025.02.06.636901
doi: 10.1101/2025.02.06.636901. URL https://www.biorxiv.org/content/ early/2025/06/18/2025.02.06.636901. Ahmad, W., Simon, E., Chithrananda, S., Grand, G., and Ramsundar, B. Chemberta-2: Towards chemical foun- dation models,
-
[2]
URL https://arxiv.org/ abs/2209.01712. Bajorath, J. Chemical and biological language models in molecular design: opportunities, risks and scientific rea- soning.Future Sci. OA, 10(1):FSO957, May
-
[3]
Brinkmann, H., Argante, A., ter Steege, H., and Grisoni, F
URL https://arxiv.org/abs/1703.07076. Brinkmann, H., Argante, A., ter Steege, H., and Grisoni, F. Going beyond smiles enumeration for data augmentation in generative drug discovery.Digital Discovery, 4:2752– 2764,
-
[4]
URL http: //dx.doi.org/10.1039/D5DD00028A
doi: 10.1039/D5DD00028A. URL http: //dx.doi.org/10.1039/D5DD00028A. Brixi, G., Durrant, M. G., Ku, J., Poli, M., Brockman, G., Chang, D., Gonzalez, G. A., King, S. H., Li, D. B., Mer- chant, A. T., Naghipourfar, M., Nguyen, E., Ricci-Tam, C., Romero, D. W., Sun, G., Taghibakshi, A., V orontsov, A., Yang, B., Deng, M., Gorton, L., Nguyen, N., Wang, N. K., ...
-
[5]
Genome modeling and design across all domains of life with Evo 2
doi: 10.1101/2025.02.18.638918. URL https://www.biorxiv.org/content/ early/2025/02/21/2025.02.18.638918. Chithrananda, S., Grand, G., and Ramsundar, B. Chem- berta: Large-scale self-supervised pretraining for molecu- lar property prediction,
-
[6]
URL https://arxiv. org/abs/2010.09885. Cohen, J., Hasson, A. G., and Tanovic, S. Unveiling la- tent knowledge in chemistry language models through sparse autoencoders,
arXiv 2010
-
[7]
URL https://arxiv. org/abs/2512.08077. Dudek, A., Dejnaka, E., Sulecka-Zadka, J., Perz, M., Krawczyk-Łebek, A., Kostrzewa-Susłow, E., Pruchnik, 8 What Does a Chemical Language Model Know About Molecules? H., and Pawlak, A. Bromo- and chloro-substituted flavones induce apoptosis and modulate cell death path- ways in canine lymphoma and leukemia cells - a c...
-
[8]
URLhttps://arxiv.org/abs/2510.08638. Fender, I., Gut, J. A., and Lemmin, T. Beyond performance: how design choices shape chemical language models.J. Cheminform., 17(1):173, November
-
[9]
URL https: //arxiv.org/abs/2406.04093. Grisoni, F. Chemical language models for de novo drug design: Challenges and opportunities.Curr . Opin. Struct. Biol., 79(102527):102527, April
-
[10]
Huang, K., Fu, T., Gao, W., Zhao, Y ., Roohani, Y ., Leskovec, J., Coley, C
URL https://arxiv.org/abs/ 2509.14252. Huang, K., Fu, T., Gao, W., Zhao, Y ., Roohani, Y ., Leskovec, J., Coley, C. W., Xiao, C., Sun, J., and Zitnik, M. Ther- apeutics data commons: Machine learning datasets and tasks for drug discovery and development,
-
[11]
Huang, K., Fu, T., Gao, W., Zhao, Y ., Roohani, Y ., Leskovec, J., Coley, C
URL https://arxiv.org/abs/2102.09548. Huang, K., Fu, T., Gao, W., Zhao, Y ., Roohani, Y ., Leskovec, J., Coley, C. W., Xiao, C., Sun, J., and Zitnik, M. Artifi- cial intelligence foundation for therapeutic science.Nat. Chem. Biol., 18(10):1033–1036, October
-
[12]
Kim, S., Chen, J., Cheng, T., Gindulyte, A., He, J., He, S., Li, Q., Shoemaker, B
URL https://arxiv.org/abs/2505.07139. Kim, S., Chen, J., Cheng, T., Gindulyte, A., He, J., He, S., Li, Q., Shoemaker, B. A., Thiessen, P. A., Yu, B., Zaslavsky, L., Zhang, J., and Bolton, E. E. PubChem 2019 update: improved access to chemical data.Nucleic Acids Res., 47(D1):D1102–D1109, January
arXiv 2019
-
[13]
F., Probst, D., Ujihara, K., Pahl, A., Godin, G., and Lehtivarjo, J
Landrum, G., Tosco, P., Kelley, B., Rodriguez, R., Cos- grove, D., Vianello, R., sriniker, Gedeck, P., Jones, G., Kawashima, E., NadineSchneider, Nealschneider, D., Dalke, A., tadhurst-cdd, Swain, M., Cole, B., Turk, S., Savelev, A., Maeder, N., Vaucher, A., W´ojcikowski, M., Faara, H., Take, I., Walker, R., Scalfani, V . F., Probst, D., Ujihara, K., Pahl...
2025
-
[14]
URL https://arxiv. org/abs/2411.12886. Schoenmaker, L., B´equignon, O. J. M., Jespers, W., and van Westen, G. J. P. UnCorrupt SMILES: a novel approach to de novo design.J. Cheminform., 15(1):22, February
-
[15]
URL https://arxiv. org/abs/2506.15679. Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., Pearce, A., Citro, C., Ameisen, E., Jones, A., Cunningham, H., Turner, N. L., McDougall, C., MacDiarmid, M., Freeman, C. D., Sumers, T. R., Rees, E., Batson, J., Jermyn, A., Carter, S., Olah, C., and Henighan, T. Scaling monosemanticity: Ex- ...
-
[16]
Tsui, D., Talreja, K., Saeedi, D., and Aghazadeh, A
URL https: //transformer-circuits.pub/2024/ scaling-monosemanticity/index.html. Tsui, D., Talreja, K., Saeedi, D., and Aghazadeh, A. Protein circuit tracing via cross-layer transcoders,
2024
-
[17]
Varadi, K., Marosi, M., and Antal, P
URL https://arxiv.org/abs/2602.12026. Varadi, K., Marosi, M., and Antal, P. Circuits, features, and heuristics in molecular transformers,
-
[18]
URL https://arxiv.org/abs/2512.09757. Veith, H., Southall, N., Huang, R., James, T., Fayne, D., Artemenko, N., Shen, M., Inglese, J., Austin, C. P., Lloyd, D. G., and Auld, D. S. Comprehensive characterization of cytochrome P450 isozyme selectivity across chemical libraries.Nat. Biotechnol., 27(11):1050–1055, November
-
[19]
Code Availability The code to reproduce the experiments is available athttps://github.com/ckennetha/intermol
10 What Does a Chemical Language Model Know About Molecules? Appendix A. Code Availability The code to reproduce the experiments is available athttps://github.com/ckennetha/intermol. B. Related Work Mechanistic Interpretability of Chemical Language Models.Understanding how cLMs work internally may help in designing better cLMs that enable the generation o...
2025
-
[20]
Normalization.For ease of interpretation, we normalized SAE latents using ∼250,000 molecular SMILES randomly sampled from the SAE training dataset
and PubChem (Kim et al., 2019), the same data pool used to train MolFormer-XL. Normalization.For ease of interpretation, we normalized SAE latents using ∼250,000 molecular SMILES randomly sampled from the SAE training dataset. Following Simon & Zou (2025), for each latent in each SAE, we used its maximum activation to rescale the encoder and decoder weigh...
2019
-
[21]
Table 1.Invalid SMILES Generation.Error variations are randomly introduced for each error type with examples of resulting invalid SMILES
This yields around 300,000 valid/invalid pairs. Table 1.Invalid SMILES Generation.Error variations are randomly introduced for each error type with examples of resulting invalid SMILES. Red tokens on the left indicate deletions, while those on the right indicate substitutions or insertions. Error type Variation Invalid SMILES Rings Remove a ring indexc1cc...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.